
💬CoT-VLA: Visual Chain-of-Thought Reasoning for Vision-Language-Action Models
🔗 논문: https://arxiv.org/pdf/2503.22020
🧐 학회: CVPR 2025
✏️ 논문 정리
1. 이 논문을 읽는 이유가 무엇인가요?
⇒ 이미지를 이용한 CoT 과정이 궁금하여 찾아보게 되었다.
2. 논문 제목의 의미는 무엇인가요?
⇒ Visual CoT 기법을 사용하여 Visual Language Action 모델에 적용하였다는 의미이다.
3. 논문의 등장배경은 무엇인가요?
⇒ 기존의 VLA는 중간 추론 단계 없이 작동한다는 한계가 있었다.
4. 논문을 1~2줄로 요약하세요
⇒ CoT-VLA는 Visual CoT와 Action Chunking, Hybrid Attention을 통해 기존 VLA 성능을 넘어섰다. Visual CoT를 학습하는 과정은 Action 라벨이 없는 비디오 데이터만으로 학습 가능하기에 많은 양의 비디오 데이터 활용 방안을 제시했다는 의의가 있다.
0️⃣ Abstract
🔷 VLA(Vision-Language-Action) 상황
-
VLA 모델은 사전 학습된 VLM(Vision-Language-Models)과 다양한 로봇 데모를 활용하여 엄청난 잠재력을 보여주고 있다.
-
하지만 현재 직접적인 입력-출력 구조이다 보니, 중간 추론 단계가 부족하다.
🔷 논문의 핵심 아이디어, Visual Chain of Thought reasoning
- 이에 따라 논문에서는 중간 추론 단계로 시각적 목표 이미지를 생성하는 Visual Chain of Thought reasoning을 제안한다.
🔷 논문에서 제안한 모델 CoT-VLA
-
논문에서는 시각적 그리고 행동 token을 이해할 수 있는 7B-VLA를 제안한다.
-
CoT-VLA는 기존 SoTA 모델보다 조작 작업에서 17%, 시뮬레이션 벤치마크에서 6% 나은 성능을 보인다.
1️⃣ Introduction
🔷 1. 기존 Robot 연구
-
현재 Robot Leanring은 빠르게 발전하고 있다.
-
그 중에서도 사전 학습된 VLM과 Robot을 연결한 구조에 대한 기대가 크다.
-
하지만 관찰(입력된 정보)과 행동(모델의 출력)이 직접적으로 매핑되어 중간 추론 과정이 없다는 한계가 존재한다.
🔷 2. 논문의 제안
-
이러한 한계를 극복하기 위해 Visual Chain of Thought reasoning을 제안한다.
-
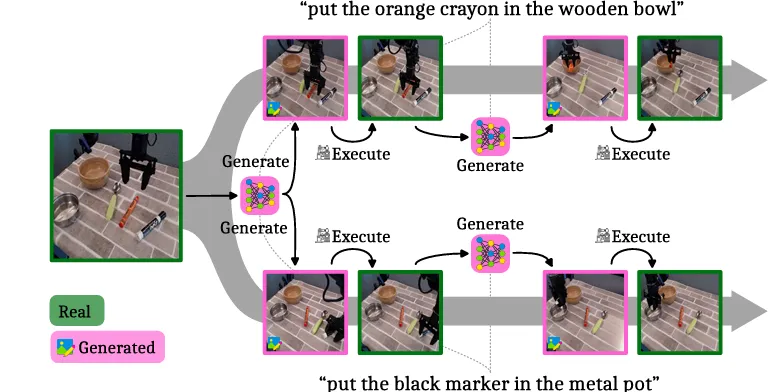
Visual Chain of Thought reasoning은 모델이 행동하기 전 자신의 행동 결과를 이미지로 먼저 생각한 후, 그에 따라 행동할 수 있도록 중간 추론 과정을 수행하는 방법이다.
🔷 3. Visual Chain of Thought reasoning
-
1 단계 : 모델이 목표 상태를 픽셀 이미지로 생성한다.
-
2단계 : 관찰(입력된 정보)과 생성된 이미지를 토대로 Action을 결정한다.
-
말 그대로 think visually이다.
🔷 4. Visual CoT의 장점
-
보통 로봇 Action 데이터에도 이미지가 함께 사용되기 때문에, 추가 전처리 과정이 필요하지 않다.
-
이미지 생성 과정에 행동에 대한 텍스트 설명이 필요 없기 때문에 다양한 비디오 데이터를 활용할 수 있다.
🔷 5. CoT-VLA
-
CoT-VLA는 hybrid attention과 action chunking 방식을 사용한다.
-
Hybrid attention : 텍스트와 이미지 데이터를 처리할 때는 causal attention을, action을 예측할 때는 full attention(양방향)을 사용한다.
-
Action Chunking : 모델이 action을 예측할 때는 action 하나하나를 순차적으로 예측하지 않고, action sequence를 한번에 예측한다.
🔷 6. 논문의 기여
-
Visual CoT를 Robot Control에 접목하였다.
-
Hybrid attention과 Action Chunking을 적용한 CoT-VLA를 개발하였다.
-
다양한 Robot Task에서 SoTA를 달성하였다.
2️⃣ Related work
2장에서는 CoT-VLA를 이루는 CoT와 VLA에 대해 설명한 후, CoT-VLA의 차별점에 대해 설명합니다.
🔷 1. Chain of Thought Reasoning
🔻 1-1. CoT의 등장
-
CoT는 Task를 여러 단계로 분해하여, 모델이 복잡한 문제를 처리할 수 있도록 한다.
-
자연어처리 분야에서 처음으로 뛰어난 성능을 보였다.
🔻 1-2. Visual 영역으로의 확장
-
Visual 영역에서는 이미지 정보를 단계별로 처리하는 방식으로 사용되었다.
-
예를 들어 이미지에 대한 설명을 생성하기 전, Bbox 좌표를 출력한 후 이를 참고하여 대답하도록 할 수 있다.
-
또 이미지 생성 시 CLIP Embedding을 중간에 조건부로 넣어 이미지를 생성하도록 할 수 있다.
🔻 1-3. Embodied 영역으로 확장
-
최근에는 로봇 분야로 CoT가 확장되었다.
-
모델 실행, 점 추적, Bbox, 미래 이미지 궤적 등을 텍스트 계획으로 생성하도록 한다.
🔻 1-4. 논문의 Visual CoT reasoning
-
Visual CoT reasoning는 로봇 조작의 중간 추론 단계에 이미지를 생성하여 사용하도록 한다.
-
이 방식은 추가 텍스트 설명이 필요없어 비디오 데모를 활용할 수 있다는 장점이 있다.
🔷 2. Vision Language Action Models
🔻 2-1. VLM의 활용
-
현재 사전 학습된 VLM을 활용하여 로봇 시스템을 구축하는데 많은 연구가 있다.
-
이들은 VLM의 지각능력, 높은 이해력, 추론 능력을 활용하여, 복잡한 문제 분해, 물체 감지, 강화학습에서의 reward와 goal를 생성한다.
🔻 2-2. VLM을 Backbone으로 End to end 학습
-
VLM을 활용하는 방식 중에는 VLM 모델을 Backbone으로 사용하여 action을 예측하도록 파인튜닝할 수 있다.
-
해당 방식은 뛰어난 성능을 보였지만, 단계별 추론 능력을 사용하지 않는다는 한계가 존재한다.
-
물론 예전에 로봇 분야에서 특정 좌표나 Bbox를 활용한 CoT reasoning이 있었습니다.
🔻 2-3. CoT-VLA
- 논문에서는 Subgoal images를 중간 추론 단계에 활용한 CoT를 통해 이러한 한계를 극복한다.
3️⃣ CoT-VLA
3장에서는 Visual Chain of Thought reasoning과 CoT-VLA에 대해 설명한다.
🔷 1. Visual Chain of Thought Reasoning
🔻 1-1. 사용 데이터
-
Robot demo dataset 텍스트 지시, Action 시퀀스, 시각적 관찰 시퀀스로 구성되어 있다.
-
Robot demo dataset은 텍스트 지시와 이미지를 토대로 Action을 예측하도록 학습하는데 사용된다.
-
Action less videos 텍스트 설명과 이미지로 구성되어 있다.
-
Action less videos는 텍스트와 이미지로만 이루어져 있어, 중간 이미지를 예측하는 과정을 학습할 때 사용된다.
🔻 1-2. VLA 수학적 표현
-
텍스트 입력(지시사항)
-
로봇이 관찰한 이미지
-
로봇이 수행할 Action
-
사전 학습된 VLM 모델
-
VLA는 텍스트 입력과 관찰한 이미지를 토대로 어떤 행동을 수행할지 결정하도록 학습한다.
🔻 1-3. CoT-VLA 수학적 표현
🔶 1. 중간 이미지 생성
-
모델은 입력 텍스트 와 관측한 이미지 를 통해 시점 이후의 자신의 행동을 이미지 로 생성한다.
-
이 과정은 Robot demo dataset 과 Action less videos 를 통해 학습한다.
🔶 2. 중간 이미지를 활용한 행동 예측
-
모델은 입력 텍스트 와 관측한 이미지 그리고 시점 이후의 자신의 행동 이미지 를 통해 앞으로의 일련의 행동을 동시에 예측한다.
-
이 과정은 Robot demo dataset 을 통해 학습한다.
🔷 2. The Base Vision Language Model
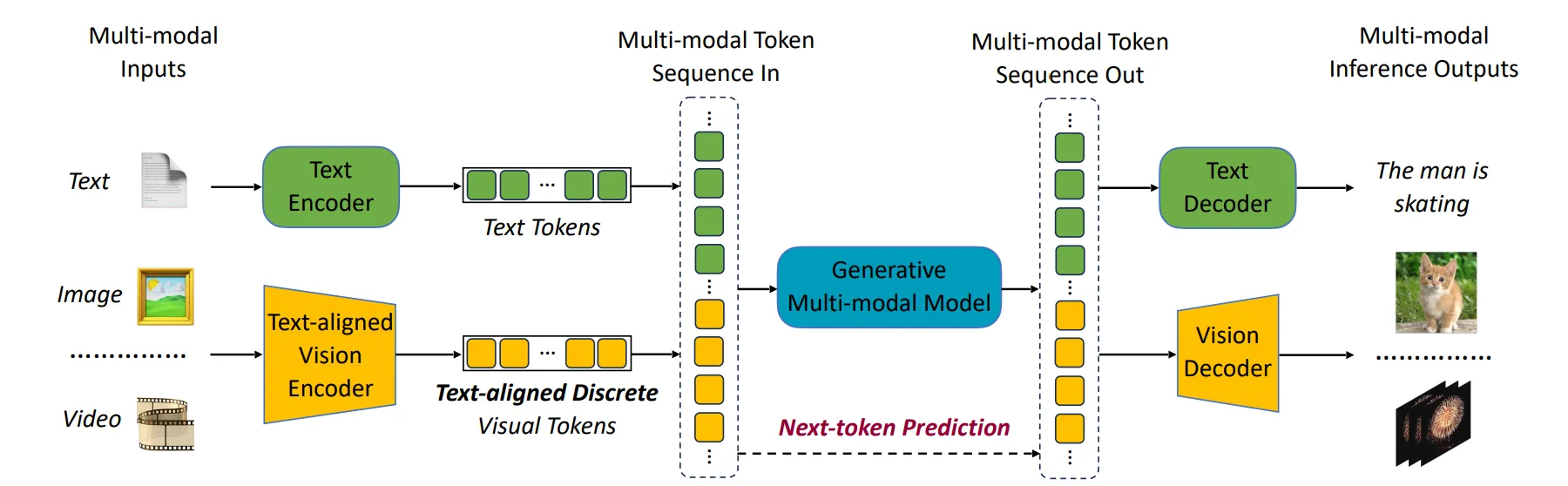
🔻 2-1. 사용 모델
-
VILA-U (a Unified foundation model that integrates Video, Image, Language understanding and generation)
-
VILA-U는 시각-언어 이해와 생성을 동시에 수행할 수 있는 모델이다.
-
VLA에서 텍스트, 이미지에 대한 이해와, 중간 추론 단계에 사용될 이미지를 생성할 수 있어야 하기 때문에 VILA-U를 선택하였다.
📃 VILA-U 논문 : VILA-U: A UNIFIED FOUNDATION MODEL INTEGRATING VISUAL UNDERSTANDING AND GENERATION
🔻 2-2. VILA-U의 특징
-
VILA-U는 이미지와 텍스트 생성을 위해 사용될 토큰을 모두 Autoregressive하게 생성한다.
-
이미지 임베딩은 Residual Quantization을 이용하여 discrete visual Tokens로 만든다.
-
이미지 디코더는 여러 벡터로 양자화된 Discrete Visual Tokens을 통해 더 디테일한 이미지 생성이 가능하다.
-
Residual Quantization에 대해서는 향후에 한번 다뤄보겠다.
📃 관련 논문 : Autoregressive Image Generation using Residual Quantization
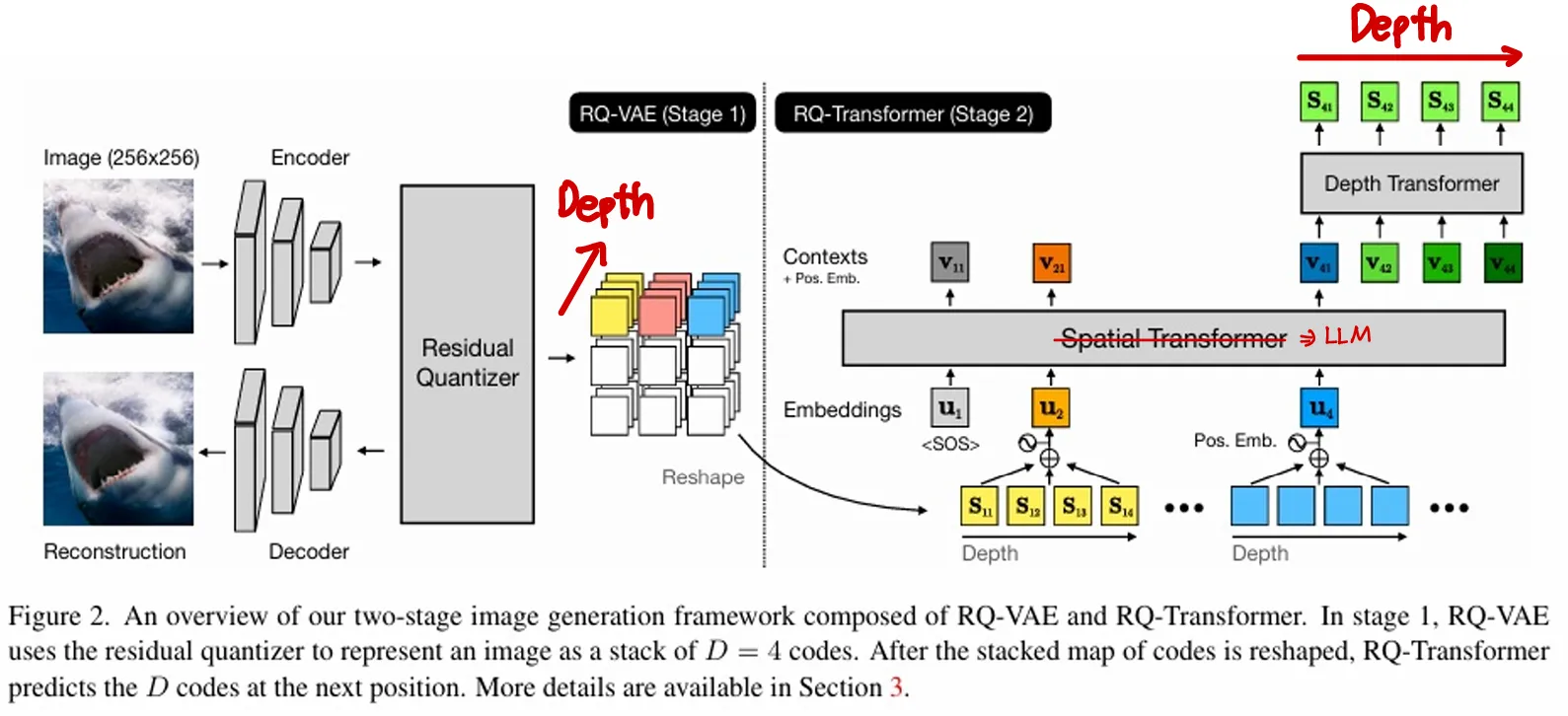
🔷 3. Training Procedures
🔻 3-1. 학습 모듈
-
LLM Backbone : 텍스트, 이미지, Action을 모두 Autoregressive하게 생성하는 언어 모델이다.
-
Projector : 텍스트 임베딩을 이미지 차원에 맞게 조정한다.
-
Depth Transformer : LLM Backbone을 통해 출력된 이미지 토큰을 입력으로 받아 양자화한다.
📃 관련 논문 : Autoregressive Image Generation using Residual Quantization
📃 관련 논문 : VILA-U: A UNIFIED FOUNDATION MODEL INTEGRATING VISUAL UNDERSTANDING AND GENERATION
🔻 3-2. Visual Tokens Prediction
-
학습 대상 : Depth Transformer
-
학습 목표 : Subgoal image 생성을 잘 할 수 있도록 학습
-
학습 프로세스 : 텍스트 설명과 현재 관찰 이미지를 입력으로 하며, step 이후의 이미지를 정답으로 제공한다.
-
번째 토큰의 번째 양자화된 벡터
-
번째 토큰의 첫 번째부터 번째까지의 양자화된 벡터
-
두 개의 시그마를 통해 각 토큰과 각 토큰을 이루는 양자화된 벡터를 모두 Autoregressive하게 예측하도록 학습한다.
📃 출처 : Autoregressive Image Generation using Residual Quantization
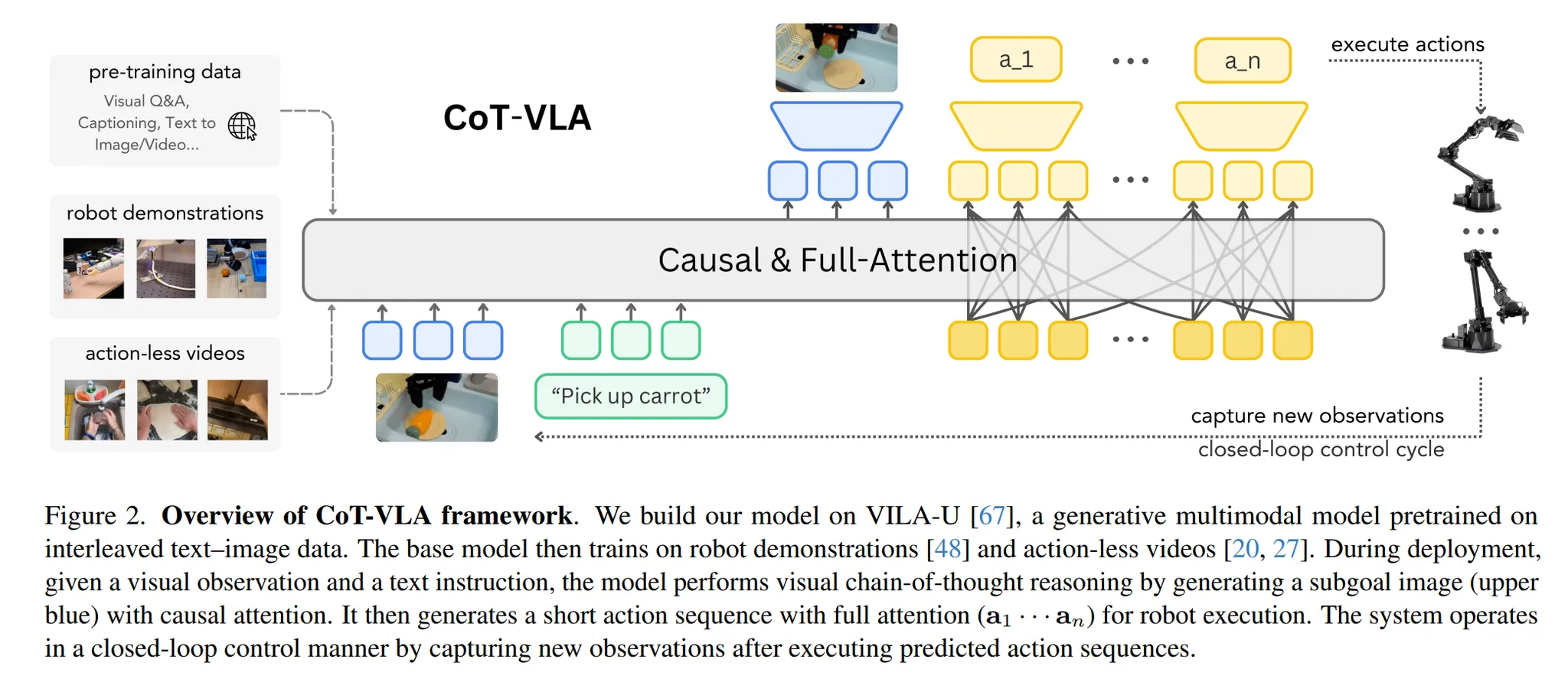
🔻 3-3. Action Tokens Prediction
-
예측된 이미지를 참고하여 모델의 Action을 예측한다.
-
하나의 action은 총 7개의 토큰으로 표현된다.
-
각 토큰은 256개의 구간 중 하나의 토큰ID를 가지게 된다. ⇒ Action Space가 Discrete하다는 의미!
-
예를 들어 팔의 각도를 %로 표현할 때, 각 토큰이 256가지 구간 중 하나의 값으로 결정되는 것이다.
-
각 action 토큰은 full-attention을 통해 서로의 action을 고려하여 결정된다.
- 사용자의 지시와 현재 관측 장면, n시점 이후의 관측 장면을 토대로 이후 일련의 action을 동시에 예측한다.
🔶 최종 Loss function
-
모델이 Subgoal Image를 잘 생성하도록 설계된 Loss
-
모델이 목표에 맞는 Action을 잘 생성할 수 있도록 설계된 Loss
🔻 3-4. Pretraining Phase
- CoT-VLA를 Pretraining하는 단계이다.
🔶 Robot demonstrations
-
Open X-Embodiment dataset을 사용한다.
-
데이터셋에서 3인칭 시점, 팔과 집게로 구성된 데이터셋을 사용하였다.
-
Action은 t시점을 포함하여 10개의 시점을 동시에 예측하도록 학습한다.
🔶 Action less videos
-
EPIC-KITCHENS와 Something-Something V2 데이터셋을 사용하였다.
-
Subgoal Image는 사이의 시점을 random하게 예측하도록 학습한다.
-
EPIC-KETCHENS : 부엌에서 요리하는 1인칭 시점 영상

- Something-Something V2 : 다양한 사물 조작 영상

- 두 데이터 모두 각 영상마다 간단한 텍스트 설명을 포함하고 있다. ⇒ 학습 시 입력 텍스트(지시사항)으로 사용된다.
🔻 3-5. Adaptation Phase for Downstream Closed-Loop Deployment
-
시전 학습된 모델을 특정 Task에 파인튜닝하는 단계이다.
-
원하는 Task에 해당하는 Robot demonstration data 을 통해 파인튜닝을 진행한다.
-
파인튜닝 대상은 LLM Backbone, Projector, Depth Transformer이다. ⇒ Action 생성과 연관된 모듈
-
Closed-Loop는 로봇이 어떤 행동을 한 후, 그 행동 결과를 관찰하여 다음 행동을 결정하는 과정의 반복을 의미한다.
🔶 CoT-VLA 작동 Pseudo code

4️⃣ Experiments
4장에서는 시뮬레이션 벤치마크와 실제 세상에서 로봇 조작 Task를 대상으로 실험을 수행한다.
🔷 0. Experiment는 아래의 3가지 질문을 중심으로 진행되었다.
- CoT-VLA가 기존의 SoTA 모델과 비교하여 어느 정도 성능을 보이는가?
- CoT-VLA의 Visual chain of Thought reasoning과 hybrid attention이 Task 성능에 어느 정도 영향을 미치는가?
- 모델의 이미지 추론 능력 향상이 얼마나 Action 예측 성능을 향상시키는가?
🔷 1. Experimental Setup
🔻 1-1. LIBERO
-
LIBERO : 로봇 학습을 위한 시뮬레이션 벤치마크 (가상환경)

출처: LIBERO simulation benchmark [25] task suites. We study VLA fine-tuning... | Download Scientific Diagram
-
평가 목표 : 모델의 공간관계(Spatial), 객체 상호작용(Object), 목표 달성(Goal), 긴 길이 Task(Long) 성능
-
각 평가 항목에 10개의 작업을 제공한다.
🔻 1-2. Bridge-V2
-
Bridge-V2 : 실제 로봇팔 데이터셋 (실제 환경)
-
WidowX 로봇팔을 사용하여 Experiment를 진행하였다.

- 평가 목표 : 시각적 이해 능력, 동작 능력, 지시 이해 능력, 지시 수행 능력
🔻 1-3. Granka-Tabletop Real-Robot Experimets
-
Franka Emika Panda 로봇팔을 사용하여 Experiment를 진행하였다.
-
평가 목표 : 모델의 새로운 환경에서의 적응 능력
-
CoT-VLA가 사전 학습 단계에서 보지 못한 새로운 환경이다.
🔻 1-4. Baselines
-
CoT-VLA와 비교하기 위해 4가지 SoTA baseline를 사용한다.
-
Diffusion Policy : 노이즈 제거 방식으로 로봇의 Action을 학습 및 추론하는 모델
-
OpenVLA : 사전 학습된 VLM 모델을 OpenX(로봇 데이터)로 파인튜닝한 모델
-
Octo : OpenX만으로 학습된 Transformer 기반 모델
-
SUSIE : 이미지 생성(Subgoal Image) 모델과 Action 추론 모델을 결합한 모델
📃 관련 논문 : ZERO-SHOT ROBOTIC MANIPULATION WITH PRETRAINED IMAGE-EDITING DIFFUSION MODELS
🔷 2. Evaluations Results
🔻 2-1. LIBERO
-
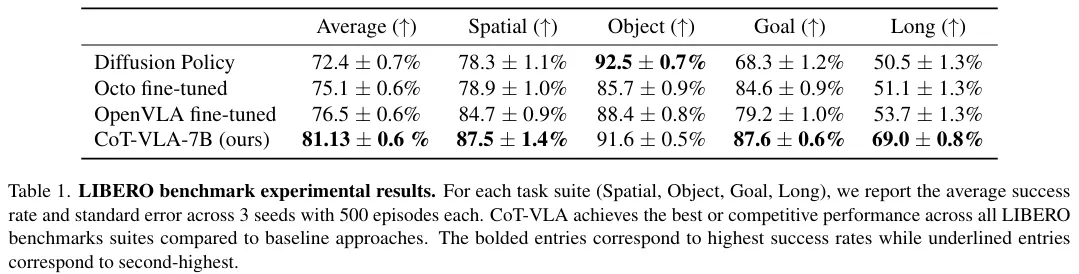
각 Task마다 500 Trials를 진행하였고, 성공률은 평균과 표준편차가 함께 제공된다.
-
해당 실험 진행 후 실패사례를 분석하였을 때, Baseline 모델이 이미지 입력에 과적합되는 현상을 관측할 수 있었다.
-
예를 들어, 입력 이미지와 Task1을 지시했는데, 이미지가 Task2와 유사하다면 Task1 지시를 무시하고 Task2를 수행하는 것이다.
-
CoT-VLA는 사용자의 Instruction에 따라 Subgoal Image를 생성하여 사용자의 지시를 잘 따르는 모습을 보였다.
🔻 2-2. Bridge-V2
-
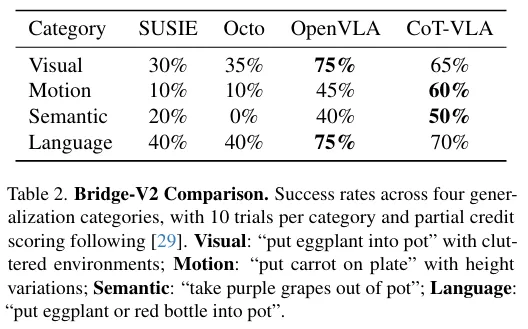
4가지 Task에 대한 실험을 수행하였다.
-
실험 결과 SUSIE는 좋은 이미지를 생성하였지만, 낮은 성능을 보였다.
-
CoT-VLA는 Visual과 Language 영역에서 OpenVLA보다 낮은 성능을 보였는데, 이는 시각 추론 능력이 아니라 Action Chunking에서 문제가 있는 것을 관찰된다.
-
위에 대해서는 5장에서 다뤄보도록 하겠다.
-
하지만 CoT-VLA는 전반적으로 다른 모델에 비해 뛰어난 성능을 발휘함을 확인할 수 있다.
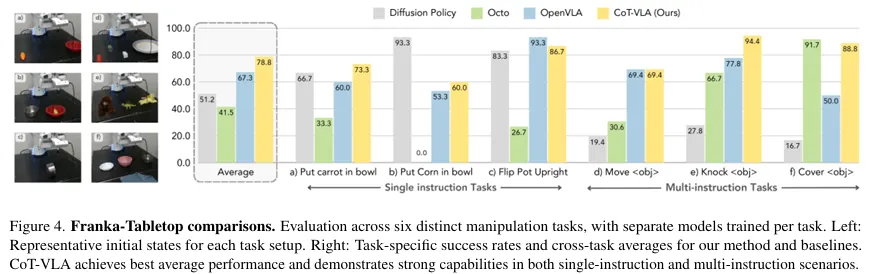
🔻 2-3. Franka-Tabletop
-
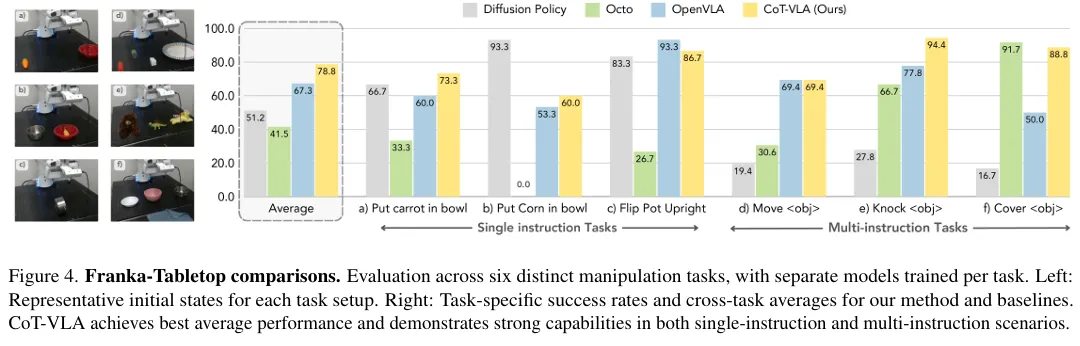
Figure 4를 보면 CoT-VLA가 평균적으로 좋은 성능을 발휘함을 확인할 수 있다.
-
실험 결과 Diffusion Policy는 Multi-instruction Task에서 낮은 성능을 발휘함을 확인할 수 있다.
-
개인적으로는 Diffusion Policy의 구조가 텍스트 데이터를 학습하지 않도록 설계되어 있어서 텍스트 이해력이 떨어진다고 생각한다.
-
논문에서는 실험을 위해 텍스트 데이터를 DistilBERT를 통해 임베딩 한 후 입력되는 구조로 설계하여 파인튜닝하였다고 작성되어 있다.
🔶 Diffusion Policy 모델 구조
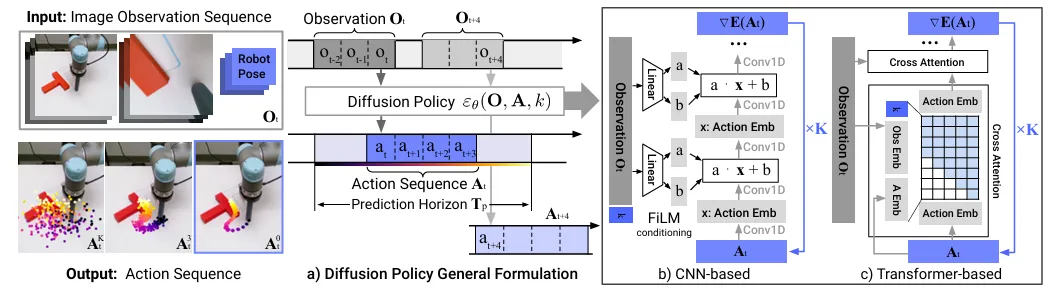
📃 관련 논문 : Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
🔷 3. Ablation Study
🔻 3-1. 핵심 모듈의 기여
| Case | VILA-U Backbone | Action Chunking | Hybrid Attention | Visual CoT Reasoning |
|---|---|---|---|---|
| Case1 (VILA-U Backbone) | O | X | X | X |
| Case2 (+Action Chunking) | O | O | X | X |
| Case3 (+Hybrid Attention) | O | O | O | X |
| Case4 (CoT-VLA) | O | O | O | O |
-
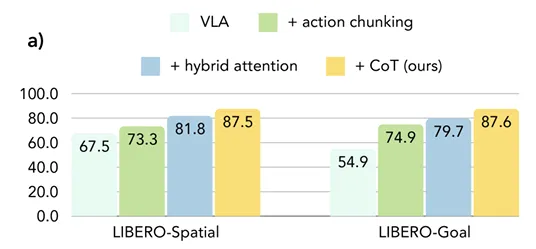
Ablation Study에서는 CoT-VLA의 핵심 요소 Action Chunking, Hybrid Attention, Visual CoT Reasoning이 실제 성능 개선에 도움이 되었는지 확인한다.
-
Figure6 a)를 보면 각 기능을 추가하였을 때 성능이 점점 개선된 것을 확인할 수 있다.
🔻 Pretraining의 효과

-
논문에서는 CoT-VLA를 다른 Downstream Task를 학습하기 전 사전 학습하는 것이 성능 개선에 도움이 되는지 확인한다.
-
Figure 6 b)를 보면 사전 학습을 하였을 경우 78.8%로 더 높은 성능을 발휘하는 것을 확인할 수 있다.
🔷 4. Better Visual Reasoning Helps

-
논문에서는 중간 추론 과정에 더 좋은 이미지를 제공할 경우 모델의 성능에 도움이 되는지 확인한다.
-
Experiment는 모델이 직접 생성한 이미지, 학습 시 정답이라고 생각한 이미지를 추론 과정에 활용하도록 설계하였다.
-
Table 3에 따르면 중간 추론 과정에 정답이라고 생각한 이미지를 제공하였을 경우 더 좋은 성능을 발휘함을 확인할 수 있다.
-
이는 중간 추론 과정에 더 좋은 이미지를 제공할수록 모델의 성능이 개선된다는 것을 알 수 있다.
🤔 생각해볼 점
현재 성능 차이는 모델이 생성한 이미지의 내용 때문일까? 아니면 이미지의 퀄리티에 따른 차이일까?
실험을 진행할 때, 이미지 대신 Ground-Truth에 해당하는 이미지의 캡션이나 Bbox 를 텍스트로 제공하는 실험을 통해, 중간 추론 과정에서 텍스트 정보와 이미지 정보의 성능 차이를 비교하는 내용을 추가했으면 좋았을 것 같다.
5️⃣ Conclusion, Limitations and Future Work
5장에서는 논문의 기여와 한계점, 미래 방향에 대해 설명한다.
🔷 1. 논문의 기여
-
논문에서는 Vision-Language-Action Model과 Visual CoT Reasoning을 결합하여 다양한 로봇 Task에 적용 가능한 CoT-VLA를 개발하였다.
-
Visual CoT를 통해 중간 추론 과정을 명확하게 구현하였다.
-
CoT 과정에 이미지를 제공하여 추론과정에 더 좋은 데이터를 제공한다.
-
Subgoal Image 생성 학습에 Video 데이터를 활용할 수 있다.
🔷 2. 한계점
-
중간 추론 과정에서 이미지를 생성하기 때문에 많은 계산량을 요구한다.
-
이미지를 Autoregressive하게 생성하기 때문에 Diffusion 방식에 비해 이미지의 퀄리티가 떨어진다.
-
Action Chunking 방식을 이용할 경우, Action 중간 중간에 피드백을 제공할 수 없고, Action이 불연속적인 경우가 발생한다.
-
비디오 데이터로 학습 시 연산 능력 제한이 모델의 성능을 제한한다.
🔷 3. 미래 방향
-
향후 성능이 향상된 비디오 생성 모델이나 시뮬레이션 모델(World Model)을 통해 비디오 데이터를 활용하여 더 높은 일반화 능력을 달성할 것이라 기대한다.
📃 관련 논문 : Video as the New Language for Real-World Decision Makin
📃 관련 논문 : Pandora: Towards General World Model with Natural Language Actions and Video States
6️⃣ 논문을 읽은 후..
이번 논문은 이미지 CoT를 통해 로봇의 Action 능력을 개선한다는 점에서 굉장히 흥미로웠다. 인간의 생각 사슬이 텍스트로만 이루어지지 않은 것처럼, AI 모델 역시 이미지를 통한 CoT를 통해 성능을 개선할 수 있다고 생각한다. 물리 엔진이나 비디오 생성은 과거의 상황을 토대로 미래를 예측하는 프로세스일 것이다. 이 과정을 원하는 방향으로 제어하여 비디오를 생성할 수 있도록 한다면 Visual CoT 영역에 큰 발전이 이루어질 것이라 생각한다. 물론 AI 모델의 비디오 이해 능력 역시 수반되어야 한다.
