픽셀 : 디스플레이를 구성하고 있는 가장 작은 단위(ex. RGB방식
![]()
해상도 : 가로와 세로의 픽셀수. 픽셀수가 많아질수록 더 선명하게 보임
-
HD < FHD < QHD < UHD 순으로 해상도가 높다
저해상도 vs 고해상도 해상도 비교 화면해상도와 픽셀 


Super Resolution(초해상화) 개념
- SISR(Single Image Super Resolution) 방법에 속함
- 저해상도 영상을 고해상도 영상으로 변환하는 작업 또는 그러한 과정
- ex) 하얀거탑 리마스터링, CCTV 차량 번호판 또는 사람 얼굴 인식, 의료영상 등
| (예시1) 하얀거탑 리마스터링 | (예시2) CCTV 차량, 사람 인식 | (예시3]) 의료영상 |
|---|---|---|
 |  |  |
Super Resolution을 어렵게 만드는 요인들
- Ill-Posed (Regular Inverse) Problem
- 하나의 저해상도 이미지를 고해상도 이미지로 만드는데 매우 다양한 경우의 수가 있다는 것
- 좌측의 사진에서는 눈으로볼 땐 차이가 없어보이지만 우측과 같이 세부적으로 픽셀값이 다름
| 이미지 | 세부 픽셀값 |
|---|---|
 |  |
- Super Resolution 문제의 복잡도
- 실제 정보(녹색 픽셀)만을 이용해 많은 정보(회색 픽셀)를 만들어내는 과정은 매우 복잡함
- 그만큼 잘못된 정보를 만들어 낼 가능성 또한 높음
- 결과평가에 있어 정량적 평가 척도와 사람의 시각적평가가 잘 일치하지 않음
- 정량적 평가에서는 결과 1이, 시각적으로 결과2가 고해상도라고 평가됨(불일치)

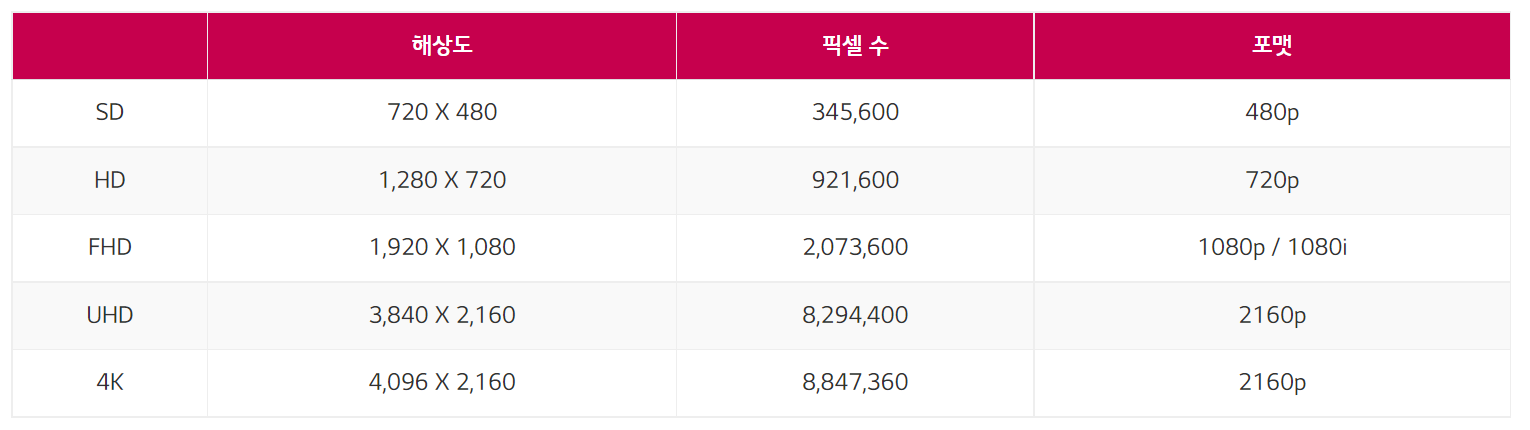
Interpolation
- Super Resolution을 수행하는 가장 쉬운 방식
- 알려진 두 점 사이의 특정 지점에 대한 값을 추정하는 방법
- Linear interpolation(선형보간법) : 1차원, 2개의 값으로 새로운 픽셀 예측
- Bilinear interpolation(쌍선형보간법) : 2차원, 4개의 값으로 새로운 픽셀 예측
- Bibubic interpolation(쌍삼차보간법)
- Linear interpolation(선형보간법) : 1차원, 2개의 값으로 새로운 픽셀 예측
Super Resolution 구조
1) SRCNN
-
Super Resolution Convolutional Neural Networks
-
Deep Learning을 이용한 Super Resolution

- LR(저해상도 image)를 bicubic interpolation(쌍삼차보간법)으로 원하는 사이즈로 눌림 ⇨ ILR 출력
- ILR을 3개의 convolutional layer를 거쳐 고해상도 이미지 생성
- HR(실제 image)와 생성된 고해상도 이미지의 차이를 역전파하여 신경망의 가중치 학습
-
SRCNN 구성방식(archite
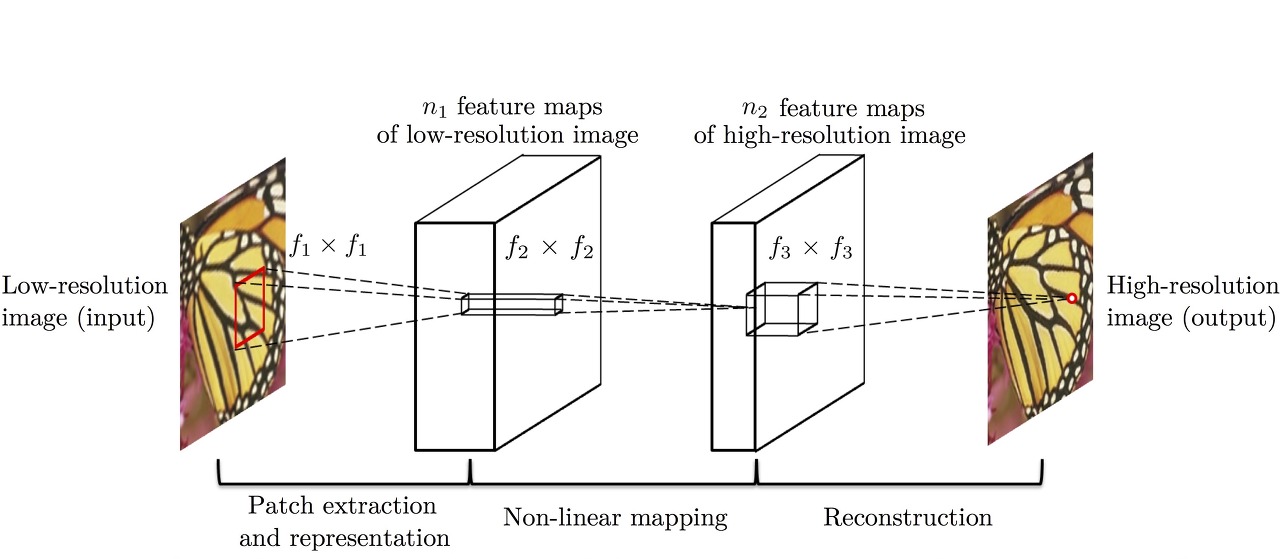
- Patch extraction and representation : 저해상도 이미지에서 patch(특징)들을 추출하는 과정
- Non-linear mapping : 여기서 얻은 다차원의 patch들을 non-linear하게 다른 다차원의 patch들로 매핑을 하는 과정
- Reconstruction : 이 다차원 patch들로부터 고해상도 이미지를 복원(3개의 convolutional layer로 실행)
- 손실함수(Loss function)로 MSE(Mean Squared Error) 평균제곱오차값 사용
-
그 외의 방법
| 항목 | VDSR (Very Deep Super Resolution) | RDN (Residual Dense Network) | RCAN (Residual Channel Attention Networks) |
|---|---|---|---|
| 차이점 | - 20개의 conv layer 사용 - 결과 생성 직전 input image를 더함(residual learning) | - 여러개의 conv layer로 출력된 특징(patch)를 재사용 | - conv layer의 결과 값 중 중요한 채널만 선택적으로 집중 |
| 구조 |  |  |  |
2) SRGAN = Super Resoultion + GAN
GAN(Generative Adversarial Networks)
- 확률 분포 모델링 : 원래 데이터와 확률분포를 정확히 공유하는 무한히 많은 새로운 데이터를 생성
- Generator(생성자) : 원 데이터의 확률분포를 따르는 새로운 데이터 생성
- ex) 위조지폐범에 해당, 위조지폐를 잘 만들어 경찰을 속이고자 함
- Discriminator(판별자) : 분류에 의미가 없는 0.5의 확률값을 출력
- ex) 경찰에 해당, 진짜 지폐와 위조지폐를 정확히 구분하여 위조지폐범을 검거하고자 함
- GAN(Generative Adversarial Networks) 을 활용한 Super Resolution 과정
- Generator Network = 위조지폐범(생성 모델)
- 저해상도 이미지를 입력 받아 (가짜)고해상도 이미지를 생성
- Discriminator Network = 경찰(분류/판별 모델)
- 생성된 (가짜)고해상도 이미지와 실제(진짜) 고해상도 이미지 중 진짜를 판별

- SRGAN에 사용되는 loss function =
perceptual losscontent loss: VGG loss. 실제 고해상도 이미지와 생성해낸 이미지를 이미지넷으로 사전 학습된(pre-trained) VGG 모델에 입력하여 나오는 feature map에서의 차이를 계산adversarial loss: GAN의 loss. Generator로 하여금 진짜처럼 보일 정도로 사실적인 가짜 이미지를 생성하도록 학습 알고리즘


- SRGAN 논문 실험한 결과
SRResNet: SRGAN의 Generator를 뜻하며, Generator 구조만 이용해 SRCNN과 비슷하게 MSE 손실함수로 학습한 결과- 오른쪽으로 향할 수록 GAN & VGG 구조를 이용하여 세부적인 이미지 구조가 선명해짐을 볼수 있음
+ VGG22는 VGG54에 비해 더 low-level의 특징에서 손실을 계산함

Super Resolution 결과 평가척도
1) PSNR(Peak Signal-to-Noise Ratio; 최대신호잡음비)
- 영상 내 신호가 가질 수 있는 최대 신호에 대한 잡음(noise)의 비율
- 목적 : 영상 및 동영사 압축시 화질이 얼마나 손실되었는지 평가
- 단위 : 데시벨(db)
- 해석 : PSNR 수치가 높을 수록 원본 영상 손실이 적고, 낮을 수록 원본 영상 손실이 많다는 의미(값이 높을수록 좋음)

- 단점 : 종종 사람이 느끼는 것과 일치되지 않은 품질 점수를 산출

2) SSIM(Structural Similarity Index Map)
- 영상의 구조 정보를 고려하여 얼마나 구조 정보를 변화시키지 않았는지를 계산
- 지역적으로 SSIM을 적용하여 얻은 SSIM 맵의 픽셀값을 평규내어 최종 품질 점수를 얻음
- 해석 : 특정 영상에 대한 SSIM값이 높을수록 원본 영상의 품질에 가깝다는 의미(값이 높을수록 좋음)
RefSR(Reference-based Super Resolution)
- 해상도를 높이는 데 참고할 만한 다른 이미지를 같이 제공
- 입력값 : Ref images를 Super Resolution을 수행
- 결과값 : SRNTT(SRGAN보다 더 선명함을 볼 수 있음)

<참고자료>
1. 최대신호대잡음비(PSNR)와 이미지 품질
2. Single Image Super Resolution using Deep Learning Overview
