정밀도와 재형율의 트레이드오프
와인 데이터
import pandas as pd
red_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/winequality-red.csv'
white_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/winequality-white.csv'
red_wine = pd.read_csv(red_url, sep=';')
white_wine = pd.read_csv(white_url, sep=';')
red_wine['color'] = 1.
white_wine['color'] = 0.
wine = pd.concat([red_wine, white_wine])
wine['taste'] = [1. if grade > 5 else 0. for grade in wine['quality']]
X = wine.drop(['taste', 'quality'], axis=1)
y = wine['taste']데이터 분리
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)로지스틱 회귀 적용
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
lr = LogisticRegression(solver='liblinear', random_state=13)
lr.fit(X_train, y_train)
y_pred_tr = lr.predict(X_train)
y_pred_test = lr.predict(X_test)
print('Tran Acc : ', accuracy_score(y_train, y_pred_tr))
print('Test Acc : ', accuracy_score(y_test, y_pred_test))
classification_report
from sklearn.metrics import classification_report
print(classification_report(y_test,lr.predict(X_test)))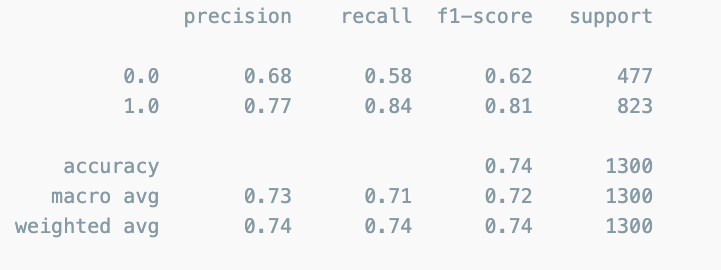
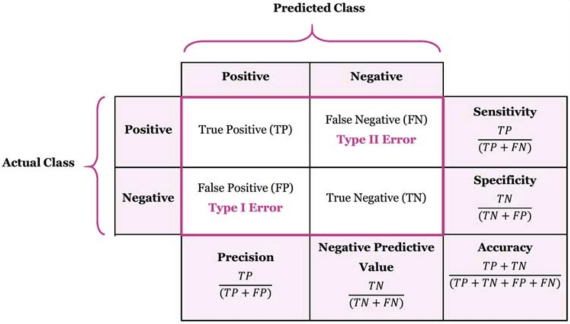
confusion matrix
from sklearn.metrics import confusion_matrix
print(confusion_matrix(y_test, lr.predict(X_test)))
Precision_recall curve
import matplotlib.pyplot as plt
from sklearn.metrics import precision_recall_curve
plt.figure(figsize=(10,8))
pred = lr.predict_proba(X_test)[:,1]
precisions, recalls, thresholds = precision_recall_curve(y_test,pred)
plt.plot(thresholds, precisions[:len(thresholds)],label='precisions')
plt.plot(thresholds, recalls[:len(thresholds)],label='precisions')
plt.grid()
plt.legend()
plt.show()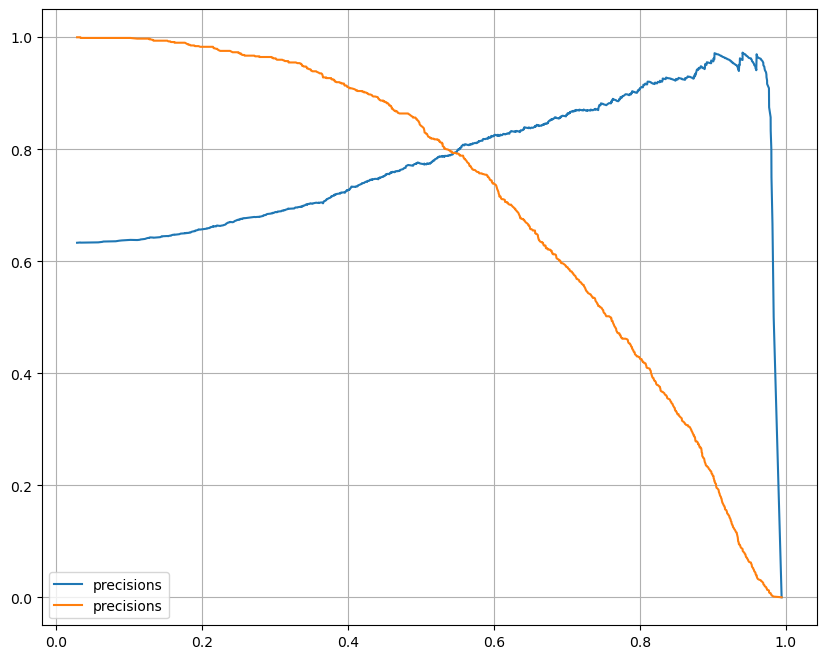
threshold = 0.5
pred_proba = lr.predict_proba(X_test)
pred_proba[:3]
간단히 확인해보기
import numpy as np
np.concatenate([pred_proba, y_pred_test.reshape(-1,1)], axis = 1)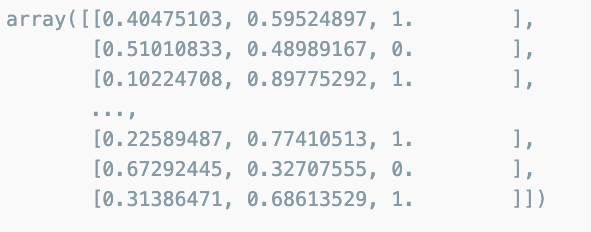
threshold 바꿔 보기 - Binarizer
from sklearn.preprocessing import Binarizer
binarizer = Binarizer(threshold=0.6).fit(pred_proba)
pred_bin = binarizer.transform(pred_proba)[:,1]
pred_bin
classification report
print(classification_report(y_test,pred_bin))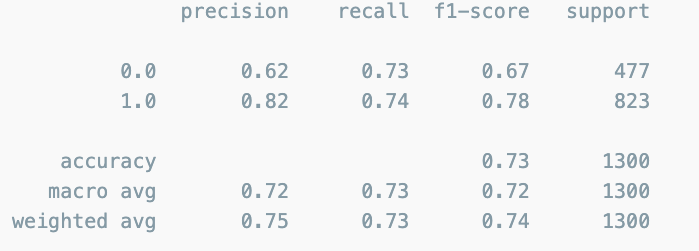
confusion matrix
from sklearn.metrics import confusion_matrix
print(confusion_matrix(y_test, pred_bin))

10√2 Data