
출처: https://huggingface.co/blog/blip-2
✏️ 작성하게 된 계기
BLIP-2 모델의 원리와 구체적인 구현 코드를 살펴보았다. 논문을 읽을 때는 “어떻게 이런 아이디어를 코드로 구현할까?” 라고 궁금했고, 실제 구현 코드를 확인한 후에는 “이렇게 class가 많은데 이런 걸 하나하나 따로 import해서 사용하는게 맞나?” 라는 의문이 들었다. 그래서 huggingface에 올라온 코드를 실제로 한번씩 실행시킨 후 출력된 결과물이 실제 github에 구현된 구조와 일치하는지 확인하기로 했다.
📃 BLIP-2에 대해서는 아래의 [논문리뷰]를 참고하시길 바랍니다.
https://velog.io/@tina1975/논문리뷰-BLIP-2-Bootstrapping-Language-Image-Pre-trainingwith-Frozen-Image-Encoders-and-Large-Language-Models
📃 BLIP-2에 코드 구현에 대해서는 아래의 글을 참고하시길 바랍니다.
https://velog.io/@tina1975/AI-모델-코드-BLIP-2-모델-코드-이해
1️⃣ Blip2Model
🔷 Blip2Model class 실행시키기
- Blip2Model의
forward함수가 실행됩니다.
from PIL import Image
import requests
from transformers import Blip2Processor, Blip2Model
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
# Processor와 Model 로드 및 GPU에 올리기
processor = Blip2Processor.from_pretrained("Salesforce/blip2-opt-2.7b")
model = Blip2Model.from_pretrained("Salesforce/blip2-opt-2.7b", torch_dtype=torch.float16)
model.to(device)
# 입력 이미지 불러오기
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
# 입력 프롬프트
prompt = "Question: how many cats are there? Answer:"
# Processor를 통해 입력 이미지와 프롬프트 전처리
inputs = processor(images=image, text=prompt, return_tensors="pt").to(device, torch.float16)
# 모델 입력
outputs = model(**inputs)🔻 입력 이미지

🔻 실행결과
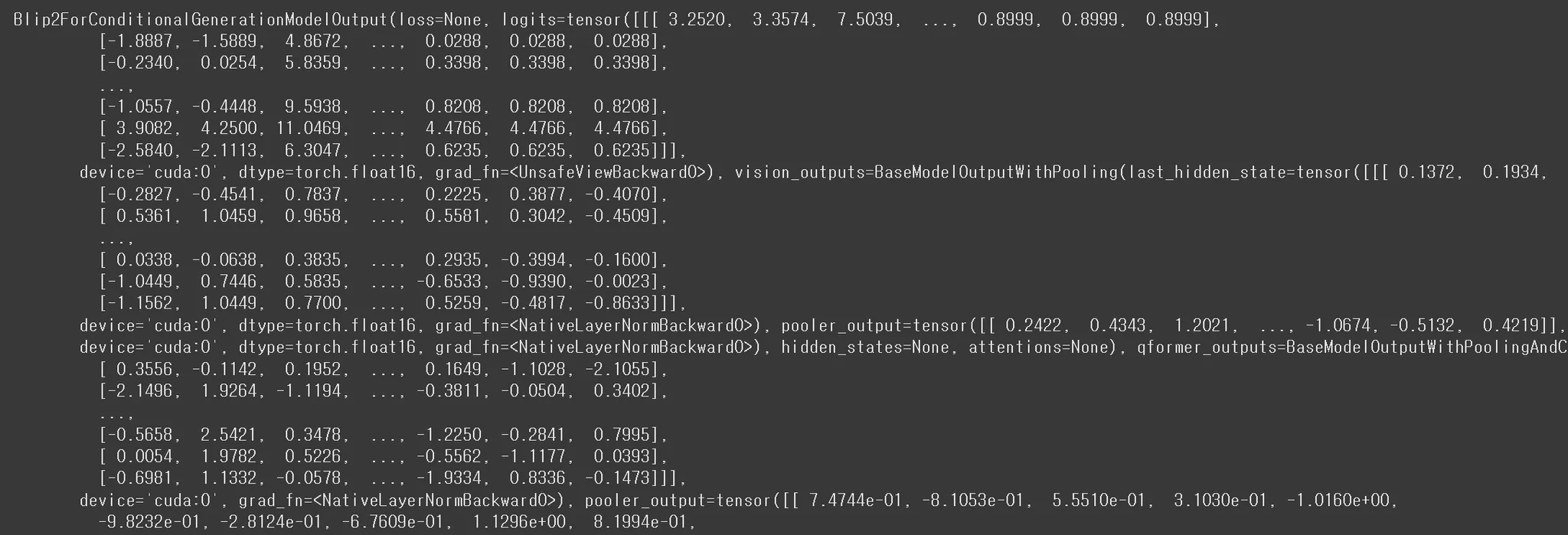
- BLIP2ForConditionalGenerationModelOutput을 출력하는 것을 확인할 수 있다.
🔻 실제 구현 코드
🔷 def get_text_features
- Blip2Model의
get_text_features함수가 실행됩니다.
import torch
from transformers import AutoTokenizer, Blip2Model
model = Blip2Model.from_pretrained("Salesforce/blip2-opt-2.7b")
tokenizer = AutoTokenizer.from_pretrained("Salesforce/blip2-opt-2.7b")
inputs = tokenizer(["a photo of a cat"], padding=True, return_tensors="pt")
print(inputs)
text_features = model.get_text_features(**inputs)
print(text_features)🔻 실행 결과

- 첫 번째는 tokenizer가 입력된 “a photo of a cat”을 토큰화한 것입니다.
- 두번째 결과물은 토큰화된 입력을 Vision encoder나 Q-Former를 거치지 않고 LLM 모델만 통과하여 출력된 값입니다.
🔻 실제 구현 코드

🔷 def get_image_features
- Blip2Model의
get_image_features함수가 실행됩니다.
import torch
from PIL import Image
import requests
from transformers import AutoProcessor, Blip2Model
model = Blip2Model.from_pretrained("Salesforce/blip2-opt-2.7b")
processor = AutoProcessor.from_pretrained("Salesforce/blip2-opt-2.7b")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(images=image, return_tensors="pt")
print(inputs)
image_outputs = model.get_image_features(**inputs)
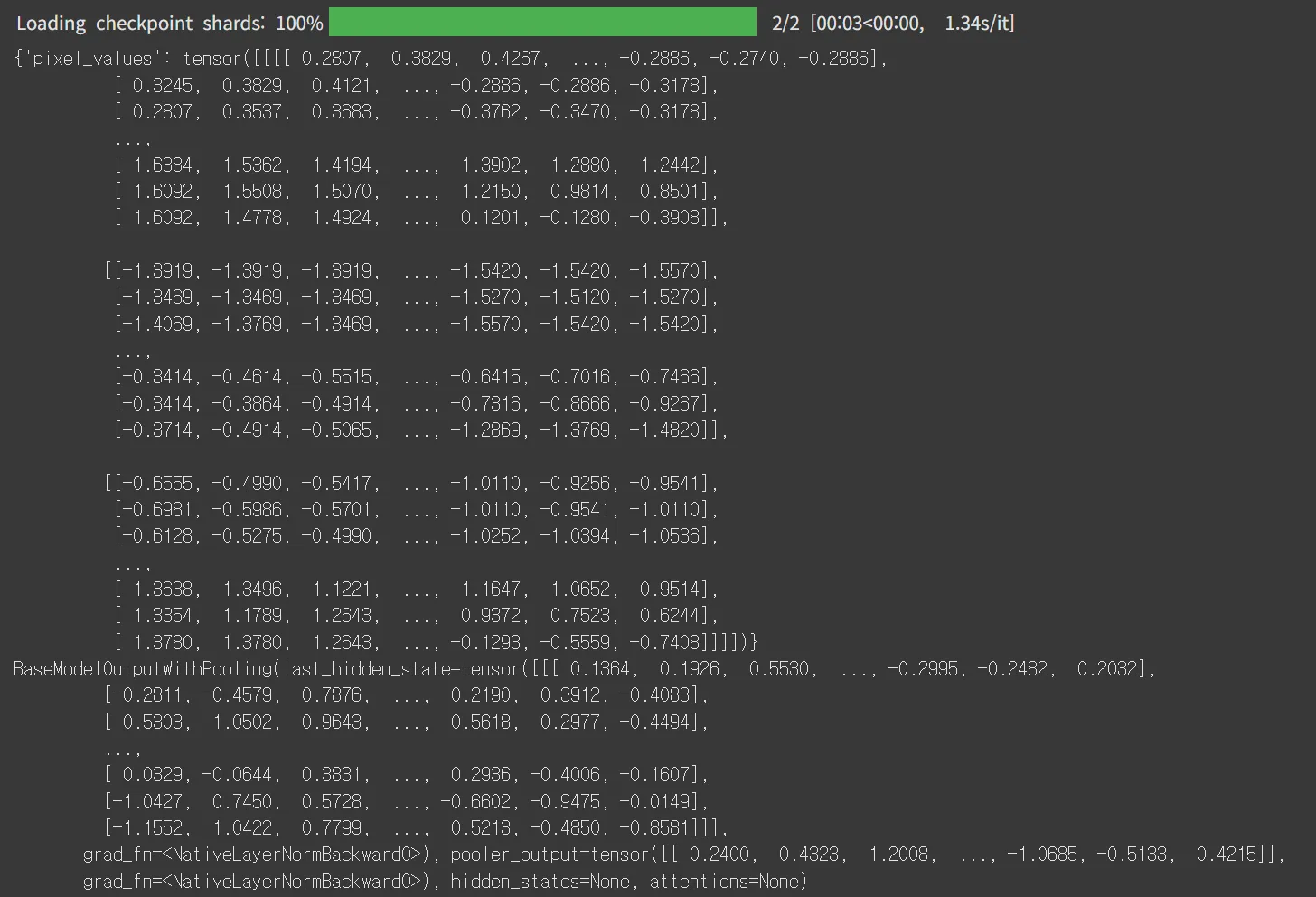
print(image_outputs)- BLIP-2 모델의 processor는 BLIP 모델의 processor를 가져와 사용합니다.
- processor를 거친
inputs는 정규화를 거친 픽셀값입니다. - 이후
get_image_features를 거치면 vision encoder를 거친 이미지 특징이 추출됩니다. - 이 값은 Q-Former를 거친 값이 아닙니다.
🔻 실행 결과
🔻 실제 구현 코드
🔷 def get_qformer_features
- Blip2Model의
get_qformer_features함수가 실행됩니다.
import torch
from PIL import Image
import requests
from transformers import Blip2Processor, Blip2Model
processor = Blip2Processor.from_pretrained("Salesforce/blip2-opt-2.7b")
model = Blip2Model.from_pretrained("Salesforce/blip2-opt-2.7b")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(images=image, return_tensors="pt")
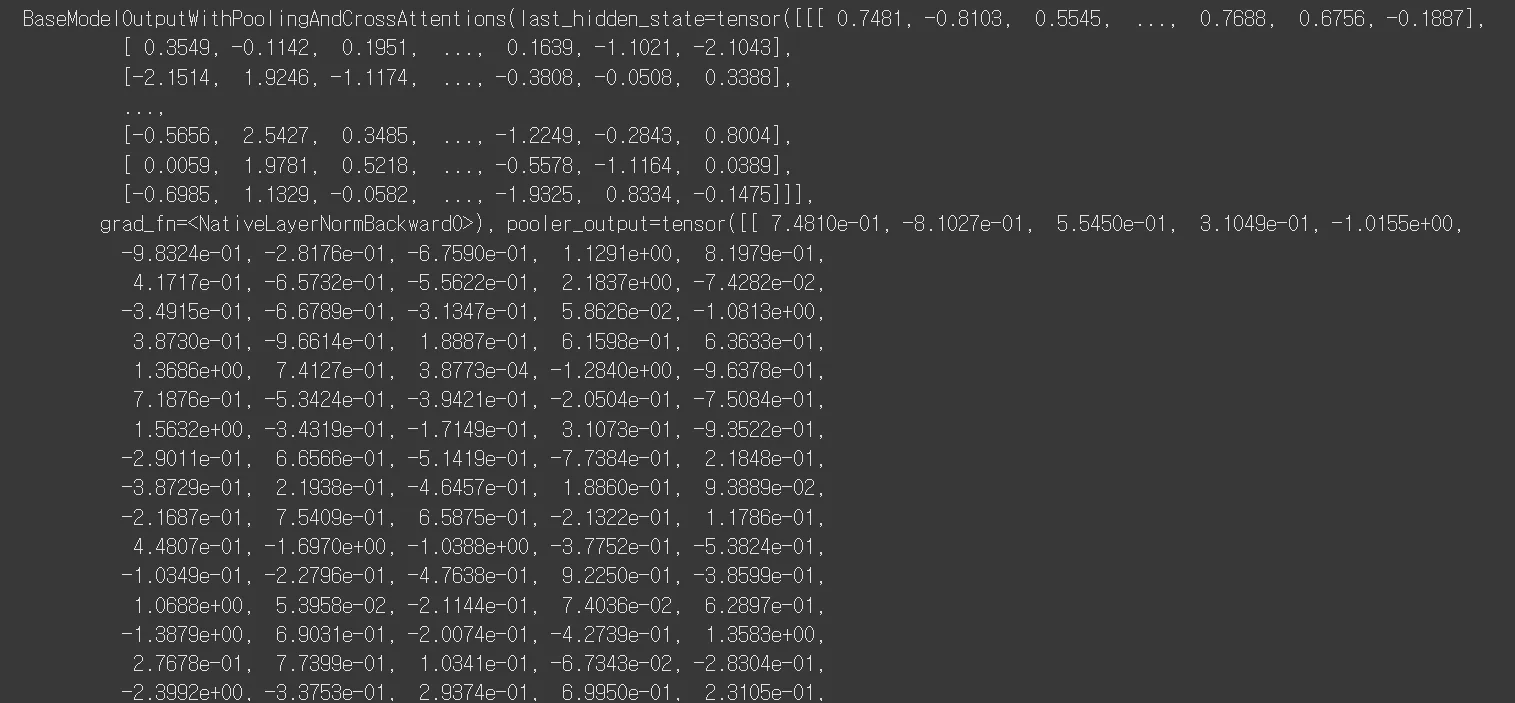
qformer_outputs = model.get_qformer_features(**inputs)
print(qformer_outputs)- 이후
get_qformer_features를 거치면 vision encoder와 Q-Former를 거친 이미지 특징이 추출됩니다.
🔻 실행 결과
🔻 실제 구현 코드

2️⃣ Blip2ForConditionalGeneration
🔷 이미지 캡셔닝
- 텍스트 프롬프트를 사용하지 않습니다.
generate함수를 사용합니다.
from PIL import Image
import requests
from transformers import Blip2Processor, Blip2ForConditionalGeneration
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
processor = Blip2Processor.from_pretrained("Salesforce/blip2-opt-2.7b")
model = Blip2ForConditionalGeneration.from_pretrained(
"Salesforce/blip2-opt-2.7b", load_in_8bit=True, device_map={"": 0}, torch_dtype=torch.float16
) # doctest: +IGNORE_RESULT
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(images=image, return_tensors="pt").to(device, torch.float16)
generated_ids = model.generate(**inputs)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
print(generated_text)🔻 입력 이미지

🔻 실행 결과

🔻 실제 구현 코드
🔷 Visual question answering (VQA)
- 텍스트 프롬프트에 질문을 작성합니다.
generate함수를 사용합니다.
from PIL import Image
import requests
from transformers import Blip2Processor, Blip2ForConditionalGeneration
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
processor = Blip2Processor.from_pretrained("Salesforce/blip2-opt-2.7b")
model = Blip2ForConditionalGeneration.from_pretrained(
"Salesforce/blip2-opt-2.7b", load_in_8bit=True, device_map={"": 0}, torch_dtype=torch.float16
) # doctest: +IGNORE_RESULT
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
prompt = "Question: how many cats are there? Answer:"
inputs = processor(images=image, text=prompt, return_tensors="pt").to(device="cuda", dtype=torch.float16)
generated_ids = model.generate(**inputs)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
print(generated_text)🔻 입력 이미지

🔻 실행 결과

3️⃣ Blip2ForImageTextRetrieval
🔷 Image-Text Matching (ITM)
- 텍스트와 이미지가 일치하는지 이진분류를 수행합니다.
import torch
from PIL import Image
import requests
from transformers import AutoProcessor, Blip2ForImageTextRetrieval
device = "cuda" if torch.cuda.is_available() else "cpu"
model = Blip2ForImageTextRetrieval.from_pretrained("Salesforce/blip2-itm-vit-g", torch_dtype=torch.float16)
processor = AutoProcessor.from_pretrained("Salesforce/blip2-itm-vit-g")
model.to(device)
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
text = "two cats laying on a pink blanket"
# Image-Text Match(ITM)
inputs = processor(images=image, text=text, return_tensors="pt").to(device, torch.float16)
itm_out = model(**inputs, use_image_text_matching_head=True)
logits_per_image = torch.nn.functional.softmax(itm_out.logits_per_image, dim=1)
probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
print(f"{probs[0][0]:.1%} that image 0 is not '{text}'")
print(f"{probs[0][1]:.1%} that image 0 is '{text}'")🔻 입력 이미지

🔻 실행 결과

🔷 Image-Text Contrastive (ITC)
- 텍스트와 이미지가 유사도 점수를 추출합니다.
import torch
from PIL import Image
import requests
from transformers import AutoProcessor, Blip2ForImageTextRetrieval
device = "cuda" if torch.cuda.is_available() else "cpu"
model = Blip2ForImageTextRetrieval.from_pretrained("Salesforce/blip2-itm-vit-g", torch_dtype=torch.float16)
processor = AutoProcessor.from_pretrained("Salesforce/blip2-itm-vit-g")
model.to(device)
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
text = "two cats laying on a pink blanket"
# Image-Text Match(ITM)
inputs = processor(images=image, text=text, return_tensors="pt").to(device, torch.float16)
itm_out = model(**inputs, use_image_text_matching_head=True)
logits_per_image = torch.nn.functional.softmax(itm_out.logits_per_image, dim=1)
probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
print(f"{probs[0][0]:.1%} that image 0 is not '{text}'")
print(f"{probs[0][1]:.1%} that image 0 is '{text}'")🔻 실행 결과

🤔 내 생각
보통 모델을 하나 불러오면 하나의 모델을 통해 생성과 검색을 모두 수행할 줄 알았는데, 실제로 각 기능에 따라 다른 class를 통해 모델을 불러오는 것을 확인하였다. 왜 그럴까 잠깐 생각을 해 보았다. 아마 필요한 기능한 로드하여 메모리 공간을 더 효율적으로 사용하기 위해서인 것 같다. 또 모델을 수정할 때도 전체 모델이 아니라 특정 task에 대한 class만 수정하면 되기 때문에 더 안전할 것 같다.

I'm curious about AI