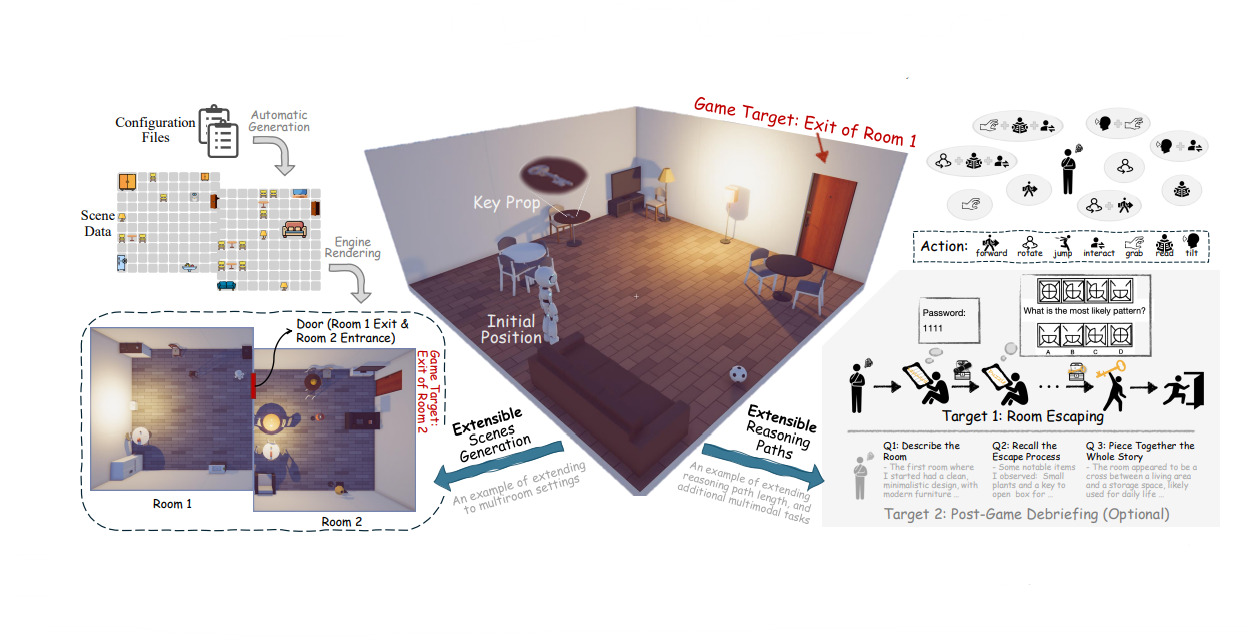
🗝️EscapeCraft: A 3D Room Escape Environment for Benchmarking Complex Multimodal Reasoning Ability
🔗 논문: https://arxiv.org/abs/2503.10042
💻 GitHub : EscapeCraft: A 3D Room Escape Environment for Benchmarking Complex Multimodal Reasoning Ability
🧐 학회: ICCV 2025
✏️ 논문 정리
1. 이 논문을 읽는 이유가 무엇인가요?
⇒ EscapeBench를 읽은 후 관련 논문을 조금 더 찾아보다가 읽기로 결정하였다. 이번 논문에서는 실제로 3D 이미지가 들어간다고 하니 이미지 정보를 어떤 방식으로 처리하여 데이터를 수집하고, EscapeBench와 도구를 사용하는 방식에서는 어떻게 다른지 비교하며 읽어보려고 한다.
2. 논문 제목의 의미는 무엇인가요?
⇒ 복잡한 멀티모달 추론 능력을 평가하기 위한 3D 방탈출 구축 프레임워크 EscapeCraft를 사용한다. 이를 통해 벤치마크 MM-Escape를 구축하였다.
3. 논문의 등장배경은 무엇인가요?
⇒ 기존의 멀티모달 벤치마크는 모델의 종합적인 추론 능력과 중간 추론 과정에 대한 평가가 부족하였다.
4. 논문을 1~2줄로 요약하세요
⇒ MM-Escape는 3D 방탈출 환경을 구축하고 사용자가 이를 커스터마이징하여 모델이 자율적으로 환경을 탐색할 수 있고, 중간 추론 과정을 평가할 수 있는 평가 지표를 만들었다. MM-Escape는 모델이 방 탈출 후 탈출 과정을 재구성하도록 하여 모델의 장기 기억 능력과 탈출 과정에 대한 종합적인 이해 능력을 평가한다.
0️⃣ Abstract
🔷 논문을 작성하게 된 배경
-
멀티모달 분야가 발전하는 것에 비해 멀티모달 모델 평가 방식에 부족한 점이 있다.
-
현재 평가 방식은 모델의 중간 동작 과정보다는 최종 결과에만 집중한다.
-
또한 평가 자체를 물체를 찾거나, 질문에 대답하는 등 모델의 제한적인 능력만 평가한다는 한계가 있다. 즉 종합적 평가가 부족하다.
🔷 논문의 제안사항, MM-Escape
-
논문에서는 방탈출 환경 벤치마크, MM-Escape를 구축하여 위의 한계를 극복하려 한다.
-
MM-Escape에서는 모델의 최종 작업 외에도, 모델의 중간 행동 과정에도 집중한다.
🔷 논문의 실험 결과
-
대부분의 MLLM 모델들이 간단한 방탈출 문제는 쉽게 해결하였지만, 난이도가 증가할수록 성능이 급격하게 떨어지는 현상을 관찰할 수 있었다.
-
모델들이 실패한 행동을 반복하는 현상을 관찰할 수 있었다.
-
모델들이 주어진 도구를 효율적으로 사용하지 못하는 현상을 관찰할 수 있었다.
-
모델의 시각 인지 능력이 부족하여, 모델이 구석에 갇히는 현상을 관찰할 수 있었다.
1️⃣ Introduction
🔷 멀티모달 모델 평가의 한계점
-
기존의 평가는 이미지 캡셔닝이나 시각적 정보 파악(Visual Grounding)과 같은 특정 작업을 목표로 하여 멀티모달 모델의 자율적인 탐색 필요성을 제한한다.
-
실제 세상에서는 복잡한 목표와 환경이 존재하지만, 현재 최종 목표만을 평가하는 방식을 사용하여 모델의 중간 추론 과정에 대한 분석이 부족하다.
-
또한 일부 Task는 추론 과정을 표준화한 라이브러리를 제공하여, 모델이 자율적으로 탐색하는 과정을 막는다.
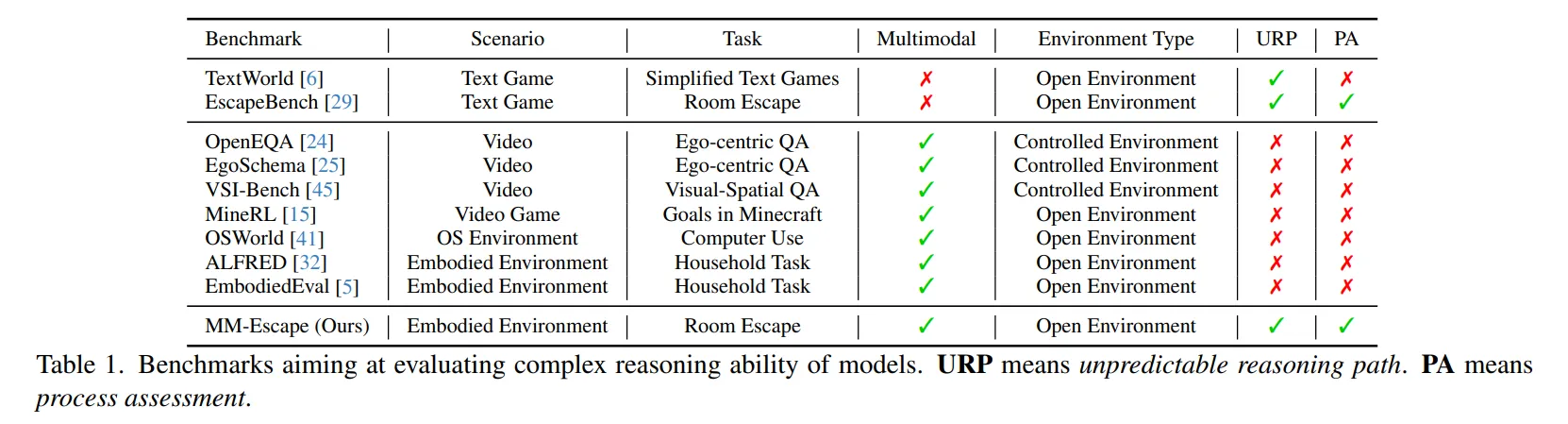
- Table 1을 보면 많은 BenchMark들이 예측할 수 없는 환경을 구축하거나 중간 동작 과정 평가가 부족하다는 것을 확인할 수 있다.
⭐ 정리하면 자율적이고 개방적인 환경에서 모델의 시각, 공간, 논리 능력 그리고 중간과정까지 종합적으로 평가하는 벤치마크가 필요한 상황이다.
We argue that in open multimodal environment, including real-world settings and virtual simulators, complex multimodal reasoning should not be solely assessed by task completion results or isolated tasks
- 논문 내용 발췌 -
🔷 논문의 아이디어, MM-Escape
-
MM-Escape는 방탈출 환경에서 영감을 받아 제작되었다.
-
MM-Escape는 모델의 자유로운 탐색을 가능하게 하여, 멀티모달 추론 능력을 포괄적으로 평가할 수 있도록 한다.
-
MM-Escape는 모델의 최종 결과 뿐만 아니라 중간 행동에도 집중한다.
-
MM-Escape의 가장 어려운 단계에서는 모델이 탈출 후, 탈출 과정을 회상하여 수집된 단서를 통해 스토리를 재구성할 수 있도록 한다.
🔷 논문의 실험 결과
-
논문에서는 MM-Escape를 사용하여 모델 행동을 분석하고, 모델의 전반적인 한계를 파악하였다.
-
GPT-4o나 Gemini-1.5-Pro와 같은 모델도 인간과 비교하면 상호작용 성공률이 절반으로 줄어들고, 필요한 step 역시 2배나 줄어들었다.
-
게임 난이도가 증가할수록 모델의 성능이 급격하게 떨어지는 것을 확인할 수 있다.
-
각 모델들은 서로 다른 실패 요인을 보이는 것을 관찰할 수 있었다.
2️⃣ Related Work
2장에서는 기존 연구의 한계점을 설명하며, MM-Escape의 필요성에 대해 설명한다.
🔷 1. Complex Reasoning Abilities of MLLM
🔻 1-1. MLLM의 연구방향
-
최근 MLLM 분야는 단순히 이미지 캡셔닝을 넘어 더욱 복잡하고, 현실 세계에 적용 가능한 Task를 해결할 수 있도록 연구되고 있다.
-
컴퓨터나 휴대폰과 같은 디지털 기기 조작, 비디오 게임 조작, 로봇 조작 등이 대표적인 예시이다.
-
이러한 복합적인 Task는 다양한 해결책이 존재하며, 모델이 자율적으로 탐색하고 환경과 상호작용하는 능력이 필요해지고 있다.
🔻 1-2. 기존 멀티모달 추론 능력 평가의 한계
-
기존 평가 방식은 모델이 환경과 상호작용하기 보다, 미리 정해진 경로를 따라가야 하는 방식이다.
-
기존 평가 방식은 모델이 정해진 가이드라인을 통해 행동하기 때문에 모델의 자율성이 떨어진다는 한계가 존재한다.
-
정해진 목표를 달성하였는지에 관한 평가만 이루어지며, 모델이 개방된 세계를 탐색하는 것에 대한 평가가 없다.
🔻 1-3. MM-Escape의 특징
-
모델이 환경과 상호작용할 수 있도록 설계되었다.
-
환경을 유연하게 설정하여 모델이 목표를 달성하기 위해 외부 지식에 의존하는 것을 막을 수 있다. → 모델이 자율적으로 탐색할 수 있도록 한다.
-
추론 과정과 최종 결과를 모두 평가한다.
🔷 2. EscapeBench와 같은 텍스트 월드 환경 저격
EscapeBench 논문에 대한 내용은 아래의 글에서 확인할 수 있습니다.
📃 논문리뷰 : [논문리뷰] EscapeBench: Towards Advancing Creative Intelligence of Language Model Agents
🔻 2-1. 텍스트로 구축된 벤치마크, TextWorld, EscapeBench
-
기존에 멀티모달 모델의 추론능력을 평가하기 위해 텍스트로 구축된 벤치마크가 있었다.
-
하지만 순수 텍스트 환경만으로는 멀티모달 모델의 추론 능력을 제대로 평가할 수는 없다.
-
텍스트 환경에서는 모델이 주변 환경을 관찰하기 위해 회전 각도나 이동 거리를 결정할 기회가 없다.
-
따라서 논문에서는 이러한 한계를 극복하기 위해 EscapeCraft를 제안한다.
3️⃣ MM-Escape
3장에서는 방 탈출 환경 구축을 돕는 EscapeCraft와 이를 통해 만들어진 벤치마크 MM-Escape에 대해 설명한다.
🔷 1. Task Definition
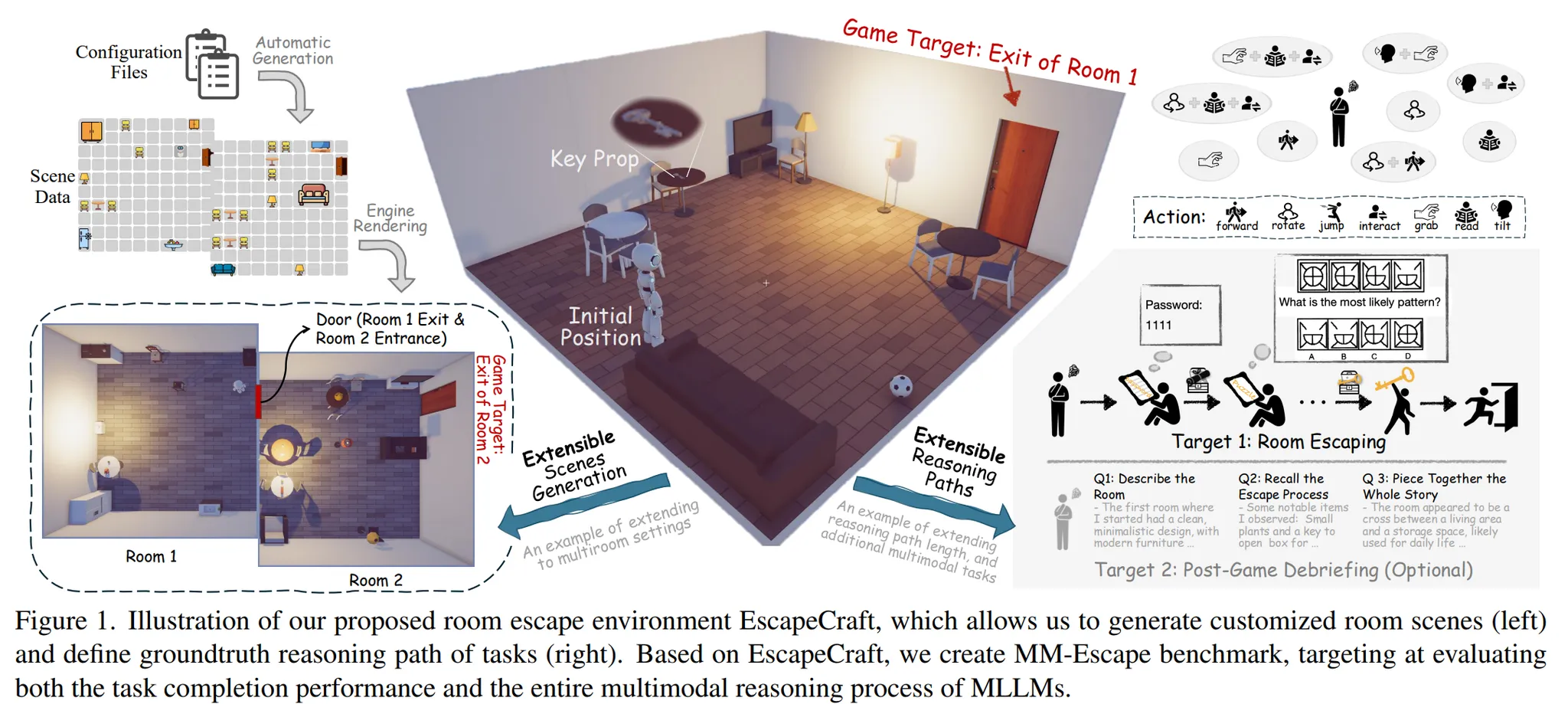
EscapeCraft에는 2가지 목표가 주어진다. 첫 번째는 방을 탈출해야 한다는 메인 목표이다. 다른 하나는 모델이 방을 탈출하였을 경우, 방을 탈출하는 과정을 스토리로 재구성하는 것이다.
-
Target 1에서는 모델이 방을 나가는 것을 목표로 한다.
-
Target 2에서는 모델이 게임 진행 과정을 재구성하는 것을 목표로 한다.
🔻 1-1. Room Escaping Task
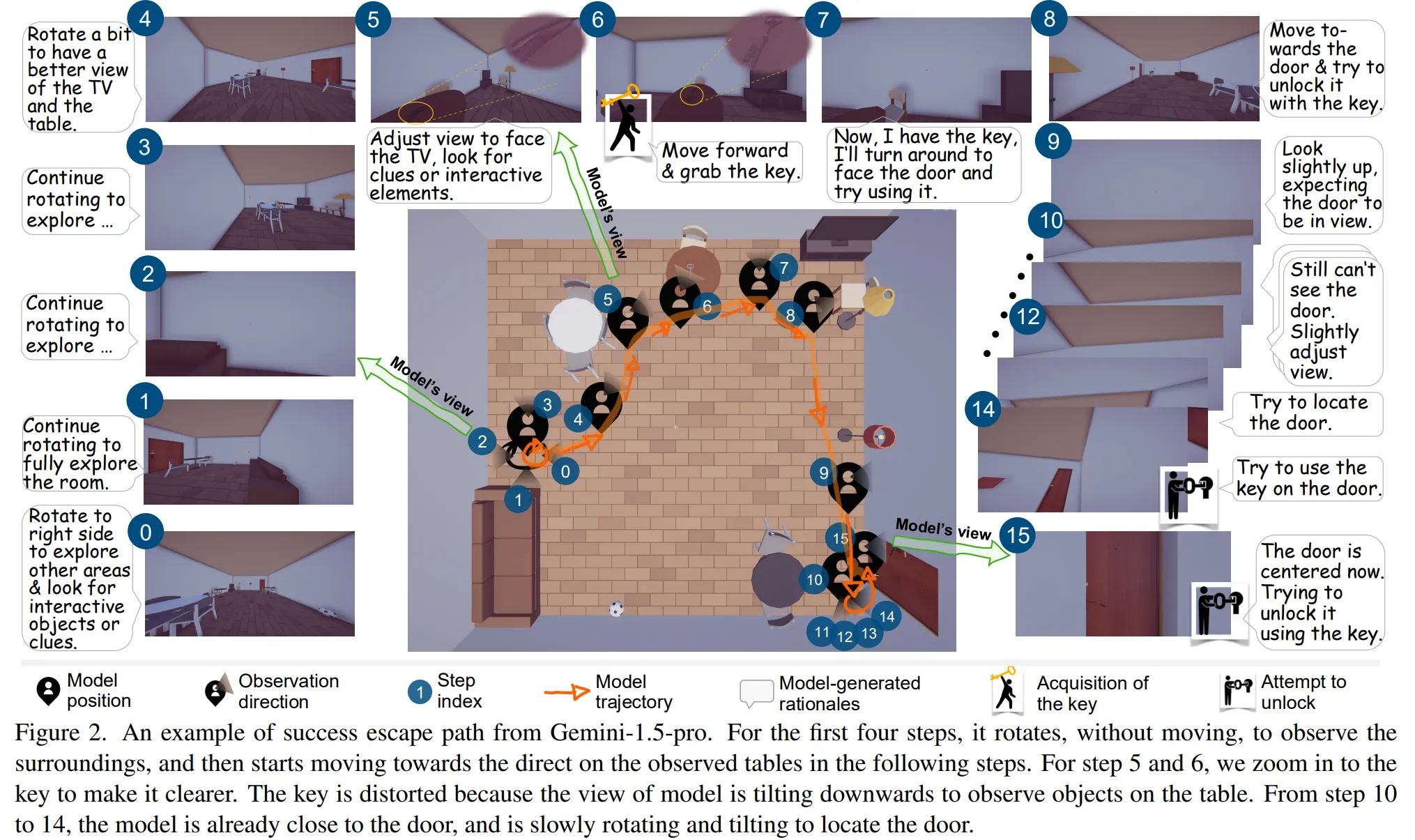
-
Figure 2에서 확인할 수 있듯이 모델은 주변 환경을 관찰하고, 주변 소품과 단서를 통해 문을 해제한다.
-
Figure 2에 대한 설명을 한번 읽어보면 이해하기 쉽다.
-
Room Escaping Task를 통해 모델의 객체 인식, 시각적 탐색, 목표 추론, 공간 추론, 소품활용 등 종합적인 멀티모달 추론 능력을 평가할 수 있다.
🔻 1-2. Post-Game Debriefing Task
-
Post-Game Debriefing은 모델이 방 탈출을 마친 후 진행된다.
-
모델이 방 탈출 과정에서는 탈출 자체에 집중하도록 하기 위함이다.

-
Post-Game Debrieging Task를 통해 모델의 기억력과 재구성 능력을 평가할 수 있다.
-
평가에서는 내용의 일관성과 논리성를 집중적으로 살펴본다.
🔷 2. Construction and Design of Environment
EscapeCraft는 자유로운 탐색 환경을 구축하였으며, 사용자가 공간을 확장하고 커스터마이징 할 수 있다.
🔻 2-1. Room Scene Generation
-
3D 방 탈출 공간을 구축하기 위해 ProcTHOR과 LEGENT를 활용하여 EscapeCraft를 개발하였다.
-
ProcTHOR : 3D 방을 만들 수 있는 프레임워크

📃 관련논문 : ProcTHOR: Large-Scale Embodied AI Using Procedural Generation
-
LEGENT : 3D환경에서 AI 에이전트의 행동을 훈련하고 평가하는 플랫폼

📃 관련논문 : LEGENT: Open Platform for Embodied Agents
-
-
EscapeCraft에서는 방의 수, 방의 크기, 가구를 사용자가 커스터마이징 할 수 있다.
-
Task를 수행하는 데 사용되는 중요한 도구나 단서는 모델이 상호작용할 수 있도록 설계하였다.
🔻 2-2. Action Space
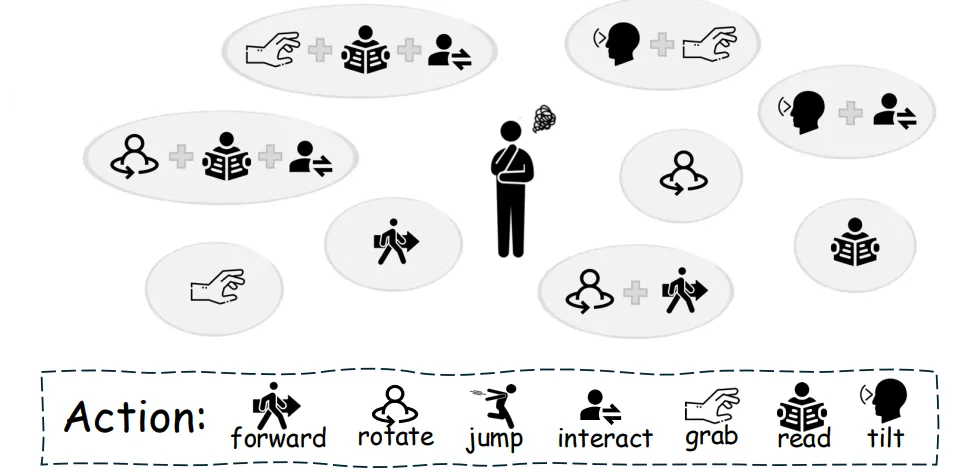
-
모델의 Action은 이동, 시야 조정, 상호작용 3가지로 구분된다.
-
이동은 모델이 다른 거리에서 객체를 인식할 수 있도록 말 그대로 위치를 이동할 수 있는 것이다.
-
시야 조정은 수평 또는 수직 회전과 같이 모델이 주변 환경을 쉽게 인식할 수 있도록 하는 행동이다.
-
상호작용에는 잡기, 사용하기, 읽기, 입력하기 행동이 있다.
-
모델은 상호작용을 통해 도구를 수집하거나 활용할 수 있다.
-
Action은 여러 행동을 동시에 수행할 수 있다.
🔻 2-3. Inventory system
-
Inventory system은 모델이 수집한 도구를 저장하고 관리할 수 있도록 한다.
-
모델은 수집한 도구의 설명을 살펴볼 수 있고, 활용할 수 있다.
-
Inventory system을 통해 모델이 도구를 사용하여 방을 성공적으로 탈출할 수 있도록 한다.
🔷 3. MM-Escape Benchmark
🔻 Prop Chain
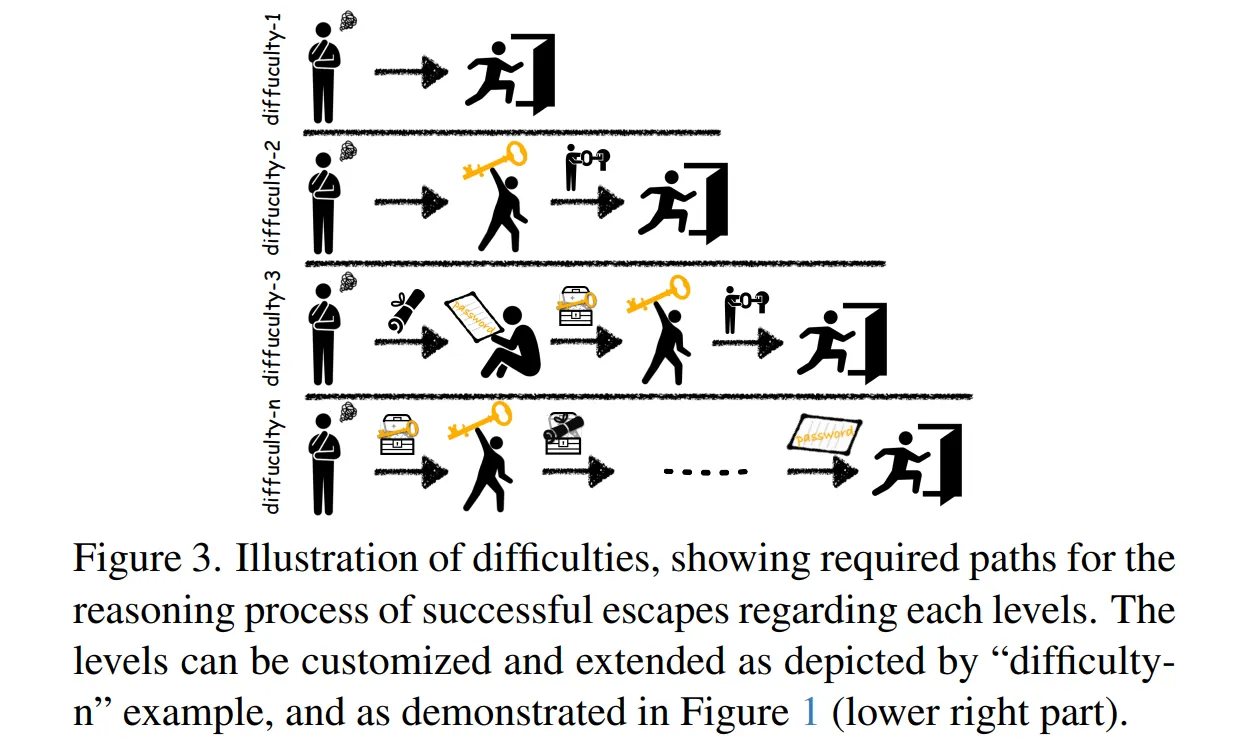
-
방 탈출 스토리를 완료하는 과정에 필요한 아이템과 상호작용 순서를 나타낸 연결리스트이다.
-
노드(Node) : 노드는 열쇠, 잠긴 상자, 출구와 같은 상호작용 요소가 들어간다.
-
링크(Link) : 노드 사이에는 아이템을 얻는 방법, 사용 방법 등이 정의된다.
-
게임의 난이도는 Prop Chain의 길이가 길어질수록 높아진다.
-
Figure 3이 Prop Chian 자체를 의미하는 것은 아니다.
🔻 게임 난이도
-
Difficulty-1 (1-hop) : 문을 여는데 소품이 필요없는 경우
-
Difficulty-2 (2-hop) : 문을 여는데 열쇠 또는 비밀번호가 필요한 경우
-
Difficulty-3 (3-hop) : 문을 여는데 열쇠와 비밀번호가 모두 필요한 경우
-
게임 난이도는 hop의 수가 늘어날수록 높아진다.
-
작업자는 단계 속 질문이나 작업 유형을 정의하여 게임을 난이도를 유연하게 조정할 수 있다.
🔻 Multi-Room
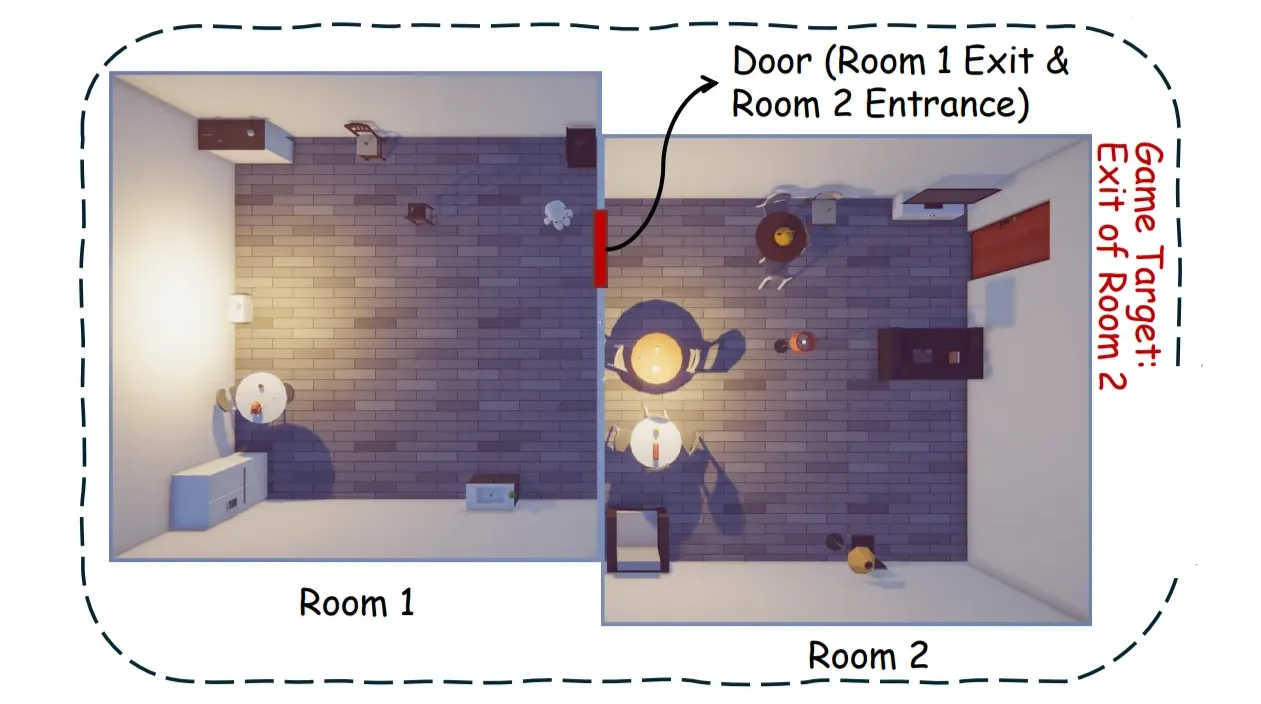
-
작업자는 모델의 능력을 평가하기 위해 방을 연결할 수 있다.
-
모델이 첫 번째 방을 탈출하면 두 번째 방으로 이동하는 방식이다.
-
두 번째 방에서는 입구와 출구를 구분해야 하기 때문에 난이도가 올라간다.
🔻 MM-Escape의 평가 지표
멀티모달 추론 능력을 평가하기 위해 최종 목표 외에도 중간 과정에 대한 평가 지표를 제안한다.
🔶 방 탈출 평가
- Escape Rate(ER) : 평균 탈출률
🔶 중간 과정 평가 지표
-
Average Step : 게임을 완료하는데까지 필요한 Step의 평균
-
Grab Count : Grab(잡기) 수행 횟수
- Prop Gain : 전체 도구에서 수집한 도구의 비율
- GSR(Grab Success Rate) : Grab(잡기) 성공 비율
- 전체 Step 중 Grab(잡기) 수행 비율
🤔 왜 중간 평가 지표에는 Grab이 많을까?
- 모델의 상호작용 Action에는 Grabbing(잡기), Using(사용하기), Reading(읽기), Inputting(입력하기)가 있다.
- 이때 모델이 환경과 상호작용 하기 위해서는 도구를 수집하는 것이 우선시되어야 한다고 생각해서 평가 지표에서 Grabbing에 집중한 것 같다.
- 개인적으로는 Using 역시 모델이 환경과 상호작용하는데 중요한 Action이라고 생각한다.
- 다만 Using을 늘리는 것이 단순히 무분별하게 도구 사용하는 것은 아닌지 구분해야 한다고 생각한다.
- 또 학습 초기에는 Using이 많더라도 점차 불필요한 Using을 줄여나가는 방식으로 학습이 가능하다면 이 역시 모델의 문제 해결 능력을 기르는데 도움이 된다고 생각한다.
🔻 Post-Game Debriefing 평가
-
모델의 재구성 평가는 언어모델을 사용하여 0~1 사이의 값으로 평가한다.
-
언어 모델은 멀티모달 모델이 재구성한 내용과 정답 경로와의 일관성을 중심으로 평가한다.
4️⃣ Experiments
4장에서는 MM-Escape를 이용하여 다양한 멀티모달 모델의 성능을 평가한다.
🔷 평가 설정
-
게임 크기가 무한이 커질 수 있기 때문에 생성 가능한 Step의 수는 난이도 별로 50, 75, 100으로 제한한다.
-
Multi Room 게임의 경우 최대 Step 수를 80으로 한다.
🔷 평가 모델
-
MM-Escape를 수행하기 위해서는 모델이 긴 Context를 입력으로 받을 수 있어야 한다.
-
따라서 입력 가능 길이가 128K 이상인 모델만 실험에 사용하였다.
-
위 표에 나와 있는 모델을 사용하여 실험을 수행하였다.
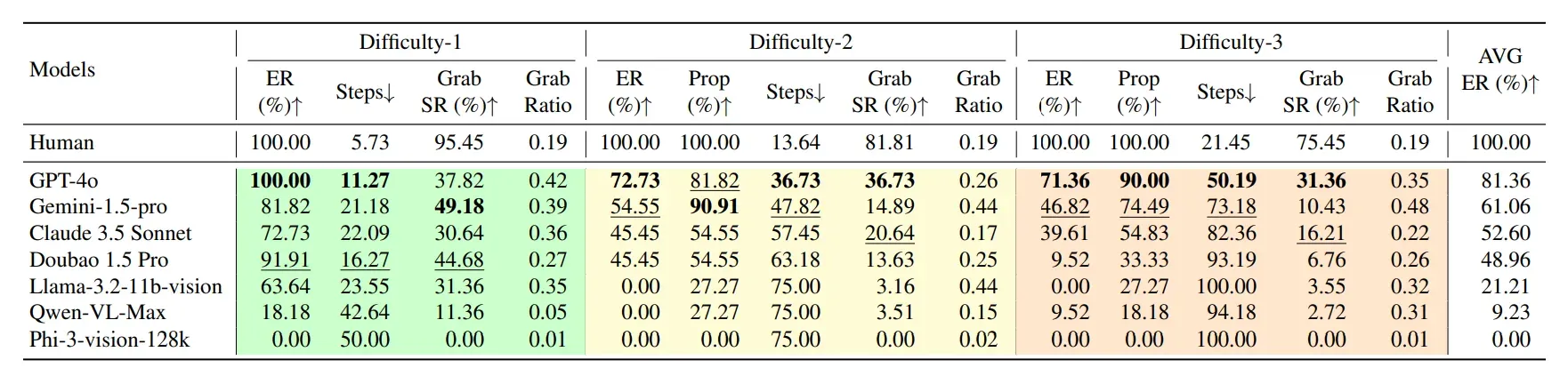
🔷 평가 결과
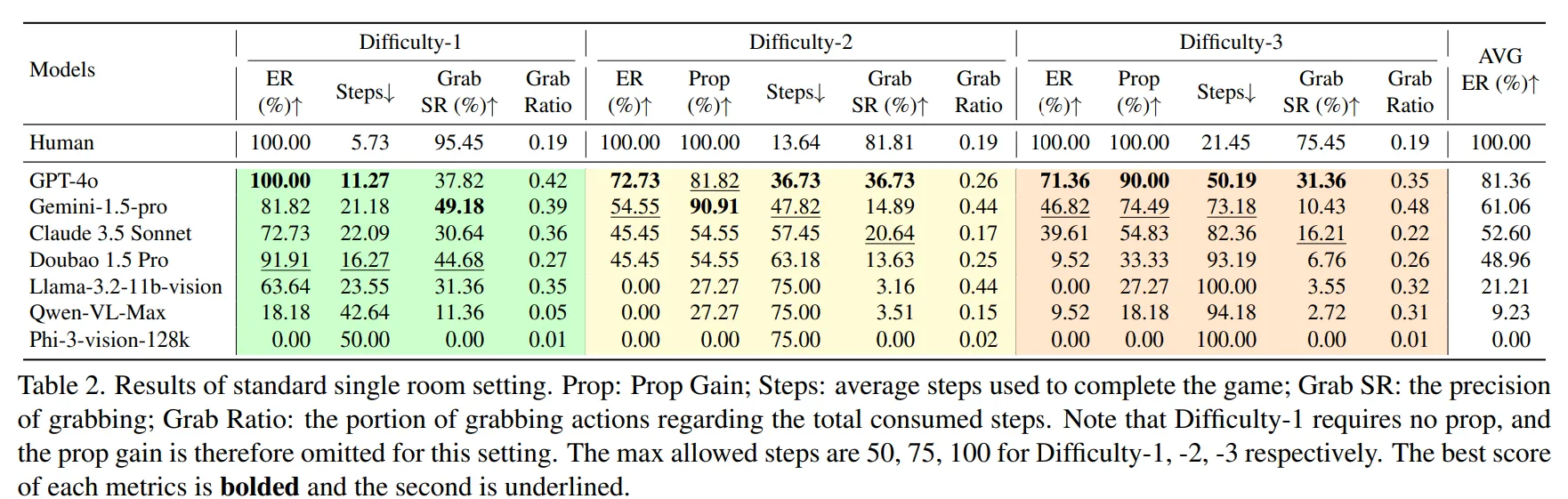
🔻 방 탈출 평가
-
모든 모델이 인간보다는 떨어지는 결과를 보였다.
-
모델 중에서는 GPT-4o가 평균 81.36%의 탈출률을 보였고, Gemini가 61.06%로 그 뒤를 이었다.
🔻 중간 과정 평가
-
GPT-4o는 적은 수의 Steps로 효율적으로 Task를 완료한 것을 확인할 수 있다.
-
Difficulty-2에서 Prop(%)을 통해 Gemini는 GPT-4o보다 탈출률은 낮지만, 더 높은 시각적 탐색 능력을 보였다.
-
Difficulty-2에서 Claude와 Doubao 모두 동일한 Prop Grain을 확인할 수 있다.
-
이때 GRS와 Grab Ratio을 통해 Claude는 조금 더 시각적 도구 이해 능력이 높고, Llama는 더 많은 도구를 찾기 위해 Grab을 많이 사용하는 방법을 사용한다고 생각할 수 있다.
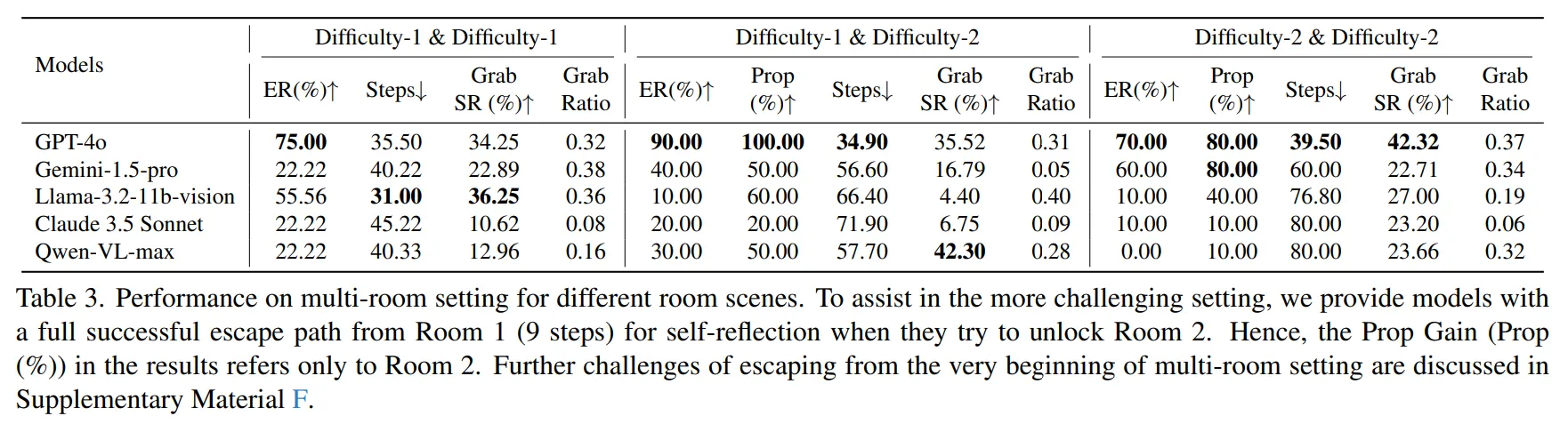
-
이러한 모델별 다른 행동 양상은 Multi-Room 실험에서도 유사하게 관찰할 수 있었다.
-
GPT-4의 경우 Difficult-1을 탈출한 경우 Difficulty-2에서 방 탈출률이 90%로 증가한 것을 확인할 수 있다.
-
Gemini와 Llama는 Single-Room에 비해 Difficulty-2 & Difficulty-2에서 Prop Gain이 증가한 것을 확인할 수 있다.
5️⃣ Analysis and Discussions
5장에서는 실험 결과에 대한 다양한 정량적, 정성적 분석 결과를 설명한다.
🔷 0. 모델별 행동 패턴
🔻 행동 패턴
-
Gemini는 시작 지점에서 시선의 각도를 움직여 주변 환경을 탐색하는 경향을 보였다.
-
GPT-4o는 넓은 환경을 관찰하여, 먼저 환경에 대한 전반적인 이해를 먼저 하였다.
🔻 관찰 전략
-
Gemini는 책상, 의자를 관찰하기 위해 아래로 시선을 옮겼다.
-
GPT-4o는 주로 정면 시선을 통해 관찰하였다.
🔻 실패 지점
-
Gemini는 방 구석에 갇히는 현상이 많았다.
-
GPT-4o는 반복적인 행동을 하는 경향을 보였다.
🔷 1. Analysis of Entire Path
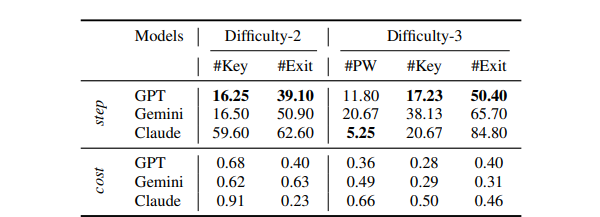
🔻 1-1. 도구 획득에 어느 정도 Step이 필요한가?
-
GPT-4o가 도구를 획득하는데 16.25 Step으로 가장 빠른 것을 확인할 수 있다.
-
Difficulty-3에서 Claude는 Key를 5.25 Step만에 획득하였지만 탈출하는 데는 오래 걸렸다.
🔻 1-2. 핵심 도구를 획득한 이후 탈출까지 어느 정도의 Step이 필요한가?
-
Difficulty-2에서는 Gemini가 GPT-4o보다 더 적은 Cost로 도구를 발견하였지만, Difficulty-3에서는 GPT-4o가 더 적은 Cost로 도구를 찾는 것을 확인할 수 있다.
-
GPT-4o가 방 환경의 기억과 이해를 활용하여 더 나은 성능을 보인다고 논문에서 말한다.
🔻 1-3. GRS(Grab Success Rate)와 탈출에는 연관성이 있는가?
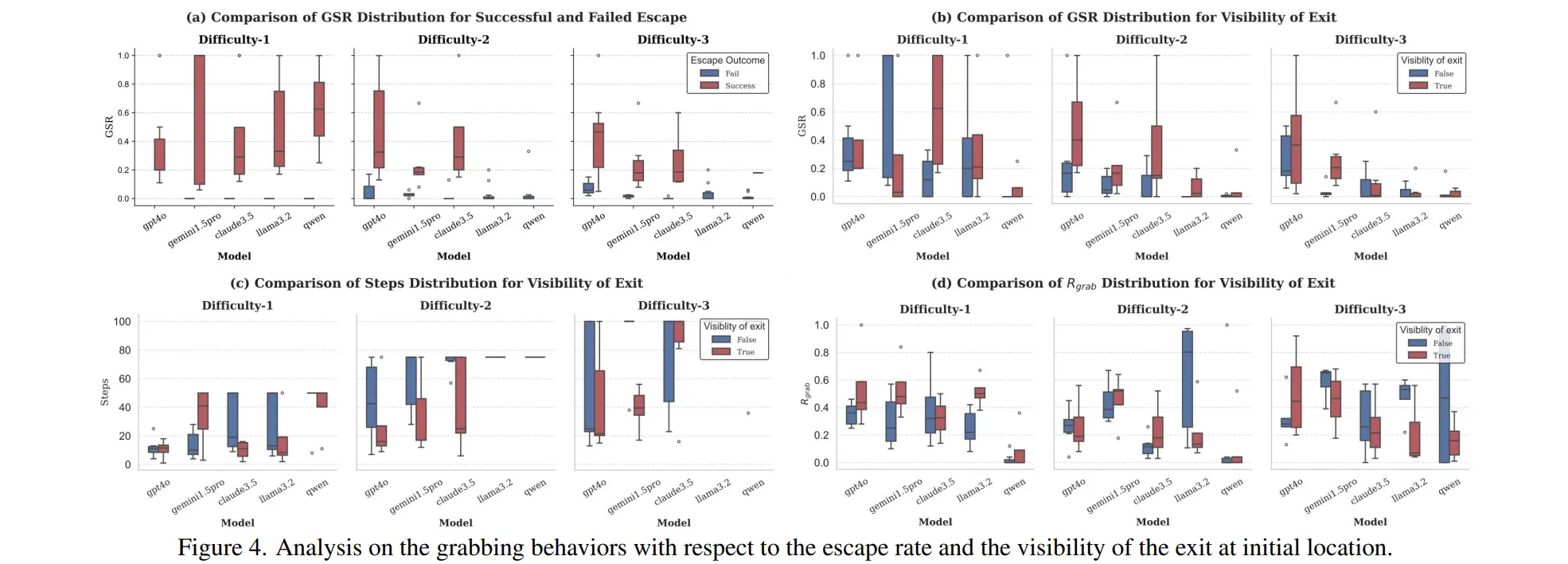
-
Figure 4의 a)를 보면 모델이 게임을 성공하였을 때 평균적으로 GRS가 높은 것을 확인할 수 있다.
-
Figure4의 a)를 보면 GPT-4o와 Claude는 게임의 난이도가 올라가도 GRS가 안정적인 것을 확인할 수 있다.
😖 개인적으로는 이 내용을 보면서는 어떤 말인지 잘 이해하지 못했다.
🔷 2. The Extensibility of EscapeCraft
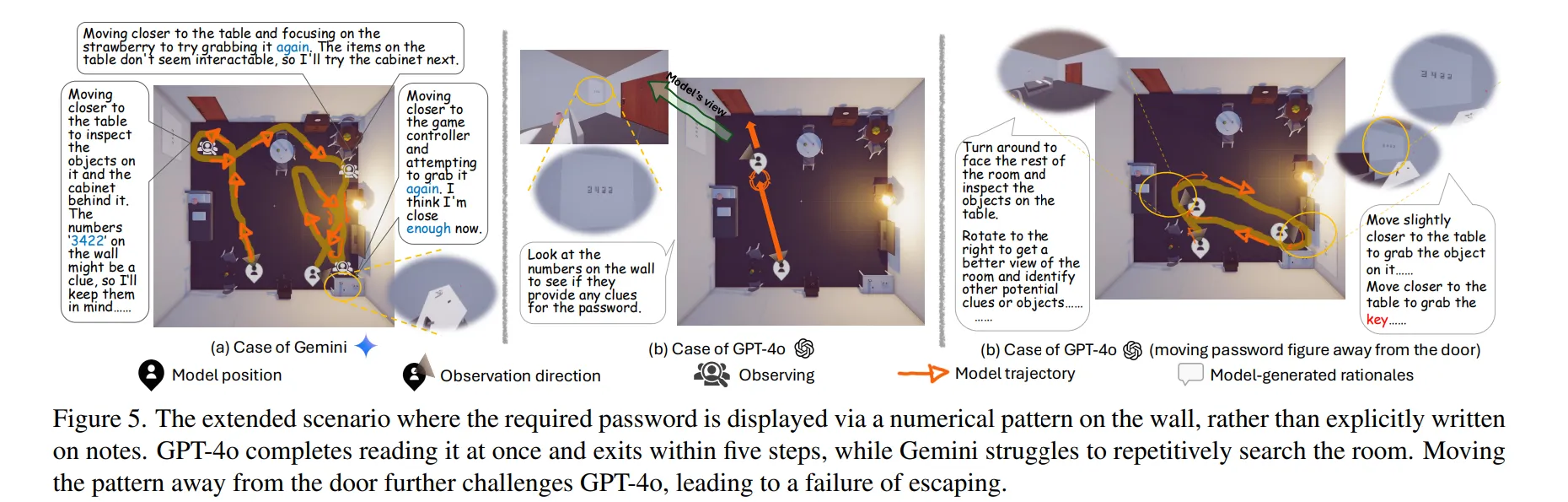
-
EscapeCraft는 모델의 성능을 평가하기 위해 유연하게 확장될 수 있다.
-
사용자는 노트에 비밀번호 단서를 주는 대신 벽에 단서를 두도록 설계할 수 있다.
-
문 근처에 단서를 두었을 경우GPT-4o는 Figure 5의 b)에서 처럼 빠르게 탈출하는 것을 확인할 수 있다.
-
반면 Gemini의 경우 문 근처에 단서를 두더라도 방을 구석구석 조사하며, 이를 활용하지 못하는 것을 확인할 수 있다.
-
벽에 있는 단서를 문에서 멀리 떨어진 경우, GPT-4o 역시 탈출하는 데 어려움을 겪는 것을 확인할 수 있다.
-
이는 아직 GPT-4o 역시 장기적인 추론 능력이 떨어진다고 해석할 수 있다.
🔷 3. Analysis of Intermediate Consistency
-
실험 중 모델이 우연히 중간 목표를 해결하였는지, 의도한 행동에 따라 중간 목표를 해결하였는지 평가하였다.
-
평가는 (Intent-Output Consistency)라고 불리는 0~1사이의 값으로 수행된다.
-
0은 우연한 성공을, 1은 유효한 추론을 의미하며, GPT-4o를 통해 모델이 생성한 근거와 실제 환경 피드백을 비교하여 평가하였다.

-
GPT-4o는 GSR이 31.36%이지만 GRS 중에서도 오직 26.51%만 일관성 있는 행동이었다는 것을 확인할 수 있다.
-
이는 아직까지 추론 능력과 인식 능력 간의 일관성이 떨어진다는 것을 알 수 있다.
🔷 4. Analysis on Post-game Debriefing
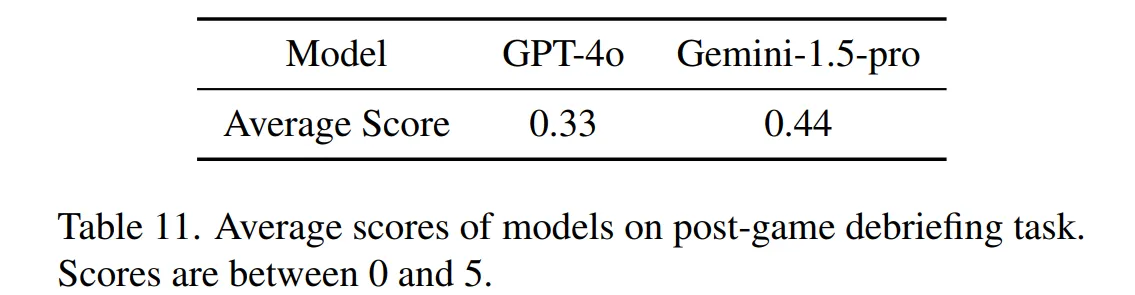
-
Post-game Debriefing에서는 모델이 게임을 마친 후, 탈출 과정을 회상하여 재구성하도록 한다.
-
평가는 게임 성공률이 높은 GPT-4o와 Gemini에 대해서만 이루어졌다.
-
두 모델 모두 재구성 능력이 아직까지 부족하다는 것을 확인할 수 있다.
-
두 모델 모두 탈출과 관련된 프로세스는 잘 기억하였지만, 탈출과 관련 없는 정보나 배경에 대해서는 잘 표현하지 못했다.
-
이러한 방식을 효율적일 수는 있지만, 논문의 저자는 향후에는 주변 정보에 대한 기억 능력 역시 향샹시켜야 한다고 말한다.
6️⃣ Conclusion
-
본 논문에서는 3D 환경 플랫폼 EscapeCraft를 개발하여, 멀티모달 추론 능력을 평가할 수 있는 MM-Escape 벤치마크를 구축하였다.
-
실험 결과 멀티모달 모델은 Task의 난이도가 증가함에 따라 성능이 급격하게 떨어지는 것을 확인할 수 있었다.
-
또한 모델들은 피드백 반영 능력이 부족하여 동일한 행동을 반복하거나, 시각 인지 능력이 떨어져 구석에 갇히는 행동을 보였다.
-
이번 연구를 통해서 MLLM의 개선사항에 대한 좋은 통찰을 제공하길 바란다.
7️⃣ 논문을 읽은 후…
우선 논문에서는 실험 결과에도 힘을 실은 것 같지만, 그에 비해서 설명력이 부족한 것 같아 아쉬웠다. 글을 통해 하고 싶은 말을 정확하게 이해하지 못하였다. 그럼에도 불구하고, 지난 번에 읽은 EscapeBench에서와 달리 시각 정보를 포함한 방 탈출 벤치마크를 구축했다는 점이 중요한 것 같다. 중간 평가 자체는 EscapeBench에서도 있어서 이번 논문 자체의 특이점이라고 생각하지는 않는다.
대신 Post-Game Debriefing은 흥미로웠다. 논문에서 Multi-Room으로 Test를 수행하였을 때 성공률이 올라가는 것을 보면, 모델이 방 탈출 과정에서 자신의 행동을 학습한다는 것을 알 수 있다. 그렇다면 모델이 자신의 시행착오에서 무엇을 배웠는지는 Post-Game Debriefing를 통해 정성적으로 확인해볼 수 있다고 연결해볼 수 있다. Continual Learning 영역을 조금 더 강화해서 모델이 계속해서 시행착오를 잘 학습할 수 있다면 이러한 부분에서 성능 개선 역시 생각해볼 수 있을 것 같다.
