지난 시간 리뷰
-
시그모이드는 0에서 1사이, 탄젠트h는 -1에서 0까지 움직인다. 시그모이드 계열(하이버볼릭탄젠트)함수가 적절한 경우가 있고, 렐루 계열의 활성화 함수가 적절한 경우가 있다. 각각의 장점이 있으니 상황에 따라 활성함수를 다르게 사용하자!
예를 들어 일반 휘발유차 토크 rpm, 디젤 rpm의 차이를 예를 들자. 일반적인 휘발유차는 rpm이 높아질수록 힘이 좋은데, 전기차는 제로백이 짱이야. 밟는대로 나감. 단수가 없다.(곡선이=플랫하다). 아무튼 각각의 장점이 있다는 것. -
최적화의 핵심 ! 경사하강법 : 산에서 눈을 감고 내려갈 방법을 모르는 상황. 그러면 어떻게 내려가나? 접선의 기울기(미분계수), 경사가 급한 쪽으로 내려가면 된다. 2D 상황에서 보면 아래 방향만으로 가기
단조 감소. 기울기가 지속적으로 내려가는 상황. 경사하강법은 기울기만 보고 어떻게 내려갈지 판단하는것! BUT 커브를 알 수 없다. 주식으로 치면 추세(하락)밖에 모르는거. local minimum 밖에 모르는 것이다. 그게 아니고 울퉁불퉁하게 내랴가면 모르겠지?
근데 뭘 최소화할건데?? = 손실 함수(loss function), 비용함수와는 다르다.
- 학습률(Learning rate) , 샘플링, 점 간의 간격을 학습률이라 하자. 샘플링 하는것 ?어느상황에서 기울기를 본다는건데. 샘플링의 간격을 학습률이라 하자. 러닝레이트를 적절하게 설정하자.
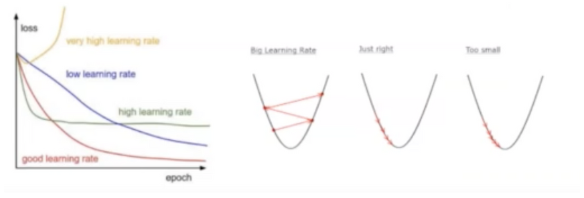
샘플링 간격을 줄이면 디테일한 커브는 할 수 있는데 한참 학습을 해야한다. 반대로 너무 대충하면 커브 모양을 못 따라 간다.
근데 어떻게 적절하게 할 것인데? 비용함수가 어떻게 움직이는지 봐야한다.
하지만. 학습(단조 감소)이 된다는 전제 하에서 러닝 레이트는 최대로 설정하는 것이 바람직하다. 계산이 빨리 되어야하니까 빨리빨리.-
옵티마이저 {경사(=손실함수)를 최소의 값을 가지도록 러닝 레이트를 지정하고, 여러 방법을 지정하기}
-
SGD(확률적) : 광우병, 100마리 중에서 광우병인놈 골라서 따지기. 직관과 다를 수 있음. 샘플은 100번 돌려봐야 하는데 초반에만 잘 해보고 나중에는 대충해도 됨. 그러나 통계적인 결과는 대부분 오차가 없긴하다.
-
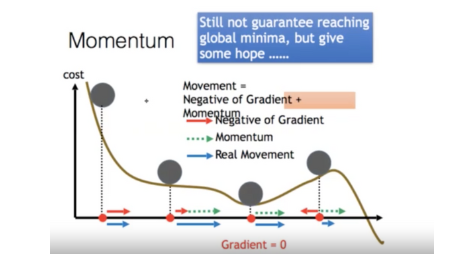
모멤텀(운동량) : 샘플링 속도를 고려하자. 관성을 예시로 든 것은, 산을 내려가는 길에 중간 중간 작은 턱이 있어도 어차피 산은 내리막길이니까 결국엔 도착하게 되어있다(공을 내리막길에서 굴리면 관성의 법칙 때문에 계속 내려감)
-
RMS Plop : 보폭 줄이기
-
Adam : 보폭과 운동량 둘 다 고려
import tensorflow as tf model = tf.keras.Sequential() model.add(tf.keras.layers.Dense(64, activation='relu')) model.add(tf.keras.layers.Dense(64, activation='relu')) model.add(tf.keras.layers.Dense(10, activation='softmax')) # 컴파일 model.compile(optimizer=tf.keras.optimizers.Adam(0.001), 케라스 코드가 텐서플로우 API인데, 케라스 코드를 텐서플로으로 컴파일 해라 loss='categorical_crossentropy', metrics=['accuracy']) 시간이 걸리더라도 최대한 정확한 쪽으로 할께~! # 모델 훈련(학습) model.fit(train_data, labels, epochs=10, batch_size=32) # 90% -> 만 개 데이터를 한 번에 하면 용량이 크니까 수백개 단위로 나뉘어 쪼개서 학습시키기 # 모델 평가 model.evaluate(test_data, labels) # 92%, 90%, 80% -> 과적합(Overfitting) # 샘플 예측 model.predict(new_sample)
-
-
이항분류 / 다항분류
- 이항분류 : 2개 값 중에서 선택
- 다항분류 : 여러 개 값 중에서 선택이항분류(0인가/1인가/9인가) ---> 일반화 ---> 다항분류(0-9에서 뭐자?) 다항분류 --> 특수화 --> 이항분류 - 텐서플로의 기본
거리의 기준
-"0"이라고 볼 수 있는 기준은?
- 이미지비교(KNN)
- 이항분류함수 0-255 / 128이상이면 1이다(이항분류)
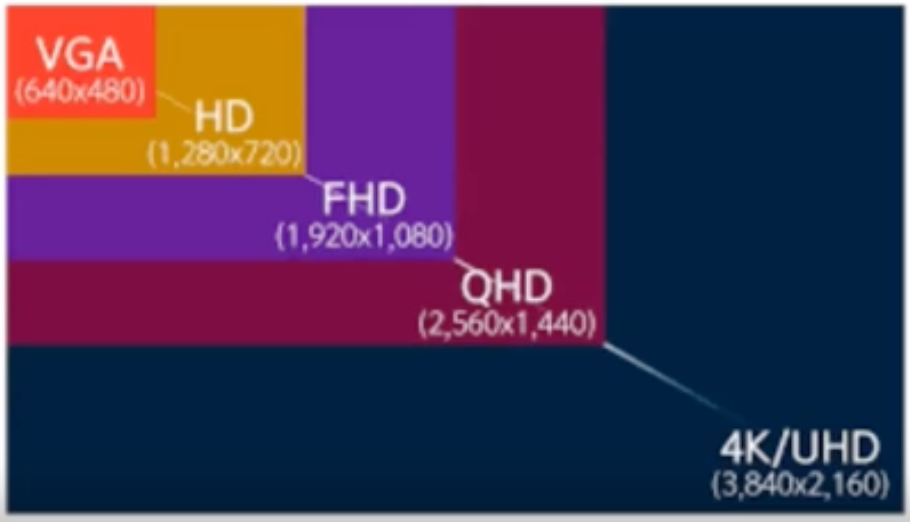
해상도와 해상수
-해상도(Resolution)
- 이미지/화면의 점의스
-해상수(color depth)
- 하나의점이 가지는 색상수
영상 / 음성 데이터 표현 방법
-한 비트(2진수 한자리)로 0/1 두 가지 정보 표현 가능
-두 비트로는?
- 00,01,10,11 4가지 정보 표현
-한자리가 추가 될 때마다 2배의 정보를 표현 가능
-정보표시 /구분 정밀도
- 정보 표시/구분 정밀도
- 8비트(1바이트)로는 256(2^8)가지의 정보 -> Grayscale
- 16비트(2바이트)로는 65536(2^16)가지의 정보
- 24비트(3바이트)로는 16,777,216(2^24)가지의 정보를 저장(True color/총 천연색)
- 30/36비트로는 10억개의 컬러를 표현(돌비 비전)
영상데이터 표현 방법
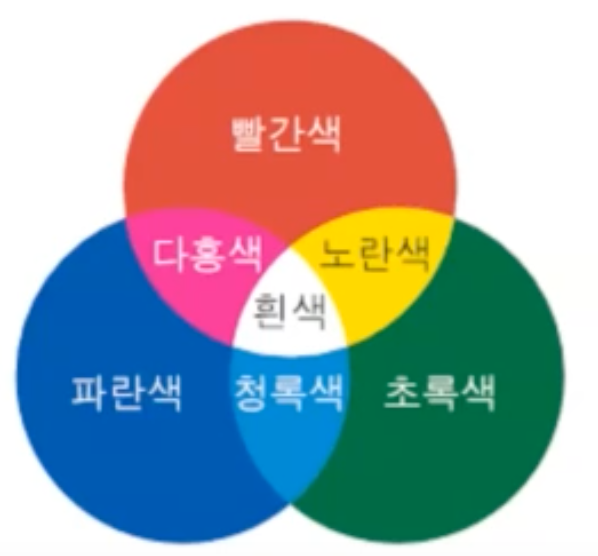
-“빛”의 삼원색 -> RGB
- 모두 합치면 흰색이 됨
-“색”의 삼원색 -> CYM
-
모두 합치면 검정색이 됨
-
한비트로는 0(검은색), 1(흰색)
-
00000000(가장 검은색) -> 11111111(가장 흰색)
- 8비트로는 총 256가지의 색상 표현(그레이 스케일) -
색상별 한 바이트씩 할당(8비트x3) - True color
-
색상별로 256단계의 색상강도 표현

가장 기본적인 칼라
이미지(영상) 데이터 거리 계산
-이미지 간의 거리
- 화면의 픽셀(점)의 컬러값의 차이를 계산(절대값)해서 모두 더한 값
2*2
192 98 32 0
56 24 65 90
|192-32| + |98-0| + |56-65| + |24-90| = 160+98+9+66 = 333
흑백이미지 기준으로 두 개의 이미자 간에 거리가 최소인 것은? = 0 (동일한 이미지를 계산하면 0이니깐)
최댓값의 의미 : 다른 이미지
최솟값의 의미 : 같은 이미지
-두 이미지의 차이가 작으면(비슷하면) 0에 가까와지고, 차이가 크면 값이 커진다
이미지에서 KNN 적용
-주어진 이미지 - 제일 비슷한 이미지 찾기(0~9)
- 10개의 이미지와의 거리 계산해서 제일 최소값을 가지는 이미지의 “인덱스”
- argmin cf. argmax
-MNIST기준으로 KNN => 90% 초반 정확도
과소적합/적합/과적합
-과소적합(Under-fitting)
- 선형회귀(Linear Regression)
- 구간 별로 다른 기울기
-적합(Just Fitting)
- 시그모이드
- 특이한 케이스를 설명가능함
-과(대)적합(Over-fitting)
- 신경망(딥러닝) -> 물량전이 가능
- 노드수/레이어수/...
투수의 컨디션이
적합 / 과적합 / 과소적합의 예
야구 - 타율(.300-강타자의 기준)
-> 전체시즌 / 월별타율 / 최근경기타율 / 특정투수상대타율 / 왼-오른쪽 투수 상대 /
구종별 타율
신경망은 과대적합에 취약하다!
Deep NN(Neural Network)의 특징
-임의의 모양의 패턴을 분류할 수 있슴
- 노드가 많을 수록,은닉계층이 많을 수록
-Overfitting가 잘나는 특징이 있슴
- 학습정확도 > 테스트정확도
- 방지기술이 발달함
- 학습정확도 = 테스트정확도
핵심 : 하이퍼 파라미터(신경망)
-(히든)레이어 수 / 노드수
-활성화함수(ReLU, Leaky ReLu, tanh, sigmoid, identity, maxout, ...)
-최적화(GD, SGD, …, Adam) + Learning Rate
-epoch(학습회수,전파/역전파)
-과적합(Overfitting) 방지기술
- DropOut/DropConnect
- 노드/레이어수 줄이기
- L1/L2 정규화
- 가중치 초기값 최적화
- Batch Normalization
@@@ 위의 과정들을 파이썬 코드로 루프로 몇 백 번씩 하면서 최적의 결과를 찾는 것이다.@@
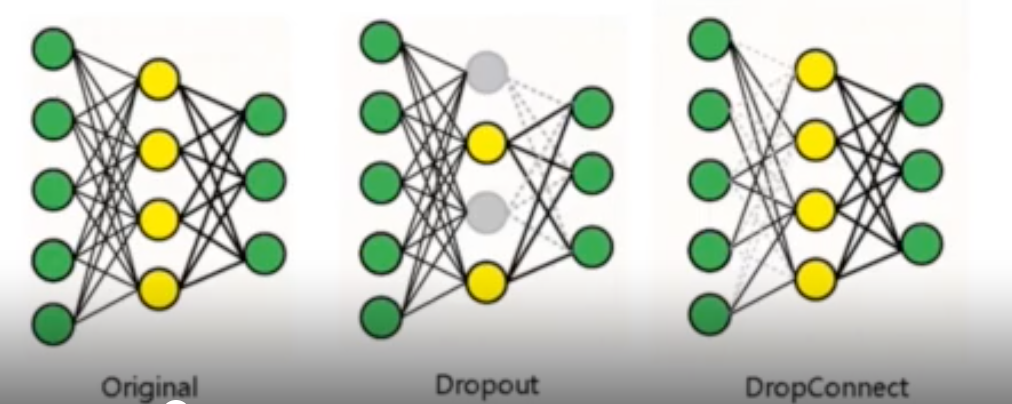
DropOut
-“Epoch”마다 일정 수의 노드를 랜덤하게 drop 시킨 후 학습시키는 방식
-전체중 dropout 비율지정
- 현대신경망(ReLU+CIFAR+DropOut)의 특징 -> 힌튼교수 그룹
-그러나 학습시간이 많이 걸림!