머신 러닝 과제
💡알게 된것
✔ from sklearn.model_selection import train_test_split
- 데이터를 트레이닝 데이터와 테스터 데이터로 분류해주는 함수
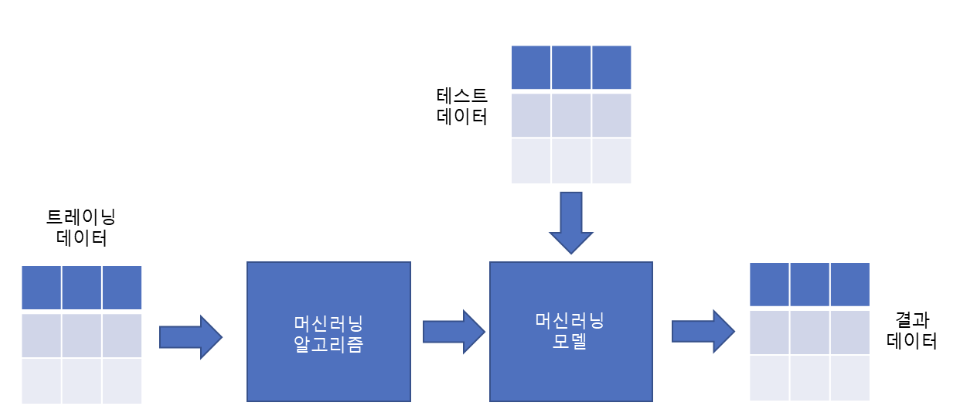
- performance의 결과를 0~1사이 수치로 알려줌
- 데이터 분류 비율은 일반적으로 8:2, 7:3정도의 비율로 나눔
- 구조
train_test_split(X,y, test_size=, random_state=)
X,y는 변수 값을 의미
test_size는 트레이닝과 테스트 데이터와 비율을 결정함.
random_state에 값을 입력하지 않으면 랜덤한 선택으로 데이터 값을 분류, 특정수로 결정하면 Seed 값이 동일해서 동일한 방식으로 데이터를 분류함. ✔ from sklearn.ensemble import RandomForestClassifier
- 개별 나무를 성장할 때 분리마다 랜덤으로 변수후보를 선택하고 이를 통해 개별 나무간 상관성을 줄여준다. 개별나무간 상관성이 작은 경우 랜덤 포레스트의 예측력이 올라간다.
(# 배깅은 붓스트랩 샘플링을 이용하여 주어진 하나의 데이터로 학습된 예측 모형보다 더 좋은 모형을 만들 수 있는 앙상블 기법)
✔ from sklearn.metrics import accuracy_score
- 정확도 : 실제 데이터에서 예측 데이터가 얼마나 같은지를 판단하는 지표
- 예측 결과가 동일한 데이터 건수 / 전체 예측 데이터 건수
- 직관적으로 모델 예측 성능을 나타내는 평가 지표
- 불균형한 Label data set에서는 사용 불가
✔ from sklearn.impute import SimpleImputer
- column의 결측치를 각 column의 평균값,중간값, 최빈값 혹은 상수값으로 채우는 결측치 처리법
✔ from sklearn.preprocessing import LabelEncoder
- 데이터 전처리를 위한 함수
- 범주형 데이터로 변환

차근차근 열심히 따라가보는 왕초보의 기록들!