[Deep Reinforcement Learning] 15강 Temporal Difference Learning 3
[Deep Reinforcement Learning]
👨🏫학습목표
오늘은 Temporal Difference의 한계와 이를 극복하기 위한 시도에 대해 배워볼 예정이다.
👨🎓강의영상: https://www.youtube.com/watch?v=g7JnA_ArmOU&list=PLvbUC2Zh5oJtYXow4jawpZJ2xBel6vGhC&index=15
1️⃣ AB example

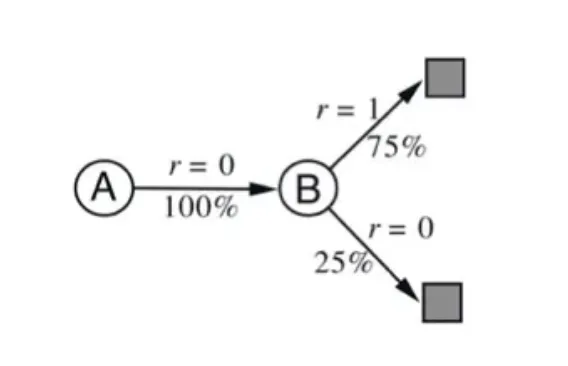
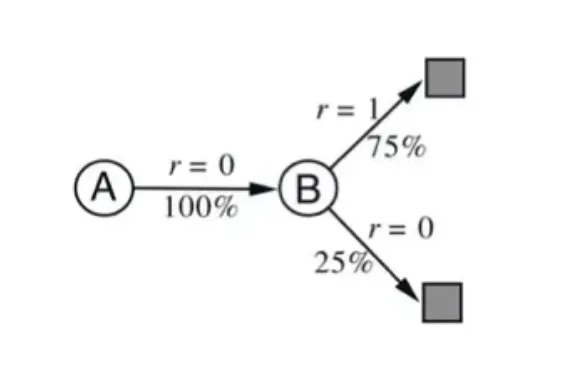
🔷 AB example
-
state A 에서 state B로 이동, 그리고 state B에서 terminal state로 이동한다.
-
현재 우리는 state transition probability를 알 수 없다.
-
state B에서 접근 가능한 terminal state의 reward는 각각 1과 0이라는 것을 확인할 수 있다.
-
sampling을 통해 8개의 episode를 구할 수 있다.
-
Initial state는 A, B 중 하나가 될 수 있다.
-
우리는 sample 데이터를 통해서 각 state의 value값, 를 구하려고 한다.
-
는 8개의 관측치 중 6번 1의 reward를 받고, 2번은 0의 reward를 받으므로 기대값이 0.75이다.
💡 를 구하는 방법
-
해당 state 이후에 얻게될 총 reward의 기대값을 통해 구한다.
-
의 경우 이후에 terminal state에 도착하기 때문에 한번의 reward만 계산하면 된다.
🔻 Temporal Difference
-
-
-
-
이므로 는 0.75에 수렴하게 될 것이다.
🔻 Monte Carlo
-
state 에서 시작하는 return값.
-
현재 sample data에는 밖에 없기 때문에 이 데이터를 통해 Return 를 구한다.
-
-
는 0에 수렴하게 될 것이다.
🔷 두 방식의 차이
-
현재 sample data에는 에서 시작하는 데이터가 하나이기 때문에 Monte Carlo 방식으로 평가 시 이 되었다.
-
그런데 상식적으로 생각해보면 에서 로의 이동은 100%이고, 이때의 Reward = 0이기 때문에 라고 추측할 수 있다.
-
따라서 이번 case에서는 Temporal Difference가 더 정확하다고 판단할 수 있다.
-
Monte Carlo는 주어진 데이터를 더 잘 적합되는 특징이 있다. 즉 데이터에 민감하다.
2️⃣ Cliff walking을 통한 비교
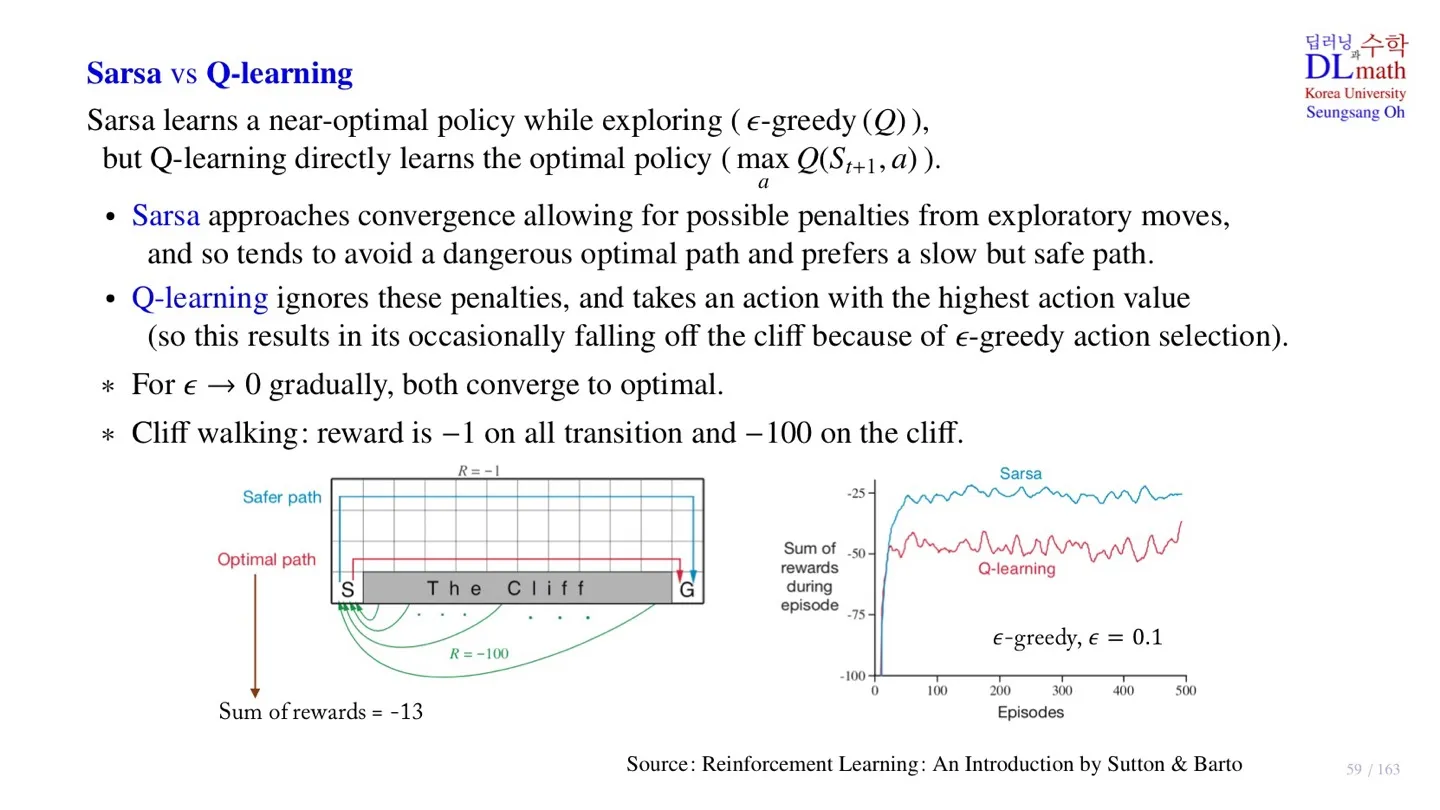
🔷 Cliff walking
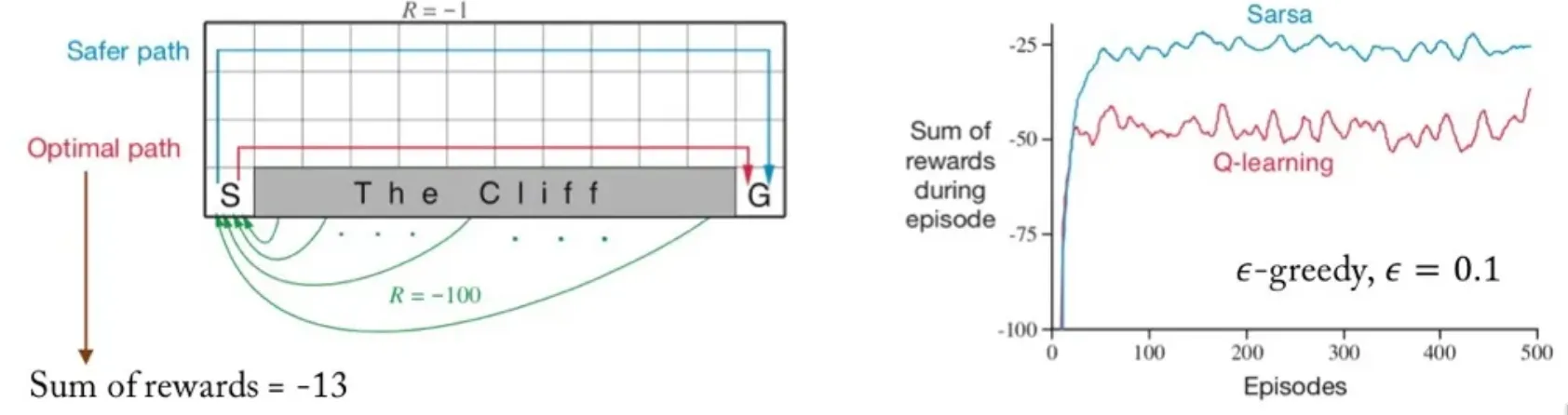
-
모든 small negative reward = -1이다.
-
The Cliff에 접근할 경우 -100의 Reward를 받는다.
-
Cliff walking에서는 Sarsa가 Q-learning보다 더 좋은 성능을 보인다.
🔷 Sarsa
-
-greedy 방식을 통해 Action 을 선택한다.
-
Target policy = Behavior policy
-
Sarsa는 머리 속으로 생각하는 방식(Target policy)으로 실제 행동(Behavior policy)을 수행한다.
-
Cliff 근처에 있으면 만큼 위험할 수 있기 때문에 돌아가려 한다.
-
탐험을 할 때 risk를 고려하면 행동한다.
🔷 Q-learning
-
Optimal action 를 통해 업데이트를 진행한다.
-
Target policy ≠ Behavior policy
-
Q-learning는 머리 속으로 생각하는 방식(Target policy)과 다르게 실제 행동(Behavior policy)을 수행한다.
-
머리속을 optimal한 경우만 생각하기 때문에 Cliff에 빠질 것을 염두하고 있지 않다.
-
Optimal한 경우만 고려하기 때문에 penalty를 고려하지 않는다.
🤔 그럼 Sarsa가 더 좋은 방식인가?
- 일반적으로는 강화학습에서 Q-learning이 Sarsa보다 더 좋은 성능을 보인다.
3️⃣ Expected Sarsa

🔷 Expected Sarsa
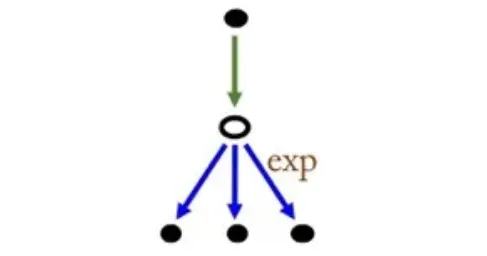
-
기대값 를 target으로 업데이트를 진행한다.
-
기대값을 사용하기 때문에 모든 policy 를 고려하는 것이다.
-
Sarsa보다는 일반적으로 더 좋은 성능을 보이지만, 계산 비용이 증가하였다.
4️⃣ Double Q-learning

🔷 Q-learning의 한계
-
업데이터를 진행할 때 항상 maximization operation을 진행한다.
-
이는 에 대한 과대평가로 이어진다.
-
도달해야 하는 target값이 더 크기 때문에 convergence 역시 느려진다.
🔷 Double Q-learning
-
Q-learning의 한계를 극복하기 위해 2개의 Q-value function을 사용한다.
-
2개의 Q-value table 를 만든다.
-
에서의 optimal한 action으로 의 Q-value를 사용한다.
-
에서는 optimal한 값이더라도 에서는 아닐 수 있다.
-
이러한 방식을 통해 Q-value값이 너무 커지고 또 overestimate되는 것을 막는다.
-
With 0.5 probability: 를 통해 모두 골고루 업데이트될 수 있도록 한다.
5️⃣ TD()

🔷 n-step return
-
n-step의 sample data를 통해 업데이트를 진행하고 싶을 때 사용한다.
-
n-step에 대한 Reward와 이후에는 state value function을 통해 계산한다.
-
Temporal Difference와 Monte Carlo의 중간이라고 생각하면 된다.
🔷 TD(n)
-
n-step을 통해 얻은 return 를 통해 업데이트를 진행한다.
-
하지만 n번째 경우만 고려한다는 한계가 있다.
🔷 TD()
- n-step sample data를 수집한 후 모든 step의 return을 구한다.
🔻 -return
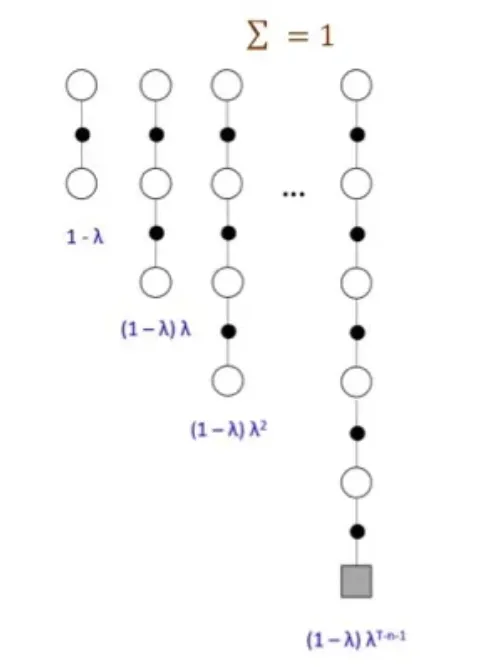
-
값이 0에 가까울수록 가까운 미래의 value가 중요하다.
-
빼고는 모두 0이 되어 Temporal Difference가 된다.
-
모든 가 고려되어 Monte Carlo와 유사해진다.
6️⃣ 정리
🔷 15강에서 배운 내용은 아래와 같다.
- AB example을 통해 Monte Carlo와 Temporal Difference 방식을 비교하였다.
- Cliff walking을 통해 Sarsa와 Q-learning 방식을 비교하였다.
- Sarsa의 sample data만 고려한다는 한계를 극복한 Expected Sarsa에 대해 배웠다.
- Q-learning의 overestimate 한계를 극복하기 위한 Double Q-learning을 배웠다.
- n-step의 sample data를 다룰 수 있는 TD()에 대해 배웠다.
