
해당 github repository
https://github.com/timointhebush/real-good-restaurant-backend
최종적으로 구성된 우리 서비스의 아키텍쳐는 다음과 같다.
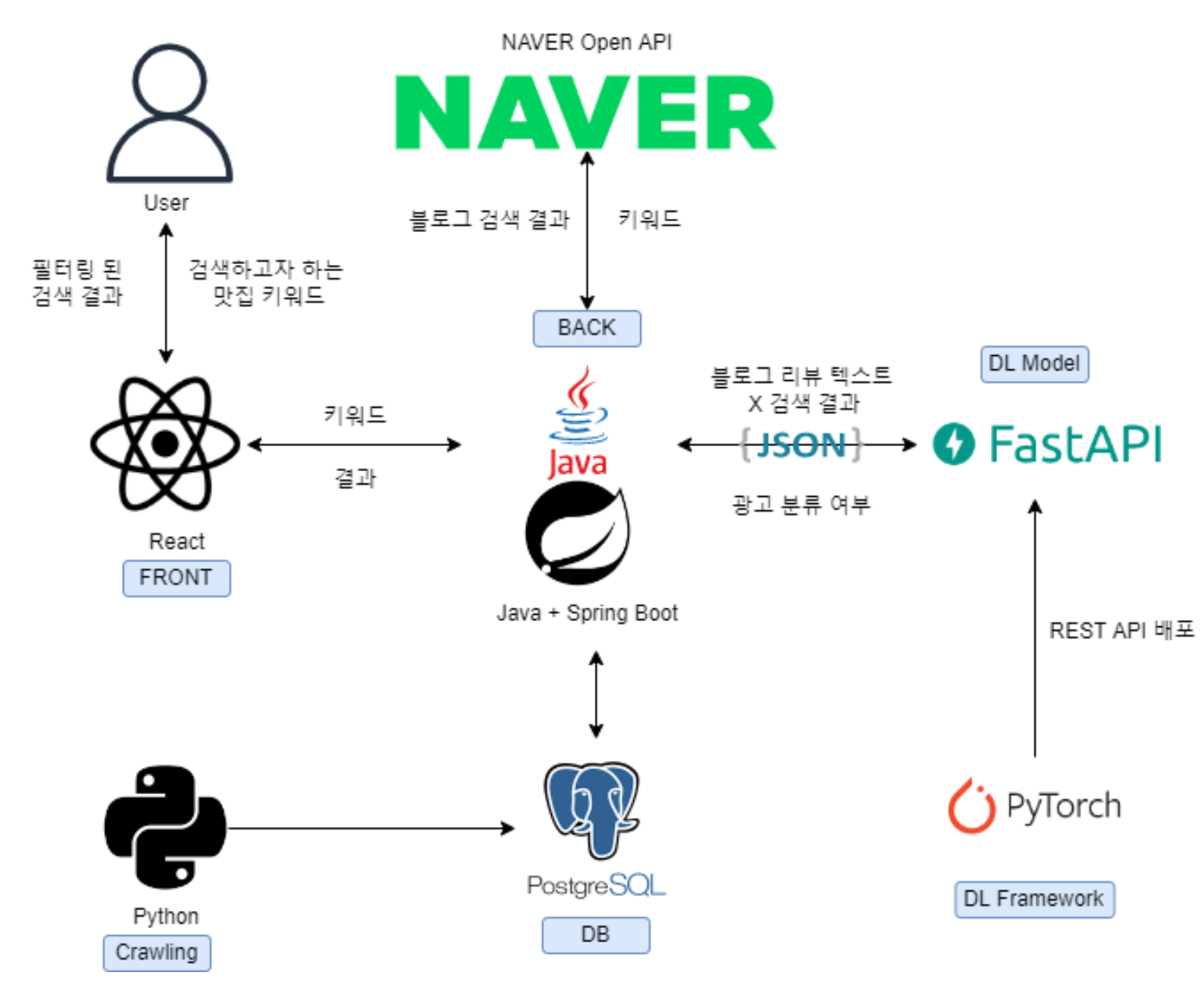
처음 작성한 하나의 API는 다음과 같은 일을 모두 수행했다.
1. 프론트에서 받아온 키워드로 Naver Open API를 호출하고
2. 호출 결과를 통해 각 블로그의 텍스트를 추출하여
3. 딥러닝 모델에 텍스트를 보내 광고 여부 결과를 받아
4. 여부 결과를 합쳐 response로 보내 주었다.
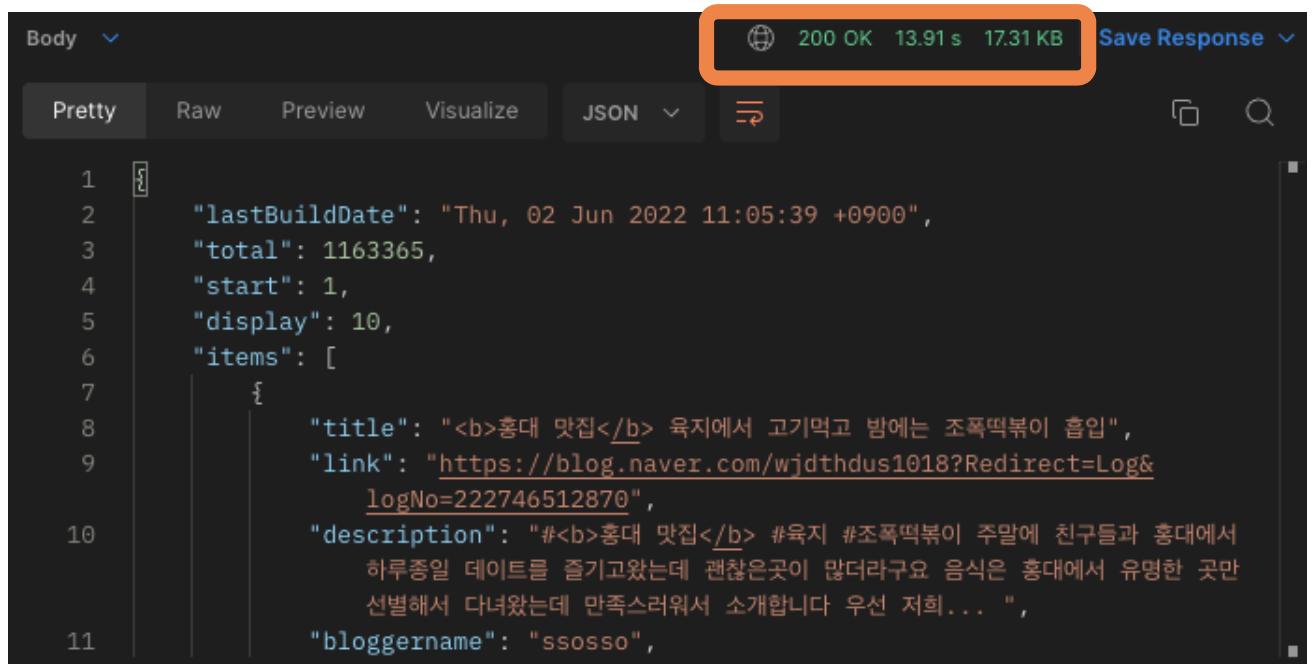
하지만 이 API는 너무나 응답 속도가 느렸다. 10개의 블로그 리뷰를 분류하고 가져오는데 약 13초가 소요되었다. 즉 사용자가 검색창에 '홍대 맛집'을 검색하고 10초 넘게 로딩 화면을 봐야 한다는 것 이었다. 이는 사용자 경험에 안좋은 영향을 줄 것이 분명했다.
1. API의 분리
사용자 경험을 개선하기 위해 우선 급한대로 API를 분리하기로 했다.
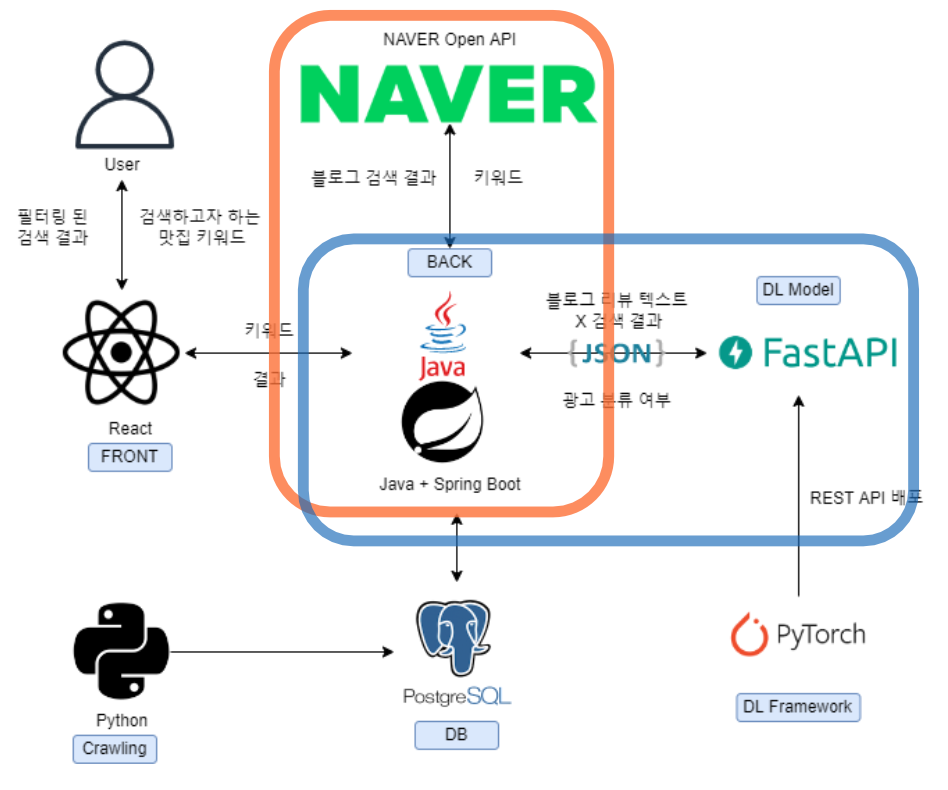
우선 사용자가 '홍대 맛집'을 검색하면,
- 프론트에서 받아온 키워드로 Naver Open API를 호출하고
- 우선 네이버 검색 결과를 먼저 출력한다.
이후 검색 결과를 responseBody에 담아 POST request를 보내면
- 호출 결과를 통해 각 블로그의 텍스트를 추출하여
- 딥러닝 모델에 텍스트를 보내 광고 여부 결과를 받아
- 여부 결과를 합쳐 response로 보내 주었다.
두번째 API의 결과는 비동기로 처리되어,
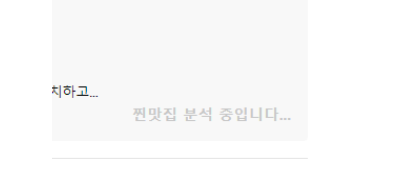
이렇게 로딩화면에서
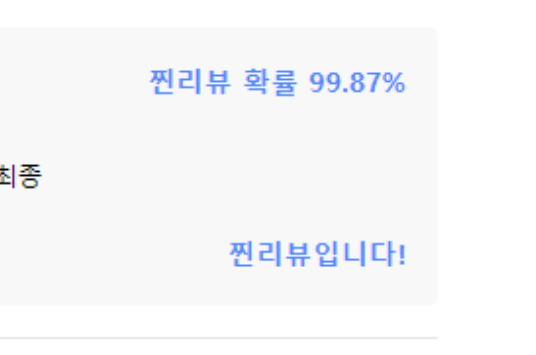
업데이트 되도록 했다.
본질적인 API의 속도는 개선하지 못했지만, 사용자는 무작정 긴 로딩 화면을 보지 않음으로서 사용자 경험을 개선했다.
2. DB를 사용한 캐싱
이미 한번 분류 한 블로그 리뷰 글의 경우, 분류한 내용을 데이터베이스에 캐싱한다면 API의 성능을 높일 수 있을 것이라 생각했다. '홍대 맛집'이라는 키워드로 네이버 Open API를 호출하고, 각 블로그 포스팅의 URL을 통해 DB에 저장된 게시글이 있는지 확인한다. 저장 된 글이라면 SELECT하여 가져오고, 그렇지 않은 게시글들은 분류한다.
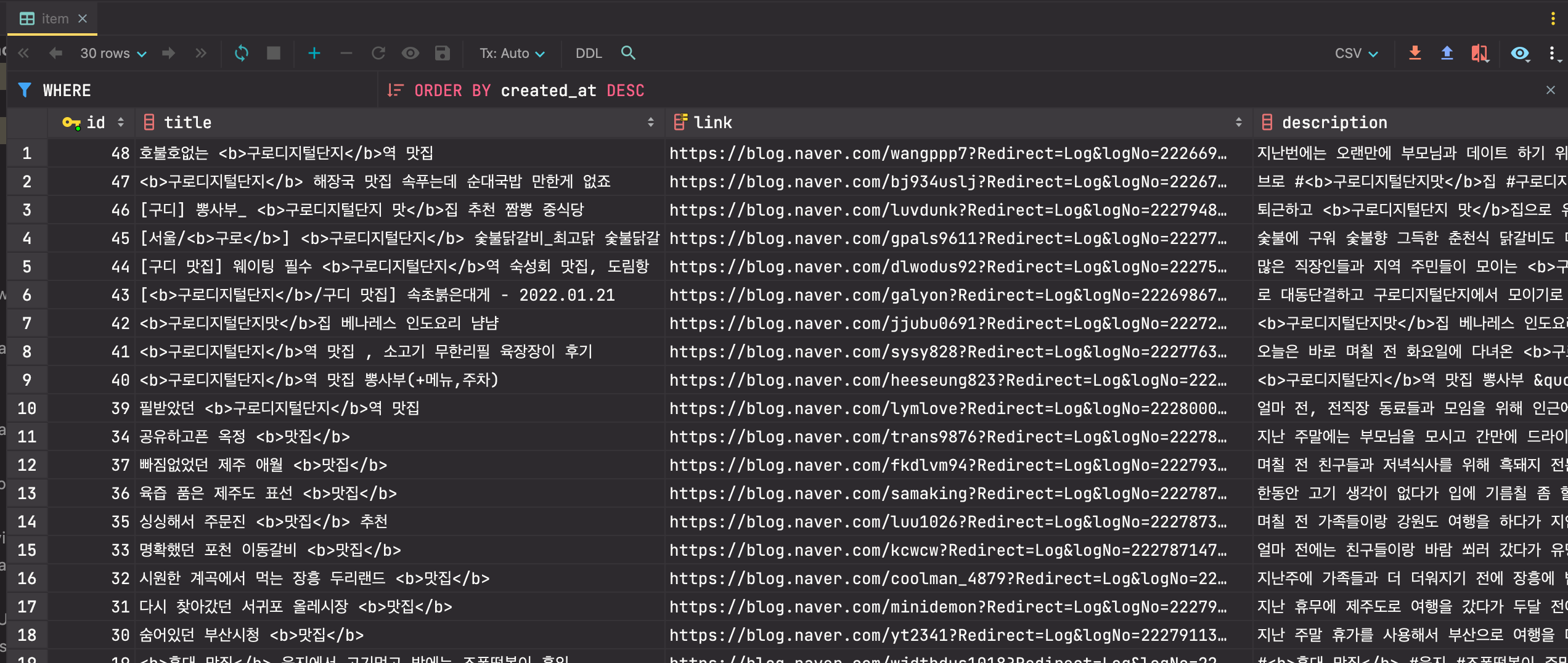
다음과 같이 분류한 블로그 게시글들을 저장할 테이블을 만들어 주었다.
create table item
(
id bigint auto_increment
primary key,
title varchar(300) null,
link varchar(150) null,
description varchar(1000) null,
bloggername varchar(50) null,
bloggerlink varchar(150) null,
postdate char(8) null,
text text null,
ad char null,
probability double(11, 10) null,
created_at timestamp default CURRENT_TIMESTAMP null,
updated_at timestamp default CURRENT_TIMESTAMP null,
constraint unique_index_link
unique (link)
); @Transactional
public NaverSearchResult classify(NaverSearchResult naverSearchResult) throws IOException, RuntimeException {
List<String> itemLinkList = itemService.extractItemsLink(naverSearchResult.getItems());
List<Item> cachedItemList = itemService.findAllByLinkList(itemLinkList);
List<Item> newItemList = this.filterCachedItems(naverSearchResult.getItems(), cachedItemList);
if (newItemList.size() > 0) {
newItemList = this.fillBlogText(newItemList);
String requestBody = mapper.writeValueAsString(newItemList);
String responseBody = RequestUtil.post(this.classifierUrl, requestBody);
List<Item> classifiedItemList = Arrays.asList(mapper.readValue(responseBody, Item[].class));
itemService.saveAll(classifiedItemList);
cachedItemList.addAll(classifiedItemList);
}
naverSearchResult.setItems(cachedItemList);
return naverSearchResult;
}그 결과 첫 호출 시, 20초 가까이 걸리던 시간이
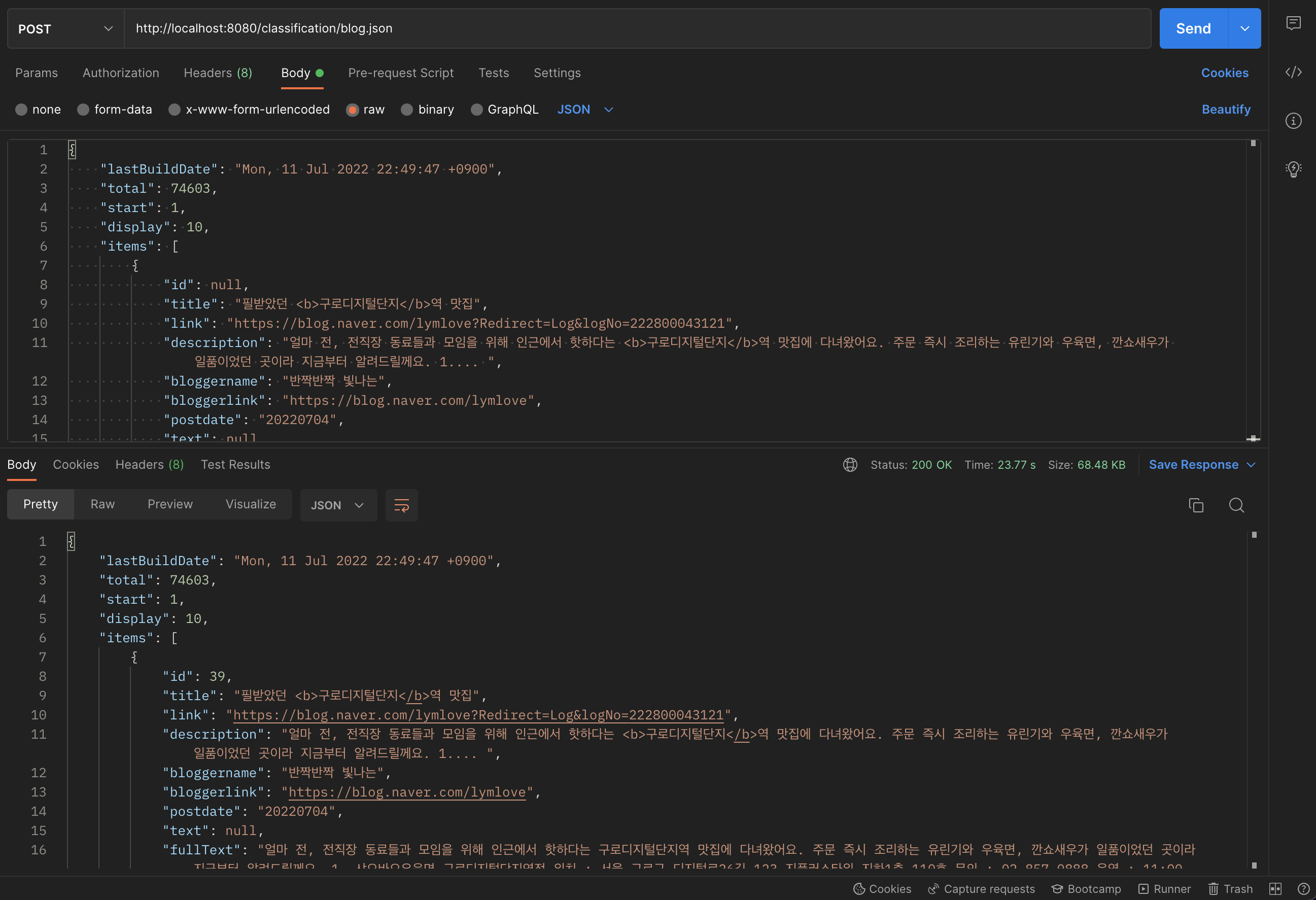
DB에 저장된 후
응답 속도가 매우 단축된 것을 확인할 수 있었다.
- 해당 캐싱을 RDB가 아닌 Redis를 사용한다면 더욱 개선할 수 있겠다는 생각이 들었다.
