
MySQL에서 공간 타입의 데이터를 인덱싱하는 방법과, 이를 활용할 수 있는 전용 쿼리를 프로젝트에 적용해본 경험을 이야기합니다.
🖥️ 이 포스트는 Directors 프로젝트 진행 중 작성되었습니다. 진행 중인 프로젝트를 보고 싶으시다면 => Directors
프로젝트 진행 중 검색 기능을 만들게 되었습니다.
여러 조건 파라미터를 통해 검색을 수행하게 되는데, 검색에 대한 Latency가 어느 정도 나오는지를 확인해보고 개선하기 위해 Postman을 통해 간단하게 테스트해보았습니다.
- Stress test를 거치기 전에 먼저 Latency test를 수행하는 이유는 무엇인가요?
Latency test를 통해 초기에 빠르게 결과를 확인하고 성능 저하 요소를 파악하기 위해서입니다. 이러한 테스트는 성능 개선을 위해 개선 가능한 부분을 우선적으로 다루는 것을 목표로 합니다. 이를 통해 개선할 수 있는 요소를 해결한 다음, Stress test를 진행할 예정입니다.
📌테스트 환경
테스트 환경은 로컬 환경(노트북)과 클라우드 환경(Naver Cloud VPC)의 2개로 구성했고, 대략적인 구성은 아래와 같습니다. 로컬에 1000명, 클라우드 서버에 10만 명의 user를 상정하고, 이에 대한 test data를 db에 세팅했습니다.
- Insert된 table 별 데이터의 숫자가 다른 이유는 무엇인가요?
이는 의미 있는 테스트 데이터를 만들기 위한 과정에서 비롯된 것인데요, 이 과정은 별도의 포스트를 통해 다루겠습니다.
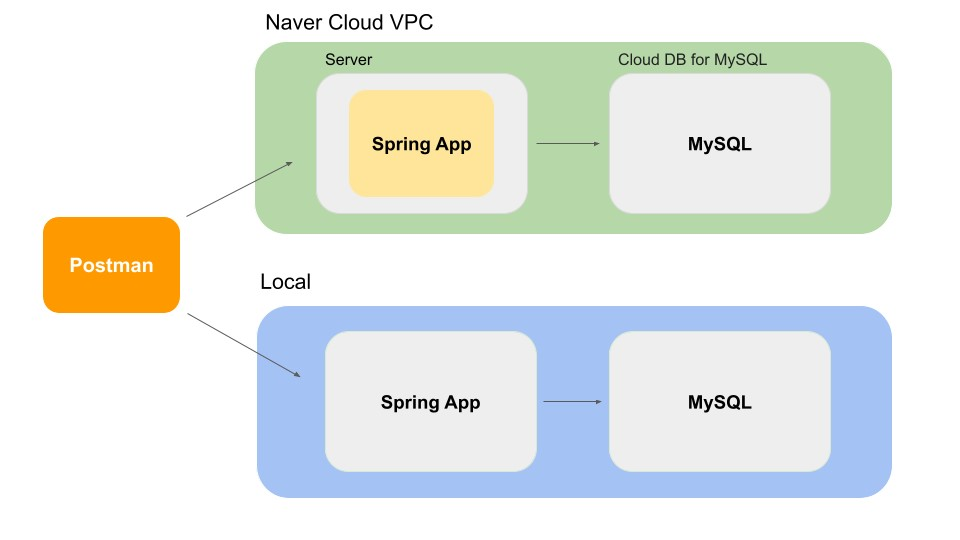
1) Local (노트북)
-
Spring Application
- Windows 11
- Memory 20GB
- Open JDK 17
- Windows 11
-
MySQL DB
- version: 8.0.32
- Insert Data
Table Name Count Users 1,000 Specialty 1,500 Schedule 33,000 Question 5,000 Region 21541
2) Naver Cloud Platform (VPC)
-
Spring Application
- Ubuntu 20.04
- vCPU 2EA, Memory 8GB
- Open JDK 17
- Ubuntu 20.04
-
Mysql Cloud DB Server
- version: 8.0.25
- Insert Data
Table Name Count Users 100,000 Specialty 150,000 Schedule 3300,000 Question 500,000 Region 21541
테스트 기준
위 그림처럼 따로 정적 파일을 서빙하는 웹 서버를 두지 않고 API 서버의 단일 API에 대한 Latency만 측정하는 것이기 때문에, 이에 대한 Latency가 어느 정도 나오면 되는지를 정하도록 했습니다.
일반적으로 알려져 있는 3초 법칙에 따라 생각해보겠습니다. static web server + web application server + db server의 3 tier로 서비스가 구성되어 있다고 생각했을 때, 조금 러프하게 생각해서 이는 한 tier 당 1초씩으로 계산해볼 수 있습니다. 그렇다면 was와 db 서버가 연동되는 이 테스트는, 2초 이내의 Latency를 반납했을 경우 적절하다고 볼 수 있습니다. 그러나 실제 상황에서는 여러 동시 요청의 가능성이 있으므로, 1/10인 0.2초로 최대 Latency를 가정하고 테스트를 진행하겠습니다.
- 추가로 vUser, rps와 같은 단위를 통한 작업은 이후 Stress test에서 진행하고, 여기서는 단순히 latency 수치를 통해 테스트를 수행하도록 하겠습니다.
테스트 수행
1) Local
-
Request Url
-
Request Data
-
Header
- Auth token 추가
- User Id가 charlotte000684인 유저 로그인 시 반환되는 인증 토큰 추가.
- Authorization: Bearer {{ Auth_token }}
- Auth token 추가
-
Body
Key Value distance 5 searchText "작업” property "디자인” hasSchedule true page 1 size 10
-
-
Result
Round Latency (ms) 1 285 2 285 3 253 4 276 5 242 6 286 7 239 8 266 9 254 10 283
- Average
- 266.9 (ms)
2) Naver Cloud Platform
-
Request Url
-
Request Data
-
Header
- Auth token 추가
- User Id가 abigail025109인 유저가 로그인 시 반환되는 인증 토큰 추가.
- Authorization: Bearer {{ Auth_token }}
- Auth token 추가
-
Body
Key Value distance 5 searchText "작업” property "디자인” hasSchedule true page 1 size 10
-
-
Result
Round Latency (ms) 1 1352 2 653 3 703 4 703 5 730 6 648 7 723 8 599 9 639 10 605 -
Average
- 735.5 (ms)
테스트 결과
- 두 테스트 결과 모두 목표했던 200(ms)를 넘어서는 큰 Latency를 보여주고 있습니다. 병목 지점을 찾아 개선하는 것이 필요해보입니다.
- 한편 두 환경 사이의 차이가 확연한데, 이는 각 DB에서 가지고 있는 데이터 양의 차이 때문인 것으로 추정됩니다.
성능 개선하기
Latency 요인 분석
-
주된 원인
-
로컬 환경에서 IDE를 통한 디버깅을 통해서, 사용자의 위치 데이터를 통해 주변의 지역을 검색하는 로직에서 전체 Latency의 약 80%가 소요되는 것을 확인했습니다. 다만 로컬 DB와 연동하여 디버깅했기 때문에 클라우드 환경에 비해 상대적으로 데이터가 많은 지역 데이터의 Latency가 크게 다가온 측면도 있습니다.
-
그러나 지역 데이터의 조회 성능에 개선이 필요한 것은 분명하므로, 지역 데이터 조회를 중심으로 문제를 분석해보도록 하겠습니다.
-
-
기존 성능 확인
-
아래 코드는 디버깅으로 찾아낸 Latency가 발생하는 코드입니다.
JPA의 @Query 어노테이션을 통해 특정 좌표 근처의 지역을 DB로부터 조회하고 있습니다.
이를 DB 콘솔을 통해 직접 로컬 DB에 쿼리하여 실제 실행 소요 시간을 확인하고, 반복하여 평균적인 Latency를 측정해보았습니다.

-
Test
-
사용된 데이터
Key Value 좌표(UTM-K 기준) 청담동 행정 센터 좌표로부터의 거리 5000 -
Result
Round Latency (ms) 1 777 2 752 3 761 4 717 5 683 6 816 7 693 8 726 9 648 10 671 -
Average
- 724.4 (ms)
- 724.4 (ms)
DB 쿼리만으로 약 700(ms)가 넘는 평균 Latency가 나왔습니다.
추가로, 실행 계획을 통해 인덱스가 적용이 되었는지 확인해 보겠습니다.


type의 값이 ALL 이고, key가 null인 것을 확인했습니다. 현재 쿼리에서는 인덱스가 적용되지 않고 있습니다.
빠른 조회를 위해, 우선적으로는 인덱스를 생성하여 사용하는 것이 필요해보입니다.
그러나 MySQL에서 공간 데이터 타입을 저장했을 경우, 일반 인덱싱 방법으로는 해당 컬럼에 인덱스를 적용할 수 없습니다. 여기서는 R-Tree라는 인덱싱 방식이 적용된 Spatial Index를 적용해야 하는데요, 아래에서 공간 데이터와 관련된 MySQL의 인덱스 방식에 대해 간단히 살펴보았습니다.
-
-
-
MySQL의 공간 인덱스(Spatial Index), R-Tree Index 살펴보기
-
MySQL은 공간 정보의 저장 및 검색을 위해 다음의 세 가지를 제공합니다.
- 공간 데이터를 저장할 수 있는 데이터 타입
- 공간 데이터 검색을 위한 공간 인덱스
- 공간 데이터의 연산 함수
-
MBR(Minimum Bounding Rectangle, 최소 경계 상자)
특별히 MySQL에서 공간 정보를 인덱싱할 때는, MBR이라는 개념을 사용하여 인덱싱을 수행하게 됩니다.
MBR이란, 말 그대로 공간을 나타내는 도형을 감싸는 가장 작은 크기의 사각형을 말합니다.
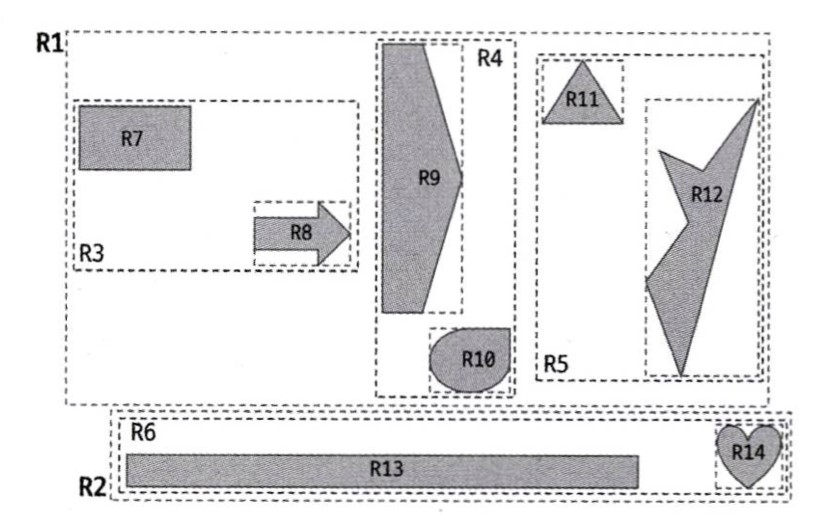
위 사진은 책 Real Mysql에서 MySQL의 공간 인덱스 개념을 도식화한 모습입니다. 공간을 나타낸 R~ 도형의 모양은 여러 가지이지만, 모두 MBR로 처리되어 인덱싱 처리됩니다.
각 MBR은 인덱스의 노드가 되며, 다른 MBR을 포함하는 상위 MBR일수록 상위 노드로 사용됩니다.
-
🙋그렇다면 이 R-Tree 인덱스를 적용하면 기존 쿼리의 성능을 개선할 수 있을까요?
그렇지 않습니다. 기존에 애플리케이션에서 사용하고 있던 공간 함수인 ST_Distance는 두 지점 간의 거리를 계산하기 위한 비교 연산을 수행하는 함수입니다. 따라서 DB에 저장된 모든 공간 데이터 칼럼과 Input으로 주어지는 공간 데이터 칼럼을 Full로 연산하게 되므로, R-Tree 인덱스의 효과를 활용하기는 어렵다고 볼 수 있습니다. 현재(MySQL 8)로써는 MySQL이 ST_Distance에 대한 인덱싱 처리를 지원해주고 있지 않기 때문입니다.R-Tree는 MBR의 포함 관계를 이용해서 만들어진 인덱스이므로, ST_Contains() 또는 ST_Within() 등과 같은 포함 관계를 비교하는 함수로 검색을 수행하는 경우에만 인덱스를 사용하게 됩니다.
따라서 공간 데이터에 대해 인덱싱을 적용하고 이를 활용하고 싶다면, ST_Contains() 또는 ST_Within() 함수와 같은 공간 데이터의 범위 쿼리에 관련된 연산을 수행하는 함수를 사용하는 것이 적합해보입니다.
자 그럼, 위 내용들을 바탕으로 지역 검색 쿼리 성능을 개선해보겠습니다.
범위 검색 쿼리의 성능 개선 과정
1) 새로운 DDL 작성하기
-
변경 계획
# 기존 테이블 생성 DDL CREATE TABLE region ( id bigint PRIMARY KEY AUTO_INCREMENT, created_time datetime(6), updated_time datetime(6), full_address varchar(50), unit_address varchar(10), geometry point NOT NULL ); # 변경 테이블 생성 DDL CREATE TABLE region ( id bigint PRIMARY KEY AUTO_INCREMENT, created_time datetime(6), updated_time datetime(6), full_address varchar(50), unit_address varchar(10), point point NOT NULL SRID 5179, SPATIAL INDEX(point) );변경 계획을 순서대로 하나씩 살펴보겠습니다.
-
공간 데이터 컬럼의 타입 변경: Geometry → Point
기존 point 컬럼을 통해 저장된 데이터는 단일 위치를 좌표로 나타내는 좌표 데이터였습니다. 그에 반해 컬럼의 데이터 타입인 Geometry는 다양한 공간 데이터(Polygon, Line, Point, ..etc )를 표현할 수 있는 범용적 타입이었습니다.
해당 컬럼에는 단일 위치의 좌표 이상의 데이터를 담지 않을 것이기 때문에, 확실히 컬럼의 데이터를 표현할 수 있는 Point 타입을 사용하도록 했습니다 -
SRID 적용
기존에는 없던 SRID라는 것이 등장했습니다.point point NOT NULL SRID 5179SRID는 Spatial Reference Identifier의 약자로, 평면 지구 매핑 또는 둥근 지구 매핑에 사용되는 특정 타원면을 기준으로 하는 공간 참조 시스템을 뜻합니다. 쉽게 말해 좌표 체계라고 할 수 있습니다.
대표적인 SRID로는 GPS의 기준이 되는 WGS84 시스템을 적용한 4326, 한국의 지리적 특성에 적합하도록 개발된 좌표계인 UTM-K를 적용한 5179가 있습니다. SRID를 적용하지 않았을 때는 기본 값인 0이 SRID에 할당되며, 이는 단순 직교 좌표계가 적용된 것을 의미합니다.
단순 직교 좌표계의 경우에는 R-Tree 인덱스의 혜택을 받기 어려우므로, 인덱스 적용을 위해서는 반드시 입력 데이터에 적합한 SRID를 적용해야만 합니다.
SRID는 테이블에서 컬럼의 속성으로 값을 주거나, Insert 쿼리를 통해 데이터를 입력할 때 데이터와 함께 줄 수 있습니다. 여기서는 기존에 사용하던 지역 데이터의 좌표 체계인 UTM-K 적용된 5179로 지정한 것을 확인할 수 있습니다.
-
SRID 적용 시 주의할 점
SRID를 적용하고 나서는(기본 값으로 주어지는 0도 포함), DB에 새로운 공간 데이터를 Insert하거나 이미 저장된 공간 데이터를 Input으로 주어지는 공간 데이터 기반으로 조회할 때 반드시 SRID를 고려해야 합니다.

위의 사진에서는 DB 컬럼의 SRID가 5179일 때, Input 공간 데이터의 SRID를 0으로 명시하고 조회를 시도하고 있습니다.
MYSQL에서는 이에 The SRID of the geometry does not match the SRID of the column ‘point’ 라는 예외 메시지를 던져줍니다.
테이블의 공간 데이터 컬럼의 SRID가 5179로 적용되어 있으므로, 테이블의 데이터를 공간 데이터 기반으로 조회하기 위해서 반드시 Input으로 주어지는 공간 데이터도 SRID 5179를 명시해주어야 합니다.
그렇지 않으면 위와 같이 DB에서 예외가 발생할 뿐더러, 설령 쿼리 된다 하더라도 전혀 다른 좌표 체계를 통해 쿼리가 수행될 수 있습니다.


위 사진과 같이 SRID를 명시해줄 때, 쿼리가 정상적으로 수행되는 것을 확인할 수 있습니다.
-
-
Spartial Index 적용
`SPATIAL INDEX(point)`이번 쿼리 성능 개선의 핵심, R-Tree 인덱스 구조를 기반으로 동작하는 Spartial Index를 적용했습니다. SPATIAL INDEX를 생성할 때는 MySQL 테이블의 공간 데이터 컬럼에 INDEX 힌트를 추가하여 인덱스를 생성하게 됩니다.
이제 이 인덱스를 기반으로 공간 데이터의 범위 검색, 인접한 데이터 검색 등의 다양한 공간 연산을 효율적으로 수행할 수 있습니다.
-
-
프로젝트에 적용하기
-
기존 DB 데이터 삭제하기
Region 테이블의 컬럼을 다시 작성해야 하기 때문에, 기존에 있던 DB 데이터를 모두 삭제해야 했습니다.
FK로 연관된 테이블이 많아 꽤 많은 양의 데이터였지만, 어차피 테스트 데이터기 때문에 과감하게 지우고 다시 시작하기로 했습니다.
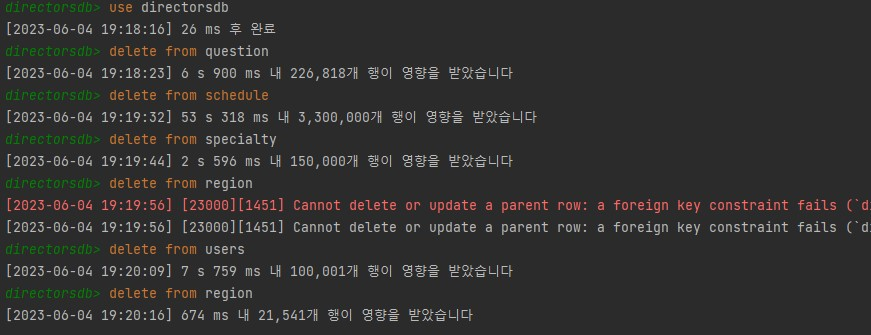
-
새로운 Region 테이블 만들기
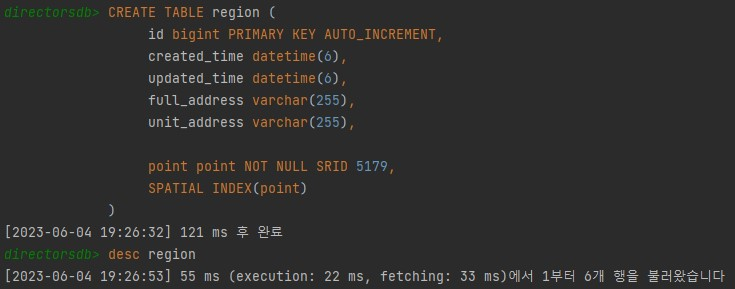
새로 테이블을 만들고, 내용을 확인합니다.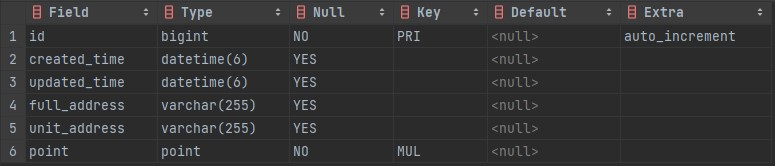
테이블이 잘 생성된 것을 확인할 수 있습니다.
인덱스도 잘 만들어졌는지 확인해봅니다.

잘 생성되었습니다👍
-
Region 데이터를 Insert 하기

잘 들어갔는지 확인해봅니다.

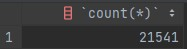
잘 들어간 것 같습니다🦾
내친 김에 각 Row 별로 SRID가 잘 적용되었는지도 확인해봅니다.

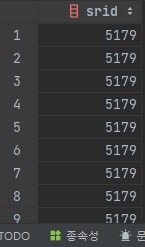
원하던 대로 UTM-K를 나타내는 5179로 잘 적용되었음을 확인했습니다.
-
2) Spartial Index가 적용되는 쿼리 작성하기
-
변경 계획
# 기존 범위 검색 쿼리 SELECT * FROM Region WHERE **ST_Distance_Sphere(POINT(?, ?)) <= ?** # 변경된 범위 검색 쿼리 SELECT * FROM Region SELECT * FROM Region WHERE **ST_Contains(ST_Buffer(ST_PointFromText(Point(? ?), 5179), ?), point)변경 계획을 함께 살펴봅니다.
-
R-Tree를 적용할 수 있는 공간 연산 함수 사용하기
특정 범위 내에 속하는 데이터들을 조회하기 위해서 사용하던 공간 연산 함수를 변경했습니다.
기존에 사용했던 ST_Distance_Sphere는 구면 좌표 체계에서 거리를 계산하는데 사용되는 공간 연산 함수였습니다. 특정 지역과 지역 간의 거리를 측정하는 데는 좋은 함수이지만, 여기서는 인덱스가 적용되지 않은 채로 모든 DB의 컬럼을 Full search하면서 공간 간 Distance를 연산하므로, 성능에 문제가 발생할 수 밖에 없었을 것입니다. 더군다나 SRID가 디폴트 값인 0으로 설정되어 있었기 때문에 제대로 작동되기 어려웠을 것입니다.
변경된 검색 쿼리에서는 ST_Contains, ST_Buffer, ST_PointFromText 함수를 사용하고, 변경된 SRID가 적용될 수 있도록 했습니다.
특히 ST_Contains는 공간 데이터베이스에서 Geometry 객체 간의 포함 관계를 확인하는데 사용되는 함수 중 하나로, 첫번째 인자로 받는 Geomtry 객체 안에 두번째 인자로 받는 Geometry 객체가 완전히 포함되는지 여부를 판별하는 데 사용됩니다. 예를 들어 ST_Contains(Seoul, Songpa) 의 연산을 수행할 경우, true가 반환 되고, ST_Contains(Seoul, Jeju) 의 연산을 수행할 경우 false가 반환됩니다.
R-Tree는 MBR의 포함 관계를 이용해서 만들어진 인덱스이므로, ST_Contains는 이를 사용하여 좋을 성능을 가져올 수 있을 것으로 기대했습니다.
한편, ST_Contains 연산을 수행하기 위해서는 공간의 범위를 객체로 생성하여 인자로 넘겨주어야 합니다. 다음 단락에서 이를 다루어봅니다.
-
어떻게 공간의 범위를 표현할 것인가
2가지의 선택지를 고려했습니다.[1] JTS(Java Topology Suite) 라이브러리 활용
- 기존 프로젝트에서 특정 위치 데이터를 표현하기 위해 공간 연산 및 공간 객체 생성에 사용되는 JTS 라이브러리를 사용하고 있었습니다. JTS에서 Polygon, Circle, Line 등의 공간 객체를 생성할 수 있는 메서드를 제공하고 있으므로, 이를 사용해볼 수 있습니다.
[2] MySQL 내장 함수 ST_BUFFER 사용
- MySQL에 내장되어 있는 ST_BUFFER 함수는 Geomtry 객체의 버퍼를 생성하는 역할을 수행합니다. 이를 사용하여 버퍼를 생성하여 공간 연산을 수행할 수 있습니다. ST_BUFFER는 첫번째 인자로 Geometry 객체를 받고, 해당 객체의 SRID의 단위를 기준으로 두번째 인자로 받는 Distance 만큼의 범위를 적용한 버퍼 객체를 생성합니다. ST_Buffer 함수에서 생성되는 버퍼의 형태는 입력된 기준 geometry 객체의 형태에 의해 결정됩니다. 주어진 geometry가 point 타입일 경우 해당 point를 중심으로 원형의 공간 버퍼를 생성하고, 선이나 다각형일 경우에는 해당 객체의 외부 경계선을 기준으로 다각형 버퍼를 생성하게 됩니다.
결론적으로는 MySQL의 ST_BUFFER 함수를 사용하기로 했습니다. 이미 ST_Contains를 쓰고 있기 때문에, ST_BUFFER를 함께 쓰는 것이 코드 상으로도 간결하고 관리하기 편할 것이라고 생각했습니다. 또한 MySQL의 내장 함수인만큼, 성능의 최적화를 기대했습니다.
[3] Geometry 객체 생성하기ST_PointFromText 함수를 사용하여, 텍스트 형식으로 표현된 Point 객체를 사용하도록 했습니다. ST_GeomFromText 는 텍스트로 표현된 WKT와 SRID를 사용하여 Point 객체를 생성할 수 있으며, 이를 통해 ST_BUFFER와 ST_Contains의 인자로 적용될 수 있습니다.
-
프로젝트에 적용하기
-
콘솔로 새로 만든 쿼리 실행 테스트하기
애플리케이션의 코드를 변경하기 전에, 먼저 콘솔로 쿼리를 테스트해보겠습니다. 쿼리의 실행 계획을 먼저 조회해봅니다.


인덱스를 잘 타는 것을 확인할 수 있습니다.
이제 실제 쿼리를 실행해봅니다.

54ms의 Latency 만에 쿼리가 수행되었습니다!
여러 번의 테스트를 더 수행해보겠습니다.
-
Test
-
사용된 데이터
Key Value 좌표(UTM-K 기준) 청담동 행정 센터 좌표로부터의 거리 5000 -
Result
Round Latency (ms) 1 54 2 59 3 60 4 67 5 60 6 103 7 71 8 53 9 64 10 60 -
Average
- 65.1 (ms)
기존 쿼리의 실행 결과와 비교했을 때, Latency가 기존 대비 1/10 가량으로 개선된 것을 확인할 수 있습니다. 아래는 기존 쿼리의 실행 결과입니다.

-
-
-
변경된 쿼리를 코드에 적용하기
-
데이터 액세스 방식의 변경
// 기존 쿼리 방식 - JPA의 @Query 어노테이션 사용** public interface JpaRegionRepository extends JpaRepository<Region, Long> { // ... @Query("SELECT r FROM Region r WHERE ST_Distance(r.point, :point) <= :distance") List<Region> findRegionByPointDistanceLessThan( @Param("point") Point point, @Param("distance") double distance ); } // 변경된 쿼리 방식 - EntityManager, PreparedStatement 사용 @Repository @RequiredArgsConstructor public class RegionRepositoryAdapter implements RegionRepository { // ... @PersistenceContext private EntityManager entityManager; public List<Region> findRegionWithin(double x, double y, double distance) { String nativeQuery = "SELECT * FROM mydb.region WHERE ST_Contains(ST_Buffer(ST_GeomFromText(?, 5179), ?), point)"; Query query = entityManager.createNativeQuery(nativeQuery, Region.class); query.setParameter(1, String.format("POINT(%f %f)", x, y)); query.setParameter(2, distance); return query.getResultList(); } }기존에는 JPA의 @Query 어노테이션을 통해 ST_Distance 함수를 사용해왔습니다. 그러나 쿼리 내용을 변경하면서, EntityManager로 쿼리의 구현을 변경하게 되었습니다.
구현을 변경한 가장 큰 이유는 @Query 어노테이션을 사용하여 JPA 쿼리를 작성할 때, 인자 값들이 쿼리에 잘 적용되지 않는 문제가 있었기 때문입니다. @Query 어노테이션은 정적인 쿼리를 작성하는 데 용이하지만, 동적인 쿼리에 대한 유연성은 상대적으로 제한적입니다. 특히, 공간 함수를 사용하는 경우에는 JPA의 @Query 어노테이션으로는 적절한 인자 바인딩이 쉽지 않았습니다.
변경된 방식은 EntityManager와 PreparedStatement를 사용하여 동적인 쿼리를 작성하고 실행합니다. 이를 통해 쿼리의 인자 값을 직접 바인딩하여 쿼리에 정확한 값을 전달할 수 있게 되었습니다.
-
Region 엔티티의 컬럼 수정
// ... import org.locationtech.jts.geom.Point; public class Region extends BaseEntity { // ... @Column(name = "point", columnDefinition = "POINT", nullable = false) private Point point; // ... }- point의 데이터 타입을 DB에서 Point로 변경했으므로, Region 엔티티에서도 이에 맞게 타입을 변경해줍니다.
- point의 데이터 타입을 DB에서 Point로 변경했으므로, Region 엔티티에서도 이에 맞게 타입을 변경해줍니다.
-
이제 지역 검색 쿼리를 위한 R-Tree 인덱스 적용 및 쿼리 개선 작업이 마무리되었으므로, 실제 포스트맨을 통해 테스트를 진행해봅니다.
최종 테스트
이제 지역 검색 쿼리를 위한 R-Tree 인덱스 적용 및 쿼리 개선 작업이 마무리되었으므로, 실제 포스트맨을 통해 테스트를 진행해봅니다.
1) Local
-
Request Url 및 data는 동일.
-
Result
Round Latency (ms) 1 59 2 49 3 42 4 50 5 45 6 42 7 49 8 38 9 42 10 46 -
Average
- 46.2 (ms)
2) Naver Cloud Platform
-
Request Url 및 data는 동일.
-
Result
Round Latency (ms) 1 524 2 523 3 510 4 534 5 527 6 506 7 515 8 619 9 509 10 539 -
Average
- 530.6 (ms)
-
Change
- 로컬의 경우 266.9 → 46.2, cloud의 경우 735.5 → 530.6로 조회 성능이 향상되었습니다. R-Tree 인덱싱을 통해 200ms 이상의 Latency를 개선한 것을 확인할 수 있습니다.
- 한편, 클라우드 환경에서는 여전히 많은 Latency가 소요되고 있습니다. 추가적인 개선 작업이 필요해보입니다.
- 로컬의 경우 266.9 → 46.2, cloud의 경우 735.5 → 530.6로 조회 성능이 향상되었습니다. R-Tree 인덱싱을 통해 200ms 이상의 Latency를 개선한 것을 확인할 수 있습니다.
마치며
검색 기능에 대한 Latency를 측정해보고, 병목 지점을 찾아 성능을 개선해보는 작업을 수행했습니다.
여전히 개선해야 할 부분이 보이지만, 이전에 비해 개선된 Latency를 보니 보람이 느껴집니다.
남은 프로젝트도 화이팅!
