1.Image Classification
1) 컴퓨터비전에서 핵심 task

- 입력 이미지를 정해진 카테고리 중 하나인 라벨로 분류하는 문제 ⇒ 지도 학습의 일종
- 사람이 ‘고양이’를 인지하기 쉽지만, 컴퓨터는 이미지를 숫자 집합들로 보는 차이가 있다.
- 이미지가 미세한 차이가 있다고 하더라도 컴퓨터가 보는 픽셀 값은 완전히 달라진다.
- 우리는 이런한 다양성도 다룰수 있어야 하지만 매우 어렵다.
| Illumination | Deformation | Occlusion | Background Clutter | Intraclass variation |
|---|---|---|---|---|
 |  |  |  |  |
- 그리고 object detection은 “고양이”이라는 객체를 직관적이고 명시적인 알고리즘이 존재하지 않는다
- 명시적 규칙 집합
- 이미지에서 edges를 계산하고, 각각의 conder(3개의 점이 지나는 지점)와 edges를 카테고리로 분류한다.
- 단점 : 강인(Robust)하지 못함. 확장성이 없다(객체별로 손으로 규칙을 생성해야 함)
- 명시적 규칙 집합
2) Data-Driven Approach
-
데이터 분석과 해석을 기반으로 전략적 결정을 내리는 것으로 다양한 객체(데이터)에 유연하게 적용할 수 있는 방법이다.
-
한국어로 읽으면 데이터 중심 접근방법(Date-Driven Approach)
-
규칙을 직접 정의하는 대신에, 많은 데이터를 수집하여 학습한다
-
데이터 중심 접근 방식을 이용했을 때, 여러 데이터 소스를 식별 및 관리하여 고급 분석 모델을 구축 할 수 있다.

-
데이터를 이용한 인식 알고리즘 순서
- 데이터와 라벨들의 데이터셋을 수집
- 머신러닝을 사용한 분류기 학습
- 새로운 이미지에 대해 분류기 평가
-
두 개의 함수가 필요함
- train 함수(input : image, label, output : model)
- predict 함수(input : model, output: image predict value)
2. 분류기
- 이렇게 분류된 이미지 쌍을 어떻게 비교할 것인가? ⇒ “어떤 함수를 쓸 것인가?”를 의미한다
- L1 distance를 이용하여 두 이미지 간에 거리(양적 표현 “456” 만큼 등) 차이를 확인한다
1) Neareset Neighbor
- 특징 : Simple, Data-driven Approach의 좋은 알고리즘
- Train step : 모든 학습 데이터를 기억한다
- Priedict Step : 새로 입력된 이미지와 기존 학습데이터를 비교 & 가장 유사한 이미지로 레이블링을 예측함
- Train set의 이미지 갯수가 N로 커진다면 Train/Test 함수의 속도는
Train Time < Predict Time형태로 상황 추론이 더 빨라야 한다 - 단점
- 초록색 점들 중간에 노란색 점이 끼어있음
- 파란점들 사이에 초록색 점이 끼어 있음 ⇒ 잡음(noise)이나 가짜가 많음.

💡 참고자료 : 시간복잡도
(1) k-NN
- NN의 조금 더 일반화(보완)된 버전
- Distance metric을 이용하여 가까운 이웃 k개 만큼 찾고, 이웃끼리 투표하는 방법
- 투표 방법 : 거리 별 가중치 등등
- 가장 많은 득표 수를 얻은 레이블로 예측한다
- K가 1보다 커지면 결정 경계(Decision Boundary)가 부드러워지고 좋은 결과를 보임
- k의 값을 높을 수록 각종 잡음(noise)에 조금 더 강인(Robust)해진다.
- 서로 다른 두 점을 어떻게 비교할 것인가? (= 어떤 거리 척도를 선택할 것인가?)
- L1 distance : 픽셀 간 차이 절대값의 합
- 좌표 시스템 종류에 따라 영향이 크다
- L2 (Euclidean) distance : 제곱합의 제곱근
+ 좌표계와 연관이 없다

- L1 distance : 픽셀 간 차이 절대값의 합
💡 참고자료 : K-Nearest Neighbors Demo
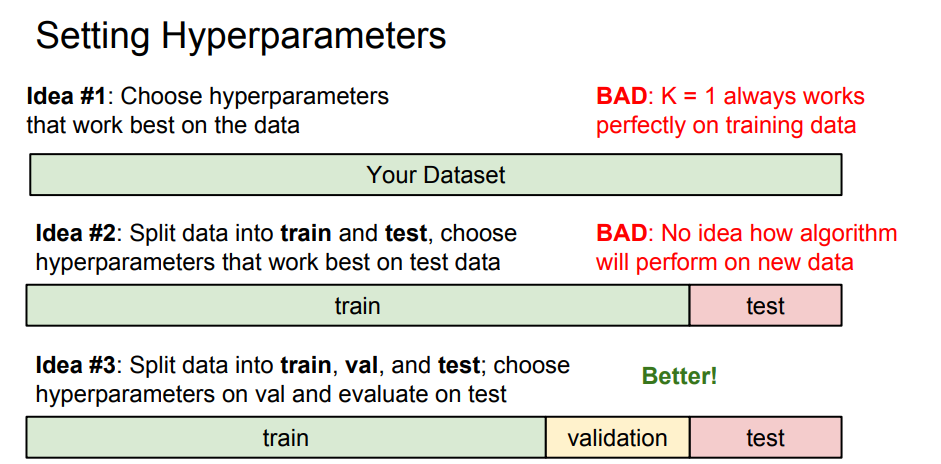
(2) 하이퍼 파라미터
- 어떻게 하면 “내 문제(problem)”와 “데이터(data)”에 꼭 맞는 모델을 찾을 수 있을 까?
- ex) k, 거리 척도 L1, L2
- 학습 전 사전에 선택해야 한다.
- 하이퍼 파라미터를 어떻게 정할까?
⇒ 문제의존적(problem-dependent)이다.
⇒ 데이터에 맞게 다양한 하이퍼 파라미터 값을 여러가지 시도해보고 가장 좋을 값을 찾는다.
- 하이퍼 파라미터를 찾는 방법
- ML system은 한번도 보지 못한 데이터에서 잘 동작해야된다.
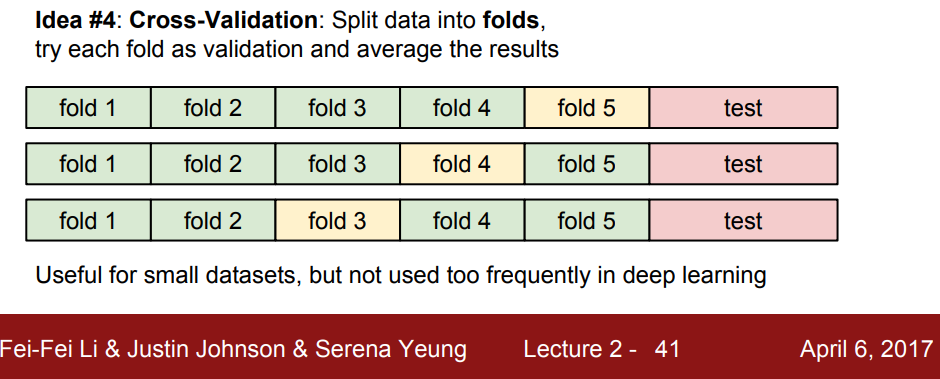
- 5(k)-Fold Cross Validation
⇒ 테스트 셋이 알고리즘 성능향상에 미치는 영향을 찾을 때 사용
- 4개의 fold에서 하이퍼 파라미터를 학습
- 남은 한 fold에서 알고리즘 평가
- 현실에서는 학습자체가 계산량이 많아 잘 쓰이진 않는다
- k-NN을 이미지 분석에 사용하지 않는 이유
- 너무 느리다
- 차원의 저주 : 데이터 용량이 커지면서 불필요한 샘플이 많아지는 것을 뜻한다
- 이미지 간 거리(유사도) 측정에 적절하지 않다(원본 vs 왜곡된 이미지)
2) Linear Classification
- NN과 CNN의 기반 알고리즘
- “parametric model”의 가장 단순한 형태이다
- parametric model 이란 : 파라메트릭 모델링(parametric modeling)의 본래의 뜻은 치수나 공식 같은 파라미터 (parameter = 매개변수)를 사용해 모델의 형상을 콘트롤하는 방식을 말합니다.
- 요소 : input image data X, parameter 또는 Weight W()
- 10개의 클래스 = 카테고리(비행기, 자동차, 고양이 등등) ????
- Training data의 정보를 요약한 것이 파라미터 W
- 장점 : 작은 디바이스에서 모델 동작할 때 효율적임
- parametric model 이란 : 파라메트릭 모델링(parametric modeling)의 본래의 뜻은 치수나 공식 같은 파라미터 (parameter = 매개변수)를 사용해 모델의 형상을 콘트롤하는 방식을 말합니다.
- 딥러닝은 함수f의 구조를 적절히 설계하는 일이다.
⇒ 어떤 식으로 가중치 W와 데이터를 조합할 것인가?
⇒ 이러한 조합 과정이 모두 NN 아키텍쳐를 설계하는 과정이다.- 아키텍쳐(architecture) 란?
- 컴퓨터를 기능 면에서 본 구성 방식이다.
- 아키텍쳐(architecture) 란?
-
계산방법
- wight와 bias 란(참고자료 : 머신러닝에서의 Bias와 Variance)
- 내적이란?
- 행렬들의 곱
- 내적을 통해서 클래스 간 템플릿의 유사도를 측정함
- 하단에 이미지 각각 클래스의 탬플릿
- linear classifier에서는 비행기를 찾을 때 푸르색을 띄는 것들을 찾는 것으로 보임
- wight와 bias 란(참고자료 : 머신러닝에서의 Bias와 Variance)
