
출처: Google Gemini
😆 글을 작성하게 된 이유와 후기
최근 BLIP-2 논문을 읽고 정리하였다. MLLM 구조의 모델을 다룬 첫 논문이어서 이런 큰 모델은 어떻게 코드로 구현하였는지 궁금하여 살펴보게 되었다. GitHub를 들어가 봤더니 아래 사진처럼 총 4개의 파일로 이루어져 있었다. 그래서 "이번에도 쉽겠군" 하고 뛰어들었다가 코드량에 두들겨 맞았다. 코드가 너무 많아 정의된 class와 함수의 기능을 중심으로 BLIP-2 모델의 프로세스를 이해해보았다. 다른 분들이 읽으라고 작성한 글이 아닌 순전히 내가 공부를 위해 작성한 글이다. 절대 이 글을 다 읽으려고 하지 않길 바란다.
📃 BLIP-2에 대해서는 아래의 [논문리뷰]를 참고하시길 바랍니다.
https://velog.io/@tina1975/논문리뷰-BLIP-2-Bootstrapping-Language-Image-Pre-trainingwith-Frozen-Image-Encoders-and-Large-Language-Models
📃 BLIP-2 모델을 실제로 실행하는 방법에 대해서는 아래의 글을 참고하시길 바랍니다.
https://velog.io/@tina1975/AI-모델-코드-BLIP-2-모델-실행하기
👩💻 분석 코드
- 코드는 Huggingface에서 GitHub에 공개한 자료를 살펴보겠습니다.

출처: https://github.com/huggingface/transformers/tree/v4.52.3/src/transformers/models/blip_2
1️⃣ configuration_blip_2.py
configuration_blip_2.py파일은 Hugging Facetransformers라이브러리에서 BLIP-2 모델의 아키텍처 구성(configuration)을 정의하는 파일입니다.
🔷 파일 속 코드 구조
configuration_blip_2.py|
├──── class Blip2VisionConfig
├──── class Blip2QFormerConfig
└──── class Blip2Config
└───── def from_vision_qformer_text_configs🔷 각 class에 대한 설명
Blip2VisionConfig:BLIP-2 모델의 비전 인코더(Vision Encoder) 구조를 결정하는 class입니다. 비전 인코더는 BLIP-2에 입력된 이미지의 특징을 추출해주는 모델 입니다.
Blip2QFormerConfig: BLIP-2 모델의 핵심 구성 요소인 Q-Former(Querying Transformer) 구조를 결정하는 Class입니다. Q-Former는 이미지 인코더에서 추출된 이미지 특징을 언어 모델이 이해할 수 있는 형태로 변환하는 역할을 합니다.
Blip2Config: BLIP-2 모델 전체(end-to-end) 에 대한 최상위 구조를 결정하는 class입니다. 이 클래스는 위에서 설명한 Blip2VisionConfig, Blip2QFormerConfig 그리고 뒤에 연결될 언어 모델(Language Model)의 구조를 통합하여 BLIP-2 모델 전체의 아키텍처를 구성합니다.
🤔 해당 코드를 만든 이유
configuration_blip_2.py는 모델의 뼈대를 결정하는 역할을 수행합니다.
-
재현성(Reproducibility) : 모델의 구조, 즉 하이퍼파라미터를 따로 정의할 수 있는 구조를 만들어 다른 사람들이 동일한 구조의 BLIP-2을 쉽게 구현할 수 있도록 합니다.
-
유연성(Flexibility) : 모델의 특정 구조를 쉽게 변경할 수 있습니다.
-
모듈화(Modularity) : 모델의 세부 구조를 따로 설정할 수 있도록 설계하여, 각 구조를 더 쉽게 관리할 수 있도록 합니다.
-
사전 학습된 모델 로딩(Loading Pre-trained model) : 사전 학습된 모델의 구조를 쉽게 설계할 수 있도록 합니다.
🔷 실제 코드
🔻 Blip2VisionConfig
-
Blip2VisionConfig에서 결정된 값은
modeling_blip_2.py파일의 신경망 모듈(Blip2VisionModel,Blip2Encoder,Blip2Attention등)에 전달되어 이미지 encoder의 구조를 결정합니다. -
BLIP-2 모델은 CLIP을 이미지 encoder로 사용하는데, 이때 CLIP 모델 속에 Vision-transformer가 사용됩니다.
🔸 Vision Transformer
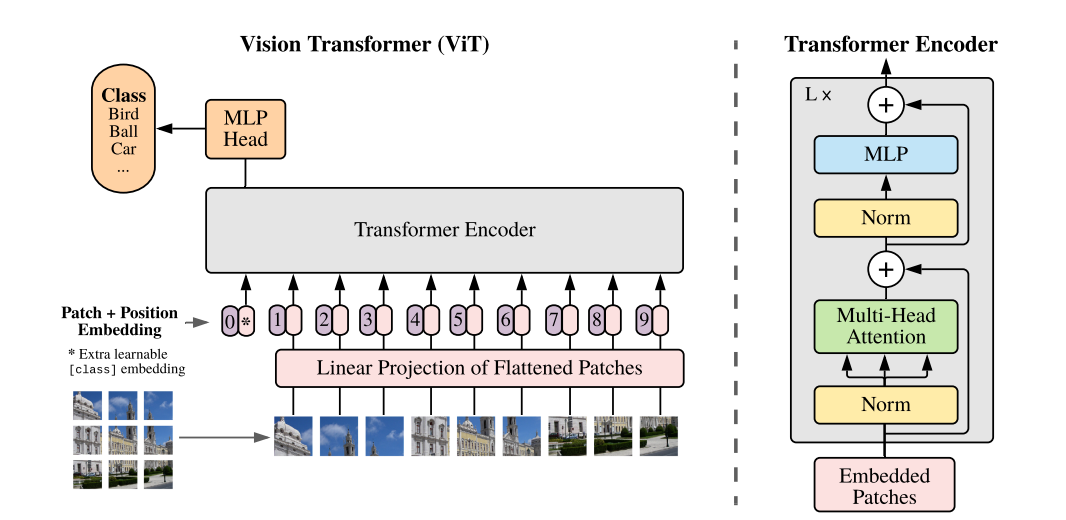
출처: https://arxiv.org/pdf/2010.11929
CLIP모델에 대한 추가적인 내용은 아래 글에서 확인 가능합니다.
📃자료: https://velog.io/@tina1975/AI-모델-코드-CLIP-모델-코드-이해
🔸GitHub code
class Blip2VisionConfig(PretrainedConfig):
def __init__(
self,
hidden_size=1408,
# 이미지 encoder의 임베딩 차원
# 1408로 굉장히 큰 값을 사용하는 것을 확안할 수 있다.
intermediate_size=6144,
# transformer의 피드포워트 신경망의 차원
num_hidden_layers=39,
# transformer의 인코더 Block 수
num_attention_heads=16,
# 멀티헤드의 크기
image_size=224,
# 입력 이미지의 크기
patch_size=14,
# 이미지를 쪼갤 패치의 크기
hidden_act="gelu",
# transformer 내부에서 사용되는 비선형함수
layer_norm_eps=1e-6,
# 레이어 정규화의 epsilon 값
attention_dropout=0.0,
# dropout 비율
initializer_range=1e-10,
# 모델 가중치 초기화 시 사용되는 표준편차
qkv_bias=True,
# self-attention 연산의 Bias 사용 유무
**kwargs,
# 그 외의 인자
):
super().__init__(**kwargs)
# 입력된 파라미터를 인스턴스 속성으로 저장
self.hidden_size = hidden_size
self.intermediate_size = intermediate_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.patch_size = patch_size
self.image_size = image_size
self.initializer_range = initializer_range
self.attention_dropout = attention_dropout
self.layer_norm_eps = layer_norm_eps
self.hidden_act = hidden_act
self.qkv_bias = qkv_bias🔻 Blip2QFormerConfig
-
Blip2QFormerConfig에서 결정된 값은
modeling_blip_2.py의Blip2QFormerModel과 그 하위 모듈들의 구조를 동적으로 설정**합니다. -
self.cross_attention_frequency는Blip2QFormerLayer내에서 이미지 임베딩에 대한 교차 어텐션이 언제 발생할지 결정합니다. -
즉 이미지에 대한 정보를 몇 번의 빈도로 가져올 지 결정하는 것입니다.
🔸GitHub code
class Blip2QFormerConfig(PretrainedConfig):
model_type = "blip_2_qformer"
base_config_key = "qformer_config"
def __init__(
self,
vocab_size=30522,
# 단어사전 크기
# 이미지 인코더와 동일한 의미
hidden_size=768,
num_hidden_layers=12,
num_attention_heads=12,
intermediate_size=3072,
hidden_act="gelu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=512,
# Q-Former가 처리할 수 있는 최대 시퀀스 길이
initializer_range=0.02,
# 가중치 초기화 시 표준편차
layer_norm_eps=1e-12,
# 레이어 정규화의 epsilon 값
pad_token_id=0,
# 패딩 토큰 아이디
position_embedding_type="absolute",
# 위치임베딩 유형, 상대적인 방식도 있다.
cross_attention_frequency=2,
# 크로스-어텐션 사용 빈도
# 이미지 encoder의 출력을 가져오는 역할
# 아주 중요한 파라미터
encoder_hidden_size=1408,
# 이미지 encoder의 임베딩 크기
# 앞서 정의한 이미지 encoder의 크기와 일치해야 한다.
use_qformer_text_input=False,
# Q-Former가 텍스트 입력을 받을지 여부
**kwargs,
):
super().__init__(pad_token_id=pad_token_id, **kwargs)
# 입력된 파라미터를 인스턴스 속성으로 저장
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.hidden_act = hidden_act
self.intermediate_size = intermediate_size
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.max_position_embeddings = max_position_embeddings
self.initializer_range = initializer_range
self.layer_norm_eps = layer_norm_eps
self.position_embedding_type = position_embedding_type
self.cross_attention_frequency = cross_attention_frequency
self.encoder_hidden_size = encoder_hidden_size
self.use_qformer_text_input = use_qformer_text_input🔻 Blip2Config
-
Blip2Config에서 결정된 값은 각 서브-모듈(이미지 encoder, Q-Former, 언어 모델)이 어떻게 구성되고, 서로 어떻게 연결될지를 결정합니다.
-
언어모델(LLM)의 경우 CONFIG_MAPPING 함수를 통해 huggingface에 저장되어 있는 LLM의 config를 가져와 활용할 수 있도록 합니다.
-
def from_vision_qformer_text_configs 함수 : 이 메서드가 반환하는
Blip2Config객체는 BLIP-2 모델 전체의 데이터 처리 파이프라인(Vision Encoder -> Q-Former -> Language Model)의 모든 세부 사항을 정의하는 최종적인 설계도입니다. -
__all__변수를 통해 각 class를 import 할 수 있도록 설계합니다.
🔸 BLIP-2의 데이터의 흐름
입력된 이미지 데이터가 Vision Encoder를 거쳐
vision_config.hidden_size차원의 임베딩이 되고, 이 임베딩이 Q-Former에encoder_hidden_size로 입력되어 Query 토큰과 교차 어텐션을 수행합니다. 이후 Query 토큰은language_projection레이어를 통해image_text_hidden_size차원으로 변환되어 언어 모델의 입력과 결합됩니다. 입력된 데이터를 바탕으로 언어모델이 최종 텍스트를 생성합니다.
🔸Github code
from ...configuration_utils import PretrainedConfig
from ...models.auto.modeling_auto import MODEL_FOR_CAUSAL_LM_MAPPING_NAMES
from ...utils import logging
from ..auto import CONFIG_MAPPING, AutoConfig
class Blip2Config(PretrainedConfig):
model_type = "blip-2"
attribute_map = {
"image_token_id": "image_token_index",
}
sub_configs = {"text_config": AutoConfig, "qformer_config": Blip2QFormerConfig, "vision_config": Blip2VisionConfig}
# BLIP-2 내부 구조의 config를 정의합니다.
# text_config는 AutoConfig를 사용하여 다양한 LLM 모델을 사용할 수 있도록 합니다.
def __init__(
self,
vision_config=None,
qformer_config=None,
text_config=None,
num_query_tokens=32,
# Q-Former에 사용되는 Query Embedding의 개수입니다.
# Query Embedding은 이미지 encoder의 데이터를 가져오는 역할을 수행합니다.
image_text_hidden_size=256,
# Q-Former의 출력을 LLM에게 전달할 때 사용되는 임베딩 차원입니다.
image_token_index=None,
# 향후 소프트 엔지니어링을 위해 사용됩니다.
# LLM의 텍스트 입력에서 이미지 데이터를 어떤 위치에 삽입할지 결정합니다.
**kwargs,
):
super().__init__(**kwargs)
# 이미지 encoder의 구조를 결정하는 config를 딕셔너리 형태로 담습니다.
# confing가 비어있는 경우 기본 구조를 사용합니다.
# 이를 통해 하위 모델에 대한 정보가 부족하더라도 BLIP-2 모델이 생성될 수 있도록 합니다.
if vision_config is None:
vision_config = {}
logger.info("vision_config is None. initializing the Blip2VisionConfig with default values.")
# Q-Former의 구조를 결정하는 config를 딕셔너리 형태로 담습니다.
if qformer_config is None:
qformer_config = {}
logger.info("qformer_config is None. Initializing the Blip2QFormerConfig with default values.")
# LLM의 구조를 결정하는 config를 딕셔너리 형태로 담습니다.
if text_config is None:
text_config = {}
logger.info("text_config is None. Initializing the text config with default values (`OPTConfig`).")
# config를 인스턴스 속성으로 저장
self.vision_config = Blip2VisionConfig(**vision_config)
self.qformer_config = Blip2QFormerConfig(**qformer_config)
text_model_type = text_config["model_type"] if "model_type" in text_config else "opt"
self.text_config = CONFIG_MAPPING[text_model_type](**text_config)
# CONFIG_MAPPING로 해당 이름을 가진 모델의 config를 가져온다.
# 입력된 파라미터를 인스턴스 속성으로 저장
self.num_query_tokens = num_query_tokens
self.image_text_hidden_size = image_text_hidden_size
self.image_token_index = image_token_index
self.qformer_config.encoder_hidden_size = self.vision_config.hidden_size
# 이미지 encoder의 출력과 Q-Former의 연결차원을 통일시켜 호환 가능하도록 합니다.
# 이미지 encoder와 Q-Former를 연결하는 가장 중요한 코드
self.use_decoder_only_language_model = self.text_config.model_type in MODEL_FOR_CAUSAL_LM_MAPPING_NAMES
# 디코더 기반 LLM의 사용 여부 결정
self.initializer_factor = 1.0
self.initializer_range = 0.02
@classmethod
def from_vision_qformer_text_configs(
cls,
vision_config: Blip2VisionConfig,
qformer_config: Blip2QFormerConfig,
text_config: Optional[PretrainedConfig] = None,
**kwargs,
):
return cls(
vision_config=vision_config.to_dict(),
qformer_config=qformer_config.to_dict(),
text_config=text_config.to_dict() if text_config is not None else None,
**kwargs,
)
# cls 함수를 통해 Config 객체를 생성한다.
# modeling_blip_2.py에서 실제 Blip2Model을 인스턴스화할 때 사용된다.
__all__ = ["Blip2Config", "Blip2QFormerConfig", "Blip2VisionConfig"]
# __all__은 파이썬 모듈에서 from module import * 구문을 사용할 때
# 임포트될 이름들의 리스트를 정의하는 특별한 전역 변수입니다.2️⃣ modeling_blip_2.py
modeling_blip_2.py는configuration_blip_2.py가 만든 BLIP-2 모델의 설계도를 바탕으로 실제 모델 구성 요소를 만들고, 이들을 조합하여 데이터를 처리하는 방법을 정의합니다.
🔷 파일 속 코드 구조
현재 구조는
modeling_blip_2.py에 존재하는 모든 class, 함수가 아니라 대표적인 class와 함수만 표현한 것입니다.
modeling_blip_2.py
├────🔻Output Classes (모델 출력 형식 정의)
│ ├──── class Blip2ForConditionalGenerationModelOutput
│ ├──── class Blip2ImageTextMatchingModelOutput
│ ├──── class Blip2TextModelOutput
│ └──── class Blip2VisionModelOutput
│
├────🔻Core Building Blocks (기본 신경망 모듈)
│ ├──── class Blip2VisionEmbeddings (이미지 -> 임베딩)
│ ├──── def eager_attention_forward (어텐션 구현 함수)
│ ├──── class Blip2Attention (Vision Encoder용 Self-Attention)
│ ├──── class Blip2MLP (Vision Encoder용 Feed-Forward)
│ ├──── class Blip2EncoderLayer (Vision Encoder의 단일 Transformer 레이어)
│ ├──── class Blip2QFormerMultiHeadAttention (Q-Former Multi-Head Attention)
│ ├──── class Blip2QFormerSelfOutput (Q-Former용 Self-Attention 출력)
│ ├──── class Blip2QFormerIntermediate (Q-Former용 Feed-Forward 중간)
│ ├──── class Blip2QFormerOutput (Q-Former용 Feed-Forward 출력)
│ ├──── class Blip2QFormerLayer (Q-Former의 단일 Transformer 레이어)
│ └──── class Blip2TextEmbeddings (Q-Former 텍스트 입력용 임베딩)
│
└────🔻Composite Models (복합 모델 및 전체 모델)
├────🦴Base & Backbone Models (기본 및 백본 모델)
│ ├──── class Blip2PreTrainedModel (모든 BLIP-2 모델의 기본 클래스)
│ ├──── class Blip2Encoder (Vision Encoder의 전체 Transformer)
│ ├──── class Blip2VisionModel (Vision Encoder의 전체 모델)
│ └──── class Blip2QFormerModel (Q-Former의 전체 모델)
│
├────🔍Projection & Specialized Feature Extractors (투영 및 특징 추출기)
│ ├──── class Blip2TextModelWithProjection (텍스트 임베딩 추출 + 투영)
│ └──── class Blip2VisionModelWithProjection (이미지 임베딩 추출 + 투영)
│
└────▶️End-to-End Task Models (종단 간(End-to-End) 태스크 모델)
├──── class Blip2Model (Vision, Q-Former, Language Model 통합 모델)
│ ├──── def get_text_features
│ ├──── def get_image_features
│ ├──── def get_qformer_features
│ └──── def forward (BLIP-2 통합 모델의 전방향 패스)
├──── class Blip2ForConditionalGeneration (조건부 텍스트 생성 모델)
│ ├──── def get_image_features (재정의된 이미지 특징 추출)
│ ├──── def forward (조건부 생성 모델의 전방향 패스)
│ └──── def generate (텍스트 생성 메서드)
└──── class Blip2ForImageTextRetrieval (이미지-텍스트 검색 모델)
└──── def forward (이미지-텍스트 검색 모델의 전방향 패스)🔷 class 군에 대한 설명
위 class를 기능적 관점에서 분류하여 살펴보도록 하겠습니다.
🔻 1. 모델 출력(Model Output) 클래스
modeling_blip_2.py
├────🔻Output Classes (모델 출력 형식 정의)
│ ├──── class Blip2ForConditionalGenerationModelOutput
│ ├──── class Blip2ImageTextMatchingModelOutput
│ ├──── class Blip2TextModelOutput
│ └──── class Blip2VisionModelOutputModel Output class는 모델의 예측 결과와 내부 데이터를 깔끔하게 캡슐화하여 반환함으로써, 개발자가 모델의 출력을 쉽게 접근하고 디버깅하며 후속 작업에 활용할 수 있도록 돕습니다.
🔸 Blip2ForConditionalGenerationModelOutput
- 역할 : 이미지 캡셔닝이나 시각 질문 응답과 같은 조건부 텍스트 생성 모델 (
Blip2ForConditionalGeneration)의 출력 구조를 정의합니다. Vision Encoder → Q-Former → Language Model의 데이터 흐름 과정에서 핵심적인 데이터를 출력합니다. - 처리하는 데이터 : LLM 모델의 Loss값, 다음 토큰에 대한 점수(logits), 이미지 Encoder, Q-Former, LLM의 모든 데이터 처리 결과를 출력합니다.
🔸 dataclass Blip2ImageTextMatchingModelOutput
- 역할 : 이미지-텍스트 검색 및 정렬 작업 (
Blip2ForImageTextRetrieval)을 위한 모델의 출력 구조를 정의합니다. - 처리하는 데이터 : 이 객체는 이미지-텍스트 유사도 점수, 최종 이미지/텍스트 임베딩, 그리고 각 서브 모델의 상세 출력을 담습니다. 주로 두 모달리티 간의 관계를 수치화한 스코어와 이를 생성하는 데 사용된 최종 임베딩을 보고합니다.
🔸 Blip2TextModelOutput
- 역할:
Blip2TextModelWithProjection클래스 (Q-Former 기반 텍스트 인코더) 의 출력 구조를 정의합니다.CLIPTextModelOutput에서 복사되었습니다. - 처리하는 데이터 : Q-Former 모델이 출력한 데이터, 해당출력에서 선형변환을 거친 데이터, 모든 Q-Former layer의 은닉상태, Q-Former의 attention layer의 가중치를 출력합니다.
🔸 Blip2VisionModelOutput
- 역할: 비전 모델 (
Blip2VisionModel또는Blip2VisionModelWithProjection)의 출력 구조를 정의합니다.CLIPVisionModelOutput에서 복사되었습니다. - 처리하는 데이터: 이미지 encoder의 출력, 해당 출력이 Q-Former와 선형변환 레이어를 거친 데이터, 이미지 encoder의 모든 레이어의 은닉상태, 이미지 encoder의 attention layer의 가중치를 출력합니다.
🔻 2. 기본 신경망 모듈 (Core Building Blocks) 클래스
modeling_blip_2.py
│
├────🔻Core Building Blocks (기본 신경망 모듈)
│ ├──── class Blip2VisionEmbeddings (이미지 -> 임베딩)
│ ├──── def eager_attention_forward (어텐션 구현 함수)
│ ├──── class Blip2Attention (Vision Encoder용 Self-Attention)
│ ├──── class Blip2MLP (Vision Encoder용 Feed-Forward)
│ ├──── class Blip2EncoderLayer (Vision Encoder의 단일 Transformer 레이어)
│ ├──── class Blip2QFormerMultiHeadAttention (Q-Former용 Multi-Head Attention)
│ ├──── class Blip2QFormerSelfOutput (Q-Former용 Self-Attention 출력)
│ ├──── class Blip2QFormerIntermediate (Q-Former용 Feed-Forward 중간)
│ ├──── class Blip2QFormerOutput (Q-Former용 Feed-Forward 출력)
│ ├──── class Blip2QFormerLayer (Q-Former의 단일 Transformer 레이어)
│ └──── class Blip2TextEmbeddings (Q-Former 텍스트 입력용 임베딩)기본 신경망 모듈 클래스는 BLIP-2 모델을 구성하는 가장 기본적인 구조를 구현합니다. 임베딩 모듈, 어텐션 모듈, 기본 이미지 encoder 블록, Q-Former 블록 등이 있습니다.
🔸class Blip2VisionEmbeddings(nn.Module)
- 역할: 픽셀 이미지 데이터를 Vision Transformer가 처리할 수 있는 임베딩 시퀀스로 변환하는 역할을 합니다.
- 주요 프로세스:
- 패치 임베딩 (Patch Embedding): 2D Convolution (
nn.Conv2d)을 사용하여 이미지를 겹치지 않는 작은 패치들로 나누고, 각 패치를 고차원 벡터로 변환합니다. - 클래스 임베딩 (Class Embedding): 시퀀스의 시작에 추가되는 학습 가능한 토큰으로, 전체 이미지에 대한 요약된 정보를 담는 역할을 합니다.
[CLS]토큰이라 이해하시면 됩니다. - 위치 임베딩 (Position Embedding): 각 패치의 공간적 위치 정보를 인코딩하여 임베딩에 더합니다.
- 패치 임베딩 (Patch Embedding): 2D Convolution (
- 데이터 흐름/변화:
1. 입력:pixel_values
2.patch_embedding(Conv2d)을 통해 픽셀 값을 패치 특징 맵으로 변환합니다. →(Batch, embed_dim, Grid_H, Grid_W)
3.flatten및transpose를 통해 패치 특징 맵을 시퀀스 형태의 패치 임베딩으로 만듭니다. →(Batch, Num_Patches, embed_dim)
4.class_embedding을expand하여 배치 차원에 맞춘 후, 패치 임베딩(patch_embeds) 앞에torch.cat으로 이어 붙입니다. →(Batch, 1 + Num_Patches, embed_dim)
5.position_embedding을 더하여 각 토큰에 위치 정보를 주입합니다.
6. 출력:embeddings→(Batch, 1 + Num_Patches, embed_dim)Vision Encoder의 입력으로 사용될 시퀀스 임베딩입니다.
🔸def eager_attention_forward
- 역할: PyTorch의 기본 연산을 사용하여 실제 Attention 연산을 수학적으로 수행하는 함수입니다.
- 데이터 흐름/변화:
1. 입력:query,key,value텐서,attention_mask
2.query와key의 전치된 형태를torch.matmul하여 원시 어텐션 점수(attn_weights)를 계산합니다.
3.attention_mask가 존재하면attn_weights에 더하여 패딩 토큰 등의 어텐션을 비활성화합니다.
4.nn.functional.softmax를 적용하여 어텐션 가중치(attention_probs)를 확률 분포로 정규화합니다.
5. 학습 시nn.functional.dropout을 적용하여 어텐션 가중치의 일부를 무작위로 0으로 만듭니다.
6. 드롭아웃이 적용된 어텐션 가중치(attention_probs_dropped)와value텐서를torch.matmul하여 최종 어텐션 출력(attn_output)을 계산합니다.
7. 출력:attn_output(어텐션 결과)와attn_weights(어텐션 가중치).
🔸class Blip2Attention(nn.Module)
- 역할: Vision Encoder의 단일 멀티-헤드 셀프 어텐션(Multi-headed Self-Attention) 블록을 구현합니다.
Blip2EncoderLayer내에서 사용됩니다. 이미지 데이터의 문맥적 의미를 이해하는 핵심구조입니다. - 주요 특징:
- 입력
hidden_states로부터 Query (Q), Key (K), Value (V)를 생성하는qkv선형 레이어를 가집니다. eager_attention_forward또는 최적화된 어텐션 백엔드를 선택적으로 사용하여 실제 어텐션 계산을 위임합니다.- 계산된 어텐션 결과를 다시 입력 차원(
embed_dim)으로 투영하는projection선형 레이어를 가집니다.
- 입력
- 데이터 흐름/변화:
1. 입력: 앞서 살펴본 이미지 임베딩hidden_states→(Batch, 1 + Num_Patches, embed_dim)
2.qkv선형 레이어를 통해hidden_states로부터mixed_qkv를 생성하고, 이를 Query, Key, Value 텐서로 분리합니다. →(Batch, Num_Heads, Seq_Len, Head_Dim)
3.eager_attention_forward를 호출하여attn_output와attn_weights를 얻습니다.
4.attn_output의 헤드 차원을 다시embed_dim으로 재구성합니다.
5.projection선형 레이어를 통해attn_output을 최종 어텐션 블록 출력으로 변환합니다.
6. 출력:attn_output(맥락을 이해한 이미지 데이터)와attn_weights
🔸class Blip2MLP(nn.Module)
- 역할: Vision Encoder의 트랜스포머 레이어 내에서 어텐션 이후에 적용되는 피드포워드 네트워크 블록을 구현합니다. 문맥 정보가 반영된 개별 토큰의 의미를 정제하는 역할을 수행합니다.
- 주요 특징: 두 개의 선형 레이어(
fc1,fc2)와 그 사이에 비선형 활성화 함수(activation_fn)를 가집니다. 입력 차원(config.hidden_size)을config.intermediate_size로 확장했다가 다시config.hidden_size로 축소하는 구조입니다. - 데이터 흐름/변화:
1. 입력:hidden_states→(Batch, 1 + Num_Patches, embed_dim)
2.fc1선형 레이어를 통과하여 차원을intermediate_size로 확장합니다.
3.activation_fn을 적용하여 비선형성을 추가합니다.
4.fc2선형 레이어를 통과하여 차원을 다시hidden_size로 축소합니다.
5. 출력: 변환된hidden_states→(Batch, 1 + Num_Patches, embed_dim)
🔸class Blip2EncoderLayer(nn.Module)
- 역할: Vision Encoder를 구성하는 기본 블록을 구현합니다.
Blip2Attention과Blip2MLP를 포함하며, 잔차 연결과 레이어 정규화를 사용하여 안정적인 학습을 돕습니다. 이미지가num_hidden_layers만큼의 이Blip2EncoderLayer를 통과하면서 점진적으로 고수준의 시각적 특징으로 인코딩됩니다. - 데이터 흐름/변화:
1. 입력:hidden_states→(Batch, 1 + Num_Patches, embed_dim)
2. 첫 번째 LayerNorm (layer_norm1)을 통과합니다.
3.self_attn(Blip2Attention)을 통과하여 어텐션이 적용된hidden_states와attn_weights를 얻습니다.
4. 어텐션 결과에residual(원래 입력hidden_states)을 더합니다.
5. 두 번째 LayerNorm (layer_norm2)을 통과합니다.
6.mlp(Blip2MLP)를 통과하여hidden_states를 비선형적으로 변환합니다.
7. MLP 결과에residual(어텐션 이후의hidden_states)을 다시 더합니다.
8. 출력: 최종hidden_states와 선택적으로attn_weights.
🔸class Blip2QFormerMultiHeadAttention(nn.Module)
- 역할: Q-Former 내에서 사용되는 멀티-헤드 어텐션 모듈입니다. Self-Attention과 Cross-Attention 모두를 처리할 수 있도록 설계된 것이 특징입니다. 즉 Q-Former가 자기 자신의 관계를 학습하거나, 가장 중요한 기능인 Vision Encoder의 출력과 Query 토큰 간의 상호작용을 학습하는 데 사용되는 핵심 메커니즘입니다.
- 주요 특징:
is_cross_attention이 True일 경우 cross attention이, False일 경우 self-attention이 수행됩니다.- 앞서
configuration_blip_2.py에서 봤던cross_attention_frequency파라미터에 의해 결정되는 값입니다.
- 데이터 흐름/변화:
1. 입력:hidden_states(Query 생성),encoder_hidden_states(Cross-Attention 시 Key/Value 생성),attention_mask.
2. Query, Key, Value를 각각의 선형 레이어를 통해 생성하고, 멀티-헤드 어텐션에 맞게 형태를 변환합니다.
3. 어텐션 점수를 계산하고,attention_mask를 적용하여 불필요한 상호작용을 차단합니다.
4. 상대 위치 임베딩이 설정된 경우 어텐션 점수에 위치 정보를 추가합니다.
5. 소프트맥스 및 드롭아웃을 적용하여 어텐션 확률을 계산합니다.
6. 어텐션 확률과 Value 텐서의 행렬 곱을 통해 문맥 정보를 담은context_layer를 생성합니다.
7. 출력:context_layer(어텐션 결과)와 선택적으로attention_probs.
🔸class Blip2QFormerSelfOutput(nn.Module)
- 역할: Q-Former 트랜스포머 레이어 내에서 Self-Attention 또는 Cross-Attention 모듈의 출력을 처리하는 부분입니다. 어텐션 결과에 추가적인 비선형 변환과 정규화를 적용하고, 잔차 연결을 통해 정보 손실을 방지하여 깊은 네트워크의 학습을 안정화합니다.
- 주요 특징:
dense선형 레이어,LayerNorm,dropout으로 구성됩니다. - 데이터 흐름/변화:
1. 입력:hidden_states(어텐션 모듈의 출력),input_tensor(잔차연결할 데이터).
2.dense레이어를 통과하고dropout을 적용합니다.
3.LayerNorm을 적용하면서input_tensor를 더합니다. (잔차연결)
4. 출력: 정규화되고 변환된hidden_states.
🔸class Blip2QFormerIntermediate(nn.Module)
- 역할: Q-Former 트랜스포머 레이어 내의 피드포워드 네트워크(FFN)의 첫 번째 부분입니다. Attention 과정을 거친 데이터를 정제한다고 이해하시면 됩니다.
- 주요 특징:
dense선형 레이어와 활성화 함수(intermediate_act_fn)로 구성됩니다. 입력 차원(config.hidden_size)을config.intermediate_size로 확장합니다. - 데이터 흐름/변화:
1. 입력:hidden_states
2.dense레이어를 통과하여 차원 확장.
3. 활성화 함수를 적용하여 비선형성 추가.
4. 출력: 확장된hidden_states.
🔸class Blip2QFormerOutput(nn.Module)
- 역할: Q-Former 트랜스포머 레이어 내의 피드포워드 네트워크(FFN)의 두 번째 부분이자 최종 출력 부분입니다. 정규화와 잔차연결을 통해 더 안정적인 학습을 수행합니다.
- 주요 특징:
dense선형 레이어,LayerNorm,dropout으로 구성됩니다.config.intermediate_size차원을config.hidden_size로 축소합니다. - 데이터 흐름/변화:
1. 입력:hidden_states(Intermediate 모듈의 출력),input_tensor
2.dense레이어를 통과하고dropout을 적용합니다.
3.LayerNorm을 적용하면서input_tensor를 더합니다. (잔차 연결)
4. 출력: 최종 변환된hidden_states.
🔸class Blip2QFormerLayer(nn.Module)
- 역할: Q-Former를 구성하는 단일 트랜스포머 레이어(블록) 를 구현합니다.
Blip2QFormerMultiHeadAttention통해 구현한 attention과 Feed-Forward 네트워크를 연결합니다. 입력된 텍스트의 요구사항을 반영하기 위해 함께 self-attention이 적용되고, 이미지를 가져올 때는 슬라이싱을 통해 쿼리 벡터만 가져오는 것을 확인할 수 있습니다. Q-Former가 텍스트 임베딩을 생성할 때query_length==0을 만족합니다. - 데이터 흐름/변화:
- 입력:
hidden_states(Query 토큰 임베딩),attention_mask,encoder_hidden_states(Vision Encoder의 이미지 임베딩, Cross-Attention 시). self.attention(자기-어텐션)을 먼저 수행하여hidden_states를 업데이트합니다.query_length > 0인 경우:query_attention_output(Query 토큰에 해당하는hidden_states부분)을 추출합니다.self.has_cross_attention이True(즉, 해당 레이어에서 교차 어텐션이 활성화됨)인 경우,self.crossattention을 통해query_attention_output이encoder_hidden_states에 대해 교차 어텐션을 수행하여 이미지 정보를 Query 토큰에 주입합니다.feed_forward_chunk_query를 통해 Query 토큰 부분에 대한 FFN을 적용합니다.- (선택적으로)
attention_output의 나머지 부분(attention_output[:, query_length:, :])이 있다면feed_forward_chunk를 통해 해당 부분에 대한 FFN을 적용하고, 결과를query_length부분과torch.cat으로 이어 붙입니다.
query_length == 0인 경우: 전체attention_output에 대해feed_forward_chunk를 적용합니다.- 출력: 최종
layer_output(현재 레이어를 통과한 후의hidden_states)와 선택적으로 어텐션 가중치 및past_key_value.
- 입력:
🔸class Blip2TextEmbeddings(nn.Module)
- 역할: Q-Former가 텍스트 입력을 처리할 때 사용되는 단어 임베딩(word embeddings)과 위치 임베딩(position embeddings) 을 생성합니다. Q-Former가 텍스트 데이터를 이해하고 처리할 수 있도록 텍스트 토큰을 고차원 벡터 공간으로 매핑하는 초기 단계입니다.
- 주요 특징:
word_embeddings:config.vocab_size와config.hidden_size에 따라 단어 ID를 벡터로 변환하는nn.Embedding레이어.position_embeddings:config.max_position_embeddings에 따라 토큰의 위치를 벡터로 변환하는nn.Embedding레이어.position_embedding_type: 절대 위치 또는 상대 위치를 사용합니다.
- 데이터 흐름/변화:
- 입력:
input_ids(텍스트 토큰 ID 시퀀스),position_ids(선택적). word_embeddings를 통해input_ids를 임베딩 벡터로 변환합니다.position_embeddings를 통해position_ids를 임베딩 벡터로 변환합니다.- 두 임베딩을 더하여 최종
embeddings를 생성합니다. - (
query_embeds가 있는 경우)query_embeds를 이embeddings앞에torch.cat으로 이어 붙입니다. 이는Blip2TextModelWithProjection에서 텍스트 프롬프트와 함께 Query 토큰을 Q-Former에 입력할 때 사용됩니다. - 출력:
embeddings(Q-Former의 입력으로 사용될 텍스트 시퀀스 임베딩).
- 입력:
🔻 3. 전체 모델 (Composite Models) 클래스
modeling_blip_2.py
└────🔻Composite Models (복합 모델 및 전체 모델)
├────🦴Base & Backbone Models (기본 및 백본 모델)
│ ├──── class Blip2PreTrainedModel (모든 BLIP-2 모델의 기본 클래스)
│ ├──── class Blip2Encoder (Vision Encoder의 전체 Transformer)
│ ├──── class Blip2VisionModel (Vision Encoder의 전체 모델)
│ └──── class Blip2QFormerModel (Q-Former의 전체 모델)
│
├────🔍Projection & Specialized Feature Extractors (투영 및 특화된 특징 추출기)
│ ├──── class Blip2TextModelWithProjection (텍스트 임베딩 추출 + 투영)
│ └──── class Blip2VisionModelWithProjection (이미지 임베딩 추출 + 투영)
│
└────▶️End-to-End Task Models (종단 간(End-to-End) 태스크 모델)
├──── class Blip2Model (Vision, Q-Former, Language Model 통합 모델)
│ ├──── def get_text_features
│ ├──── def get_image_features
│ ├──── def get_qformer_features
│ └──── def forward (BLIP-2 통합 모델의 전방향 패스)
├──── class Blip2ForConditionalGeneration (조건부 텍스트 생성 모델)
│ ├──── def get_image_features (재정의된 이미지 특징 추출)
│ ├──── def forward (조건부 생성 모델의 전방향 패스)
│ └──── def generate (텍스트 생성 메서드)
└──── class Blip2ForImageTextRetrieval (이미지-텍스트 검색 모델)
└──── def forward (이미지-텍스트 검색 모델의 전방향 패스)BLIP-2의 이미지 encoder, Q-Former, BLIP-2 전체 구조를 구현하고, 이미지 캡션 생성과 이미지-텍스트 검색 기능을 구현합니다.
🦴 3-1. 기본 및 백본 모델 (Base & Backbone Models)
modeling_blip_2.py
└────🔻Composite Models (복합 모델 및 전체 모델)
├────🦴Base & Backbone Models (기본 및 백본 모델)
│ ├──── class Blip2PreTrainedModel (모든 BLIP-2 모델의 기본 클래스)
│ ├──── class Blip2Encoder (Vision Encoder의 전체 Transformer)
│ ├──── class Blip2VisionModel (Vision Encoder의 전체 모델)
│ └──── class Blip2QFormerModel (Q-Former의 전체 모델)Base & Backbone Models에서는 앞서 구현한 기본 신경망 클래스를 결합하여, 최종 이미지 encoder와 Q-Former를 구현합니다. 이 모듈들은
Blip2Model의 최종 구조로 활용됩니다.
🔸class Blip2PreTrainedModel(PreTrainedModel)
- 역할: 모든 BLIP-2 관련 모델들이 공통적으로 사용하는 기본 기능을 제공하는 추상 기본 클래스입니다. 다른 함수에서 해당 class를 상속받으며, 가중치 초기화, 사전 학습된 모델 로딩/저장, 장치 매핑 처리, 경사 체크포인팅 등을 지원합니다.
🔸class Blip2Encoder(nn.Module)
- 역할: Vision Encoder의 핵심인 전체 Transformer 인코더를 구현합니다.
Blip2EncoderLayer를config.num_hidden_layers만큼 여러 개 쌓아 올린 구조입니다. 이미지 패치 임베딩을 입력받아 고수준의 시각적 데이터로 변환합니다. - 주요 특징:
self.layers = nn.ModuleList([Blip2EncoderLayer(config) for _ in range(config.num_hidden_layers)]):config.num_hidden_layers에 명시된 수(예: 39개)만큼의Blip2EncoderLayer인스턴스를 포함합니다. 이는 모델의 깊이를 결정합니다.self.gradient_checkpointing = False: 경사 체크포인팅(torch.utils.checkpoint)을 사용하여 역전파 시 중간 활성화 값을 다시 계산함으로써 메모리 사용량을 줄일 수 있도록 합니다.
- 데이터 흐름/변화: 입력된
inputs_embeds는 여러 층의 트랜스포머 인코더 레이어를 통과하면서 어텐션과 피드포워드 변환을 거칩니다. 각 레이어를 거칠 때마다 데이터는 점진적으로 더 추상적이고 고수준의 시각적 특징 표현으로 변환됩니다.hidden_states텐서의 값들이 각 레이어를 통해 복잡하게 재계산되고 정제되며,attention_mask에 의해 특정 상호작용은 차단됩니다. forward메서드:- 입력:
inputs_embeds(주로Blip2VisionEmbeddings에서 나온 이미지 패치 임베딩, 형태:(Batch, Seq_Len, hidden_size)) - 레이어 순환:
config.num_hidden_layers만큼의encoder_layer(Blip2EncoderLayer)를 순차적으로 반복합니다.- 각 레이어의 입력으로 현재
hidden_states,attention_mask,output_attentions를 전달합니다. gradient_checkpointing이 활성화되고 학습 중일 경우,_gradient_checkpointing_func를 사용하여 메모리 효율적으로 포워드 패스를 수행합니다.- 각
layer_outputs를 받습니다. hidden_states를 다음 레이어의 입력으로 업데이트합니다.output_hidden_states가True이면 현재hidden_states를encoder_states튜플에 추가합니다.output_attentions가True이면 현재 레이어의 어텐션 가중치를all_attentions튜플에 추가합니다.
- 각 레이어의 입력으로 현재
- 최종 상태 저장: 모든 레이어를 통과한 후의 최종
hidden_states를encoder_states에 추가합니다. - 출력 형식:
return_dict가True이면BaseModelOutput객체로, 그렇지 않으면 튜플 형태로last_hidden_state,hidden_states,attentions를 반환합니다.
- 입력:
🔸class Blip2VisionModel(Blip2PreTrainedModel)
- 역할: 이미지 픽셀 값을 받아
Blip2Encoder를 통해 시각적 특징 임베딩을 생성하는 최종 이미지 encoder입니다. 지금까지 만들었던Blip2VisionEmbeddings(config),Blip2Encoder(config)를 연결하여 픽셀 단위의 이미지를 Q-Former가 가져갈 수 있는 형태로 변환합니다. forward메서드:- 입력:
pixel_values(원시 이미지 데이터, 형태:(Batch, Channels, Height, Width)). - 임베딩:
self.embeddings(pixel_values, interpolate_pos_encoding=...)를 호출하여 픽셀 값을 트랜스포머 입력 가능한 시퀀스 임베딩(hidden_states, 형태:(Batch, 1 + Num_Patches, embed_dim))으로 변환합니다. - 인코딩:
self.encoder(inputs_embeds=hidden_states, ...)를 호출하여 임베딩된 시퀀스를 Vision TransformerBlip2Encoder를 통과시킵니다. - 최종 정규화:
encoder_outputs[0](인코더의last_hidden_state)에self.post_layernorm을 적용합니다. - 풀링된 출력:
last_hidden_state의 첫 번째 토큰([:, 0, :])을 추출하여pooler_output으로 사용합니다 (이것이 클래스 토큰[CLS]에 해당하는 이미지의 요약 특징입니다). 이pooler_output에도 다시post_layernorm을 적용합니다. - 출력:
BaseModelOutputWithPooling객체 형태로,last_hidden_state,pooler_output, 선택적으로hidden_states,attentions를 반환합니다.
- 입력:
- 데이터 흐름/변화: 원시 이미지 픽셀 데이터는 이 모델을 거치면서 패치화되고 임베딩된 후, 깊은 트랜스포머 인코더를 통과하며 고수준의 시각적 특징(
last_hidden_state)으로 변환됩니다. 특히pooler_output은 이미지 전체를 대표하는 압축된 벡터로 생성되어 Q-Former의 입력으로 사용될 준비를 합니다.
🔸class Blip2QFormerModel(Blip2PreTrainedModel)
- 역할:
Blip2QFormerEncoder와 정규화, 드롭아웃 레이어를 합하여 만든 최종 Q-Former 모델입니다. BLIP-2에서 이미지 정보와 언어 정보 사이를 연결하는 핵심적인 다중 모달 역할을 수행합니다. 참고로 입력되는query_embeds는 더 상위 모델인Blip2Model에서 만들어집니다. - 데이터 흐름/변화: 입력된
query_embeds는 초기 정규화 및 드롭아웃을 거친 후,Blip2QFormerEncoder의 여러Blip2QFormerLayer를 통과합니다. 이 과정에서encoder_hidden_states(이미지 특징)와 주기적으로 교차 어텐션을 수행하며 시각적 문맥을 흡수합니다. 결과적으로query_embeds는 이미지 정보가 압축되고 요약된last_hidden_state로 변환되며, 이 중pooler_output은 언어 모델의 입력으로 사용될 핵심 정보가 됩니다. forward메서드:- 입력:
query_embeds,query_length,attention_mask,encoder_hidden_states(Vision Encoder에서 나온 이미지 임베딩),encoder_attention_mask. - 입력 임베딩 처리:
query_embeds에layernorm과dropout을 적용합니다. - 마스크 확장:
attention_mask와encoder_attention_mask를 어텐션 계산에 적합한 확장된 형태로 변환합니다. - Q-Former 인코딩:
self.encoder(...)를 호출하여 처리된query_embeds를 Q-Former의 핵심 인코더(Blip2QFormerEncoder)를 통과시킵니다. 이 과정에서encoder_hidden_states에 대한 교차 어텐션이 주기적으로 발생하여 Query 토큰에 이미지 정보가 융합됩니다. - 풀링된 출력:
sequence_output(인코더의 최종 은닉 상태)의 첫 번째 토큰([:, 0, :])을pooled_output으로 사용합니다. 이는 Q-Former의 출력을 대표하는 압축된 벡터입니다. - 출력:
last_hidden_state(최종 처리된 Query 토큰 임베딩),pooler_output, 선택적으로past_key_values,hidden_states,attentions,cross_attentions를 반환합니다.
- 입력:
🔍 3-2. 투영 및 특징 추출기 (Projection & Specialized Feature Extractors)
modeling_blip_2.py
└────🔻Composite Models (복합 모델 및 전체 모델)
│
├────🔍Projection & Specialized Feature Extractors (투영 및 특화된 특징 추출기)
│ ├──── class Blip2TextModelWithProjection (텍스트 임베딩 추출 + 투영)
│ └──── class Blip2VisionModelWithProjection (이미지 임베딩 추출 + 투영)Projection & Specialized Feature Extractors에서는 BLIP-2의 학습과 검색에 활용되는 텍스트, 이미지 임베딩을 출력하는 class를 구현합니다.
🔸class Blip2TextModelWithProjection(Blip2PreTrainedModel)
- 역할: 텍스트 입력을 받아
Blip2QFormerModel을 통해 처리한 후, 이미지 특징과 비교 가능한 공통 임베딩 공간으로 텍스트 특징을 투영(project)하여 추출하는 모델입니다. 향후 이미지-텍스트 검색(Blip2ForImageTextRetrieval) 작업에서 텍스트 측면의 특징을 얻는 데 사용됩니다. - 주요 특징:
self.query_tokens = nn.Parameter(...): 이 모델 내에서도 학습 가능한 쿼리 토큰을 가집니다. 하지만 이 모델의forward에서는 이 쿼리 토큰이 직접 이미지와 상호작용하는 용도가 아니라,Blip2TextEmbeddings에서 나오는 텍스트 임베딩과 결합되어self.qformer의 입력으로 사용될 수 있습니다.self.embeddings = Blip2TextEmbeddings(config.qformer_config): 텍스트input_ids를 임베딩으로 변환하는 모듈.self.qformer = Blip2QFormerModel(config.qformer_config): Q-Former 모델의 인스턴스.self.text_projection = nn.Linear(config.qformer_config.hidden_size, config.image_text_hidden_size): Q-Former의 최종 출력을config.image_text_hidden_size차원으로 투영하는 선형 레이어. 이image_text_hidden_size는 이미지 특징의 투영 차원과 일치하여 두 모달리티의 특징이 동일한 공간에서 비교될 수 있도록 합니다.
- 데이터 흐름/변화: 입력된 텍스트 토큰은
Blip2TextEmbeddings를 통해 임베딩된 후,Blip2QFormerModel을 통과하며 심층적으로 인코딩됩니다. 이 Q-Former의 출력은self.text_projection선형 레이어를 통해image_text_hidden_size차원으로 투영되고 정규화됩니다. 이 과정에서 텍스트 데이터는 이미지 특징과 직접 비교될 수 있는 공통 벡터 공간의 특징 표현으로 변환됩니다. forward메서드:- 입력:
input_ids(텍스트 토큰 ID) - 텍스트 임베딩 생성:
self.embeddings(...)를 호출하여 텍스트input_ids를 임베딩(query_embeds)으로 변환합니다. - Q-Former 처리:
self.qformer(...)를 호출하여query_embeds를 Q-Former에 입력합니다. 이때query_length=0이 명시적으로 전달되어, Q-Former는 순수 텍스트 인코딩 모드로 작동하며 이미지에 대한 교차 어텐션 없이 텍스트 자체를 심층적으로 처리합니다. - 최종 특징 투영:
text_outputs.last_hidden_state(Q-Former의 최종 은닉 상태)를self.text_projection레이어로 투영합니다. - 정규화: 투영된 특징(
text_embeds)에nn.functional.normalize(..., dim=-1)를 적용하여 L2 정규화를 수행합니다. 이는 임베딩 간의 코사인 유사도 계산을 용이하게 합니다. - 출력:
text_embeds(정규화된 투영 텍스트 특징) 입니다.
- 입력:
🔸class Blip2VisionModelWithProjection(Blip2PreTrainedModel)
- 역할:
Blip2VisionModel에서 추출된 이미지 특징을Blip2QFormerModel을 통해 처리하고, 이를 텍스트 특징과 비교 가능한 공통 임베딩 공간으로 이미지 특징을 투영(project)하여 추출하는 모델입니다. 향후 이미지-텍스트 검색(Blip2ForImageTextRetrieval) 작업에서 텍스트 측면의 특징을 얻는 데 사용됩니다. - 주요 특징:
main_input_name = "pixel_values": 주요 입력이 이미지 픽셀 값임을 명시합니다._keep_in_fp32_modules = ["query_tokens", "qformer"]: 특정 모듈을fp32로 유지합니다.self.vision_model = Blip2VisionModel._from_config(...): 전체 비전 인코더 모델의 인스턴스.self.query_tokens = nn.Parameter(...): 학습 가능한 쿼리 토큰. 이 모델의forward에서는 이 쿼리 토큰이 Vision Encoder의 출력(이미지 특징)과 교차 어텐션을 수행하여 이미지 정보를 요약하는 데 사용됩니다.self.qformer = Blip2QFormerModel._from_config(...): Q-Former 모델의 인스턴스.self.vision_projection = nn.Linear(config.qformer_config.hidden_size, config.image_text_hidden_size): Q-Former의 최종 출력을config.image_text_hidden_size차원으로 투영하는 선형 레이어.
- 데이터 흐름/변화: 입력된 이미지 픽셀은
Blip2VisionModel을 통해 고수준 시각 특징으로 인코딩된 후, 이 특징이Blip2QFormerModel에 입력되어 학습 가능한 쿼리 토큰들에 의해 요약됩니다. Q-Former의 이 요약된 출력은self.vision_projection선형 레이어를 통해image_text_hidden_size차원으로 투영되고 정규화됩니다. 이 과정에서 이미지 데이터는 텍스트 특징과 직접 비교될 수 있는 공통의 벡터 공간 특징 표현으로 변환됩니다. forward메서드:- 입력:
pixel_values(원시 이미지 데이터) - 이미지 특징 추출:
self.vision_model(...)을 호출하여 이미지 픽셀을vision_outputs로 변환합니다. - Q-Former 처리:
query_tokens를 배치 크기에 맞게expand한 후,self.qformer(...)에query_embeds=query_tokens와encoder_hidden_states=pooled_output(Vision Model의last_hidden_state)를 입력하여 처리합니다. 이 과정에서 쿼리 토큰은 이미지 정보를 효과적으로 요약합니다. - 최종 특징 투영:
query_outputs.last_hidden_state(Q-Former의 최종 은닉 상태)를self.vision_projection레이어로 투영합니다. - 정규화: 투영된 특징(
image_embeds)에nn.functional.normalize(..., dim=-1)를 적용하여 L2 정규화를 수행합니다. - 출력:
image_embeds(정규화된 투영 이미지 특징) 입니다.
- 입력:
▶️ 3-3. End-to-End 태스크 모델 (End-to-End Task Models)
modeling_blip_2.py
└────🔻Composite Models (복합 모델 및 전체 모델)
│
└────▶️End-to-End Task Models (종단 간(End-to-End) 태스크 모델)
├──── class Blip2Model (Vision, Q-Former, Language Model 통합 모델)
│ ├──── def get_text_features
│ ├──── def get_image_features
│ ├──── def get_qformer_features
│ └──── def forward (BLIP-2 통합 모델의 전방향 패스)
├──── class Blip2ForConditionalGeneration (조건부 텍스트 생성 모델)
│ ├──── def get_image_features (재정의된 이미지 특징 추출)
│ ├──── def forward (조건부 생성 모델의 전방향 패스)
│ └──── def generate (텍스트 생성 메서드)
└──── class Blip2ForImageTextRetrieval (이미지-텍스트 검색 모델)
└──── def forward (이미지-텍스트 검색 모델의 전방향 패스)End-to-End Task Models에서는 BLIP-2 모델의 학습, 이미지에 대한 텍스트 생성, 이미지-텍스트 검색을 구현한 class입니다.
- BLIP2Model : BLIP-2 모델의 백본 모델로 언어 생성에 대한 loss와 그 밖의 BLIP-2의 중간 출력을 모아 반환합니다. BLIP-2를 다른 목적으로 사용할 때 활용될 것으로 보입니다.
- BLIP2ForConditionalGeneration : BLIP-2 모델을 통해 최종 텍스트 생성을 수행하는 모델입니다.
- BLIP2ForImageTextRetrieval : BLIP-2 모델을 통해 이미지-텍스트 검색을 수행하는 모델입니다.
🔸class Blip2Model(Blip2PreTrainedModel)
- 역할: BLIP-2 모델의 최종 통합 모델입니다.
Blip2VisionModel,query_tokens,Blip2QFormerModel, 언어 모델(AutoModelForCausalLM또는AutoModelForSeq2SeqLM)을 모두 포함하며, 이미지와 텍스트 프롬프트를 입력받아 언어 모델을 통해 텍스트를 생성하는 전체 BLIP-2 파이프라인의 전방향 패스(forward)를 구현합니다. - 구조 설계:
config_class = Blip2Config: 이 모델이Blip2Config를 사용하여 구성됨을 나타냅니다.self.vision_model = Blip2VisionModel._from_config(config.vision_config): Vision Encoder를 초기화합니다.self.query_tokens = nn.Parameter(torch.zeros(1, config.num_query_tokens, config.qformer_config.hidden_size)): 이미지 정보를 쿼리하는 데 사용되는 학습 가능한 쿼리 토큰을 정의합니다.self.qformer = Blip2QFormerModel._from_config(config.qformer_config): Q-Former를 초기화합니다.self.language_projection = nn.Linear(config.qformer_config.hidden_size, config.text_config.hidden_size): Q-Former의 출력을 언어 모델의 입력 차원으로 매핑하는 선형 레이어입니다.self.language_model:config.use_decoder_only_language_model설정에 따라AutoModelForCausalLM(디코더 기반 LLM) 또는AutoModelForSeq2SeqLM(인코더-디코더 기반 LLM) 중 하나로 언어 모델을 로드합니다.
- 사용함수
def get_text_features(self, input_ids, attention_mask, ...):- 역할: 언어 모델(
self.language_model)에 텍스트(input_ids)를 직접 전달하여 언어 모델의 출력을 얻는 함수입니다. - 데이터 흐름/변화: 입력 텍스트 토큰 ID를 언어 모델에 전달하여, 언어 모델이 해당 텍스트를 인코딩하거나 디코딩한 결과를 반환합니다. 이 메서드는 Q-Former나 Vision Encoder를 거치지 않고 순수하게 언어 모델의 텍스트 처리 능력을 확인하고 싶을 때 유용합니다.
- 역할: 언어 모델(
def get_image_features(self, pixel_values, ...):- 역할:
self.vision_model을 호출하여 이미지 픽셀에서 직접 시각적 특징(vision_outputs)을 추출하는 함수입니다.
- 역할:
def get_qformer_features(self, pixel_values, ...):- 역할: 이미지 픽셀 값을 입력받아
self.vision_model을 거친 후,self.query_tokens와 함께self.qformer를 통과시켜 Q-Former의 출력(처리된 쿼리 토큰 임베딩) 을 얻는 함수입니다.
- 역할: 이미지 픽셀 값을 입력받아
def forward(self, pixel_values, input_ids, attention_mask, ...)- 역할: BLIP-2 모델의 가장 중요한 통합 전방향 패스입니다. 이미지와 텍스트 프롬프트를 동시에 입력받아 최종적으로 언어 모델의 로짓과 손실을 계산합니다.
- 데이터 흐름/변화:
- Step 1: 이미지 인코딩:
self.vision_model(pixel_values=pixel_values, ...)를 호출하여vision_outputs와image_embeds(Vision Encoder의last_hidden_state)를 얻습니다. (이미지 픽셀 -> 시각 특징) - Step 2: Q-Former 처리:
image_embeds와self.query_tokens를 사용하여self.qformer(...)를 호출하여query_outputs와query_output(이미지 정보가 요약된 쿼리 임베딩)을 얻습니다. (시각 특징 + 쿼리 토큰 -> 시각 정보가 요약된 쿼리 임베딩) - Step 3: 언어 모델 준비 및 실행:
language_model_inputs = self.language_projection(query_output): Q-Former의 출력을 언어 모델 입력 차원으로 투영합니다.inputs_embeds = self.language_model.get_input_embeddings()(input_ids): 텍스트input_ids를 언어 모델 임베딩으로 변환합니다.- 이미지-텍스트 결합: (soft engineering 과정)
image_token_id가 설정된 경우:special_image_mask를 사용하여input_ids내의image_token_id위치에language_model_inputs를 삽입합니다 (inputs_embeds.masked_scatter). 이 경우 언어 모델 입력 시퀀스의 길이가query_tokens수만큼 늘어납니다.image_token_id가 없는 경우 (레거시):language_model_inputs를 텍스트inputs_embeds앞에torch.cat으로 이어 붙입니다.
self.language_model(...)를 호출하여 최종 결합된inputs_embeds를 언어 모델에 전달하여outputs(로짓 등)를 얻습니다.
- 출력:
loss,logits,vision_outputs,qformer_outputs,language_model_outputs
- Step 1: 이미지 인코딩:
🔸class Blip2ForConditionalGeneration(Blip2PreTrainedModel, GenerationMixin)
- 역할: 이미지-캡셔닝, 시각 질문 응답(VQA) 과 같이 이미지를 기반으로 텍스트를 생성하는 조건부 생성 모델입니다.
Blip2Model의 기능을 활용하며, Hugging FaceGenerationMixin을 상속받아 텍스트 생성에 특화된generate메서드를 제공합니다. def get_image_features(self, pixel_values, ...)(재정의된 이미지 특징 추출):- 역할:
Blip2Model.get_image_features와 유사하지만, 이 모델의generate메서드에서 내부적으로 호출됩니다. 이미지 픽셀 값을 받아language_model_inputs(언어 모델로 투영될 이미지 요약 쿼리 임베딩)와vision_outputs,query_outputs를 반환합니다. - 데이터 흐름/변화: 이 메서드는
Blip2Model.forward의 Step 1과 Step 2의 결과를 묶어서 반환합니다. 즉, 이미지 픽셀에서 Q-Former를 거쳐 언어 모델의 입력으로 들어갈 준비가 된 시각적 특징(language_model_inputs)을 얻는 과정을 캡슐화합니다.
- 역할:
def forward(self, pixel_values, input_ids, attention_mask, ...)(조건부 생성 모델의 전방향 패스):- 역할:
Blip2Model의forward와 거의 동일합니다. 주로 학습 시 손실을 계산하는 데 사용됩니다. - 데이터 흐름/변화:
self.get_image_features(...)를 호출하여 이미지 특징을 얻고, 이를 텍스트input_ids임베딩과 결합하여 언어 모델에 전달한 후, 언어 모델의 로짓과 손실을 계산합니다.
- 역할:
def generate(self, pixel_values, input_ids, attention_mask, ...)(텍스트 생성 메서드):- 역할: BLIP-2 모델을 사용하여 실제로 텍스트 시퀀스를 생성하는 추론(inference) 전용 메서드입니다.
- 데이터 흐름/변화:
- 이미지 특징 추출 (추론용):
self.vision_model(...)과self.qformer(...)를 통해language_model_inputs(언어 모델로 전달될 이미지 요약 쿼리 임베딩)를 얻습니다. - 시작 토큰 구성:
input_ids(텍스트 프롬프트)가None인 경우,config.text_config.bos_token_id(문장 시작 토큰) 또는config.image_token_id(이미지 토큰)를 사용하여 텍스트 생성의 시작 토큰을 구성합니다. - 언어 모델 입력 결합:
language_model_inputs와 텍스트input_ids의 임베딩을 결합하여 언어 모델의 최종 입력(inputs_embeds)을 준비합니다. - 생성 파라미터 조정:
max_length,min_length등generate_kwargs를 조정하여 이미지 임베딩 길이가 생성 길이에 영향을 미치도록 합니다. - 텍스트 생성 실행:
self.language_model.generate(**inputs, **generate_kwargs)를 호출하여 실제 텍스트 시퀀스를 생성합니다. 이 과정에서 Hugging FaceGenerationMixin이 제공하는 빔 서치, 샘플링, 온도 조절 등 다양한 생성 전략이 적용됩니다. - 출력: 생성된 텍스트 토큰 ID 시퀀스 (
torch.LongTensor).
- 이미지 특징 추출 (추론용):
🔸class Blip2ForImageTextRetrieval(Blip2PreTrainedModel)
- 역할: 이미지와 텍스트 간의 관련성(유사도)을 측정하여 이미지-텍스트 검색(Image-Text Retrieval) 을 수행하는 모델입니다. ITM 또는 ITC 방식을 사용하여 이미지-텍스트 유사돌르 출력합니다.
- 주요 특징:
self.vision_model,self.query_tokens,self.qformer: 동일하게 사용.self.embeddings = Blip2TextEmbeddings(config.qformer_config): 텍스트input_ids를 임베딩하는 데 사용됩니다.self.vision_projection = nn.Linear(...),self.text_projection = nn.Linear(...): Q-Former의 출력(이미지/텍스트 특징)을 공통 임베딩 공간으로 투영하는 선형 레이어입니다.self.itm_head = nn.Linear(config.qformer_config.hidden_size, 2): 이미지-텍스트 매칭(ITM) 작업을 위한 이진 분류 헤드입니다. 2개의 출력은 이미지와 텍스트가 "관련 있음"과 "관련 없음"에 대한 로짓을 나타냅니다.
forward메서드:- 이미지 특징 추출:
self.vision_model(...)을 통해image_embeds를 얻습니다. use_image_text_matching_head분기: 이 플래그에 따라 ITM 또는 ITC가 적용됩니다.True인 경우 (Image-Text Matching, ITM):query_tokens와 텍스트input_ids의 임베딩을 결합하여 Q-Former의query_embeds로 사용합니다.- 이 결합된
query_embeds를encoder_hidden_states=image_embeds와 함께self.qformer(...)에 입력하여 Q-Former를 통과시킵니다. - Q-Former의 출력에서
query_tokens에 해당하는 부분(text_embeds[:, : query_tokens.size(1), :])을 추출한 후, 이진 분류 로짓(logits_per_image)을 계산합니다. 이 로짓은 해당 이미지-텍스트 쌍이 서로 관련 있는지 여부를 예측하는 데 사용됩니다.
False인 경우 (Image-Text Contrastive, ITC):query_tokens와image_embeds를self.qformer(...)에 입력하여 이미지 관련 쿼리 특징(image_embeds)을 얻습니다. 이 특징은self.vision_projection을 통해 정규화됩니다.- 텍스트
input_ids의 임베딩을self.qformer(...)에query_length=0으로 입력하여 텍스트 특징(question_embeds)을 얻습니다. 이 특징은self.text_projection을 통해 정규화됩니다. - 정규화된
image_embeds와text_embeds간의 코사인 유사도 점수(logits_per_image)를 계산합니다.
- 출력:
logits_per_image,logits_per_text,text_embeds,image_embeds
- 이미지 특징 추출:
- 중요성: BLIP-2가 이미지-텍스트 간의 의미적 정렬을 학습하는 데 사용되는 모델입니다. 특히 ITM과 ITC라는 두 가지 주요 멀티모달 표현 학습 기법을 어떻게 구현하고, 그에 필요한 유사도 점수나 분류 로짓을 어떻게 생성하는지 보여줍니다.
3️⃣ processing_blip_2.py
processing_blip_2.py 은 입력된 원시 데이터를 **modeling_blip_2.py가 만든 모델이 이해하고 처리할 수 있는 형태로 변환하는 역할을 담당**합니다.
processing_blip_2.py
├──── Kwargs Helper Class (인자 처리 헬퍼 클래스)
│ └──── class Blip2ProcessorKwargs (Processor의 kwargs 기본값 정의)
│
└──── Main Processor Class (메인 프로세서 클래스)
└──── class Blip2Processor (이미지 및 텍스트 입력을 모두 처리하는 핵심 클래스)
├──── def __init__ (초기화 메서드)
├──── def __call__ (이미지+텍스트 전처리)
├──── def batch_decode (토큰 ID -> 텍스트 변환)
├──── def decode (토큰 ID -> 텍스트 변환)
└──── def model_input_names (모델의 입력 이름 정의)🔷 각 class에 대한 설명
-
Blip2ProcessorKwargs:Blip2Processor의__call__메서드에 전달될 수 있는 다양한 인자(arguments)의 기본값을 정의하는 클래스입니다. -
Blip2Processor:BlipImageProcessor와AutoTokenizer를 하나의 인터페이스로 묶어, BLIP-2 모델의 입력 데이터를 전처리하는 역할을 수행합니다.
🔷 핵심 코드 정리
processing_blip_2.py파일에서 가장 중요한 부분만 간단하게 살펴보도록 하겠습니다.
🔻 __init__ 메서드
- 이 코드는
Blip2Processor가 시작될 때tokenizer에<image>라는 특수 토큰을 추가하는 역할을 합니다. - Tokenizer가 이미지를 의미하는
<image>토큰을 작성함으로써 사용자가 원하는 위치에 이미지를 놓는 soft prompting이 가능해집니다. - 실제로
<image>토큰 자리에 이미지 임베딩이 삽입됩니다.
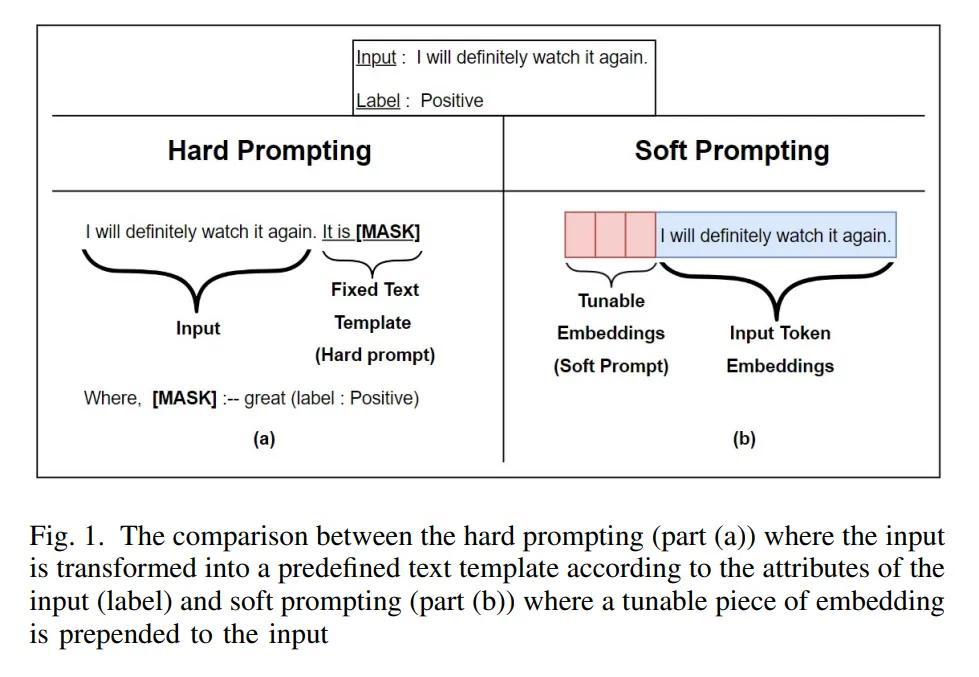
출처: https://arxiv.org/pdf/2212.02924
🔸 핵심 코드
class Blip2Processor(ProcessorMixin):
def __init__(self, image_processor, tokenizer, num_query_tokens=None, **kwargs):
# image_processor와 tokenizer를 직접 입력받는다.
# 학습된 모델을 가져올 때는 자동으로 입력된다.
#...
# 텍스트 입력에 이미지를 추가하기 위한 <image> 토큰 추가
# 일반적으로 tokenizer는 이미지를 다루지 않기 때문에 <image> 라는 토큰이 없다.
if not hasattr(tokenizer, "image_token"):
# tokenzier가 "image_token"아라는 속성이 없다면!
self.image_token = AddedToken("<image>", normalized=False, special=True)
# <image> 라는 토큰 객체를 만들고
tokenizer.add_tokens([self.image_token], special_tokens=True)
# <image> 토큰을 tokenizer에 추가합니다.
else:
self.image_token = tokenizer.image_token
# Q-Former의 쿼리 토큰 개수를 저장합니다.
self.num_query_tokens = num_query_tokens
# 상위 클래스 초기화
super().__init__(image_processor, tokenizer)4️⃣ __init__.py
__init__.py는 configuration_blip_2.py ,processing_blip_2.py, modeling_blip_2.py 파일들을 한 곳에 모아 깔끔하고 편리하게 불러올 수 있도록 창구 역할을 수행한다.
🔷 전체 코드
__init__.py는 github에 저장되어 있는 모듈을 효율적으로 import할 수 있도록 설계되었습니다.
from typing import TYPE_CHECKING
# 데이터 타입을 표시할 수 있는 라이브러리
# 👍라이브러리를 효율적으로 로딩하기 위한 장치
from ...utils import _LazyModule
# 실제로 실행되지 않은 파일은 로딩시키는 것을 지연시키는 도구
# modeling_blip_2.py 파일 속 class를 호출 시 modeling_blip_2.py만 실행
from ...utils.import_utils import define_import_structure
# 해당 파일의 class와 함수를 분석하여 로드맵을 만든다.
# 각 class와 함수가 어떤 파일에 있는지 이해한다.
if TYPE_CHECKING:
from .configuration_blip_2 import *
from .modeling_blip_2 import *
from .processing_blip_2 import *
else:
import sys
_file = globals()["__file__"]
sys.modules[__name__] = _LazyModule(__name__, _file, define_import_structure(_file), module_spec=__spec__)- 각 모듈의 역할은 주석에 작성된 바와 같습니다.
- 구체적인 구현 로직은 다음 기회에 다루도록 하겠습니다.
😥 내 생각
코드를 보다 보면 작은 하위 구조부터 조금씩 조금씩 결합하여 큰 모델을 구현하는 것을 확인할 수 있었다. 내가 AI 연구원이 되어 모델을 개발하려면 논문의 아이디어가 실제로 어떻게 구현되었는지, 거시적으로 또 미시적으로 이해해야한다고 생각한다. 그래서 코드를 살펴보고 있는데 이게 맞는 건가 하는 생각도 조금씩 든다.
오히려 읽기보다는 실제로 조금씩 만들어보는게 더 빠를 수도 있겠다는 생각이 든다. 그래도 너무 요령 피우지 말고 조금만 더 해보자. 아직은 부족한 것 같다.
