JPA를 통해 실행한 조회 쿼리의 성능을 개선한 경험을 이야기합니다. JPA에서 발생할 수 있는 N+1 문제와 Fetch Join과 Limit을 함께 사용했을 때 발생할 수 있는 문제에 대한 해결 방법을 포함하고 있습니다.
🖥️ 이 포스트는 Directors 프로젝트 진행 중 작성되었습니다. 진행 중인 프로젝트를 보고 싶으시다면 => Directors
기존 프로젝트의 프론트엔드 코드를 작성 중에 있습니다.
그러던 중, 특정 엔티티의 목록을 조회하는 화면에서 렌더링 속도가 느린 문제를 발견했습니다.
문제: 너무 긴 API Latency
그래서 원인을 파악하기 위해서, 아래처럼 user 테이블에 대해 다른 조건은 다 빼고 offset: 0과 limit: 20만 매개변수로 준 상태에서 쿼리 로직을 실행해 보았습니다. 그런데도 200ms가 넘는 latency이 발생하는 것이었습니다!
무언가 잘못된 것 같습니다..! 해당 로직에 대한 하이버네이트의 쿼리 실행 계획을 확인해보았습니다.
엔티티의 FetchType으로 발생한 N+1 문제
그렇습니다. User 내부에서 Region이라고 하는 다른 엔티티를 FetchType.Eager로 참조하고 있던 것이 문제가 되었던 것이었습니다.
User 엔티티와 연관된 Region 엔티티를 FetchType.EAGER로 설정한 것이 이 문제의 주 원인이었습니다. 즉, User 엔티티를 조회한 후에 FetchType.EAGER 설정에 따라 User의 수만큼 Region 엔티티도 추가로 조회하게 되는, 말 그대로 N+1 문제가 발생했던 것입니다.
단순히 하나의 User 엔티티를 조회해오고 나서 연관된 하나의 Region 엔티티를 추가로 조회하는 것이라면 큰 문제가 되지 않을 수도 있지만, 이 경우 최대 20개의 User 엔티티에 대한 Region을 추가로 조회해오는 것이기 때문에 문제가 되었습니다. 한 번의 API 요청으로, 최대 21의 쿼리가 발생할 수 있었습니다.
사실 이 API의 비지니스 요구사항에서는 region의 값을 요구하고 있지도 않았고, 애플리케이션 전체적으로 살펴보았을 때도 User 엔티티와 함께 참조될 횟수가 적을 것이라고 판단되었으므로 User의 Region에 대한 FetchType을 FetchType.Lazy로 변경했습니다.



이후 실행 결과 하이버네이트도 하나의 쿼리만으로 로직을 수행하게 되고, API Latency도 확실히 개선된 것을 확인할 수 있었습니다.
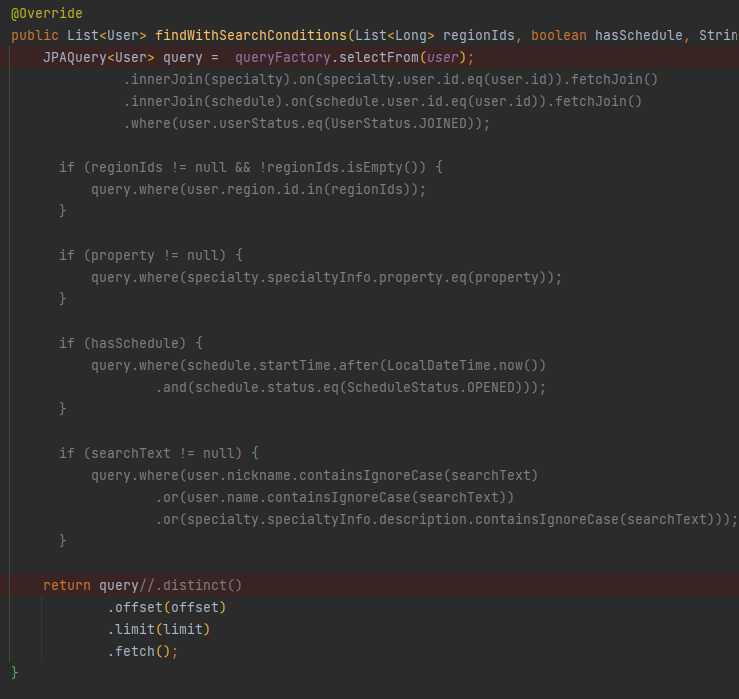
Fetch Join과 Limit를 함께 사용했을 때의 문제
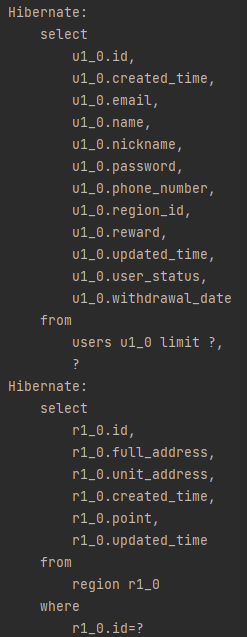
하나의 문제는 해결되었다고 판단했으므로, 기존의 쿼리를 다시 사용하여 동일한 API를 조회해보았습니다. 그 결과 다음과 같은 로그 메시지가 콘솔에 올라왔고, 결과를 받기 까지는 19초 정도의 Latency가 소요되는 것을 확인했습니다.

(firstresult/maxresults specified with collection fetch applying in memory hibernate 라는 내용의 로그입니다)
시간도 시간이고, 쿼리 결과도 제대로 나오지 않았습니다.
블로그 글을 통한 문제 접근
다행히 검색을 통해 같은 문제를 만난 블로그 글을 찾을 수 있었습니다. 블로그의 내용을 정리하면 다음과 같습니다.
-
Jpa는 DB에 따라 방언을 바꾸어 쿼리를 생성하므로, MySQL 방언에 속하는 LIMIT 절을 JPQL에서 직접 사용할 수 없다. 그리고 setFirstResult() 와 setMaxResults() 를 이용해서 pagination을 수행한다.
-
QueryDSL을 사용하는 경우 pagination을 위해 offset 과 limit 절을 사용하게 되는데, 이는 위의 setFirstResult(), setMaxResults()에 사용된다. (offset → setFirstResult, limit → setMaxResults)
-
문제는 fetch join 상황에서 limit를 사용할 때 발생한다. 쿼리 결과를 전부 메모리에 적재한 뒤 Pagination 작업을 어플리케이션 레벨에서 하게 된다. 이는 하이버네이트 내의 QueryTranslatorImpl가 fetch join 사용 시, limit를 쿼리 조회 시 사용하지 않고, 애플리케이션으로 가져왔을 때 적용하기 때문이다.
-
추가로 조회 내용을 카티시안 곱으로 가져오기 때문에, 기존 쿼리가 원하는 방향으로 결과가 나오지 않을 수도 있다.
- 하이버 네이트 문서
Fetch는 setMaxResults() 또는 setFirstResult()와 함께 사용해야 합니다. 이러한 작업은 일반적으로 즉시 컬렉션 가져오기를 위한 중복 항목을 포함하는 결과 행을 기반으로 하므로 행 수가 예상한 것과 다릅니다.
- 하이버 네이트 문서
-
결과적으로 이 블로그에서는 조회의 방향을 반대로 전환함으로써 원하는 결과를 얻어오는데 성공했다.
블로그 내용을 통해 제 코드에 있었던 문제와 해결책을 파악할 수 있었습니다.
DB에서 LIMIT 처리되지 않은 대량의 데이터를 조회하여 (그것도 카타시안 곱으로) 애플리케이션 단에 올리고, 거기서 limit을 수행하여 데이터를 가져오려고 했으니 시간이 많이 걸릴 수밖에 없었던 것입니다.
어플리케이션 레벨에서의 대량 DB 조회 내용 적재를 막기 위해 fetch절과 limit절을 분리해야 한다는 것은 확실해졌습니다.
한편, 이 API의 비즈니스 목적상, User 엔티티와 연관되는 2개의 엔티티(Specialty, Schedule)를 조회해야 했기에 위 블로그의 방법을 사용할 수는 없다고 생각되었습니다.
여기까지의 살펴본 문제의 핵심과 해결해나갈 방향을 다음의 2가지로 정리해보았습니다.
- 메모리 비용
- 해결 방향: 애플리케이션 단에 조회된 DB 데이터가 적재됨으로 인해 메모리 과부하가 발생해서는 안됩니다. 이는 db 단에서 해결되어야 하는 문제입니다.
- 네트워크 비용
- 해결 방향: 가능한 적은 수의 쿼리를 통해 문제가 해결되어야 합니다. 이전의 1:N 문제가 반복되어서는 안됩니다.
2번의 쿼리를 사용한 문제 해결
이를 위해서 여러 방법을 찾아보았습니다. nativeQuery와 DTO 객체를 결합해보기도 하고, 쿼리를 이리저리 바꾸어 보면서 테스트해보기도 했습니다. (생각보다 시간이 많이 걸렸습니다..)
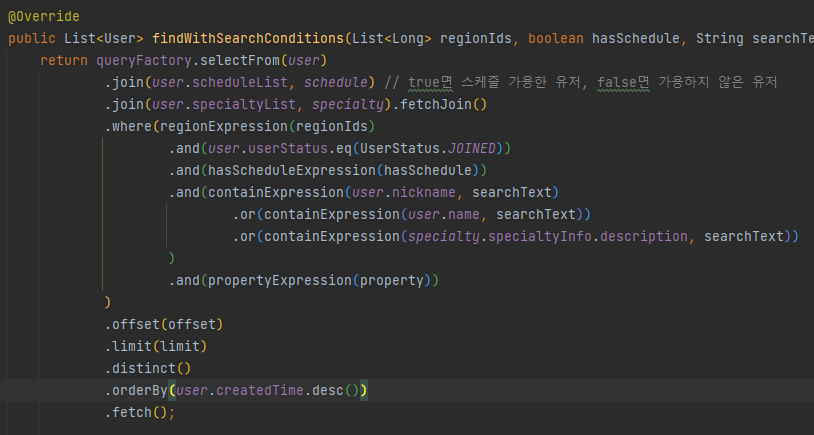
결론적으로 선택한 방법은 2개의 쿼리를 사용하는 방법이었습니다. 이는 다음의 순서를 따르는 두 쿼리입니다.
- Join, Where, limit 절을 통해 검색 조건에 맞추어 조회될 User의 Id 목록을 조회합니다.
- 조회된 User Id 목록을 통해 User 엔티티를 Fetch join 합니다.
1개의 쿼리로 해결되지는 않았던 점은 아쉬웠으나, 이는 문제를 해결하는데 효과적이었다고 생각됩니다.
- Limit절과 Fetch Join 절을 분리함으로써 애플리케이션 단에 카타시안 곱의 내용이 적재되는 것을 막았고,
- 가능한 적은 양의 데이터를 쿼리할 수 있었기 때문입니다.
아래는 실제 적용한 쿼리 내용입니다.
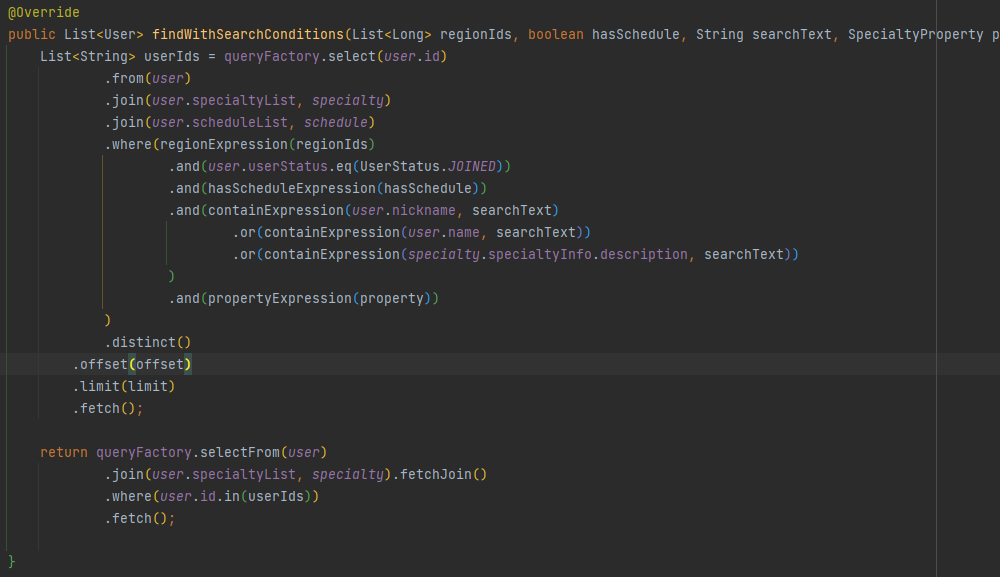
변경된 내용을 적용한 후 API의 Latency는 기존 20s 이상의 속도에서, 60-70ms의 속도로 대폭 향상되었습니다. 또한 이전에 발생했던 애플리케이션 메모리 과부하 문제도 발생하지 않았습니다.
결론
오늘 다룬 문제들은 JPA의 작동 방식을 이해함으로써 해결할 수 있는 문제였습니다.
구체적으로는 FetchType에 따라 달라지는 JPA의 작동 방식, 그리고 Fetch Join과 Limit를 동시에 사용할 때 수행되는 JPA의 작동 방식을 이해하면서 문제를 해결해나갈 수 있었습니다.
한편 기존에 하나의 쿼리로 해결하지 못했던 문제를 오히려 2개의 쿼리를 통해 더 나은 성능을 발휘하도록 한 것은 새로운 경험이었습니다. 단순히 쿼리 수를 줄이는 것만이 능사는 아니구나.. 라는 생각을 하게 되었습니다.
과정은 쉽지 않았지만, 개선된 성능에 기쁩니다. 그리고 JPA에 대해 트러블 슈팅을 하면서, JPA에 대해 자신감이 조금씩 생겨나는 것 같아 좋습니다. 역시 경험만한 스승이 없다라고 느껴집니다..
화이팅!
참고
