HAR data
import pandas as pd
url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/features.txt'
feature_name_df = pd.read_csv(url, sep='\s+', header=None, names=['column_index', 'column_name'])
feature_name = feature_name_df.iloc[:,1].values.tolist()
X_train_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/train/X_train.txt'
X_test_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/test/X_test.txt'
X_train = pd.read_csv(X_train_url, sep='\s+', header=None)
X_test = pd.read_csv(X_test_url, sep='\s+', header=None)
X_train.columns = feature_name
X_test.columns = feature_name
y_train_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/train/y_train.txt'
y_test_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/test/y_test.txt'
y_train = pd.read_csv(y_train_url, sep='\s+', header=None)
y_test = pd.read_csv(y_test_url, sep='\s+', header=None)
X_train.shape, X_test.shape , y_train.shape , y_test.shape

재사용 함수
from sklearn.decomposition import PCA
def get_pca_data(ss_data, n_components=2):
pca = PCA(n_components=n_components)
pca.fit(ss_data)
return pca.transform(ss_data), pca PCA fit
HAR_pca , pca = get_pca_data(X_train, n_components=2)
HAR_pca.shape
pca.mean_.shape, pca.components_.shape
조금 더 재미있는 함수 만들기 위해
cols = ['pca_' + str(n) for n in range(pca.components_.shape[0])]
cols
PCA 결과를 저장하는 함수
def get_pd_from_pca(pca_data, col_num):
cols = ['pca_' + str(n) for n in range(pca.components_.shape[0])]
return pd.DataFrame(pca_data, columns=cols)components 2개
HAR_pca, pca = get_pca_data(X_train, n_components=2)
HAR_pd_pca = get_pd_from_pca(HAR_pca, pca.components_.shape[0])
HAR_pd_pca['action'] = y_train
HAR_pd_pca.head()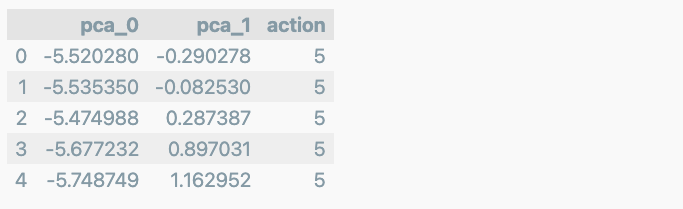
import seaborn as sns
sns.pairplot(HAR_pd_pca, hue='action', height=5, x_vars=['pca_0'], y_vars=['pca_1']);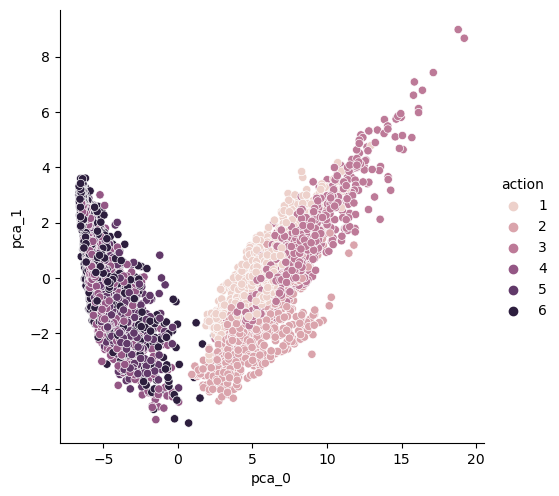
전체 500개가 넘는 특성을 단 두개로 줄이면 이 정도
import numpy as np
def print_variance_ratio(pca):
print('variance_ratio :', pca.explained_variance_ratio_)
print('sum of variance_ratio :', np.sum(pca.explained_variance_ratio_))
print_variance_ratio(pca)
컴포넌트 3개
HAR_pca, pca = get_pca_data(X_train, n_components=3)
HAR_pd_pca = get_pd_from_pca(HAR_pca, pca.components_.shape[0])
HAR_pd_pca['action'] = y_train
HAR_pd_pca.head()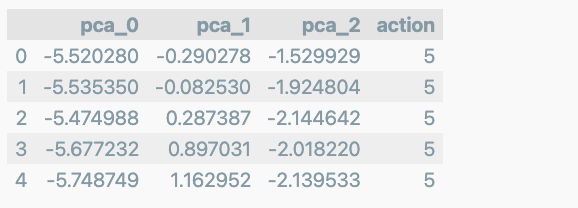
print_variance_ratio(pca)
컴포넌트 10개
HAR_pca, pca = get_pca_data(X_train, n_components=10)
HAR_pd_pca = get_pd_from_pca(HAR_pca, pca.components_.shape[0])
HAR_pd_pca['action'] = y_train
HAR_pd_pca.head()
이 결과가 시간이 길게 나왔다면
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
params = {
'max_depth' : [6, 8, 10],
'n_estimators' :[50, 100, 200],
'min_samples_leaf' : [8, 12],
'min_samples_split' : [8, 12]
}
rf_clf = RandomForestClassifier(random_state=13, n_jobs=1)
grid_cv = GridSearchCV(rf_clf, param_grid=params, cv=2, n_jobs=1)
grid_cv.fit(HAR_pca, y_train.values.reshape(-1,))
cv_results_df = pd.DataFrame(grid_cv.cv_results_)
cv_results_df.columns 
target_col = ['rank_test_score','mean_test_score','param_n_estimators','param_max_depth']
cv_results_df[target_col].sort_values('rank_test_score').head()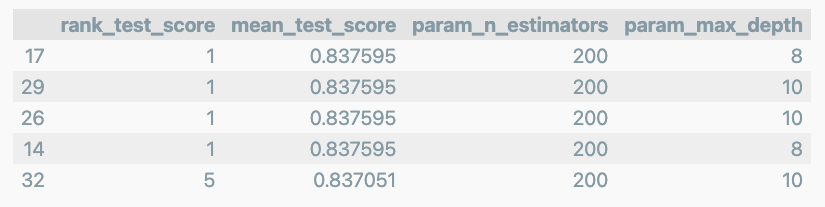
테스트 데이터에 적용
from sklearn.metrics import accuracy_score
rf_clf_best = grid_cv.best_estimator_
rf_clf_best.fit(HAR_pca, y_train.values.reshape(-1 , ))
pred1 = rf_clf_best.predict(pca.transform(X_test))
accuracy_score(y_test, pred1)
시간이 많이 걸렸던 xgboost
import time
from xgboost import XGBClassifier
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y_train = le.fit_transform(y_train)
evals = [(pca.transform(X_test), y_test)]
start_time = time.time()
xgb = XGBClassifier(n_estimators=400, learning_rate=0.1, max_depth=3)
xgb.fit(HAR_pca, y_train. reshape(-1,), early_stopping_rounds=10, eval_set=evals)
print('Fit time :', time.time() - start_time)


10√2 Data