⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜
🔍BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
🔗 논문: https://arxiv.org/pdf/2301.12597
⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜⬛⬜
📃 BLIP-2에 코드 구현에 대해서는 아래의 글을 참고하시길 바랍니다.
https://velog.io/@tina1975/AI-모델-코드-BLIP-2-모델-코드-이해
📃 BLIP-2 모델을 실제로 실행하는 방법에 대해서는 아래의 글을 참고하시길 바랍니다.
https://velog.io/@tina1975/AI-모델-코드-BLIP-2-모델-실행하기
0️⃣ Abstract
Abstract에서는 BLIP-2 논문을 작성하게 된 계기과 BLIP-2 모델의 강점에 대해 간단하게 설명합니다.
Vision-Language Pretraining (VLP)의 end-to-end 학습 방식은 모델의 크기가 점점 커지면서 더 많은 비용을 필요로 합니다. 따라서 해당 논문에서는 기존에 학습된 이미지 인코더와 대규모 언어모델 (LLM)을 활용하여 더 효율적인 학습 방법을 제시합니다.
논문에서는 BLIP-2를 통해 더 적은 파라미터를 학습함에도 불구하고 다양한 시각-언어 task에서 뛰어난 성능을 보여줍니다. 또한 이미지-텍스트 생성에서 기존에 없던 Zero-shot 능력이 생겨남을 보여줍니다.
1️⃣ Introduction
1장에서는 기존 Vision-Language Pre-training(VLP) 연구의 문제점과 이를 해결하기 위한 BLIP-2의 접근 방식에 대해 설명합니다.
🔷 기존 VLP의 한계
Vision-language pre-training (VLP) 연구는 계속해서 발전하고 있습니다. 이에 따라 Vision-language model은 점점 더 다양한 task에서 뛰어난 성능을 보여주고 있습니다.
하지만 지금까지 등장한 Vision-Language Model (VLM)은 모델의 크기가 크고 end-to-end 방식으로 학습됐기에 많은 계산 비용과 학습 데이터를 필요로 합니다.
🔷 논문의 제안
논문에서는 사전 학습된 이미지 모델과 언어 모델을 부트스트래핑하여 더 효율적인 VLP 방식을 제안합니다. 여기서 부트스트래핑은 기존의 모델들을 활용하여 더 효율적인 모델을 개발한다는 의미 정도로 이해하시면 됩니다.
사전 훈련된 이미지 모델을 사용하여 이미지의 특징을 잘 추출할 수 있고, 대규모 언어모델 (LLM)을 통해 텍스트 데이터에 대한 높은 이해도와 zero-shot과 같은 능력을 활용할 수 있습니다. 또한 사전 학습된 모델을 사용하여 가중치를 고정하는 방식을 통해 Catestrophic forgetting 문제 역시 해결할 수 있습니다.
📃 Catestrophic forgetting에 대해서는 아래의 [논문리뷰]를 참고하시길 바랍니다.
https://velog.io/@tina1975/논문리뷰-CONTINUAL-LEARNING-AND-CATASTROPHIC-FORGETTING
이미지 모델과 LLM을 활용하여 VLM 모델을 개발하기 위해서는 두 모델이 각자 처리하는 데이터가 서로 호환될 수 있도록 하는 것이 중요합니다.
이를 위해서 논문에서는 2단계로 구성된 Vision-Language Pretraining (VLP) 방법을 제시합니다.
첫 번째는 Querying Transformer (Q-Former)를 활용하여 이미지 인코더가 출력한 데이터에서 중요한 시각적 특징을 가져오는 방법입니다. Figure 1의 왼쪽 자료를 보시면 이미지 인코더가 추출한 데이터에서 Query 벡터를 통해 중요한 데이터를 가져오는 것을 확인할 수 있습니다.
두 번째는 Q-Former가 가져온 시각적 특징을 LLM이 이해할 수 있는 형태로 출력할 수 있도록 학습하는 것입니다.

Figure 1. Overview of BLIP-2’s framework. We pre-train a lightweight Querying Transformer following a two-stage strategy to bridge the modality gap. The first stage bootstraps vision-language representation learning from a frozen image encoder. The second stage bootstraps vision-to-language generative learning from a frozen LLM, which enables zero-shot instructed image-totext generation (see Figure 4 for more examples).
논문의 저자는 해당 논문에서 제안하는 VLP 방법을 BLIP-2라고 이름 붙였습니다.
지금까지의 내용을 정리하면 BLIP-2는 기존의 VLP 방법의 한계를 극복하기 위해 사전 학습된 이미지 모델과 LLM을 사용할 것을 제안합니다. 그리고 서로의 데이터가 호환될 수 있도록 Query-Transformer(Q-Former)를 통해 데이터를 연결합니다.
Q-Former는 서로 다른 종류의 데이터를 연결하기 위해 2단계의 학습을 진행합니다. 첫 번째는 입력 텍스트의 내용을 참고하여 이미지의 특징을 잘 가져올 수 있도록 하는 Representation Learning 단계입니다. 두 번째는 Q-Former의 출력을 LLM이 이해할 수 있도록 Q-Former의 출력을 조정하는 Generative Learning 단계입니다.
이러한 방식을 통해 BLIP-2는 시각적 질문에 대한 대답, 이미지-텍스트 검색, 이미지 캡셔닝과 같은 다양한 task에서 뛰어난 성능을 보여줍니다. 또한 LLM 모델로 OPT나 Flan-T5 모델을 사용할 경우 이미지에 대한 zero-shot이나 높은 추론 능력을 발휘함을 확인하였습니다.
🔻 BLIP-2의 zero-shot 예시

Figure 4. Selected examples of instructed zero-shot image-to-text generation using a BLIP-2 model w/ ViT-g and FlanT5XXL, where it shows a wide range of capabilities including visual conversation, visual knowledge reasoning, visual commensense reasoning, storytelling, personalized image-to-text generation, etc.
또한 사전 학습된 모델과 경량화된 Query-Transformer(Q-Former)를 활용하기 때문에 Flamingo과 같은 모델에 비해 54배 적은 학습 파라미터를 사용함에도 불구하고 제로샷 VQAv2에서 8.7% 더 뛰어난 성능을 보였습니다. BLIP-2는 성능을 높이기 위해 더 좋은 이미지 모델이나 LLM 모델로 교체할 수 있다는 이점 역시 존재합니다.
📕 정리
- BLIP-2 논문의 등장배경인 VLP의 한계를 살펴보았습니다.
- 기존의 VLP 한계를 극복하기 위해 사전 학습된 모델과 Q-Former 모델을 사용하는 것을 배웠습니다.
- Q-Former를 학습하기 위해서는 Representation Learning과 Generative Learning 2단계 과정을 거쳐야 함을 살펴보았습니다.
- BLIP-2 모델은 기존의 VLP에 비해 더 적은 파라미터를 학습함에도 불구하고 더 좋은 성능을 발휘할 수 있음을 확인하였습니다.
2️⃣ Related Work
2장에서는 기존의 Vision-Language Pre-training(VLP) 연구들을 두 가지 주요 범주로 나누어 설명합니다.
🔷 2-1 End-to-end Vision-Language Pre-training
End-to-end Vision-Language Pre-training(End-to-end VLP)은 이미지와 텍스트 같은 다양한 modality의 데이터를 함께 학습하여, 다양한 시각-언어 관련 작업에서 성능을 향상시키는 Multimodal foundation model을 만드는 것을 목표로 합니다.
🔻 End-to-end Vision-Language Model의 종류
🔸 Dual-encoder architecture
- 이미지 데이터를 처리하는 encoder와 텍스트 데이터를 처리하는 encoder를 별도로 가지고 있는 구조입니다.
- 각 encoder가 주어진 데이터를 독립적으로 처리한 후 추출된 데이터를 비교하여 이미지 데이터와 텍스트 데이터가 어떤 관계를 맺고 있는지 학습하고 추론합니다.
- 대표적인 모델: CLIP, ALIGN
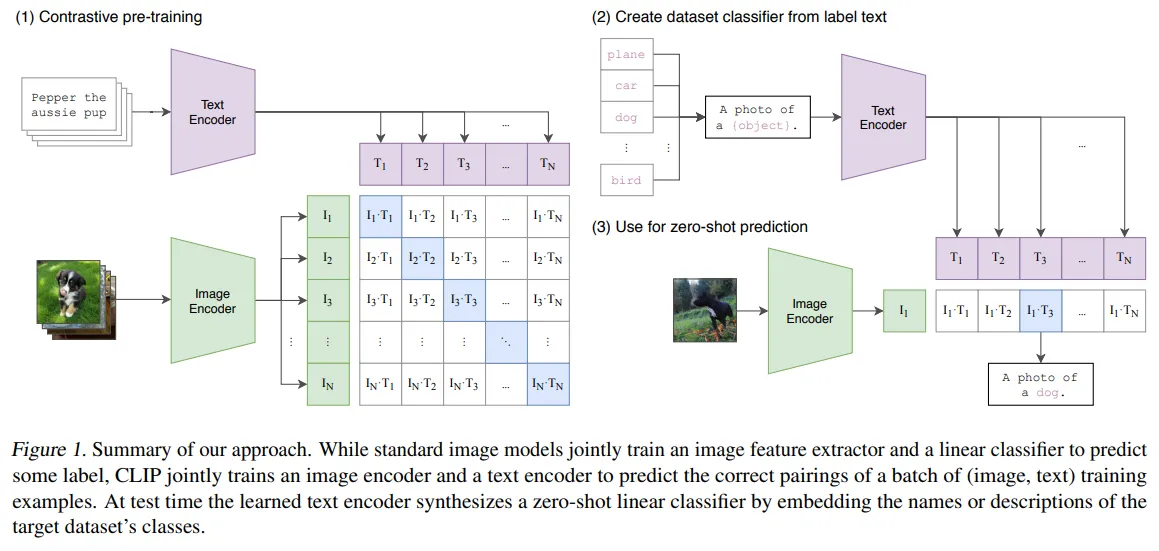
출처: https://arxiv.org/pdf/2103.00020
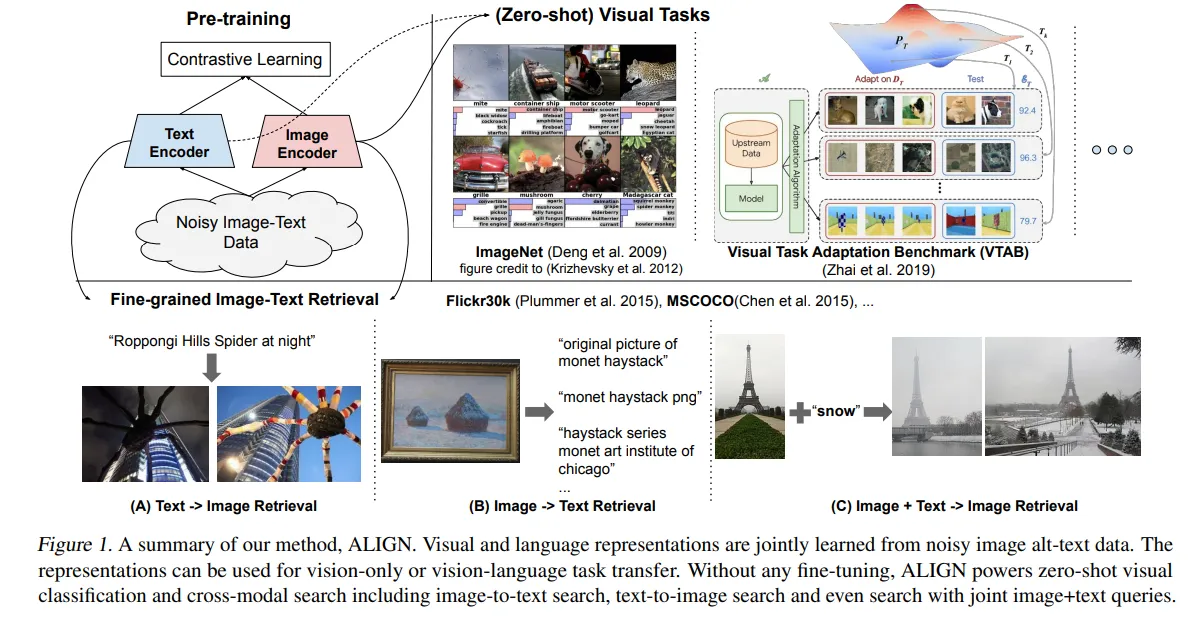
출처: https://arxiv.org/pdf/2102.05918
🔸 Fusion-encoder architecture
- 이미지 데이터와 텍스트 데이터를 하나의 encoder로 함께 처리합니다.
- 이미지 데이터와 텍스트 데이터를 섞으며 이해하기 때문에 데이터를 더 깊이 이해할 수 있습니다.
- 일반적으로 계산 비용이 큽니다.
- 대표적인 모델: LXMERT, UNITER

출처: https://arxiv.org/pdf/1908.07490
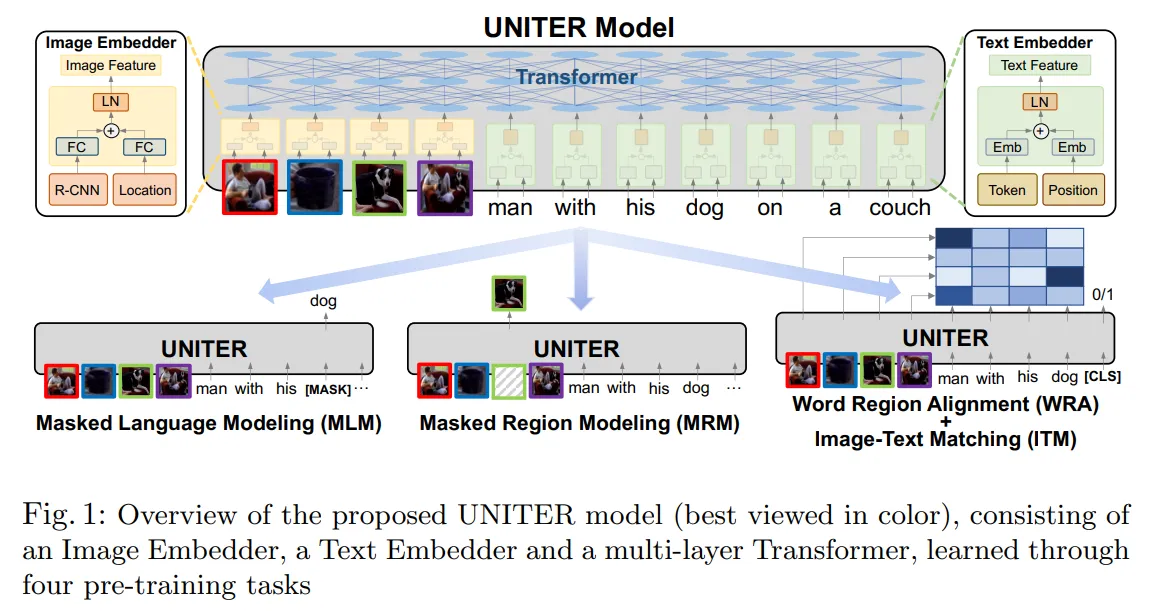
출처: https://arxiv.org/pdf/1909.11740
🔸 Encoder-decoder architecture
- 생성 task를 위한 architecture라고 이해하면 됩니다.
- Encoder를 통해 입력 이미지나 텍스트를 이해하고, 디코더를 통해 텍스트를 생성합니다.
- 예를 들어, 이미지를 입력하면 이미지에 대한 캡션을 생성하는 작업을 생각할 수 있습니다.
- 대표적인 모델: OFA
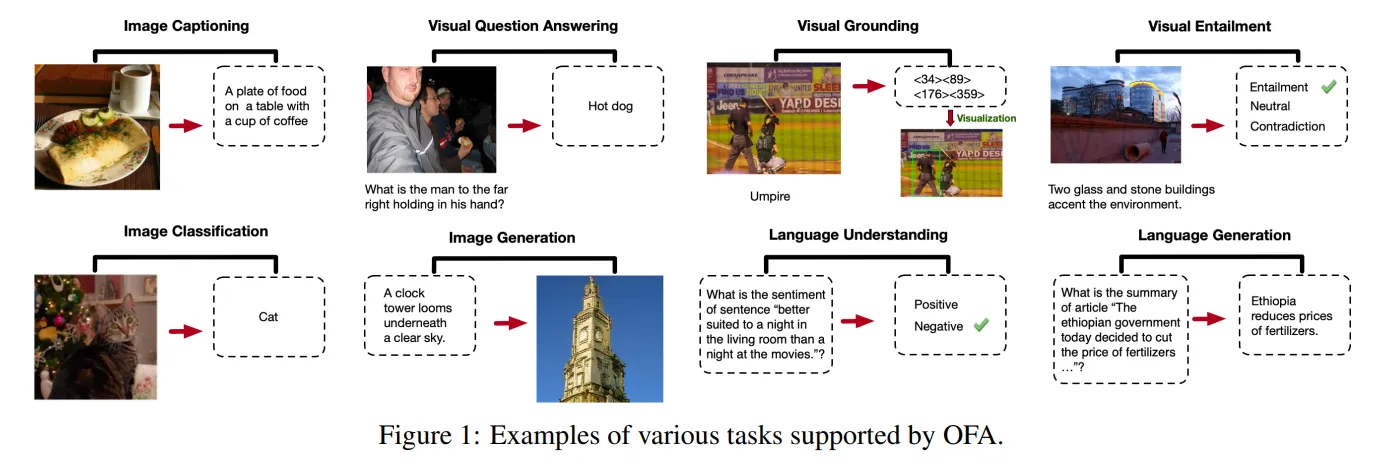
출처: https://arxiv.org/pdf/2202.03052
🔸 Unified transformer architecture
- 다양한 vision-language task를 하나의 단일모델로 처리할 수 있는 구조이다.
- 대표적인 모델: BLIP
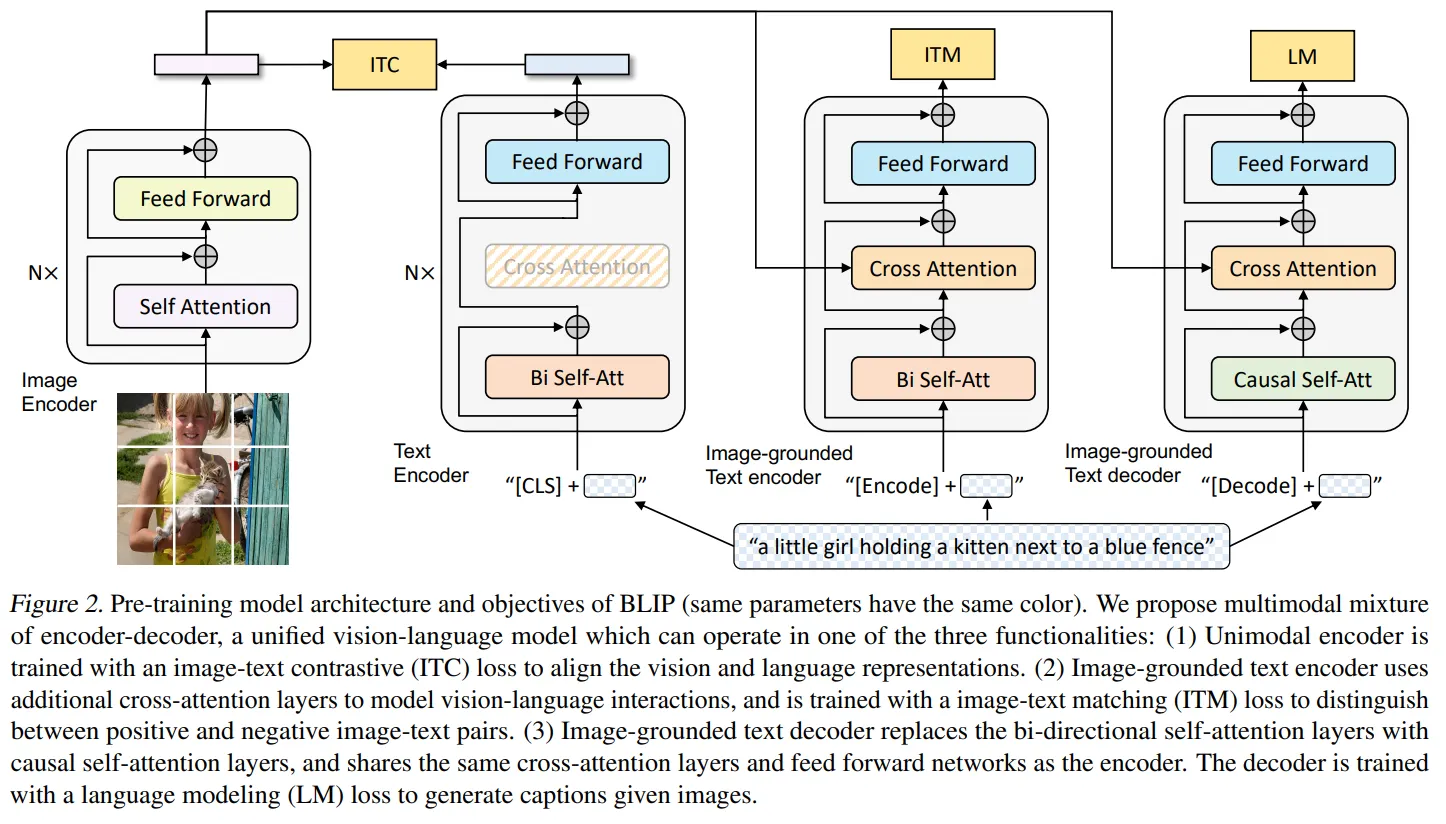
출처: https://arxiv.org/pdf/2201.12086
🔻 End-to-end Vision-Language Pretraining의 종류
🔸 Image-text Contrastive Learning
- 이미지-텍스트 쌍이 의미적으로 잘 연결되었는지 학습합니다.
- 이미지-텍스트 쌍이 의미적으로 유사한 경우와 유사하지 않은 경우를 함께 학습합니다.
- 이 방식을 통해 모델이 입력된 이미지와 텍스트가 잘 맞는지 비교할 수 있습니다.
- 이미지 데이터와 텍스트 데이터가 전반적으로 유사한지 판단하는 학습 방법입니다.
- 유사도 정도에 대한 회귀값을 출력합니다.
🔸 Image-text Matching
- 이미지와 텍스트가 서로 관련된 것인지 이진분류를 하는 학습방법입니다.
- 대조 학습에 비해 더 디테일한 구분을 수행합니다.
- 이미지와 텍스트의 정확한 매칭을 판단하는 학습방법입니다.
- 매칭 여부에 대한 이진 분류를 수행합니다.
🔸 (Masked) Language Modeling
- 텍스트의 일부를 masking하고 이를 예측하도록 하는 학습방법입니다.
- 모델이 예측을 진행할 때는 입력된 이미지를 참고하여 예측을 진행합니다.
- 이를 통해 시각적 정보와 언어 정보에 대한 관계를 학습할 수 있습니다.
🔻 Limitations of Existing VLP Methods
🔸 높은 계산 비용
- End-to-end Vision-Language Pretraining은 많은 Image-text 쌍의 데이터로 학습합니다.
- 모델의 크기가 커짐에 따라 계산 비용이 점점 증가합니다.
🔸 기존 모델 활용의 어려움
- VLP는 기존의 모델 구조를 Image-text 쌍의 데이터로 처음부터 다시 학습합니다.
- 그 결과 기존에 이미 학습된 모델을 사용할 수 없다는 한계가 존재합니다.
🔷 2-2 Modular Vision-Language Pre-training
- 기존의 End-to-end Vision-Language Pre-training은 모델 전체를 모두 학습하는 방식입니다.
- Modular Vision-Language Pre-training은 기존의 학습된 모델을 가져와 각 모델의 파라미터를 frozen 한 후 학습을 진행합니다.
🔻 Frozen한 모델 활용하기
🔸 Frozen Image encoder
- 기존에 이미지의 특징을 추출하기 위해 이미지 encoder를 frozen하여 활용한 경우가 있습니다.
- CLIP 모델에서 이미 학습된 Vision transformer를 활용하는 경우가 대표적인 사례입니다.
🔸 Frozen Language Model
- 이미지 특징을 통해 텍스트 생성을 수행할 때 기존에 학습된 LLM을 활용합니다.
- 이미지 encoder을 fine-tuning하여 encoder의 출력을 소프트 프롬프트로 활용합니다.
- 즉 벡터 형태로 LLM 모델에 입력합니다.
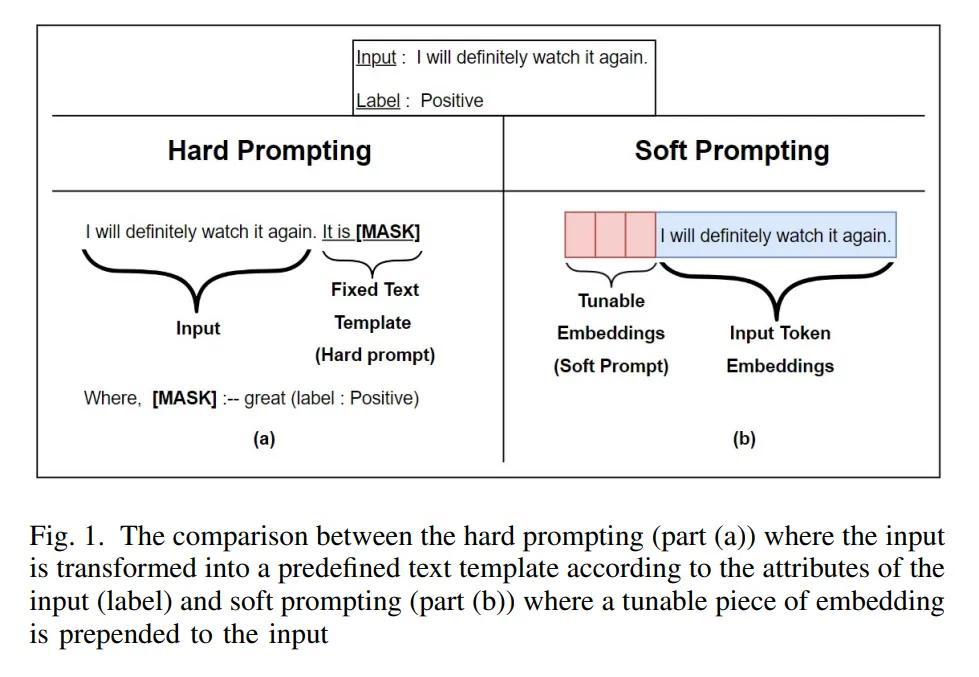
출처: https://arxiv.org/pdf/2212.02924
- Flamingo🦩의 경우 Image encoder의 출력을 LLM 모델 내부에 cross-attention을 통해 주입합니다.
- LLM 모델이 이미지 정보에 대한 링거를 맞는다고 이해하시면 됩니다.
- 이때는 링거 호스, 즉 cross-attention layer만 학습하여 고정된 LLM 모델을 활용합니다.
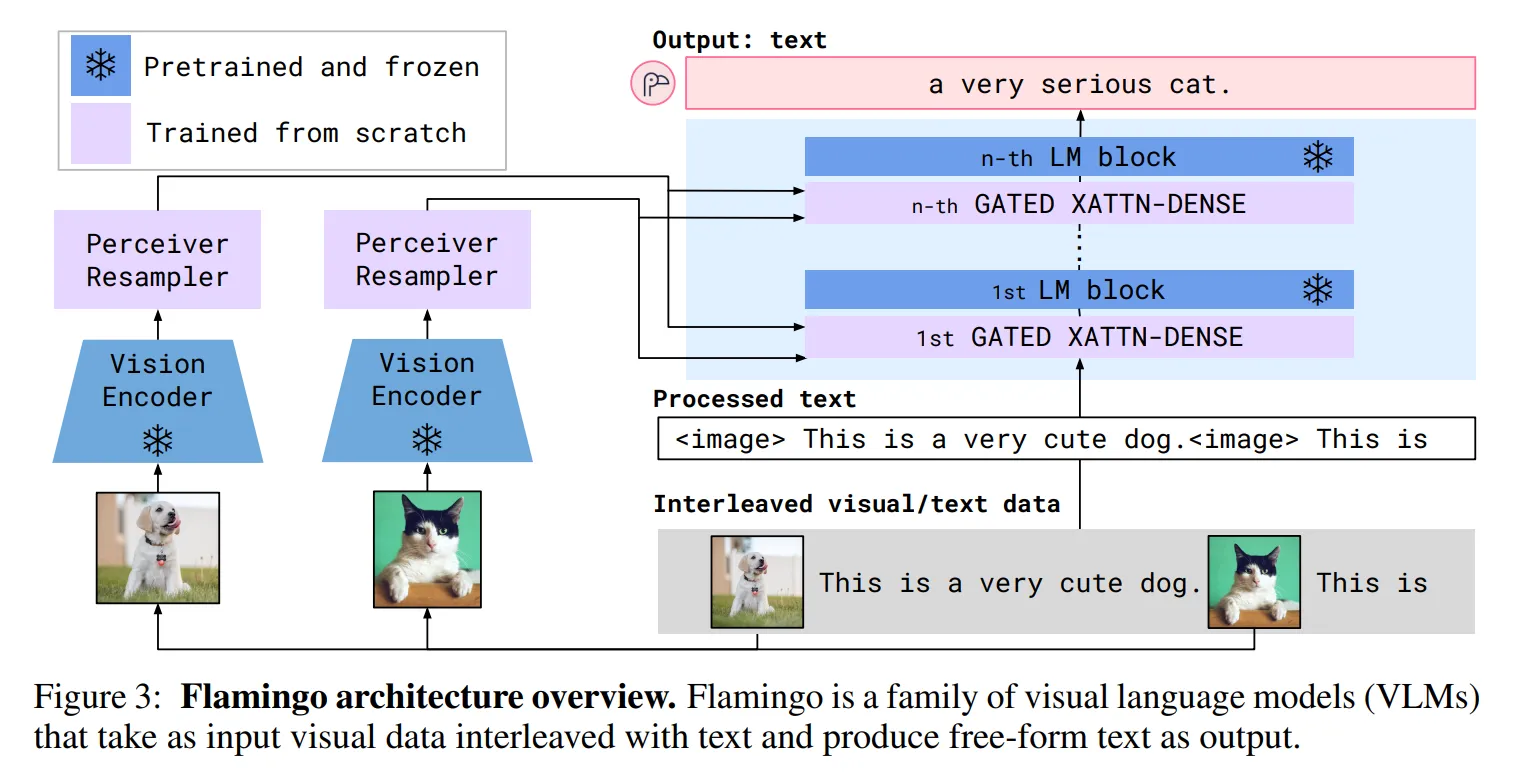
출처: https://arxiv.org/pdf/2204.14198
🔻 BLIP-2의 Frozen model 활용
- BLIP-2는 Image encoder와 LLM 모두 학습된 모델을 가져와 파라미터를 고정합니다.
- 두 모델을 연결하는 구조만 학습을 진행하여 기존의 End-to-end Vision-Language Pre-training보다 훨씬 적은 파라미터를 학습합니다.
- 이러한 방식을 통해 더 적은 계산 비용으로 VLP 학습을 진행합니다.
3️⃣ Method
3장에서는 사전 학습된 이미지 encoder와 LLM 모델을 연결하는 Query Transformer(Q-Former)의 구조와 2단계 학습 방법에 대해 설명합니다.
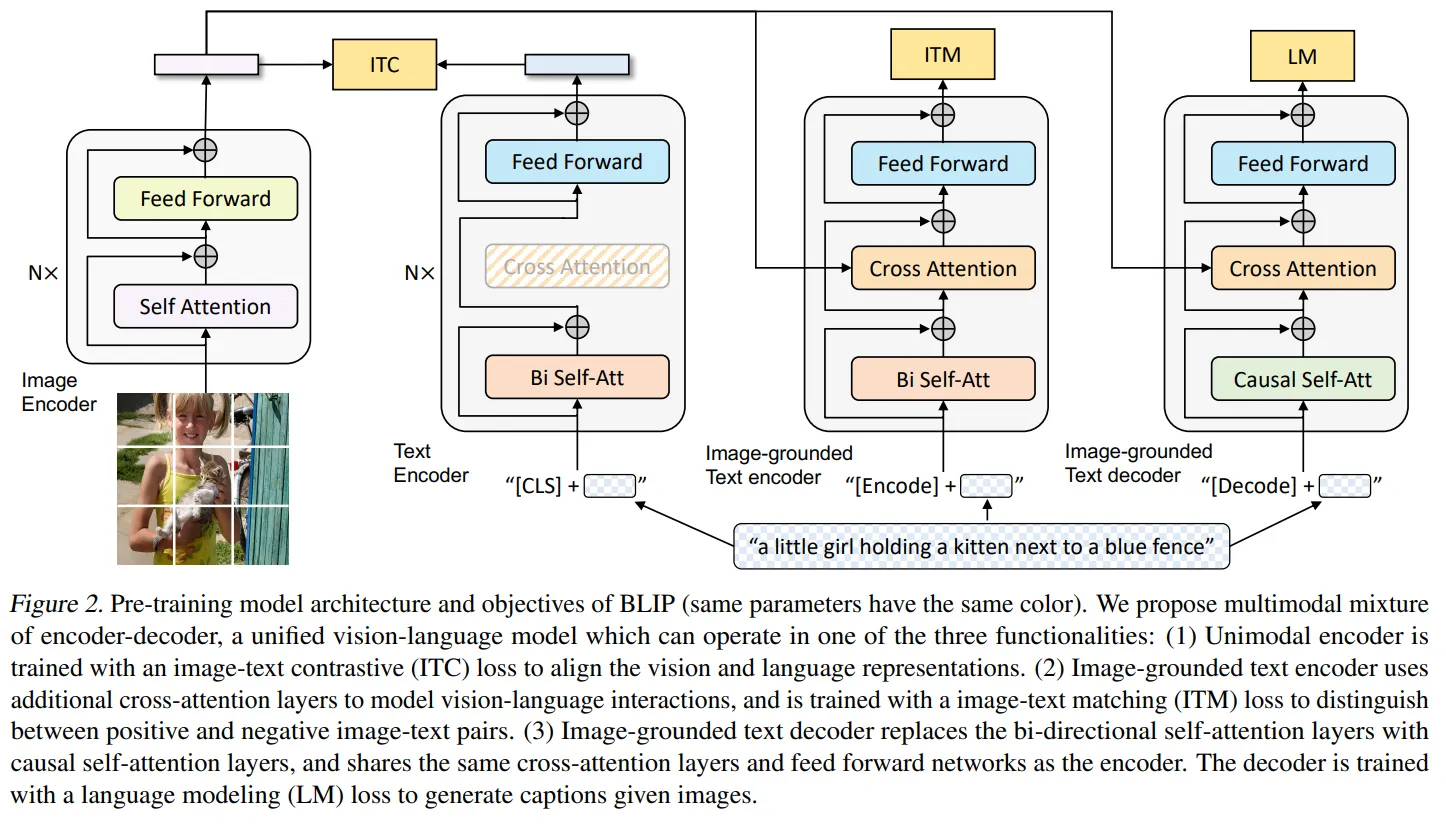
🔷 3-1 Model Architecture
🔻 Q-Former의 목적
- Q-Former는 이미지 encoder와 LLM 사이에 존재하는 modality gap을 연결하는 역할을 수행합니다.
🔻 Q-Former의 구조
🔸 Image transformer
-
이미지 encoder로부터 시각적 특징을 추출하는 역할을 수행합니다.
-
이미지 encoder와 연결되어 있는 transformer 입니다.
🔸 Text transformer
-
텍스트 encoder와 decoder 역할을 수행합니다.
-
Figure 2에 있는 것처럼 N개의 text transformer block이 encoder와 decoder의 역할을 수행한다.
-
Encoder처럼 동작할 때는 N개의 Block을 한번에 통과한 후 문장 전체의 의미가 담긴 [CLS] 토큰을 활용합니다.
-
Decoder처럼 동작할 때는 [Dec]이라는 토큰을 시작으로 Auto-regressive하게 동작하여 문장을 생성합니다.
🔸 Query Embedding
-
Query Embedding은 transformer 레이어를 흐르는 데이터이지만 학습 가능하기 때문에 학습 파라미터로 간주합니다.
-
논문에서는 총 32개의 Query를 사용합니다.
-
학습 과정을 통해 각 Query가 이미지에 대해 어떤 질문을 할지 학습합니다.
-
학습이 완료되면 각 Query는 이미지 encoder의 출력에 최적화된 질문을 던지는 것입니다.
🔸 파라미터 수
- 총 1억 8,800만개의 파라미터로 구성되어 있습니다.
🔻 Q-Former의 주요 데이터 흐름
-
Q-Former에서 학습 가능한 Query Embedding을 생성합니다. 향후 레이어틀 거치면서 해당 Query Enbedding에 이미지의 특징이 담깁니다.
-
Self-attention 모듈은 입력된 데이터의 관계를 파악하여 맥락적 이해를 높입니다. Figure 2의 self-attention 모듈을 보시면 Image transformer와 Text transformer의 self-attention이 양방향, 단방향, 개별적으로 작동하여 서로 정보를 공유하는 과정을 살펴볼 수 있습니다.
-
Image transformer의 cross-attention 모듈을 통해 이미지 encoder의 출력 데이터 중 관심 있는 특징을 Query embedding이 가져오는 것을 확인할 수 있습니다.
-
Feed Forward는 position-wise 구조를 통해 개별적으로 데이터를 정제합니다.
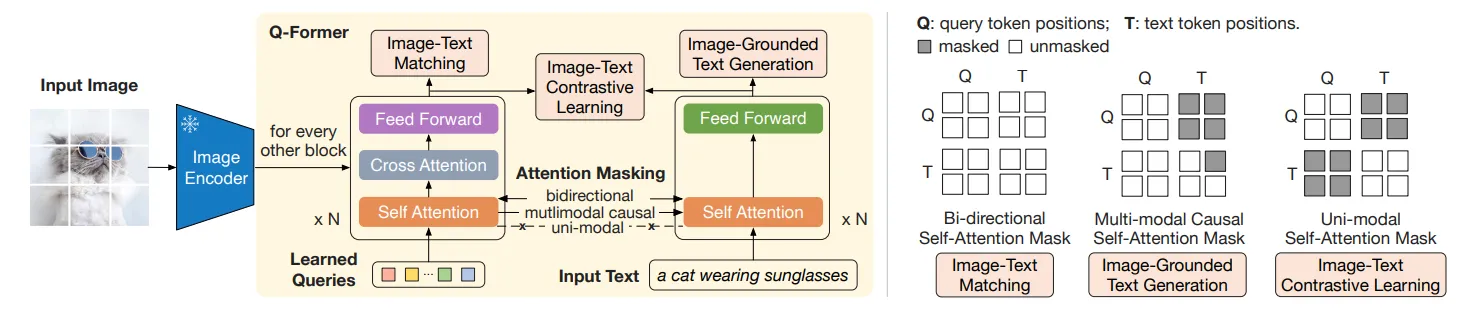
Figure 2. (Left) Model architecture of Q-Former and BLIP-2’s first-stage vision-language epresentation learning objectives. We jointly optimize three objectives which enforce the queries (a set of learnable embeddings) to extract isual representation most relevant to the text. (Right) The self-attention masking strategy for each objective to control query-text interaction.
🔷 3-2 Bootstrap Vision-Language Representation Learning from a Frozen Image Encoder
🔻Representation Learning의 학습전략
Q-Former는 Image Encoder로부터 시작적 특징을 잘 추출할 수 있도록 학습합니다. 이때 사용되는 학습 전략은 3가지입니다.
Image-Text Contrastive Learning (ITC): 대조학습이라는 이름처럼 이미지와 텍스트의 전반적이 의미적 유사성에 대해 학습합니다.
Image-Text Matching (ITM): 이미지와 텍스트 데이터의 일치 여부를 확인합니다. 이를 통해 이미지와 텍스트이 디테일한 의미적 관계를 학습합니다.
Image-grounded Text Generation (ITG): 이미지를 바탕으로 텍스트를 생성하는 방법을 학습합니다. 이를 통해 Q-Former가 텍스트 생성을 위해 필요한 정보를 잘 가져올 수 있도록 학습합니다.
Q-Former는 위 3가지 학습 전략을 동시에 사용하여 학습을 진행합니다.
🔻 Representation Learning에 대한 Loss function
- 논문에는 Loss function이 없지만 간단하게 표현해보면 아래와 같을 것 같습니다.
- Loss fucntion의 형태는 기존에 잘 알려진 형태라 자세한 설명은 생략하겠습니다.
🔸 Image-Text Contrastive Learning (ITC)

출처: https://arxiv.org/pdf/2103.00020
- CLIP 모델의 contrastive Loss function과 동일한 구조입니다.
🔸 Image-Text Matching (ITM)
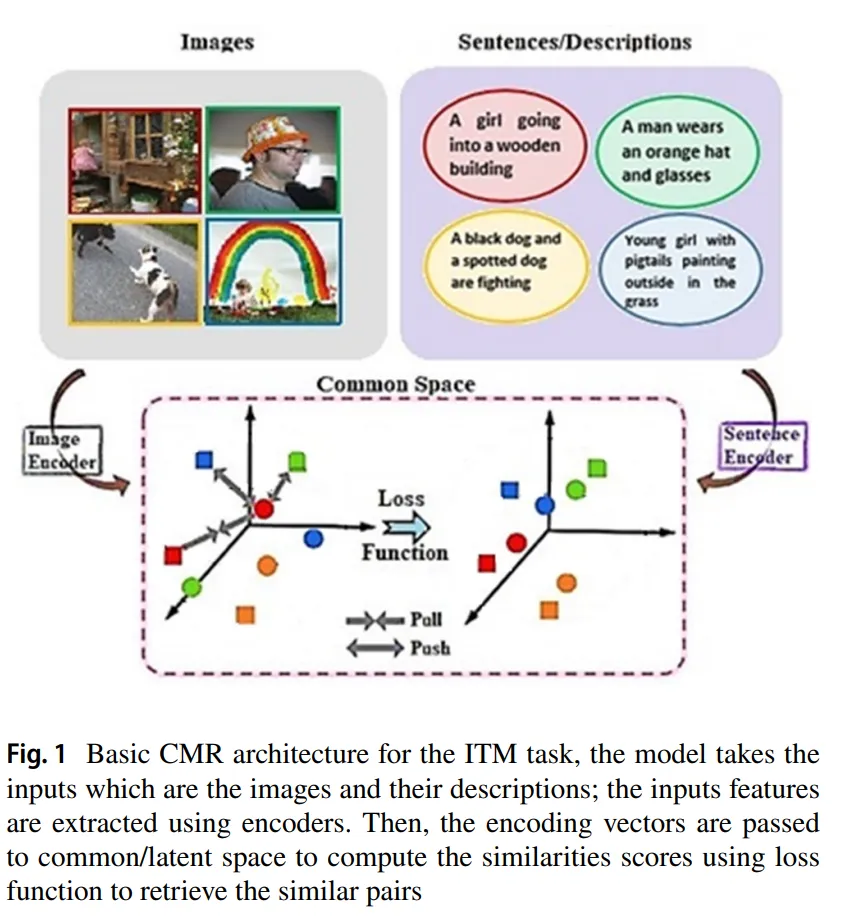
출처: https://link.springer.com/article/10.1007/s44196-023-00260-3>
- 이진 분류의 Loss function과 동일한 구조입니다.
🔸 Image-grounded Text Generation (ITG)
- 생성 모델의 Loss function과 동일한 구조입니다.
🔸 최종 Loss function
- 각 Loss 값의 합으로 구성됩니다.
🔻 Image-Text Contrastive Learning (ITC)
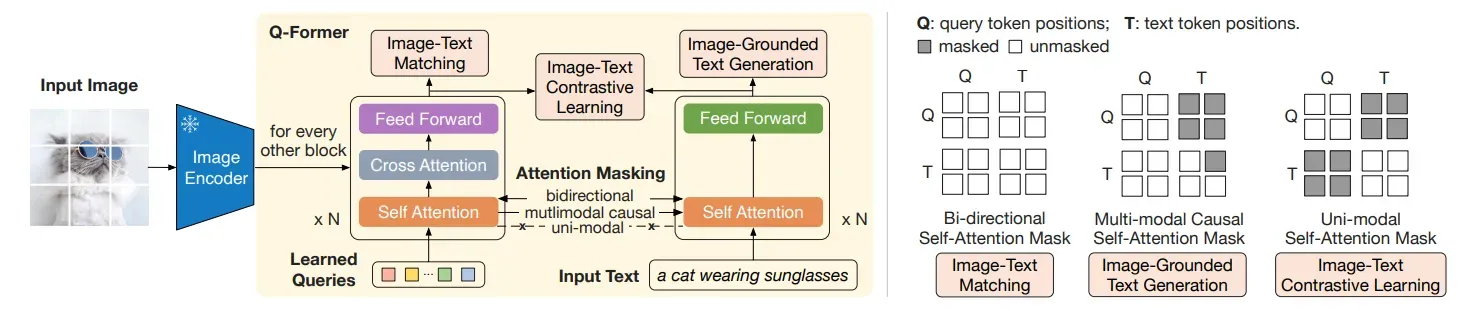
Image-Text Contrastive Learning은 Image transformer와 text transformer가 출력한 벡터의 유사도를 계산하는 학습 방법입니다. 이때 Image transformer의 출력은 입력 때 사용했던 Query Embedding의 개수와 같습니다. 그리고 text transformer가 출력한 text vector는 문장 전체의 의미가 담긴 [CLS] 토큰 벡터를 사용합니다. 이후 각 Query 벡터와 [CLS] 벡터의 유사도를 계산 후 가장 큰 유사도 값을 최종 유사도로 사용합니다.
🔸 작동 방식
- Self-attention은 uni-modal 방식으로 작동합니다.
- 따라서 이미지와 텍스트 transformer 간 정보 공유는 없으며, 개별적으로 데이터 특징 추출이 수행됩니다.
- Image transformer는 cross attention 과정을 통해 이미지의 특징을 가져옵니다.
- 최종적으로 출력된 유사도 중 관련이 있는 쌍은 유사도가 1이 되도록 학습합니다.
🔻 Image-Text Matching (ITM)
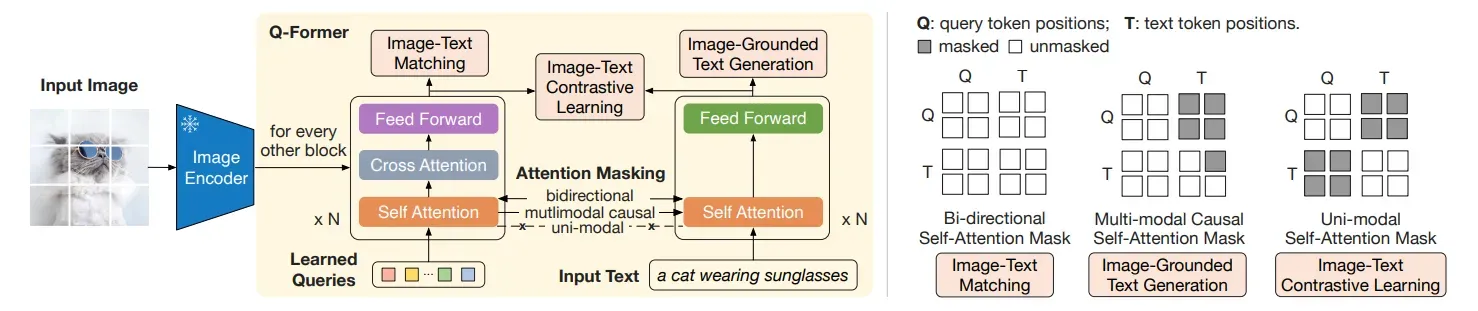
Image-Text Matching 방식은 Image transformer와 text transformer가 출력한 정보가 의미적으로 일치하는지 판단하는 과정입니다. 일치 여부를 판단하는 것이기에 단순히 유사한 정도가 아니라 세부적인 특징까지 고려하여 판단이 이루어집니다.
💡 그렇다면 질문!!
ITC에서는 각 데이터를 따로 처리하여 유사도를 측정하였는데 ITM에서는 왜 Bidirectional 방식을 사용하였을까요?
ITM은 텍스트 데이터와 이미지 데이터의 세부적인 특징을 비교한다고 했는데 어떻게 그게 가능한건가요??
🤔 나의 생각은?
우리가 transformer 모델을 통해 처리하는 Query 벡터, text 벡터 모두 각자의 의미를 담고 있을 것이다. 하지만 그 값이 discrete한 것이 아니라 다양한 의미가 담긴 continuous한 값이다. 따라서 세부적인 요소를 우리가 정확하게 잘라 가져오는 것은 쉽지 않다.
그런데 우리가 알고 싶은 것은 이미지와 텍스트의 세부적인 정보가 일치하는지 일치하지 않는지 여부이다. 그래서 Q-Former에서는 이미지 데이터와 텍스트 데이터를 함께 self-attention을 수행하는 과정을 거친다. 이것이 Bidirectional 방식이다.
이미지 데이터와 텍스트 데이터가 함께 self-attention 과정을 거치면 서로 유사한 데이터끼리는 유사도가 높아 서로 더 많이 정보를 교환할 것이다. 만약 이미지와 텍스트가 디테일하게 똑같은 데이터라면 각 벡터의 유사도가 높아서 서로 정보를 많이 교환할 것이다. 이 과정을 N개의 Block을 거치며 반복하면 두 데이터는 서로 유사해질 것이다.
반면 이미지와 텍스트의 데이터가 서로 유사하지만 디테일하게 다른 부분이 있다면, 그 부분은 유사도가 낮아 정보의 교환이 잘 이루어지지 않을 것이다. 그 결과 해당 디테일에 있어서는 이미지와 텍스트가 자신이 가지고 있는 특징을 계속 고유하게 유지할 것이다.
Bidirectional 방식을 통해 디테일하게 일치하는 데이터는 더욱 유사한 데이터가 될 것이고, 디테일하게 다른 데이터는 각자의 특징을 유지한 채 최종 벡터로 출력될 것이다.
이렇게 가공된 정보를 통해 두 데이터가 서로 디테일하게 일치하는지 아닌지를 분류할 수 있습니다.
✨ 그래서 가장 중요한 것
그래서 이 학습 과정을 통해서 최종적으로 학습하는 것은 무엇일까요?? ITM 방식으로 분류를 잘 하기 위해서는 각 Image transformer와 text transformer가 디테일한 특징의 벡터 간 유사도 계산이 잘 되도록 해당 특징을 부각(스칼라 값이 커지는 느낌?🤔)시켜야 할 것입니다. 그래서 Query Embedding과 Feed Forward에서 디테일한 특징이 잘 부각되도록 파라미터 업데이트가 진행됩니다.
🔻 Image-grounded Text Generation (ITG)
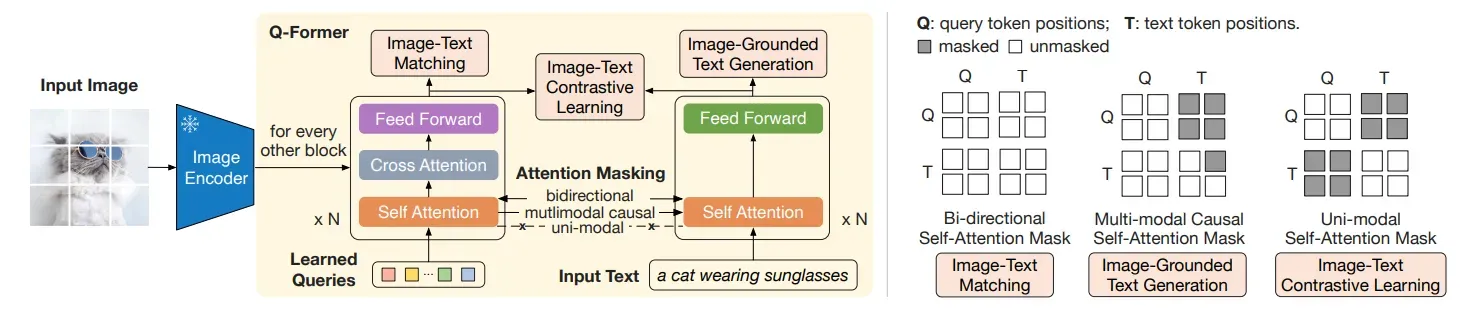
Image-grounded Text Generation에서는 text transformer가 지금까지 입력으로 사용되었던 학습 데이터의 텍스트 데이터를 생성할 수 있도록 학습합니다. 이때는 self-attention을 multimodal causal이라는 방식으로 masking을 하는데 텍스트 데이터만 이미지 데이터의 정보를 참조할 수 있도록 하는 방법입니다. 즉 이미지 Query 벡터는 텍스트 데이터의 정보를 가져올 수 없습니다. 이러한 방식으로 통해 text transformer는 계속해서 Image transformer의 이미지 정보를 참고하여 text generation을 수행합니다.
🔸 작동 방식
- Text transformer에 입력으로 [DEC] 토큰이 입력됩니다.
- Multimodal causal 방식을 통해 Text transformer가 Image transformer의 정보를 가져옵니다.
- 최종 N Block을 통과하는 동안 이미지 정보를 참고하여 [DEC] 다음에 올 첫 단어를 생성합니다.
- Auto-regressive한 방식으로 [DEC] 토큰과 생성된 첫 단어가 다시 text transformer에 입력됩니다. - 이 과정을 반복하여 이미지에 대한 문장을 생성합니다.
🔷 3-3 Bootstrap Vision-to-Language Generative Learning from a Frozen LLM
Generative Learning에서는 Q-Former가 최종 출력한 Query 벡터를 LLM에게 전달하여 LLM이 해당 정보를 이해하여 텍스트를 생성할 수 있도록 학습합니다. 이때 Q-Former의 출력을 LLM이 이해할 수 있는 텍스트 임베딩으로 변환해주는 선형 레이어를 추가하고, 해당 선형 레이어를 학습하여 두 modality가 서로 호환 가능하도록 합니다.
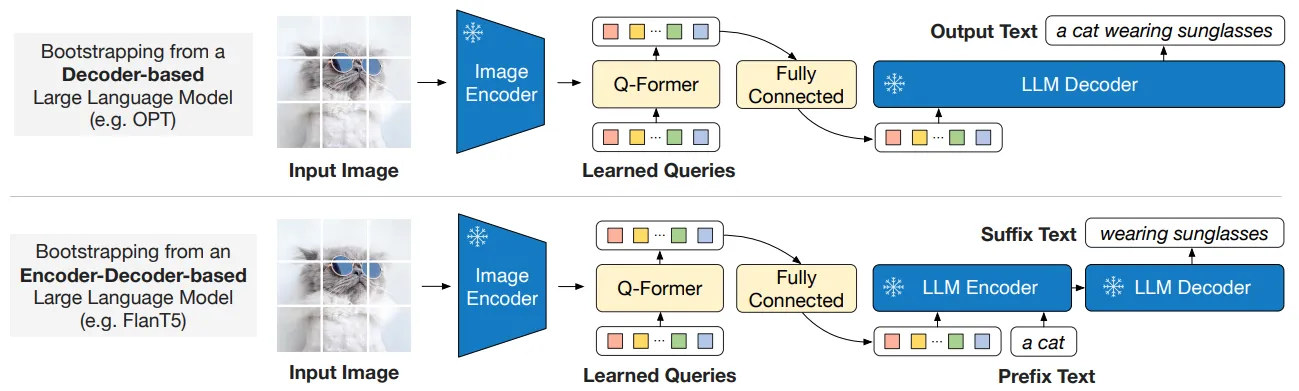
Figure 3. BLIP-2’s second-stage vision-to-language generative pre-training, which bootstraps from rozen large language models (LLMs). (Top) Bootstrapping a decoder-based LLM (e.g. OPT). (Bottom) Bootstrapping an encoder-decoder-based LLM (e.g. FlanT5). The fully-connected layer adapts from the output dimension of the Q-Former to the input dimension of the chosen LLM.
🔻 LLM 구조에 따른 학습 방식
🔸 Decoder 기반 LLM

Decoder 기반 LLM에는 선형 변환을 거친 Q-Former의 출력을 Decoder의 입력을 넣습니다. Decoder 기반 LLM은 이 정보를 바탕으로 Auto-regressive하게 이미지에 대한 문장을 생성합니다.
🔸 Encoder-Decoder 기반 LLM

Encoder-Decoder 기반 LLM은 선형 변환을 거친 Q-Former의 출력과 이미지에 대한 텍스트 데이터 앞부분을 함께 Encoder에 넣습니다. 이후 Decoder에서 이미지와 텍스트에 대한 정보를 참고하여 텍스트의 뒷 부분을 생성하도록 학습합니다.
🔷 3-4 Model Pre-training
🔻 Pre-training Data
아래의 데이터에서 총 1억 2천 9백만 (129M)개의 데이터를 가져와 BLIP-2 학습을 진행하였습니다.
🔸 COCO (Common Objects in Context)
- 객체 인식, 세분화, 캡셔닝 등 다양한 컴퓨터 비전 작업을 위한 인기 있는 데이터셋입니다.
📃 관련 논문: https://arxiv.org/pdf/1405.0312
🔸 Visual Genome
- 이미지 내의 객체, 속성, 관계에 대한 풍부한 주석을 포함하는 데이터셋입니다.
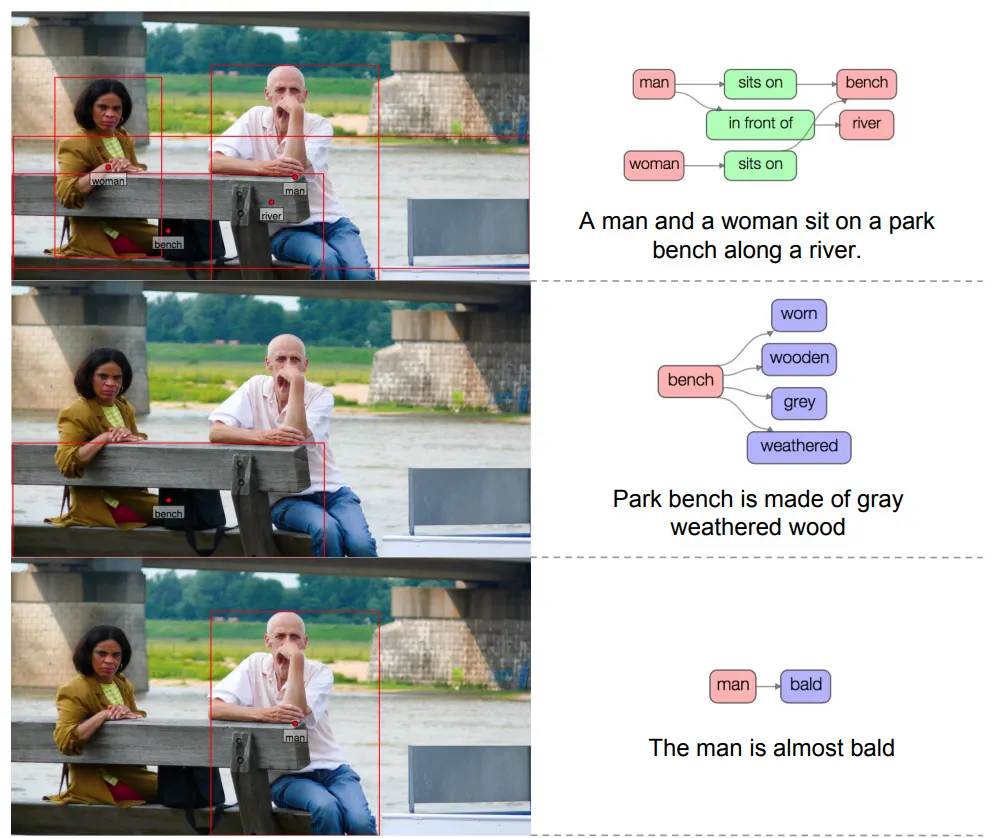
출처: https://arxiv.org/pdf/1602.07332
🔸 CC3M (Conceptual Captions 3 Million)
- 웹에서 수집된 3백만 개의 이미지-텍스트 쌍 데이터셋입니다.
출처: https://ai.google.com/research/ConceptualCaptions/download
🔸 SBU (Stony Brook University) Captioned Photo Dataset
- 사진 공유 웹사이트 Flichr에서 수집된 사진-캡션 데이터셋입니다.

출처: https://tamaraberg.com/papers/generation_nips2011.pdf
🔸 LAION400M
-
웹에서 수집된 4억(400M) 개의 이미지-텍스트 쌍으로 이루어진 매우 큰 데이터셋입니다
📃 관련 논문: https://arxiv.org/pdf/2111.02114
🔻 데이터 전처리
이후 데이터 품질을 높이기 위해 BLIP-large caption 모델을 활용하여 caption을 수정합니다.
🔸 BLIP-large captioning model
- BLIP-large captioning model을 활용하여 10개의 합성 캡션을 생성합니다.
출처: https://arxiv.org/pdf/2201.12086
🔸 CLIP 모델을 통한 필터링
- CLIP ViT-L/14 모델을 활용하여 가장 유사한 상위 2개의 caption만 훈련 데이터로 사용합니다.
- 실제 학습 단계에서는 두 개의 caption 중 하나를 무작위 샘플링합니다.
🔻 Pre-trained image encoder and LLM
🔸 사전 학습된 이미지 encoder
- CLIP ViT-L/14 모델을 사용하였습니다.
- EVA-CLIP ViT-g/14 모델을 사용하였습니다.
🔸 사전 학습된 LLM
- Decoder 기반 LLM으로 OPT 모델을 사용하였습니다.
- Encoder-Decoder 기반 LLM으로 Flan-T5를 사용하였습니다.
4️⃣ Experiment
4장에서는 다양한 실험을 통해 BLIP-2 모델의 성능을 평가합니다.
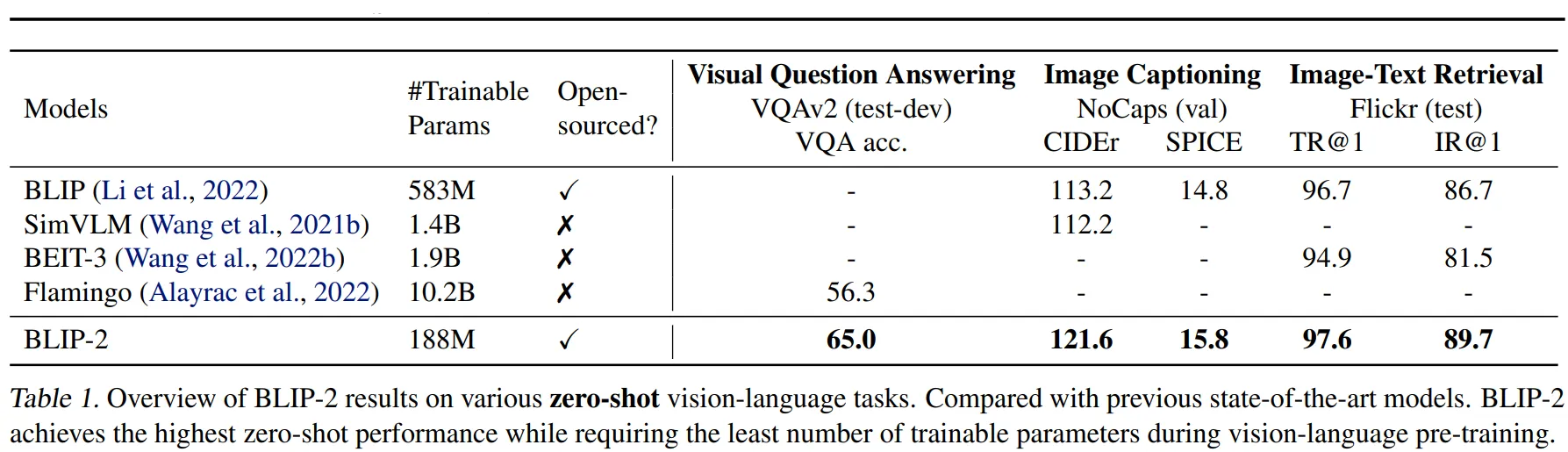
BLIP-2 모델은 Table1에서 확인할 수 있듯이 더 적은 파라미터를 학습시키더라도 다양한 task에서 타 모델보다 뛰어난 성능을 발휘하는 것을 확인할 수 있습니다. 지금부터 각 task 별 BLIP의 성능에 대해 알아보겠습니다.
🔷 4-1 Instructed Zero-shot Image-to-Text Generation
BLIP-2 모델은 기존의 사전 학습된 LLM 모델을 활용합니다. BLIP-2를 구성하는 LLM 모델 중에는 In-context Learning 능력이 뛰어난 모델들이 있습니다. 따라서 BLIP-2 모델은 학습에 사용된 LLM 모델의 프롬프트 이해 능력을 활용하여 다양한 시각적 task를 처리할 수 있습니다.
아래의 Figure 4는 BLIP-2 모델이 다양한 시각적 task에서 뛰어난 zero-shot 능력을 보여줌을 확인할 수 있습니다.

🔻 Zero-shot VQA
논문에서는 시각적 질의응답에 대한 정량적 평가를 수행하였습니다. 이때 BLIP-2 모델에 사용된 LLM 모델에 따라 다른 프롬프트를 사용하였습니다.
🔸 프롬프트 형태
-
OPT 모델: “Question: {} Answer:” 형태의 프롬프트를 사용합니다.
-
FlanT5 모델: “Question: {} Short answer:” 형태의 프롬프트를 사용합니다.
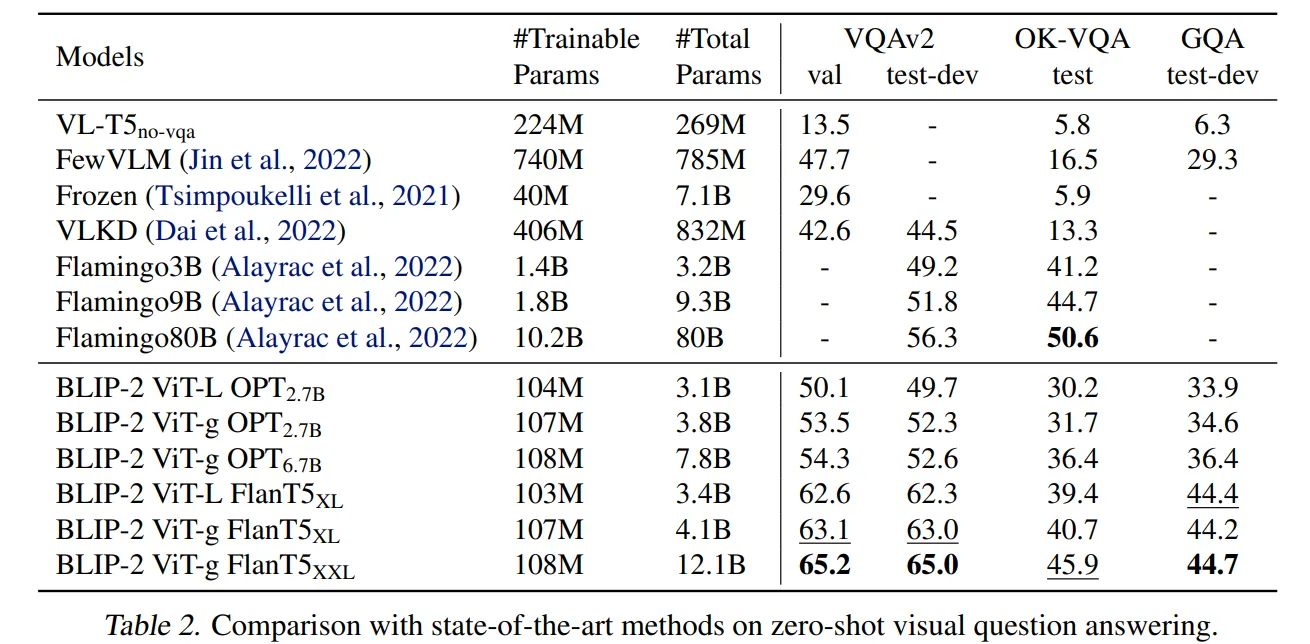
Table 2를 보면 BLIP-2 모델이 VQAv2와 GQA 데이터 세트에서 SOTA의 성능을 발휘함을 확인할 수 있습니다.
또한 OK-VQA 데이터셋에서도 Flamingo80B 다음으로 좋은 성능을 발휘합니다.
🔸 VQAv2
-
VQAv2는 VQA보다 더 많은 이미지와 질문-답변 쌍을 포함한 데이터셋입니다.
-
VQAv2는 VQA의 데이터 분포가 특정 답변에 편향되었다는 한계를 극복하기 위해 더 다양한 데이터를 수집한 데이터셋입니다.

출처: https://arxiv.org/pdf/1612.00837
🔸 GQA (Generalized Question Answering)
-
GQA는 시각 질문 응답에 대한 데이터셋입니다.
-
GQA는 이미지 내의 객체, 속성, 그리고 객체 간의 관계를 구조적으로 표현한 장면 그래프를 통해 모델이 더 복잡한 시각적 추론을 할 수 있도록 만들어진 데이터셋입니다.

출처: https://arxiv.org/pdf/1902.09506
🔸 OK-VQA (Outside Knowledge Visual Question Answering)
-
OK-VQA는 이미지 내용만으로는 답할 수 없는 질문에 초점을 맞춘 시각 질문 응답(VQA) 데이터셋입니다.
-
즉 모델이 외부 세계 지식을 결합하여야 해결할 수 있는 데이터셋입니다.
-
Flamingo80B모델이 BLIP-2 모델보다 성능이 좋은 이유 역시 Flamingo80B모델에 사용된 Chinchilla70B 모델이 BLIP-2모델에 사용된 FlanT5XXL 11B 모델보다 배경지식이 많이 때문이라고 가정합니다.

출처: https://arxiv.org/pdf/1906.00067
🔸 BLIP-2를 구성하는 모델에 따른 성능 변화
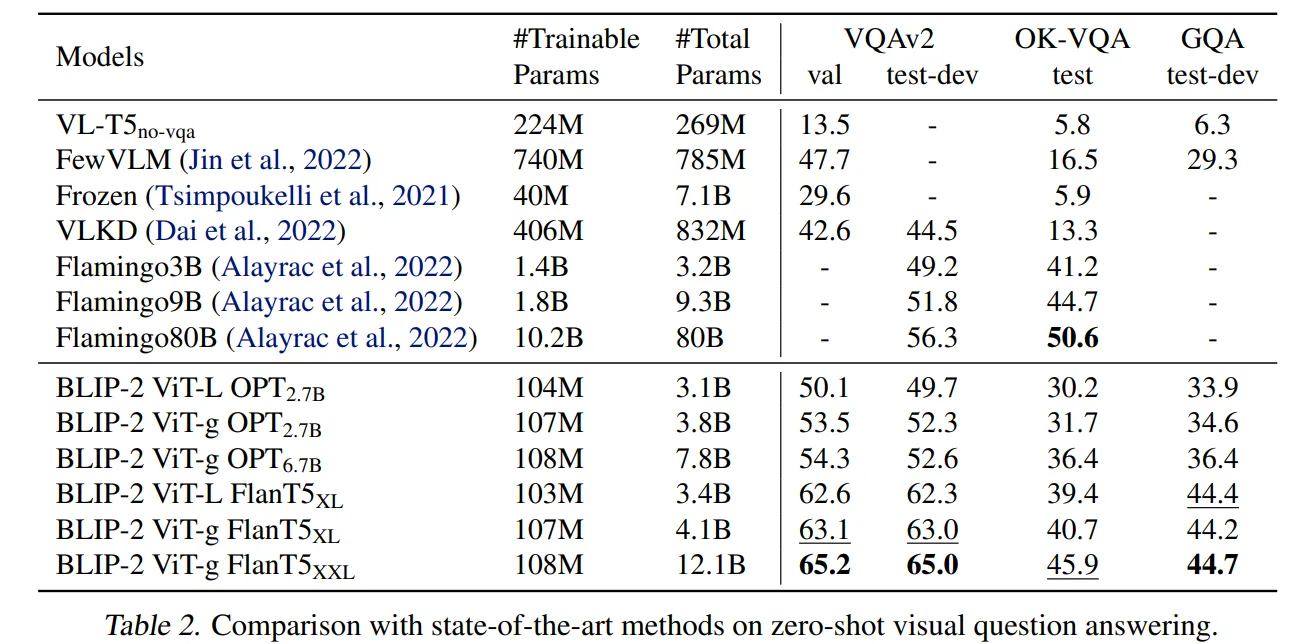
Table 2를 보면 BLIP-2 모델을 구성하는 이미지 encoder와 LLM의 성능이 높아질수록 더 좋은 성능을 발휘합니다. 이는 자연어처리(NLP), 컴퓨터비전(CV) 분야에서 각 모델의 성능이 발전할수록 BLIP-2의 성능 역시 개선될 수 있다는 사실을 시사합니다.
🔻 Effect of Vision-Language Representation Learning
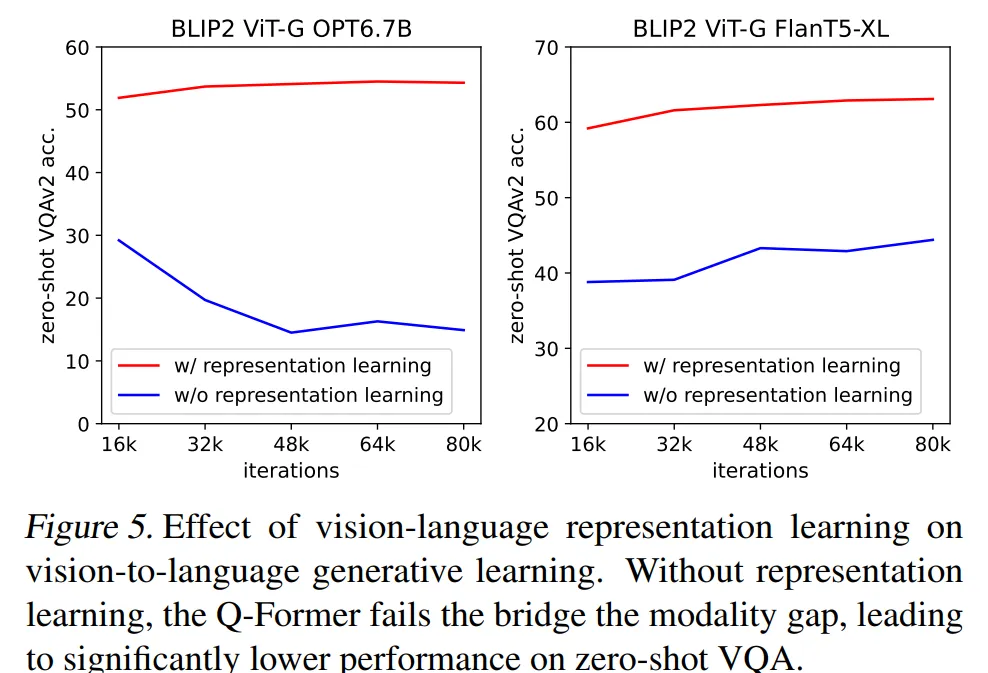
앞서 설명드렸듯이 이미지 encoder와 LLM모델을 연결하는 Q-Former는 2단계를 거쳐 학습합니다. 첫 번째가 이미지에서 중요한 특징을 추출하는 Representation Learning이고 두 번째는 LLM 모델이 시각적 특징을 바탕으로 텍스트를 잘 생성할 수 있도록 시각적 특징을 적절하게 변형해주는 Generative Learning입니다.
Figure 5를 보시면 Representation Learning을 거친 모델 (빨간색)이 Representation Learning을 생략한 모델 (파란색)보다 더 좋은 성능을 발휘하는 것을 확인할 수 있습니다.
🔷 4-2 Image Captioning
논문의 저자는 BLIP-2 모델이 이미지에 대한 텍스트 설명을 생성하는 이미지 캡셔닝 task를 위해 파인튜닝을 진행합니다. LLM 모델에게는 “a photo of”라는 프롬프트를 사용하고 학습은 이미지 encoder와 Q-Former의 파라미터를 업데이트합니다. COCO 데이터를 사용하여 파인튜닝 후 COCO 데이터의 테스트 세트와 NoCaps 데이터의 검증 세트를 활용하여 평가를 진행하였습니다.
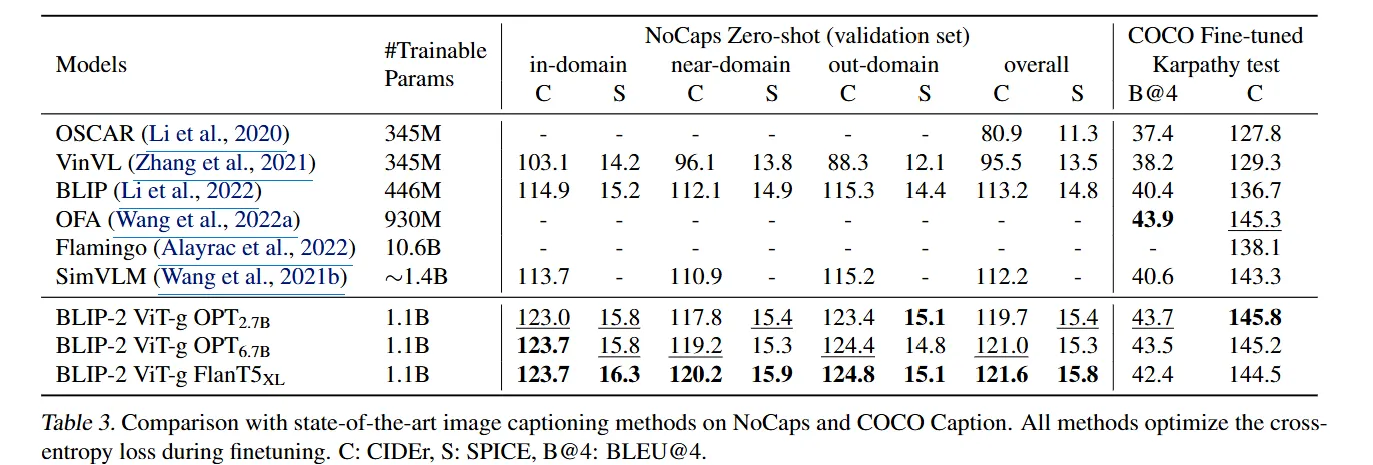
Table 3에서 확인할 수 있듯이 NoCaps 데이터에서 BLIP-2가 SOTA의 성능을 발휘하였습니다.
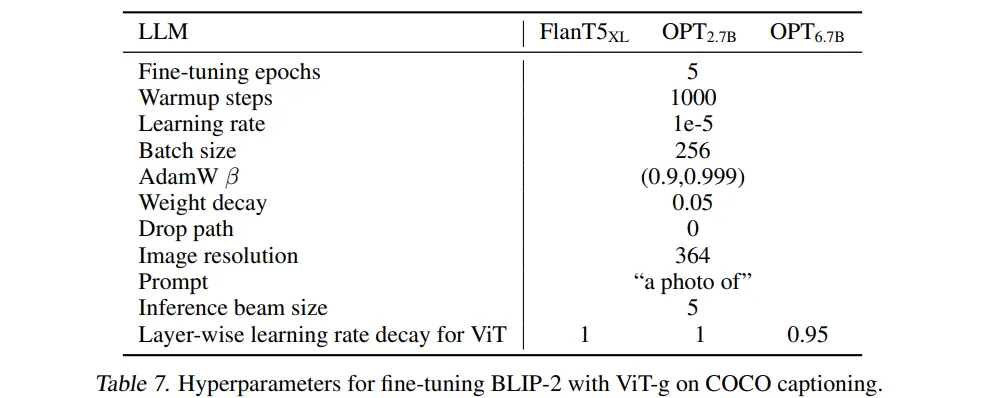
🔸 Fine-tuning에 사용한 하이퍼파라미터
🔷 4-3 Visual Question Answering
논문의 저자는 BLIP-2 모델이 이미지와 질문을 기반으로 질문에 대한 답변을 생성하는 VQA task를 처리할 수 있도록 파인튜닝을 진행합니다. 학습은 VQA 데이터를 통해 이루어지며 BLIP-2 모델이 질문에 대한 이미지 특징을 잘 추출할 수 있도록 Q-Former의 text transformer에 질문 데이터를 입력하여 학습을 진행합니다.
Q-Former는 질문 데이터와 사전에 학습한 Query Embedding을 self-attention을 통해 연결하여 Q-Former가 질문에 대한 이미지 특징을 추출할 수 있도록 학습합니다.

Table 4에서 BLIP-2는 Open-ended generation 모델에서 SOTA의 성능을 발휘함을 확인할 수 있습니다. 여기서 Open-ended generation 모델은 질문에 대한 답변을 생성하는 모델입니다. 반면 Closed-ended classification 모델은 객관식 문제처럼 질문에 대한 답변을 선택하는 모델입니다.
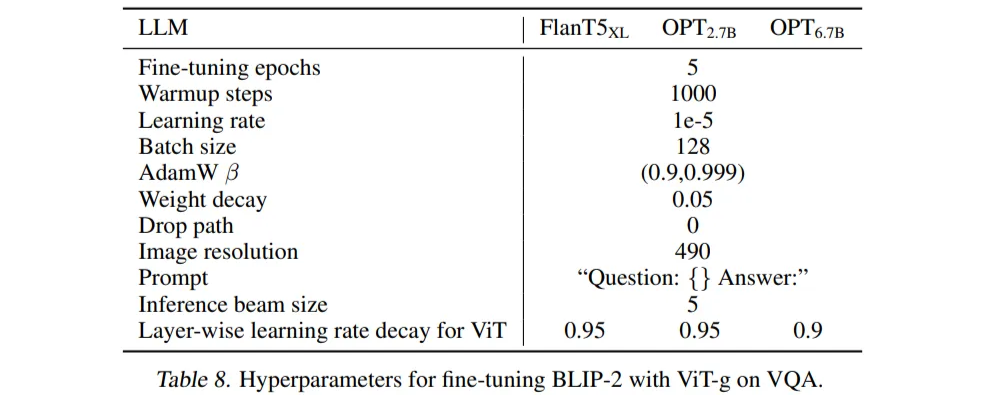
🔸 Fine-tuning에 사용한 하이퍼파라미터
🔷 4-4 Image-Text Retrieval
논문의 저자는 BLIP-2 모델이 이미지를 통한 텍스트 검색, 텍스트를 통한 이미지 검색 task를 수행할 수 있도록 파인튜닝합니다. 검색을 위해서는 텍스트 생성이 불필요하기 때문에 이때는 LLM 모델을 제외한 이미지 encoder와 Q-Former만을 사용하여 학습을 진행합니다. 학습 데이터로는 COCO를 사용하였으며 COCO와 Flickr30K의 테스트 데이터를 통해 평가를 진행하였습니다.
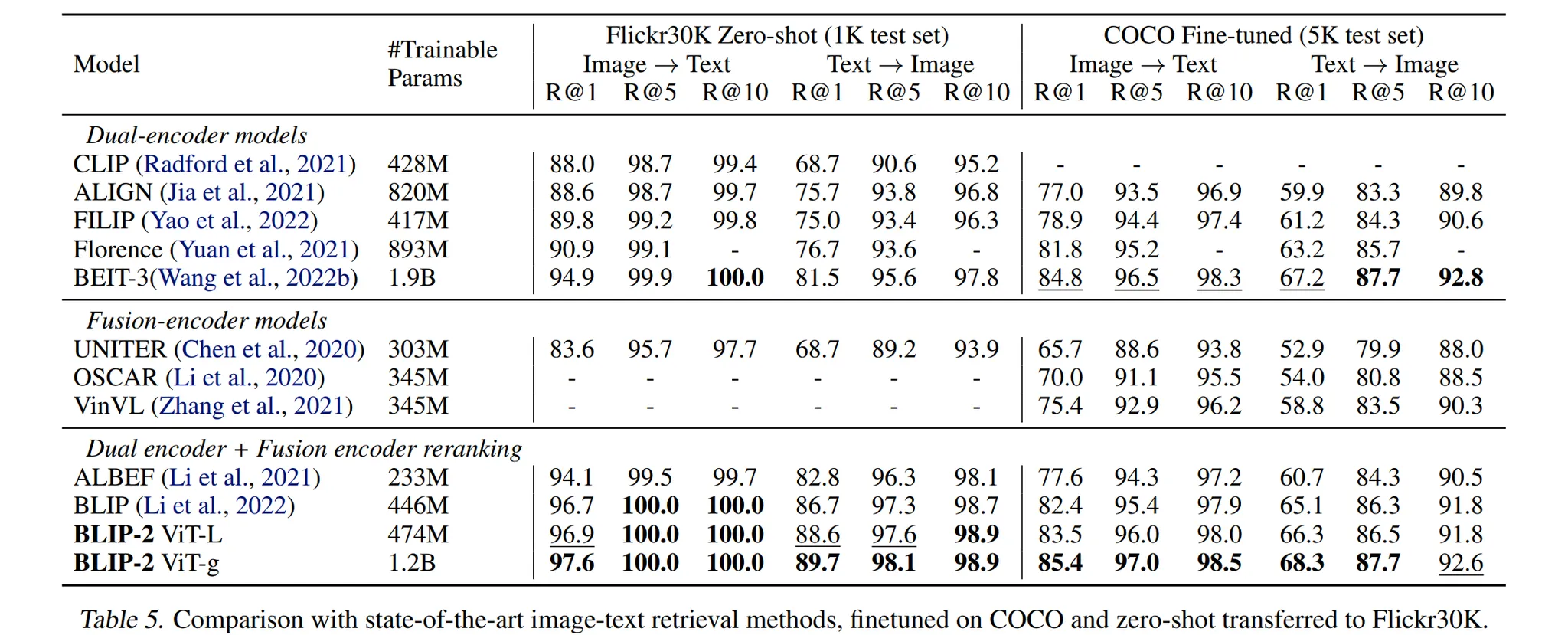
Table 5에서 확인할 수 있듯이 BLIP-2 모델이 이미지를 통한 텍스트 검색과 텍스트를 통한 이미지 검색 task에서 SOTA의 성능을 발휘함을 확인할 수 있습니다.
🔻 ITG Loss의 중요성
또한 논문의 저자는 검색과 관련이 없어보이는 ITG(Image-grounded Text Generation) Loss의 중요성을 평가하기 위해 파인튜닝 과정에서 ITG Loss를 사용하지 않는 실험을 진행하였습니다.
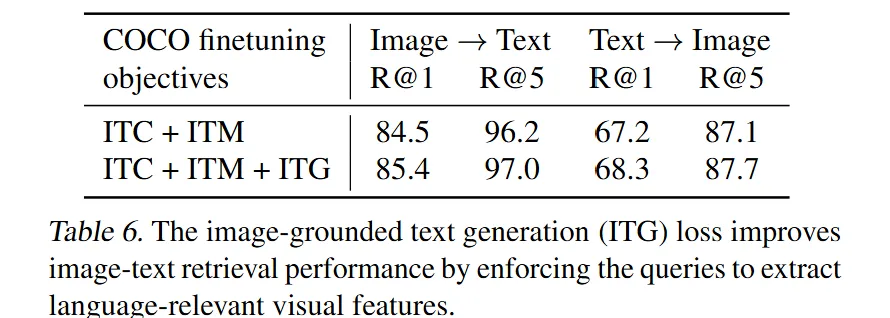
Table 6에서 확인할 수 있듯이 ITG Loss를 사용할 때 Retrieval task에서도 더 좋은 성능을 발휘함을 확인할 수있습니다.
🔸 Fine-tuning에 사용한 하이퍼파라미터
5️⃣ Limitation
5장에서는 BLIP-2 모델의 한계에 대해 설명합니다.
🔷 In-context learning 능력 부족
In-context learning이란 모델에게 몇 가지 예시를 보여준 후 그 예시를 바탕으로 새로운 작업을 수행할 수 있도록 학습하는 방법입니다. 그런데 BLIP-2 모델에서는 In-context learning 기법에서 좋은 성능을 발휘하지 못했습니다.
논문의 저자는 그 원인을 학습 데이터에서 찾습니다. BLIP-2는 학습을 진행할 때 하나의 이미지와 텍스트 쌍에 대해서 일대일 관계만 학습하기 때문에 데이터 상호 간의 관계를 파악하는 능력이 떨어질 수 있습니다.
따라서 논문의 저자는 이미지-텍스트 쌍이 번갈아 사용되는 데이터를 구축하는 것을 향후 과제로 남겨주었습니다.
👍 향후 MLLM에서는 이러한 한계를 극복하기 위해 Instruction tuning 기법을 활용합니다.
🔷 이미지-텍스트 생성의 불만족스러운 결과
논문의 저자는 새로운 이미지 데이터에 대한 정보 부족, LLM 모델의 부정확한 지식, 텍스트 지시에 대한 LLM 모델의 이해 부족 등을 이유로 BLIP-2 모델의 생성 결과의 한계를 지적합니다.

Figure 6. Incorrect output examples for instructed zero-shot image-to-text generation using a BLIP-2 model w/ ViT-g and FlanT5XXL
👍 향후 MLLM에서는 이러한 한계를 극복하기 위해 Instruction tuning 기법을 활용합니다.
🔷 고정 모델 사용으로 인한 위험 상속
사전 학습된 Image encoder와 LLM을 사용하기 때문에 기존의 모델이 가지고 있는 위험을 그대로 가져옵니다. 예를 들어, 공격적인 말투, 사회적 편견, 사전 학습한 개인정보 등이 있습니다.
이러한 한계를 극복하기 위해 사전 학습을 진행할 때 유해한 데이터를 필터링하여 학습할 수 있습니다.
6️⃣ Conclusion
6장에서는 BLIP-2 모델의 특징과 논문의 의의에 대해 설명합니다.
BLIP-2 모델을 통해 기존의 End-to-end Vision-Language Pre-training이 많은 계산 비용이 든다는 한계를 극복하였습니다. 또한 BLIP-2는 더 적은 파라미터를 학습하면서 타 모델에 비해 더 뛰어난 성능을 보여주었습니다. Zero-shot에서도 새로운 능력을 획득하였습니다.
결론적으로 BLIP-2 모델은 대화형 멀티모달 AI 에이전트를 개발하는데 밑거름이 될 것입니다.
🤔 논문을 읽은 후…
기존의 MLLM Survey 논문을 읽었어서 논문의 내용이 크게 부담스럽지는 않았다. 논문을 읽을 때마다 새로운 아이디어를 하나씩 배워가는 기분이다. 이번에는 Cross-attention과 self-attention의 활용 방법에 대해 조금 더 깊이 이해할 수 있었다.
BLIP은 상당히 초기 논문인 줄 알았는데 Flamingo🦩 모델이 더 빨리 나왔는 줄 몰랐다. 다음 기회에 한번 읽어보고 싶다.
논문을 읽으면 각 아이디어의 논리가 합리적이라는 생각이 든다. 하지만 실제로 내가 모델을 만들기 위해서는 상당히 많은 컴퓨팅 비용과 데이터가 필요하기 때문에 이러한 생각이 피부로 와닿지 않는 것 역시 사실이다.
이 부분이 극복되면 AI를 공부하는 것이 더 재밌을 것 같다.
