[논문 Review] Conversation Model Fine-Tuning for Classifying Client Utterances in Counseling Dialogues
논문 리뷰
 Conversation Model Fine-Tuning for Classifying Client Utterances in Counseling Dialogues
Conversation Model Fine-Tuning for Classifying Client Utterances in Counseling Dialogues
읽은 날짜: 2025년 3월 24일 ~ 3월 30일
- 논문 PDF
- NAACL (2019)
Abstract
-
텍스트 기반 온라인 상담 어플리케이션을 통해 상담사와 클라이언트는 상호작용 함
-
이 상호작용 데이터셋을 이용해 클라이언트의 발화를 분류하여 상담사가 클라이언트 상태를 진단하고 상담 결과를 예측하는 데 도움을 줄 수 있는 범주로 자동으로 분류하도록 학습하는데 사용
-
이 논문이 제시하는 ConvMFiT 모델은 아래 두 모델을 이용해 두 개의 역할 특정 언어 모델ㄹ 구성된 미리 훈련한 대화 모델이다.
- 도메인 외 코퍼스에서 구축된 일반 언어 모델
- 레이블이 없는 도메인 내 대화
Introduction
-
일부 정신 장애는 심리치료를 통해 효과적으로 치료되는 것으로 알려져 있다.
-
그러나 심리 치료가 필요한 사람들은 시간, 금전, 정서적 장벽 및 사회적 낙인 때문에 전통적인 상담 서비스를 방문하는데 어려움을 느낄 수 있다. (Bearse et al. 2013)
-
그래서 전문 상담사와 함께 하는 텍스트 기반 온라인 상담 서비스가 인기
-
그러나 온라인에서 상담사는 클라이언트의 비언어적 신호를 읽을 수 없고, 클라이언트는 자신의 생각과 감정을 전달하기 위해 구술이 아니라 문자 메세지를 사용한다.
-
이전 연구는 상담사 발화에 초점을 두었다면 이 논문은 클라이언트 발화에 초점
-
상담에서 클라이언트의 응답은 상담 결과를 판단하고 클라이언트의 상태를 이해하는 데 중요한 요소
-
범주화 체계는 CBT 이론을 기반으로 함
Categorization of Client Utterances
-
클라이언트 응답의 두 가지 특징
- 상담 세션 내내 변할 수 있는 클라리언트의 내부 상태를 이해하는 데 필수적인 단어를 제공
- 상담 결과를 예측하는 데에도 도움이 될 수 있음
-
이 논문의 최종 목표는 클라이언트 발화를 분류하기 위한 기계 학습 모델을 구축하는 것
-
대면 상담에서는 클라이언트 상담사 9개 범주와 상담사 언어적 응답 14개의 범주 제안 그러나 이 논문에서는 5개 범주로 연구 진행
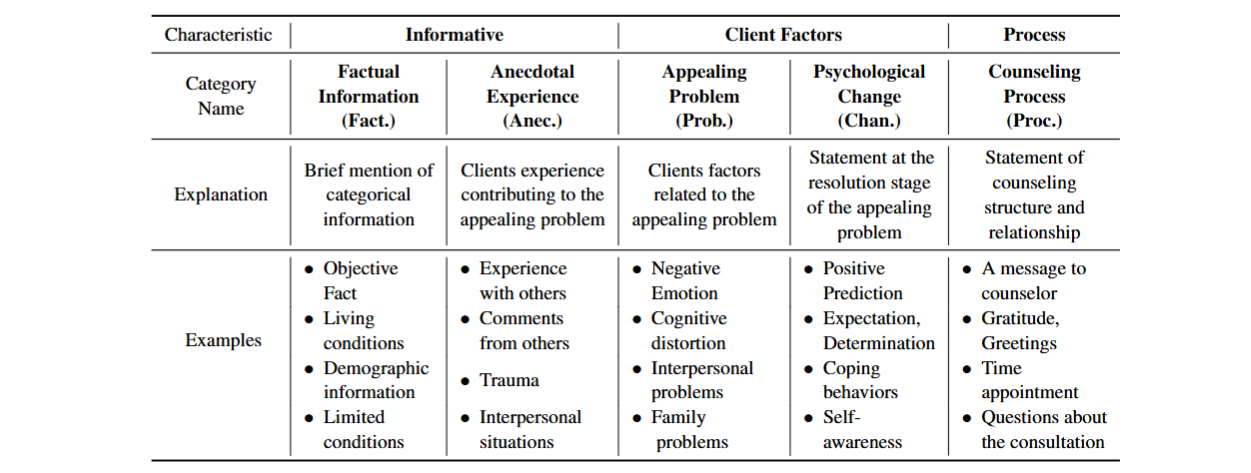
Table 1 : 클라이언트 발화의 최종 분류는 5가지의 카테고리
-
사실 정보(Factual Information)
상담자의 발화에 대한 정보적 응답으로 나이, 성별, 직업, 교육, 가족, 이전 상담 경험 등을 포함한다. -
일화적 경험(Anecdotal Experience)
매력적인 문제 형성과 관련된 과거 사건 및 현재 상황을 설명하는 응답이다. 응답에는 트라우마 경험, 다른 사람과의 상호작용, 다른 사람의 평과 기타 일화적 경험이 포함된다. -
매력적인 문제(Appealing Problem)
클라이언트의 내부 요인이나 문제와 관련된 행동을 포함하여 아직 해결되지 않은 주 매력적인 문제를 다루는 발화이다. 구체적으로 발화에는 인지, 감정, 생리적 반응 및 문제의 진단적 특징과 변화하고자 하는 욕구가 포함된다. -
심리적 변화(Psychological Change)
내부 요인이나 행동의 소규모 및 대규모 변화에 대한 통찰과 인지를 설명하는 발화이다. 매력적인 문제가 해결되고 있는 시점에서의 발화를 의미한다. -
상담 과정(Counseling Process)
상담의 목표, 상담자에 대한 요청, 상담 세션에 대한 계획 및 상담 관계를 포함하는 발화이다. 이 카테고리는 또한 인사 및 다음 세션 예약을 포함한다.
Dataset
Characteristics of Counseling Dialogues
-
상댐 대화는 상담자와 클라이언트 간의 여러 턴(Multi turn)으로 구성되며, 각 턴은 여러 발화를 포함한다.
-
일반 대화와 상댐 대화의 차이
- 발화자의 독특한 역할 : 상담 대화는 긍정적인 상담 결과를 도출하는 것을 목표
- 하나의 턴에 여러 개의 변화 : 모든 발화를 개별적으로 다룸
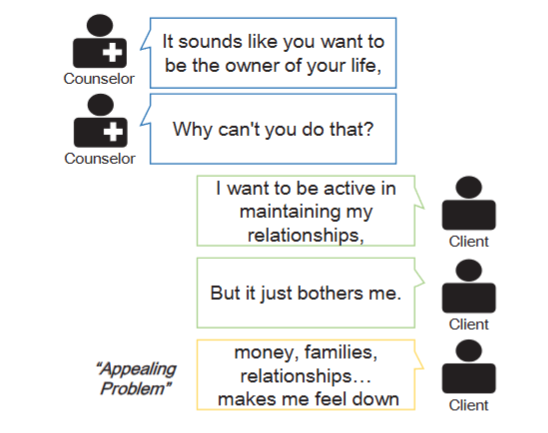 Fig 1. 상담사와 클라이언트 간의 번역된 예제 대화 : 각 턴은 여러개의 발화를 가질 수 있으며 클라이언트 턴을 발화 수준에서 주석을 달아줌
Fig 1. 상담사와 클라이언트 간의 번역된 예제 대화 : 각 턴은 여러개의 발화를 가질 수 있으며 클라이언트 턴을 발화 수준에서 주석을 달아줌
Collected Dataset
-
한국의 텍스트 기반 온라인 상담 플랫폼인 Trost에서 클라이언트와 해당 전문 상담 대화 수립
-
1,446개의 상댐 대화 사용, 개인 식별 정보를 제거함으로써 익명화
-
100개의 대화를 무작위로 선택해 전문 상담사가 대화에서 각 클라이언트의 발화만 다섯 카테고리로 주석을 달음
Preprocessing
-
구두점과 이모지를 의도적으로 남겨둠
-
상담사의 발화(Fig 1의 파란색), 클라이언트의 발화(초록색), 분류될 클라이언트의 목표 발화(노란색)를 구성
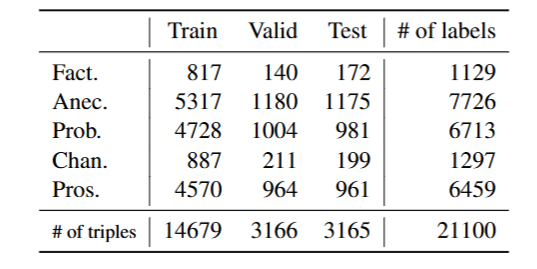 Table 3. 각 세트에 대한 삼중항 수와 해당 레이블
Table 3. 각 세트에 대한 삼중항 수와 해당 레이블
- 사실 정보(사실) 및 심리적(변화) 카테고리가 다른 카테고리보다 덜 빈번하게 나타남
Model
-
ConvMFiT를 소개하며, 이는 클라이언트의 발화를 분류하기 위해 미리 훈련된 seq2seq 기반 대화 모델을 미세 조정한다.
-
적은 레이블이 있는 데이터 세트에 사전 훈련된 언어 모델을 사용하면 효과적이다.
-
따라서 레이블이 없는 도메인 내 대화와 일반적으로 도메인 외에 있는 코퍼스에서 지식을 전달하는데 집중한다.
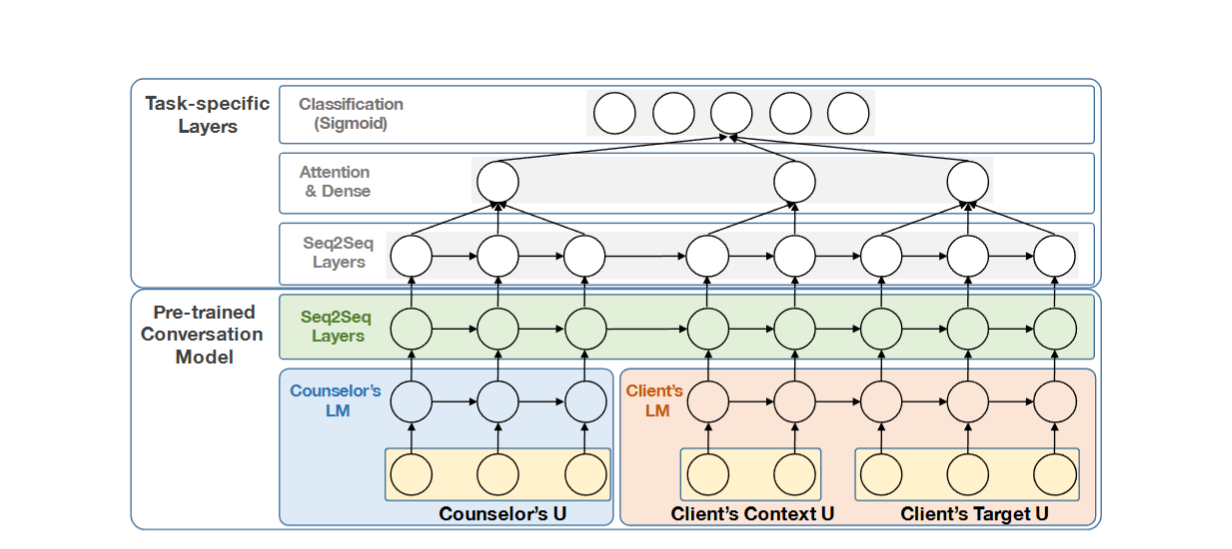
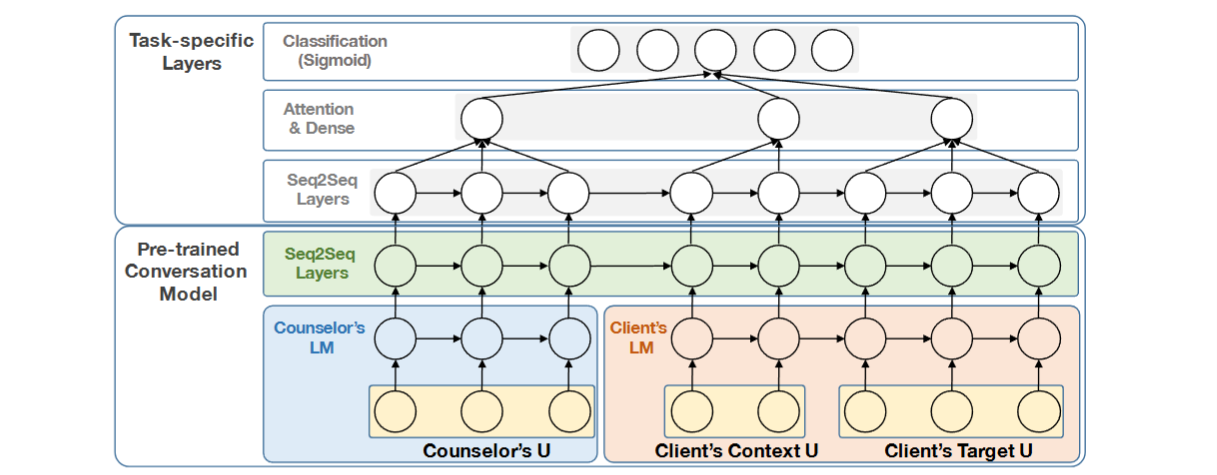 Fig 2. ConvMFiT 모델 아키텍처 : seq2seq 모델을 사용하여 사전 훈련된 대화 모델을 사용한다.
Fig 2. ConvMFiT 모델 아키텍처 : seq2seq 모델을 사용하여 사전 훈련된 대화 모델을 사용한다.
-
대화 모델을 나타내는 사전 훈련된 seq2seq 계층을 샇는다. (Fig 2. 초록색)
-
특정 작업 특화된 특징을 포착하기 위해 추가적인 seq2seq 계층과 분류 계층을 그 위에 쌓고 두 계층 사이에 attention-layer를 추가하여 모델의 해석 가능성을 높임 (Fig 2. Task-specific Layers)
-
이러한 방식은 전이 학습을 위한 언어 모델 기반 대화 모델 사용의 장점을 활용
-
ConvMFiT에서 모델이 두 개의 사전 훈련된 언어 모델, 즉 인코더와 디코더를 필요로 하는 사전 훈련된 seq2seq 대화 모델을 수용하여 seq2seq 계층에서 이들 간의 의존성을 학습
-
인코더에는 소스 언어 모델을 사용하고 디코더에는 목표 언어 모델을 적용
Model Components
- Word Vectors
- 한국어 텍스트의 형태학적 특징을 잘 반영하기 위해 개발된 단어 벡터 사용
- 한국의 위키피디아, 온라인 뉴스 기사, sejong corpus, 레이블이 없는 상담 대화와 같은 다양한 말뭉치에서 학습
- Pre-trained Language Models
- 상담사와 클라이언트의 역할 차이를 반영하기 위해 각각 다른 언어 모델을 학습
- Pre-trained Conversation Model
- seq2seq 모델을 기반으로 하여 사전 훈련된 상담사 언어 모델을 인코더로 클라이언트 언어 모델을 디코더로 사용하여 대화 모델을 학습
- 대화의 흐름과 맥락을 이해하고 이전 발화에 따른 다음 발화를 예측하는데 사용
- Task-specific Layers
- 사전 훈련된 언어 모델과 대화 모델을 활용하여 분류 작업을 수행하기 위해 추가적인 레이어를 쌓음
Model Training
모델을 세 단계로 훈련된다
1. 단어벡터와 두 언어 모델을 훈련
2. 사전 훈련된 언어 모델로 seq2seq 대화 모델을 훈련
3. 대화 모델의 소프트 맥스를 제거한 후 작업 특화 분류 레이어를 미세 조정
Experiences
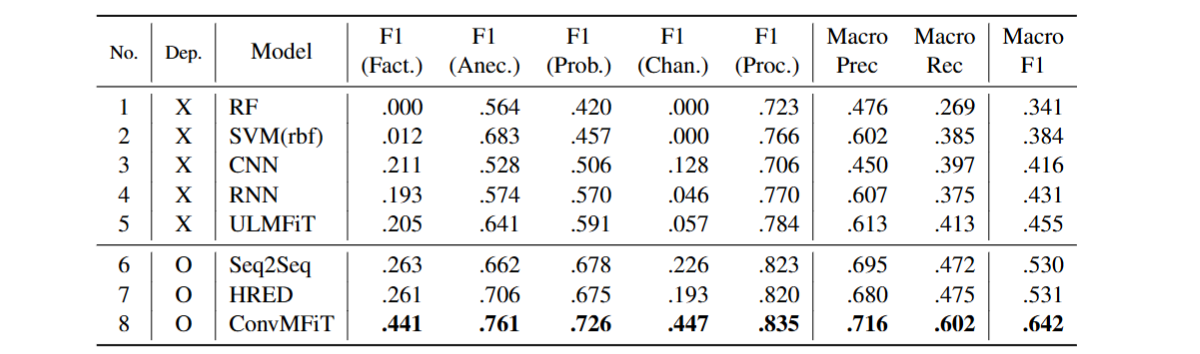 Table 4. 모델 별 분류 결과
Table 4. 모델 별 분류 결과
Results
-
사실 정보(Factual Information)
클라이언트는 인구 통계 정보와 상담사 방문에 대한 이전 경험을 제공한다. 경우에 따라 클라이언트는 상담의 동기에 대해 더 이야기한다. 이 정보는 상담 세션의 초기 단계에서 탐색되기 때문에 클라이언트 이름과 함께 상담사의 인사도 찾아낸다. -
일화적 경험(Anecdotal Experience)
클라이언트는 과거 시제를 사용하여 자신의 경험을 설명한다. 일반적으로 발언에는 '내가 생각했던 것', '나는 완전히 틀렸다' 등의 구문이 포함된다. 상담사는 간단한 반응을 나타낸다. -
매력적인 문제(Appealing Problem)
일화적 경험과 같이 클라이언트는 문제를 설명하지만 현재 시제를 사용한다. 클라이언트 자신의 생각과 감정을 호소한다. 상담사 또한 간단한 반응을 보인다. 상담 세션이 시작된 직후 일부 클라이언트는 즉시 문제를 쏟아내기 때문에 상담사의 인사가 주요 구문에 나타난다. -
심리적 변화(Psychological Change)
클라이언트는 자신의 감정이나 생각의 변화를 뚜렷하게 보고한다. 이는 과거를 돌아보고 미래에 변화를 결심하는 것으로 본다. 상담사는 지지하는 반응과 공감 이해를 제공한다. -
상담 과정(Counseling Process)
클라이언트와 상담자는 서로 인사를 나눈다. 또한 그들은 다음 세션을 위한 예약에 대해 논의한다. 경우에 따라 상담자는 클라이언트의 질문에 답변한다.
Conclusions
모델 ConvMFiT가 무수한 성능을 보이며, 이는 사전 훈련된 모델에서 지식을 전이 했기 때문이다. 각 범주에 대한 상담자와 클라이언트의 전형적인 언어 패턴을 탐색하고 보여준다.
