
🎮ORAK: A FOUNDATIONAL BENCHMARK FOR TRAINING AND EVALUATING LLM AGENTS ON DIVERSE VIDEO GAMES
🔗 논문: https://arxiv.org/abs/2506.03610
💻 GitHub : ORAK: A FOUNDATIONAL BENCHMARK FOR TRAINING AND EVALUATING LLM AGENTS ON DIVERSE VIDEO GAMES
🧐 학회: ICLR 2026 submitted
✏️ 논문 정리
1. 이 논문을 읽는 이유가 무엇인가요?
⇒ 비디오 게임에 따라 환경이 어떻게 다르며, 모델이 어떻게 게임 환경과 상호작용하는지 이해하고 싶다.
2. 논문 제목의 의미는 무엇인가요?
⇒ 비디오 게임 속에서 LLM의 성능을 평가할 수 있는 벤치마크와 학습, 평가 데이터를 제공하는 논문이다.
3. 논문의 등장배경은 무엇인가요?
⇒ 현재 비디오 게임 속에서 LLM의 성능을 평가하는 벤치마크는 존재하지만, 게임 환경이 2D이거나 다양한 에이전틱 모듈, 다양한 게임 환경을 제공하는 벤치마크는 부족하다. 그래서 3D 게임 환경을 포함한 12개의 비디오 게임 벤치마크와 다양한 모듈을 적용해볼 수 있는 MCP 인터베이스를 제공한다.
4. 논문을 1~2줄로 요약하세요
⇒ 논문에서는 Plug and Play 인터페이스를 통해 다양한 LLM, 에이전틱 모듈로 평가할 수 있는 벤치마크 Orak을 제공한다. 추가로 각 게임에서 성능이 좋은 모델의 Trajectory를 파인튜닝 데이터로 제공한다.
0️⃣ Abstract
🔷 게임 산업에서의 LLM
- 현재 게임 산업에서는 사람들이 원하는 캐릭터를 만들기 위해 LLM을 활용하고 있다.
🔷 하지만 아직까지 초입
- 현재 다양한 장르의 게임에서 LLM의 성능을 평가하기 위한 방법이 부족하다.
- LLM이 복잡한 게임에서 잘 작동하기 위한 에이전트 모듈에 대한 연구가 부족하다.
- 사전 학습된 LLM을 특정 게임에 파인튜닝하기 위한 데이터셋이 부족하다.
🔷 위 문제를 해결하기 위해 Benchmark Orak 제안!
- 12개의 인기 비디오 게임에서 LLM을 훈련하고 평가하기 위한 벤치마크 Orak 제안한다.
- MCP(Model Context Protocol)을 기반으로 구축한 plug-and-play 인터페이스를 통해 다양한 게임에서 에이전트 모듈에 대한 연구를 수행할 수 있도록 돕는다.
- 또한 게임에서 가장 뛰어난 성능을 보이는 모델의 게임 수행 과정을 추가적인 파인튜닝 데이터셋으로 제공한다.
- Orak은 게임 리더보드나 LLM 배틀 아레나, 에이전트 전략 및 파인튜닝 효과 심층 분석 등 통합적인 평가 프레임워크를 제공한다.
1️⃣ Introduction
🔷 게임 산업에서의 LLM
- 현재 게임 산업에서는 사람들이 더욱 게임을 즐길 수 있도록, LLM을 활용한 지능적인 NPC(Non-Player-Character), 몬스터, 동료 생성에 관심을 가지고 있다.
- 이에 발맞춰, 게임 속에서 LLM의 능력을 평가하는 다양한 벤치마크가 등장하고 있다.
🔷 현 벤치마크의 한계
- 대부분의 벤치마크는 실시간 비디오 환경이 아니라 Text 데이터 환경이거나 2D의 격자 시뮬레이션 환경이다.
- 복잡한 게임을 해결하기 위해서는 Self-reflection, Memory, Tool use와 같은 에이전틱 모듈이 필요한데, 현재 벤치마크들은 이에 대한 평가가 부족하다.
- 사전 학습된 LLM이 특정 게임에 뛰어난 성능을 발휘하기 위한 파인튜닝 데이터셋이 부족하다.
🔷 그래서 Orak 벤치마크 제작!
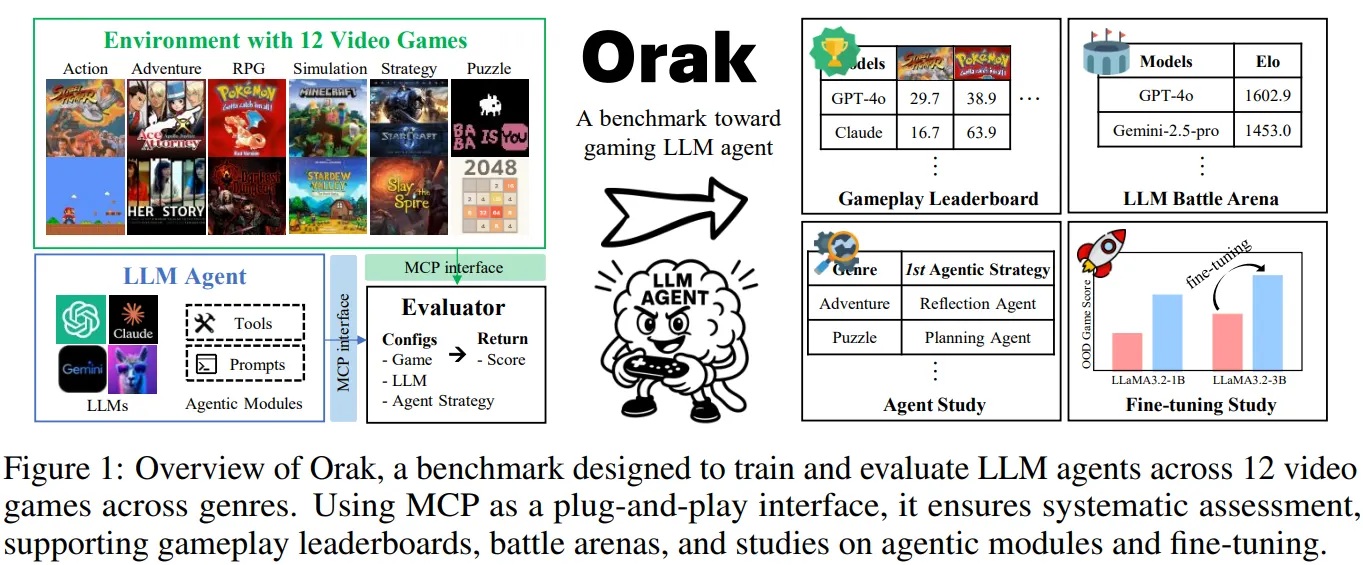
🔻 Orak 데이터셋 속 게임 종류
- Orak은 총 12개의 비디오 게임 환경을 대상으로 구축되었다.
- Street Fighter III (스트리트 파이터 3)
- Super Mario (슈퍼 마리오)
- Ace Attorney (역전재판)
- Her Story (헐 스토리)
- Pokemon Red (포켓몬스터 레드)
- Darkest Dungeon (다키스트 던전)
- Minecraft (마인크래프트)
- Stardew Valley (스타듀 밸리)
- StarCraft II (스타크래프트 2)
- Slay the Spire (슬레이 더 스파이어)
- Baba Is You (바바 이즈 유)
- 2048 (2048)
🔻 Orak 게임 장르
- 선정된 12개의 6개의 게임 장르로 분류되며, 각 장르를 통해 LLM 모델의 게임 능력을 종합적으로 평가할 수 있다.
- action (액션) : 세밀한 조작 능력 평가
- adventure (어드벤처) : 장기기억 능력과 문제 해결 능력 평가
- role-playing (RPG)
- simulation (시뮬레이션)
- strategy (전략) : 복잡한 추론 능력과 여러 단계의 계획 설계 능력 평가
- puzzle (퍼즐)
🔻 LLM과 게임 환경이 상호작용할 수 있는 Plug and Play 인터페이스 구축!
- MCP를 활용한 Plug and Play 인터페이스를 구축하여 LLM이 게임 환경과 원활하게 상호작용할 수 있다.
- 게임 환경과 에이전틱 모듈 모두 MCP 서버로 작동하여 LLM이 호출할 수 있는 Tool로 제공된다.
⭐ 이 부분은 개인적으로 필요한 내용이라 원문 작성
To enable consistent evaluation of rapidly evolving LLMs, we introduce a plug-and-play interface using Model Context Protocol (MCP) (Hou et al., 2025), allowing LLMs to seamlessly interact with agentic modules in gameplay. Each game environment and agentic module package operates as an independent MCP server, providing game mechanics (e.g., retrieving game states, executing game steps) or agentic strategies (e.g., reflection, planning) as callable tools to LLMs. During evaluation, LLM interacts with these servers by sequentially retrieving game states, performing action inference using agentic modules, and executing game steps, which enables streamlined evaluation across diverse games and supports controlled studies of various agentic modules.
🔻 Expert LLM의 Trajectory를 파인튜닝 데이터셋으로 제공
- Orak은 GPT-4o와 같은 뛰어난 성능을 발휘하는 모델의 게임 Trajectory를 파인튜닝 데이터셋으로 제공한다.
- Trajectory에는 게임 속 전문가 모델의 판단 등의 정보가 압축적으로 담겨 있어 효율적인 학습이 가능한다.
🧐 KD(Knowledge Distillation) : 지식증류
위와 같은 데이터셋은 교사 모델(여기서는 GPT-4o)의 사고과정을 압축하여 전달하는 것이니 지식증류로 볼 수 있을 것 같다. 한편으로는 모델의 추론 과정을 통해 데이터셋을 증강할 수 있다는 사실도 캐치할 수 있을 것 같다. 이러한 데이터는 게임환경(입력데이터) → 모델의 행동(정답) 형태의 지도 학습으로 파인튜닝 하는 걸까? 아니면 게임환경(텍스트 데이터로 전처리) + 모델 출력을 비지도학습으로 학습하는 걸까? 이에 대해서는 4장에서 다루는 것 같으니 조금 있다가 살펴보기로 하자!
🔻 다양한 평가방식으로 모델의 종합적인 평가 가능
- LeaderBoard
- LLM Battle Arena
- 입력 이미지 데이터에 대한 분석
- 에이전틱 전략 분석 (Ablation Study)
- 파인튜닝 효과 분석
🔷 Orak 벤치마크 실험을 통해 알게 된 사실!
- Proprietary LLM(소스 공개되지 않는 모델)이 Open Source LLM보다 월등히 뛰어난 성능을 발휘한다.
- Battle Arena에서는 Proprietary LLM와 Open Source LLM 간의 성능 차이가 줄어든다.
- Proprietary LLM은 에이전틱 모듈의 성능을 잘 활용하지만, Open Source LLM은 한정된 성능 향상만 관측된다.
- 입력 이미지의 상태가 LLM의 성능을 제한한다.
- 파인튜닝 데이터셋은 큰 모델에서 작은 모델로 게임 메타 정보를 효과적으로 전달한다.
☝️ 결론적으로 Orak 벤치마크는 게임 에이전트 모듈 구축과 게임 환경에서의 모델 평가에 기여한다는 것을 알 수 있다.
2️⃣ Related Work
2장에서는 LLM이 적용된 게임 환경과 각 환경에서의 벤치마크의 변화, 모델의 성능개선을 위한 노력 등에 대해 설명한다.
🔷 1. 게임 환경에서의 LLM 적용
🔻 1-1. 시작은 Text World에서!
- 초기에 LLM은 Text에 기반한 게임에 적용되었다.
- LLM은 Text 환경에서 추론 과정을 통해 게임을 진행하였다.
- 예시 : Jericho, Zork TextCraft
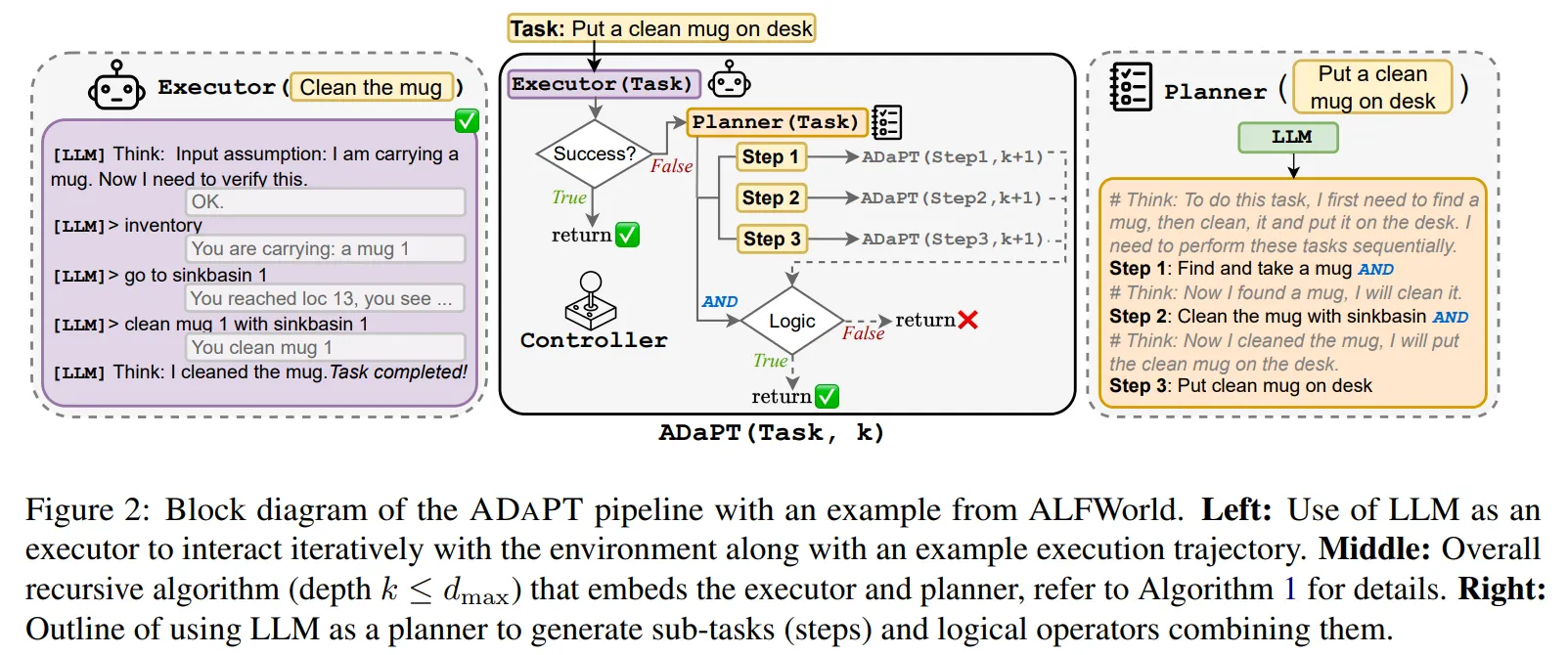
📃 출처 : ADaPT: As-Needed Decomposition and Planning with Language Models
🔻 2D 게임으로 확장!
- 이후 LLM은 2D 게임 환경에 적용되기 시작하였다.
- 이때부터 공간적인 추론과 퍼즐을 풀 수 있는 능력이 중요해지기 시작하였다.
- 예시 : Chess, NetHack, Crafter


📃 출처 : BENCHMARKING THE SPECTRUM OF AGENT CAPABILITIES
🔻 복잡한 비디오 게임으로의 확장과 에이전틱 모듈 활용!
- 현재는 복잡한 비디오 게임에 LLM을 적용하고 있다.
- 복잡한 게임을 해결하기 위해 LLM은 다양한 에이전틱 모듈을 활용하고 있다.
- 예시 : Minecraft, Civilization, Pokemon, StarCraft
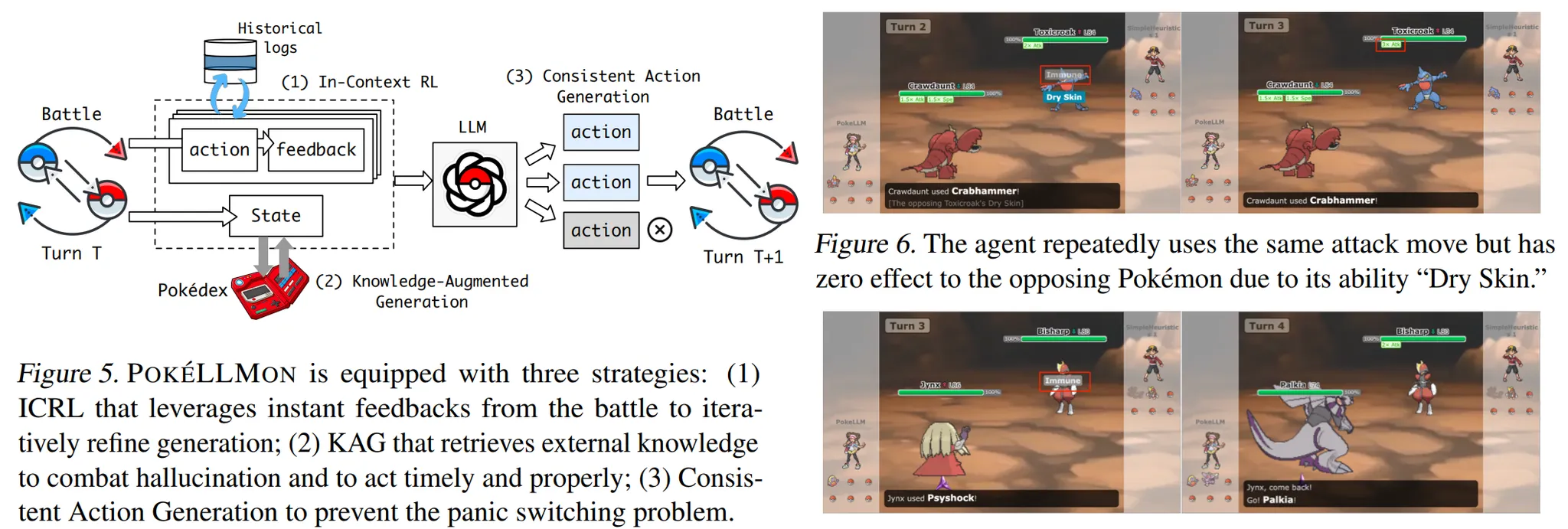
📃 출처 : POKE´LLMON: A Human-Parity Agent for Pokemon Battles ´ with Large Language Models
🔷 2. 현재 등장한 벤치마크는 어떤 게 있지?
📚 Game 환경의 벤치마크들!

🔻 2-1. Text-based 벤치마크
- Text 환경에서 만들어진 벤치마크는 LLM의 텍스트 환경 탐색과 추론 능력을 평가한다.
- 예시 : GAMA-Bench, GameBench, GameArena, SmartPlay

📃 출처 : SMARTPLAY : A BENCHMARK FOR LLMS AS INTELLIGENT AGENTS
🔻 2-2. 2D 차원 게임 벤치마크
- 2D 게임환경의 벤치마크는 모델의 시각적 추론 능력과 공간 추론 능력을 평가한다.
- 예시 : Barlog, LVLM-Playground
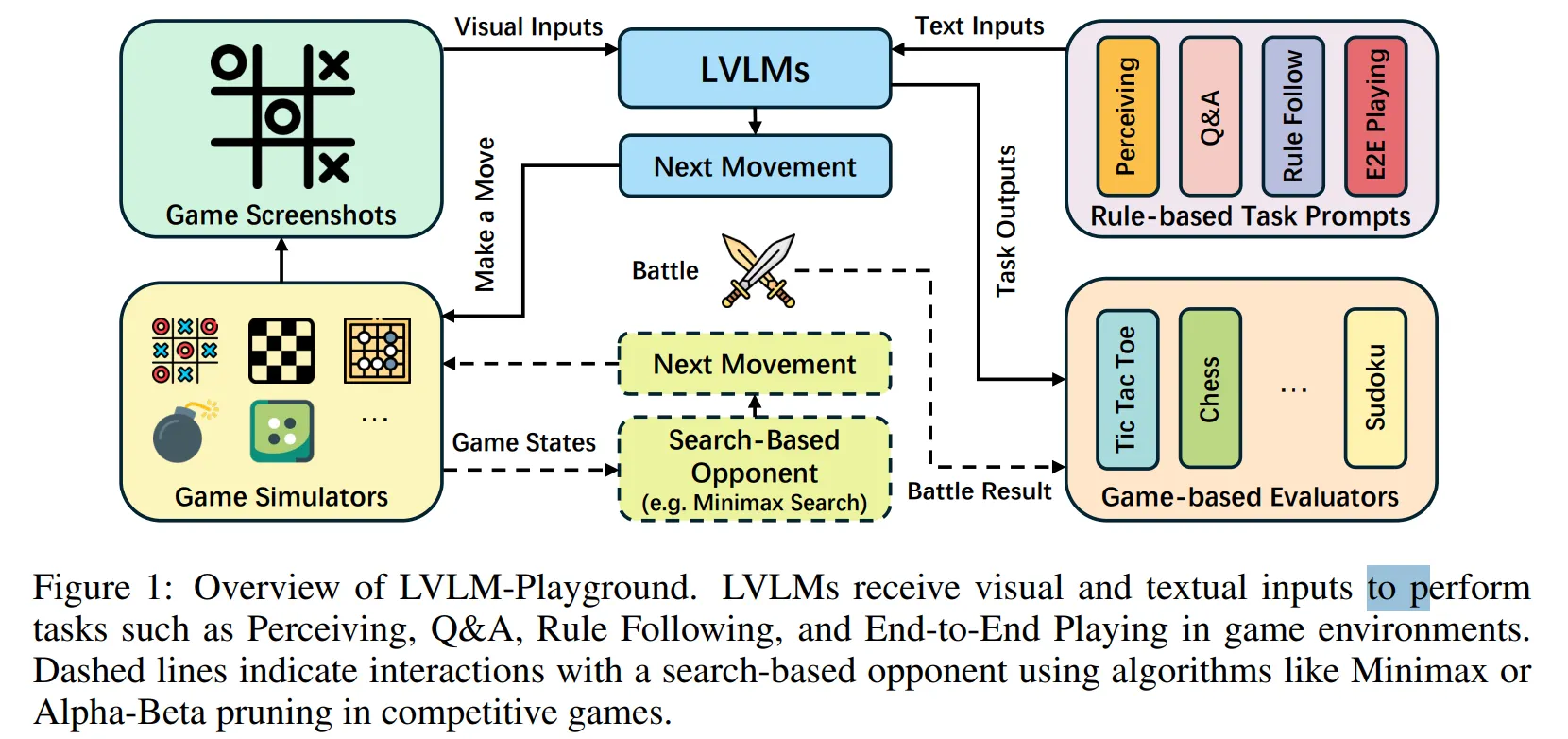
📃 출처 : ARE LARGE VISION LANGUAGE MODELS GOOD GAME PLAYERS?
🔻 2-3. Vidoe 게임의 벤치마크
- 비디오 게임의 벤치마크는 시뮬레이션 상황과 모델의 전략적 행동 등을 평가한다.
- 예시 : Cradle, V-MAGE, DSGBench
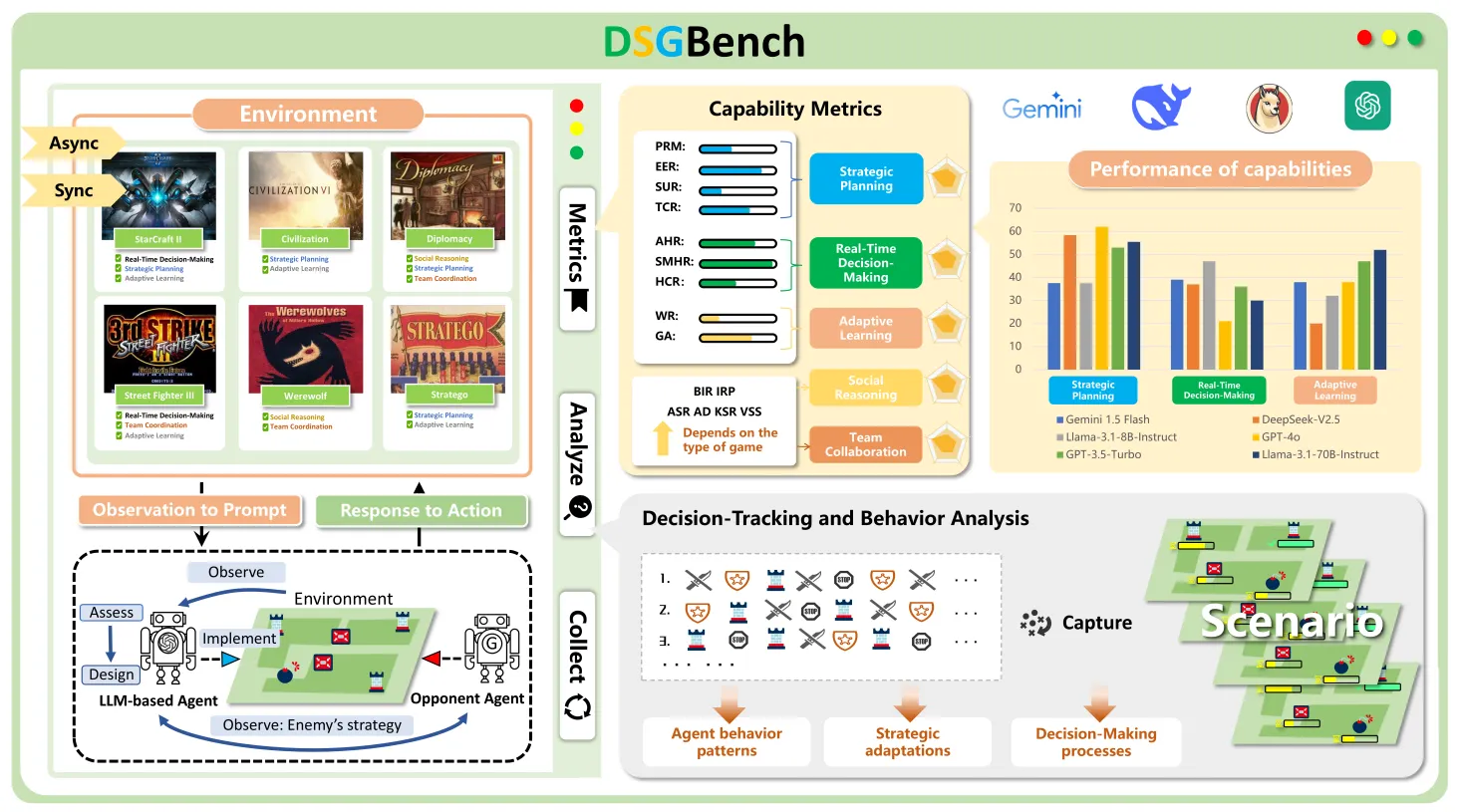
📃 출처 : DSGBench: A Diverse Strategic Game Benchmark for Evaluating LLM-based Agents in Complex Decision-Making Environments
🔷 3. 성능 개선을 위한 노력
🔻 3-1. 다양한 시도들
- Chain of Thought(CoT) : 모델이 답변 전 단계적으로 생각하는 방식
- Self-reflection : 에이전트가 이전에 수행한 행동이나 결과를 분석하는 방식
- Hierarchical Task Planning : 복잡하고 장기적인 목표를 여러 개의 하위 목표로 쪼개어 순차적으로 해결하는 방식
- Skill Library : 에이전트가 사용할 수 있는 사전 정의된 Tool
🔻 3-2. 파인튜닝 방식의 종류
🔶 Data-Centric Approach
- 모델이 Trajectory와 같은 모델의 행동 등의 데이터를 중심으로 학습하는 방식
- Expert 모델의 CoT, Reflection, Planning 등의 내용을 함께 학습한다.
- 논문에서 제공하는 Expert LLM Trajectory Data가 여기에 해당한다!
🔶 Framework Oriented Approach
- 모델이 환경과의 상호작용을 통해 학습하는 방식
🤔 내가 벤치마크을 만든다면??
지금까지 살펴본 내용을 바탕으로 게임환경에서의 특징을 정리해보자.
- 모델과 환경이 상호작용 할 수 있는 시스템 구축
- 모델의 행동, 결과를 환경에 전달
- 환경 상태를 모델에 전달
- 모델의 다양한 프레임워크를 평가할 수 있는 Metric 설계
- 게임 환경과 목표에 대한 가이드라인 제공
- 게임 환경 분석 ⇒ 이건 3장에서 다루는 것 같으니 그때 살펴보도록 하자.
3️⃣ Orak
3장에서는 Orak 벤치마크의 Plug and Play 인터페이스와 벤치마크 속 게임의 장르, 특징에 대해 설명한다.
🔷 1. Plug and Play 인터페이스
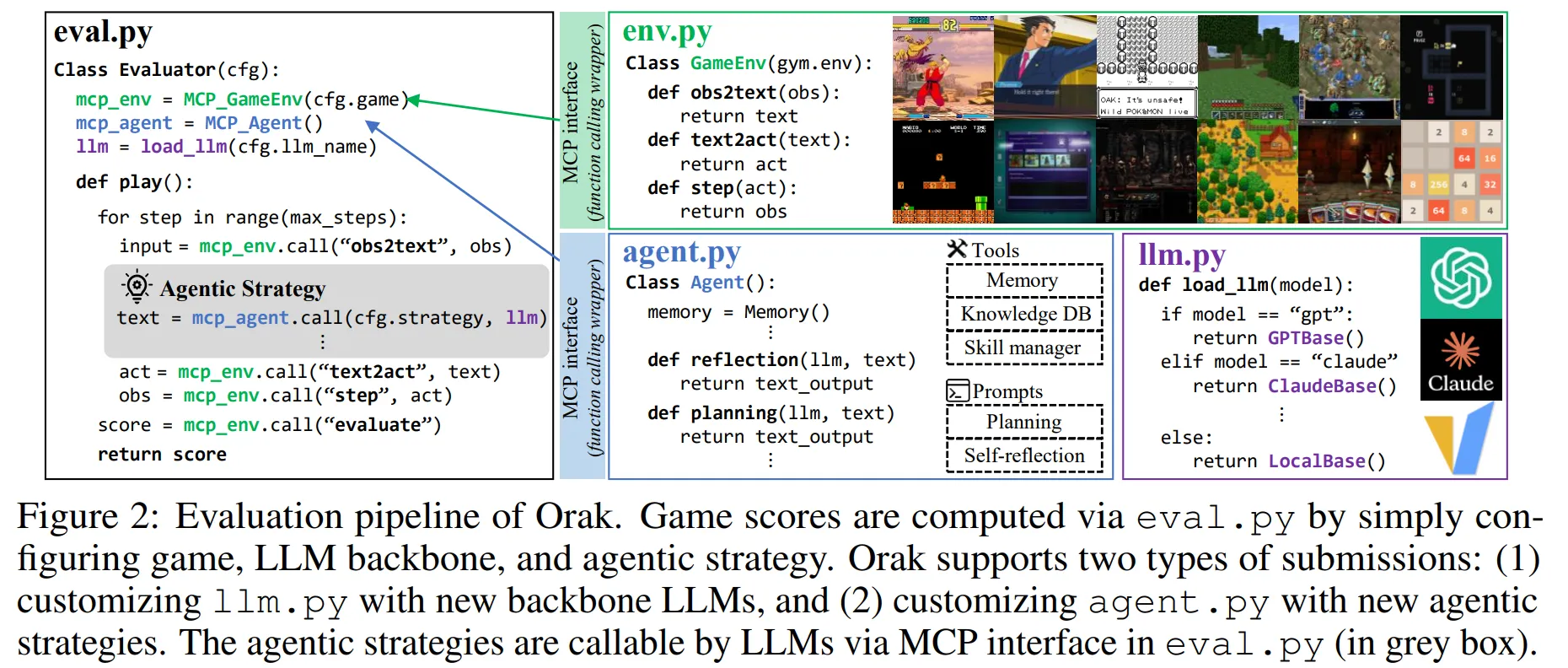
- Orak은 LLM과 게임 환경을 MCP 인터페이스로 통합하여 사용자가 다양한 실험을 수행할 수 있도록 설계되었다.
- 사용자는 LLM과 Agentic 구조를 자유롭게 변경하며 모델의 성능을 평가할 수 있다.
🔻 eval.py
- eval.py에서는 LLM Backbone, Game, Agentic strategy를 통합하여 모델의 성능을 평가한다.
- 게임의 상태가 모델에 전달
- LLM이 Agent strategy를 사용하여 작동
- 모델의 실행 결과가 게임에 전달
- 게임의 종료 혹은 최대 한도 단계까지 1~3이 반복된 후 게임의 점수 기록
🔷 2. Game Environments
🔻 2-1. LLM Capabilities Required
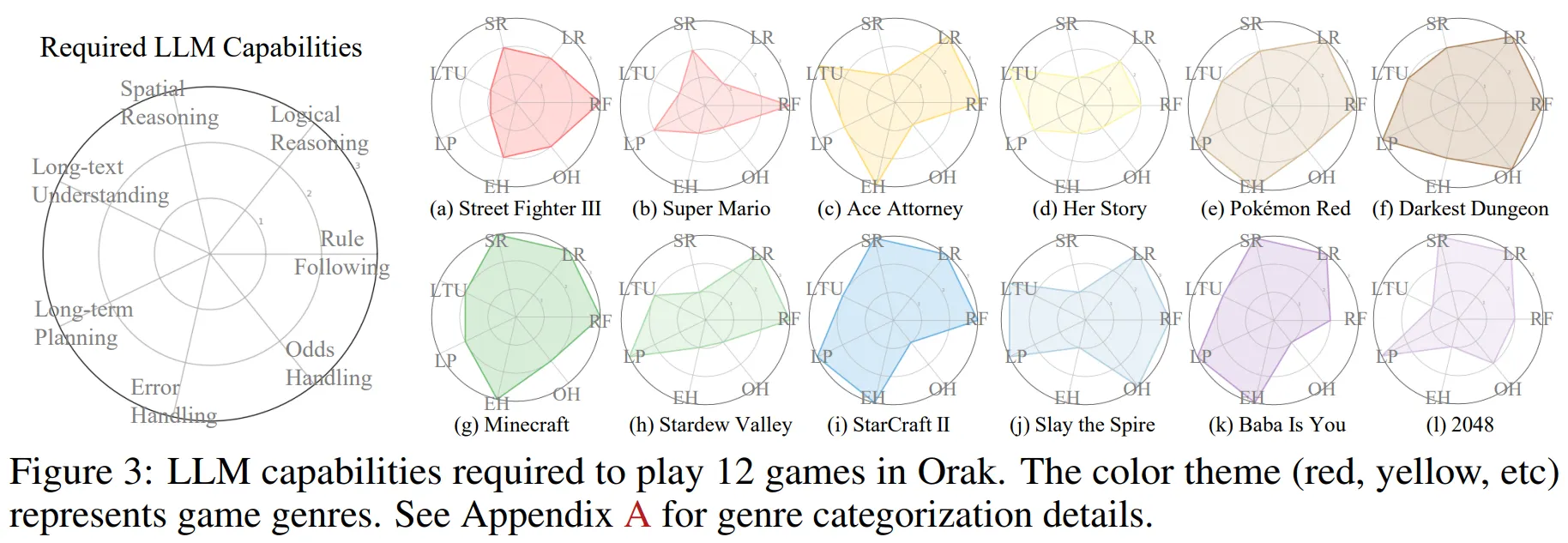
- Figure 3에서 각각의 게임을 잘 수행하기 위해 필요한 능력을 확인할 수 있다.
- Rule Following (RF): 요구되는 규칙 개수 (1: 단일 규칙, 2: 5개 미만 규칙, 3: 5개 이상 규칙)
- Logical Reasoning (LR): 게임 플레이를 위해 필요한 추론 단계 수 (1: 1단계, 2: 1~3단계, 3: 3단계 이상)
- Spatial Reasoning (SR): 게임 플레이에 요구되는 공간 이해 능력 수준 (1: 불필요, 2: 특정 상황에 필요, 3: 핵심 플레이에 필수)
- Long-text Understanding (LTU): 게임 플레이에 요구되는 긴 문맥 이해 능력 (1: 몇 줄, 2: 몇 문단, 3: 500단어 이상의 한 페이지 초과)
- Long-term Planning (LP): 전략적 계획 수립이 요구되는 정도 (1: 불필요, 2: 3개까지의 연속 행동 계획, 3: 3개 이상의 연속 행동 계획 필수)
- Error Handling (EH): 게임 플레이 계획이 틀어졌을 때 대처 능력 (1: 불필요, 2: 1단계 되돌리기 필요, 3: 다단계 되돌리기 및 재계획 필요)
- Odds Handling (OH): 게임 플레이 중 발생하는 변수 대처 능력 (1: 불필요, 2: 무작위성 존재, 3: 핵심 플레이에 무작위성 필수)
🔶 12게임에 종합적으로 필요한 능력
- Figure 3의 방사형 그래프를 참고하여 평균적으로 필요한 능력을 계산해 보았다.
| Capability | Rule Following | Logical Reasoning | Spatial Reasoning | Long-text Understanding | Long-term Planning | Error Handling | Odds Handling |
|---|---|---|---|---|---|---|---|
| Sum | 33 | 32 | 24 | 24 | 30 | 24 | 20 |
| Average | 2.75 | 2.67 | 2 | 2 | 2.5 | 2 | 1.67 |
→ Visual Date를 처리하는 능력도 중요하지만, 기본적으로 규칙 이해와 논리적 추론 능력, 장기 계획 설계 능력이 많이 중요한 것 같다. 이러한 성능은 Backnone LLM의 기본 성능에 많이 좌우될 것 같다. Agentic 모듈 역시 이런 능력을 보완할 수 있는 방향으로 설계되어야 할 것 같다.
🔻 2-2. GAME GENRE CATEGORIZATION (Appendix A)
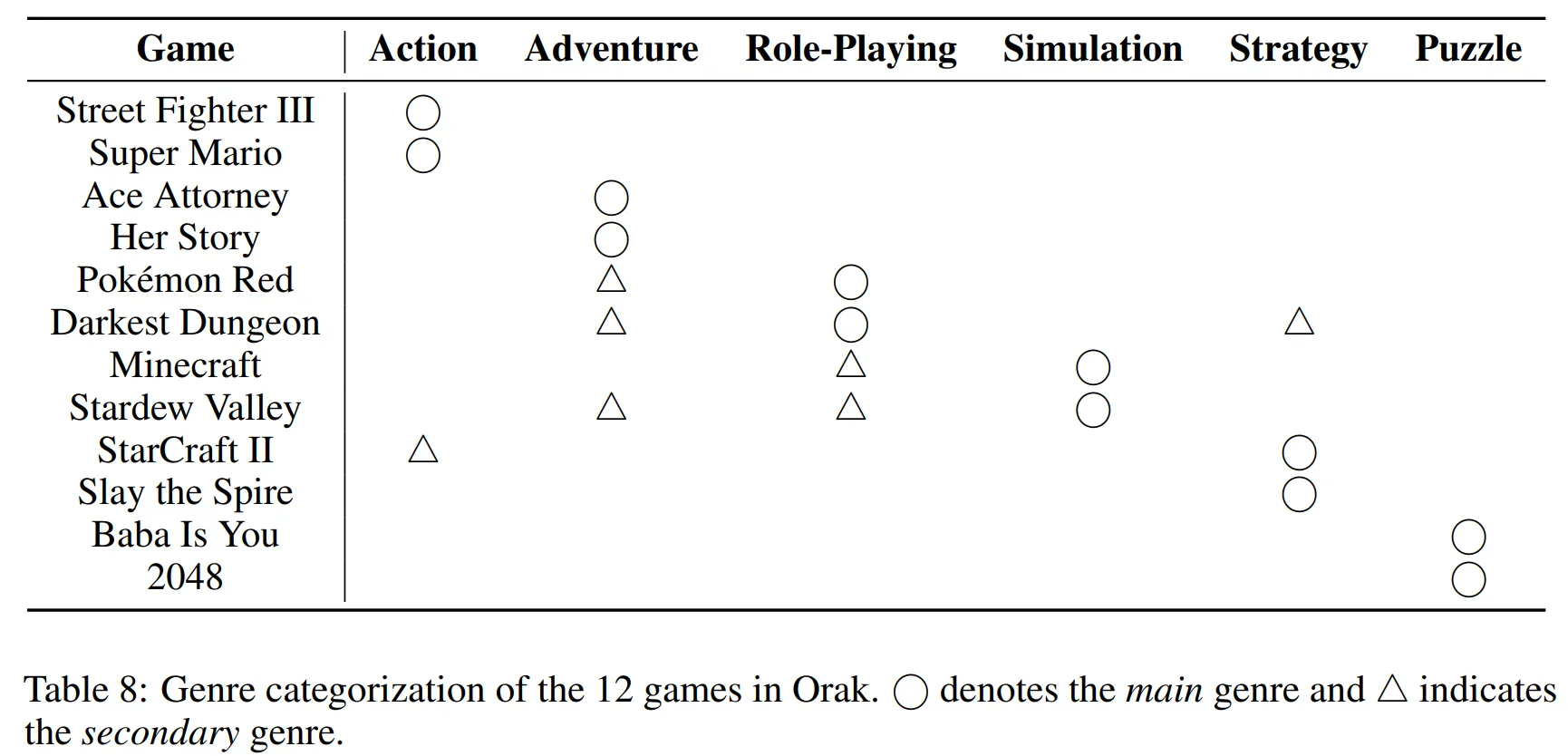
- Table 8을 보면 각 게임이 어떤 장르에 속하는지 정리한 것을 확인할 수 있다.
- Action: 정확한 조작, 빠른 반응 속도, 그리고 반사 신경을 중심으로 하는 게임
- Adventure: 스토리 탐색, 대화 상호작용, 단서 수집 및 논리적 추론을 통해 진행되는 서사 중심의 게임
- Role-Playing: 캐릭터의 레벨, 능력치 기반의 성장과 턴제 전투, 그리고 퀘스트 기반의 스토리 진행이 특징인 게임
- Simulation: 자원, 시간 등 복잡하고 상호 의존적인 변수들을 관리하고 조작하는 시스템 기반의 환경 게임
- Strategy: 장기적인 계획, 자원 관리, 전술적 의사결정 및 실행을 강조하는 게임
- Puzzle: 규칙 기반의 문제 해결, 패턴 인식, 논리적 또는 공간적 추론을 중심으로 하는 게임
🧐 마인크래프트 환경에서 신경써야 할 부분은?
논문 내용
(g) Minecraft (Mojang Studios, 2011) is categorized as a Simulation game due to its open-ended, system-driven mechanics, including resource gathering, crafting, and environmental manipulation. It also exhibits Role-Playing traits through its progression systems and player-driven narrative development, warranting secondary classification.
- 시간적, 공간적 변수들을 관리하고 조작하는 능력이 필요
- Rule Following (RF): 5개 이상 규칙을 잘 이해해야 한다.
- Logical Reasoning (LR): 3단계 이상의 추론 능력을 수행할 수 있어야 한다.
- Spatial Reasoning (SR): 공간 이해 능력이 매우 중요하다.
- Error Handling (EH): 계획이 틀어지더라도 계획을 유연하게 재설계할 수 있어야 한다.
🤔 Minecraft와 유사한 특징의 게임은 무엇이 있을까??
3D 환경이면 좋을 것 같고, 자원 수집, 도구 수집 및 제작 등이 가능한 World 게임이면 좋을 것 같다.
2D 환경에서 유사한 게임도 있었지만, Spatial Reasoning이 중요한 요소라 가능하면 유사한 3D 환경으로 살펴보았다.
🔶 1. Vintage Story
- 마인크래프트보다 훨씬 더 현실적이고, 기온, 습도 등 생존 요소가 극대화된 게임이다.
📃 출처 : https://shockbyte.com/en-gb/games/vintage-story-server-hosting
🔶 2. Valheim (발헤임)
- 북유럽 신화 테마의 3D 생존, 건축, 오픈 월드 게임이다.
📃 출처 : https://burrow.tistory.com/57
🔶 3. No Man's Sky (노 맨즈 스카이)
- 3D 우주 탐험을 배경으로 한 생존 게임이다.
- 아래의 자료는 자원을 수집하는 장면이다.
📃 출처 : https://www.youtube.com/watch?v=v24LaGnm5uo&list=PLghwljjAhdFT6lxZwFWBKHpUQWzns2s5-&index=1
🔻 2-3 게임에 대한 설명

- 논문에는 게임에 대한 설명이 작성되어 있다.
- 이번 글에서는 Minecraft에 대해서만 간단하게 정리하도록 하겠다.
🔶 Minecraft
- Minecraft는 세계를 탐험하고, 블록을 배치/파과하며, 자원을 수집하는 생존 게임이다.
- Game State : 플레이어 위치, 인벤토리, 체력, 근처 블록과 생물 정보
- Action Space : 자바 스크립트 코드 → 코드를 통해 동작
- Evaluation Task : 목표 도구 제작 → 인벤토리에 목표 도구 여부로 평가
#️⃣ Appendix I
Appendix I는 Minecraft 게임 실험 설계 방식과 결과를 설명한다.
😄 Appendix I는 지엽적인 내용이라 안보셔도 됩니다.

📃 출처 : https://namu.wiki/w/마인크래프트/자바 에디션/업데이트/정식판/1.19
🔷 Ⅰ. Description
🔻 Environment
- Orak에서 Minecraft 환경은 Mineflayer JavaScript API를 기반으로 작동한다.
- Mineflayer를 사용하면 LLM이 Javascript Command를 통해 Bot를 조종할 수 있다.
- Minecraft는 1.19 버전을 사용하였다. (2025년 10월 26일 기준 1.21.10까지 나왔다.)
- World는 Random seed 42로, Bot의 시작 위치는 (604, 100, -823)로 고정하였다.
- 시작할 때는 어떠한 도구도 제공되지 않는다.
- 목표 제작 도구 : 제작대, 돌 곡괭이, 화로, 황금검, 양동이, 다이아몬드 곡괭이, 마법부여대, 네더 포털
🔻 Observation to Text Conversion
- 게임 환경에 대한 정보를 LLM이 이해할 수 있도록 텍스트 형태로 변환한다.
- 환경에 대한 정보는 아래의 형식으로 전달받는다.
{주변 생물환경, 시간대, 주변 블록, 체력 상태, 배고픔 상태, 위치, 장착 아이템, 인벤토리 상태}🔻 Action Space
- LLM은 Javascript 언어를 통해 Bot을 조작한다.
- 이때 LLM이 복잡한 행동을 쉽게 수행할 수 있도록, 몇 개의 함수를 만들어 모델이 사용할 수 있도록 사전에 정보를 제공한다.
exploreUntil(bot, direction, maxTime, callback): 에이전트를 지정된 방향으로 최대 시간(maxTime) 동안 이동시키거나, 정의된 사용자 지정 중단 조건(callback)이 만족될 때까지 이동시킵니다.mineBlock(bot, name, count): 주변 32 블록 반경 내에서 지정된 이름(name)의 블록을 원하는 수량(count)만큼 채굴하고 수집합니다.craftItem(bot, name, count): 근처에 있는 제작대를 사용하여 지정된 아이템(name)을 원하는 수량(count)만큼 제작합니다.placeItem(bot, name, position): 지정된 위치(position)에 특정 유형의 블록(name)을 배치(설치)합니다.smeltItem(bot, itemName, fuelName, count): 지정된 아이템(itemName)을 제공된 연료(fuelName)를 사용하여 제련합니다. 이 함수를 사용하려면 근처에 화로가 있어야 합니다.KillMob(bot, mobName, timeout): 지정된 몬스터(bot, mobName)를 제한 시간(timeout) 내에 추격하고 제거한 후, 수집된 드롭 아이템을 획득합니다.getItemFromChest(bot, chestPosition, itemsToGet): 지정된 위치(chestPosition)의 상자로 이동하여 요청한 아이템(itemsToGet)을 검색하고 인벤토리로 가져옵니다.depositItemIntoChest(bot, chestPosition, itemsToDeposit): 지정된 상자로 이동하여 지정된 아이템(itemsToDeposit)을 해당 상자에 저장합니다.
🔷 Ⅱ. Prompt
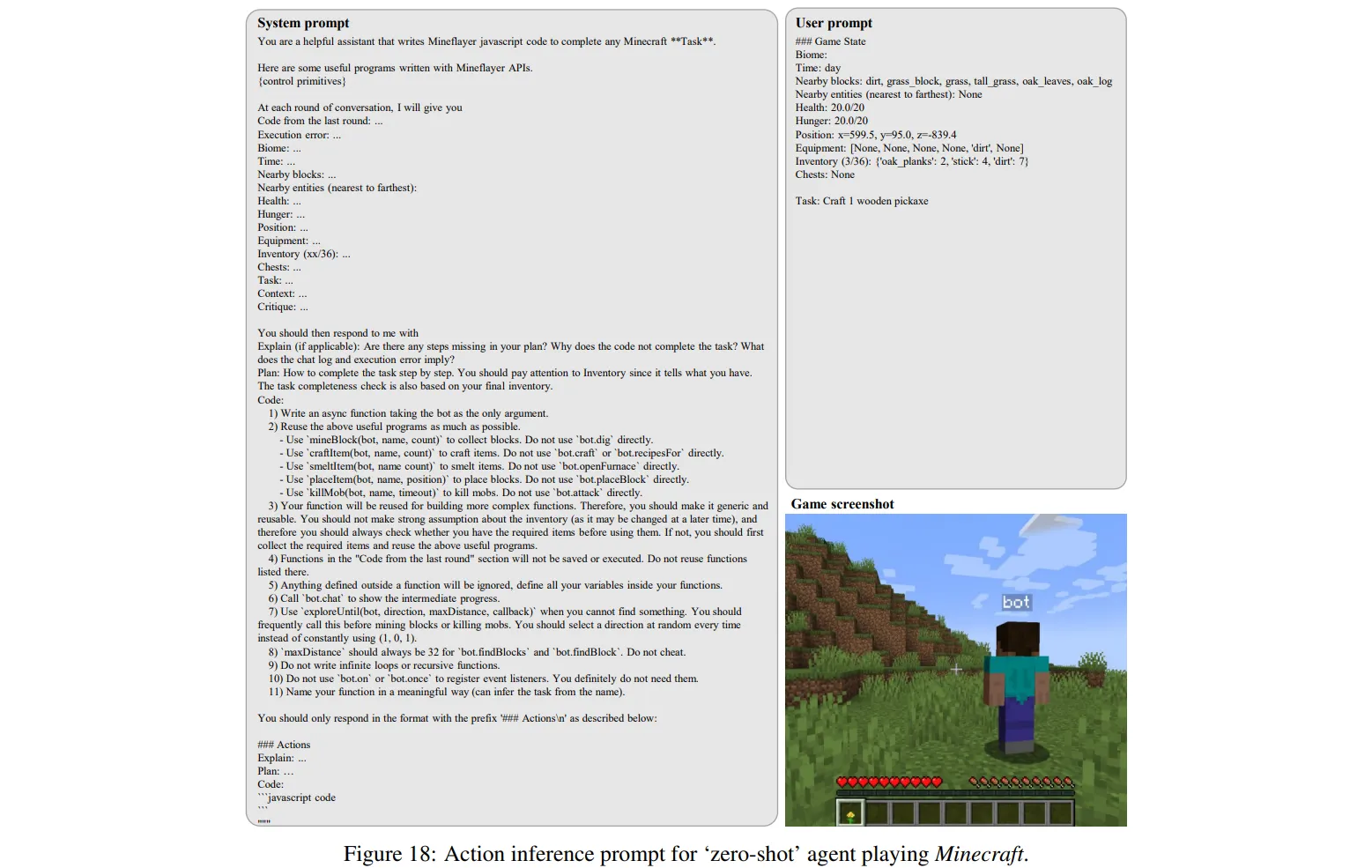
- LLM에게 제공되는 프롬프트는 System Prompt와 User Prompt로 나뉜다.
🔻 System Prompt
- System Prompt는 LLM에게 게임에 대한 지식과 코딩 규칙을 설명한다.
- 게임의 주요 목표
- 사전에 만든 행동 함수 설명
- 텍스트 형태의 환경 정보 포맷(앞서 설명한 포맷)
- LLM의 출력 형태 설명
🔶 규칙에 대한 내 생각
4) Functions in the "Code from the last round" section will not be saved or executed. Do not reuse functions listed there
- 모델이 이전 행동에 대한 Reflection을 해야 하니까 이전 코드를 제공한다.
- 모델이 이전 코드를 현재 실행 중이라는 오해를 막기 위해 종료되었다고 알려준다.
- 모델이 똑같은 행동을 반복하지 않도록 이전 코드 사용을 막는다. → 행동 함수를 통해 반복 작업이 이미 구현했기 때문에 동일한 함수를 반복해서 사용하는 상황은 어느 정도 방지된 것 같다.
7) Use
exploreUntil(bot, direction, maxDistance, callback)when you cannot find something. You should frequently call this before mining blocks or killing mobs. You should select a direction at random every time instead of constantly using (1, 0, 1)
- 모델이 World를 계속해서 탐험할 수 있도록 유도한다.
- 주변 환경의 방향에 대한 정보가 없어서 어떻게 구현될지 궁금했는데, Orak에서는 방향에 대한 정보는 추가적으로 제공하지 않고 모델이 Random하게 정할 수 있도록 한 것 같다.
- 나 역시 Minecraft Game에서 탐색을 할 때는 여기저기 돌아다녔던 것 같아서 괜찮은 아이디어인 것 같다.
- 하지만 주변 환경에 대해 기억하고, 더 효율적인 탐색을 수행하기 위해서는 방향 정보 역시 향후에 추가되어야 할 것 같다.
🔻 User Prompt
- User Prompt는 LLM에게 현재 게임 상황을 전달한다.
- Mineflayer API에게 전달받은 게임 state

🔷 Ⅲ. Evaluation Metric for Minecraft
- 모델이 평가는 모델이 제작한 도구의 성공 여부로 진행된다.
- 모델의 각 Step마다 도구가 인벤토리에 있을 경우 100점을, 없을 경우 0점을 부여한다. → 이 부분은 코드를 통해 살펴보았다.
- 한번에 하나의 도구 생성이 목표인 것을 확인할 수 있다.
# LLMs
# "gpt-4o-mini" "gpt-4o" "o3-mini" "claude-3-7-sonnet-20250219" "gemini-2.5-pro-preview-03-25" "deepseek-reasoner"
# SLMs
# "meta-llama/Llama-3.2-1B-Instruct" "meta-llama/Llama-3.2-3B-Instruct" "Qwen/Qwen2.5-3B-Instruct"
# "Qwen/Qwen2.5-7B-Instruct" "nvidia/Nemotron-Mini-4B-Instruct" "nvidia/Mistral-NeMo-Minitron-8B-Instruct"
game="minecraft"
model="gpt-4o-mini"
agent="skill_management_agent"
input_modality="text" # (text, image, text_image)
# Note: you need to run each task below sequentially
# 여기 보면 된다.
# Task1 - crafting_table
python scripts/play_game.py \
--config="./src/mcp_agent_client/configs/$game/config.yaml" \
env.task="craft 1 crafting table" \
env.success_condition="crafting_table" \
env.input_modality="$input_modality" \
agent.llm_name="$model" \
agent.agent_type="$agent" \
agent.prompt_path=mcp_agent_servers."$game".prompts."$input_modality"."$agent"
# 여기 보면 된다.
# Task2 - stone_pickaxe
python scripts/play_game.py \
--config="./src/mcp_agent_client/configs/$game/config.yaml" \
env.task="craft 1 stone pickaxe" \
env.success_condition="stone_pickaxe" \
env.input_modality="$input_modality" \
agent.llm_name="$model" \
agent.agent_type="$agent" \
agent.prompt_path=mcp_agent_servers."$game".prompts."$input_modality"."$agent"- 코드를 보면 max_stpes : 100이라 하나의 도구 제작마다 100 스텝이 주어지는 것을 확인할 수 있다.
# config.yaml
# logging: true
env_name: "Minecraft"
log_path: "logs"
runner:
max_steps: 100 # 여기 100 step 확인!
env:
task: craft 1 golden sword
input_modality: "text" # text
success_condition: golden_sword
world_seed: 42
azure_login_path: keys/azure-login/azure_login.json
server_host: http://127.0.0.1
server_port: 3000
request_timeout: 600
logging: false
# Agent configuration
agent:
llm_name: gpt-4o-mini # Qwen/Qwen2.5-7B-Instruct
api_key: "token-abc123"
api_base_url: "http://YOUR_LOCAL_IP:PORT/v1"
temperature: 1.0
repetition_penalty: 1.0
agent_type: skill_management_agent
prompt_path: mcp_agent_servers.minecraft.prompts.text.skill_management_agent
# mcp configuration
game_server: "./src/mcp_game_servers/minecraft/server.py"
agent_server: "./src/mcp_agent_servers/minecraft/server.py"🔷 Ⅳ. Experimental Configuration for Minecraft
- LLM 공통 파라미터 : temperature 1, repetition penalty 1
- 스텝 수 : 최대 100 step
- 실험 수 : 각 도구마다 3번의 게임을 진행하였고, 실험 결과의 평균과 표준편차를 제공한다.
🔷 Ⅴ. Result for Minecraft
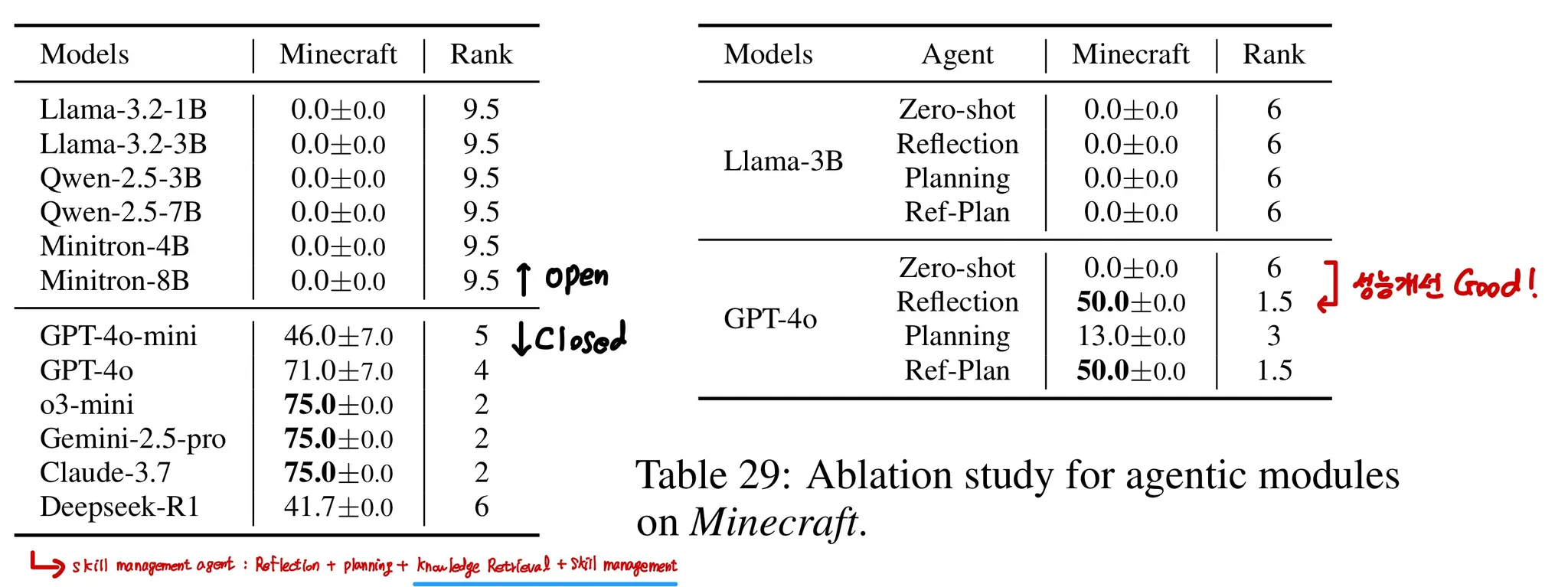
- Table 28을 보면 Closed source 모델들, 그 중에서도 o3-mini, Gemini-2.5-pro, Claude-3.7은 75점으로 뛰어난 성능을 발휘한다.
- Open source 모델들은 게임 실행을 위한 유의미한 Javascrpt 코드를 생성하는데 어려움을 겪었다.
- Table 29를 보면 Reflection 모듈은 모델 성능에 크게 기여하지만, Plannig까지 추가한 Ref-Plan은 성능 향상이 없음을 확인할 수 있다.
- Table 28에 있는 GPT-4o는 Skill management agent라는 조금 더 모듈이 추가된 모델이다.
- Skill management Module은 모델이 성공적인 행동 코드를 저장한 후 필요할 때 가져올 수 있는 모듈이다.
4️⃣ Fine Tuning: Aligning Pre-trained LLMs into Game Agents
4장에서는 Expert LLM의 Trajectory로 제작된 파인튜닝 데이터셋에 대해 설명한다.
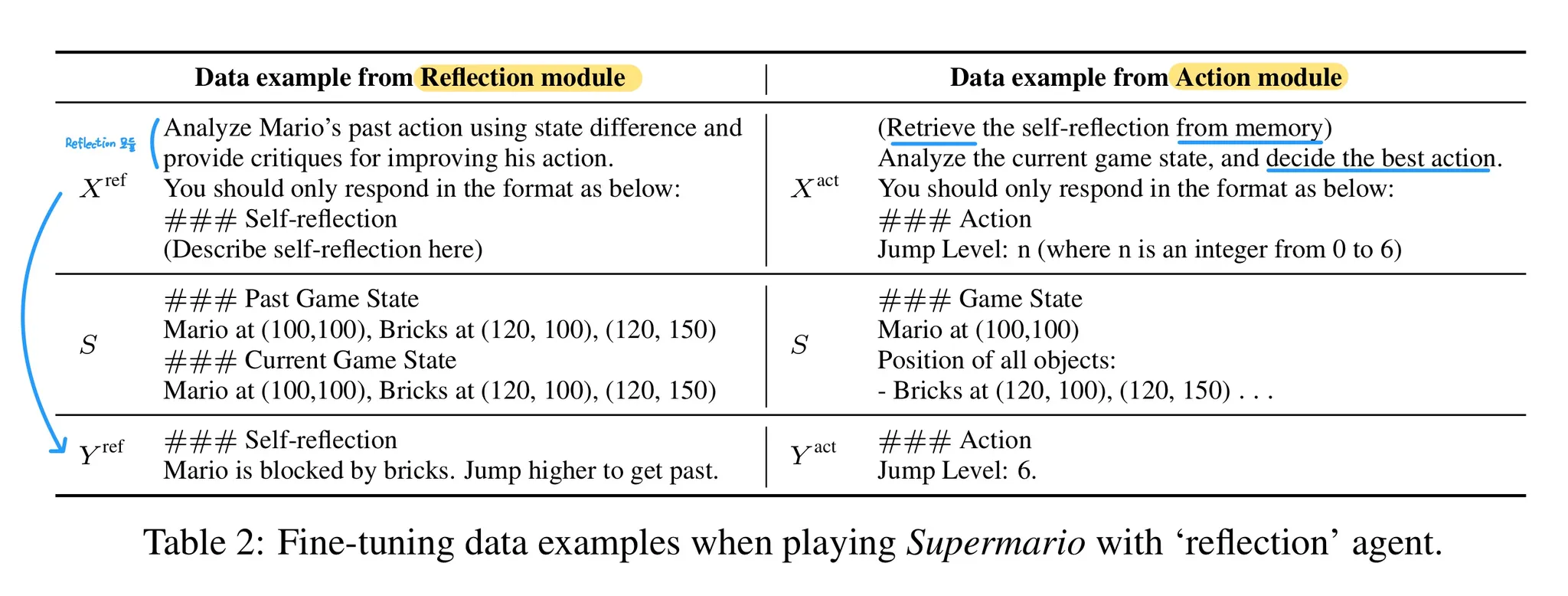
- 아래의 데이터 포맷에 대한 설명을 읽으며 Table 2를 살펴보면 된다.
🔷 1. Description
- Data는 GPT-4o, o3-mini와 같은 expert LLM이 게임 환경과 상호작용하는 Trajectory를 통해 구축하였다.
- 데이터셋은 Supervised fine-tuning(SFT)을 중심으로 구축되었다.
🔷 2. Data Format
- 각 게임의 데이터는 의 형태로 저장되어 있다.
- 각 는 LLM의 추론이 담겨 있다. 즉 는 게임 시작부터 종료까지 모델의 행동이다.
- : 각각의 step은 여러 개의 agentic 모듈이 사용될 수 있다.
- Table 2의 왼쪽 자료는 속에서도 인 경우라고 생각하면 된다.
🔷 3. Data Selection
- 논문의 저자는 파인튜닝 데이터 선정을 위해 1000개 이상의 LLM Trajectory를 수집하였다.
- 그 중 점수가 가장 높은 300개의 Trajectory를 선정하고, 12개의 게임 모두 이와 같은 방식으로 데이터를 수집한다.
- 최종적으로 11K의 파인튜닝 데이터셋을 구축하였다.
🔷 4. Data Augmentation
- 저자는 데이터셋의 프롬프트의 다양성을 늘리기 위해 GPT-4o를 사용하여 데이터를 증강하였다.
- 이때 데이터 증강은 System 프롬프트에 대해서만 수행되었다.
- 총 10개의 변형된 프롬프트를 생성하여 데이터가 11배로 확장되는 결과를 이끌었다.

- Figure 27은 GPT-4o를 활용하여 system prompt를 증강한 예시를 살펴볼 수 있다.
5️⃣ Experiment
5장에서는 리더보드, 아레나, Ablation study, Visual data에 대한 분석과 파인튜닝 효과에 대한 실험 결과를 설명한다.
🔷 1. Experiment Setup
🔻Model
- 8개의 Open source LLM : LLaMA-3.2-1B/3B , LLaMA-3.3-72B, Qwen-2.5-3B/7B/72B, Minitron-4B/8B
- 7개의 Proprietary LLM : GPT-5/4o/4o-mini , o3-mini, Gemini-2.5-pro , Claude-3.7-sonnet ,DeepSeek-R1
- 5개의 멀티모달 LLM : Qwen2.5-vl-7B/32B, GPT-4o, Gemini-2.5-pro, Claude-3.7-sonnet
🔻 Default Agentic Strategies
- Zero-shot action inference Agent : Street Fighter III, HerStory, Darkest Dungeon, 2048
- Reflection-planning Agent : Super Mario, Pokemon Red, Stardew Valley, StarCraft II, Slay the Spire, Baba Is You
- Reflection Agent : Ace Attorney
- Skill-management Agent : Minecraft
🔻 Metrics and Implementation Details
- 점수는 최대 점수를 통해 정규화 하였다.
- 각 게임마다 3~20번의 시행 후 평균 점수를 구하였다.
- 추가적으로 3명의 초보 유저의 점수도 평가하였다.
🔷 2. LLM Gameplay Performance
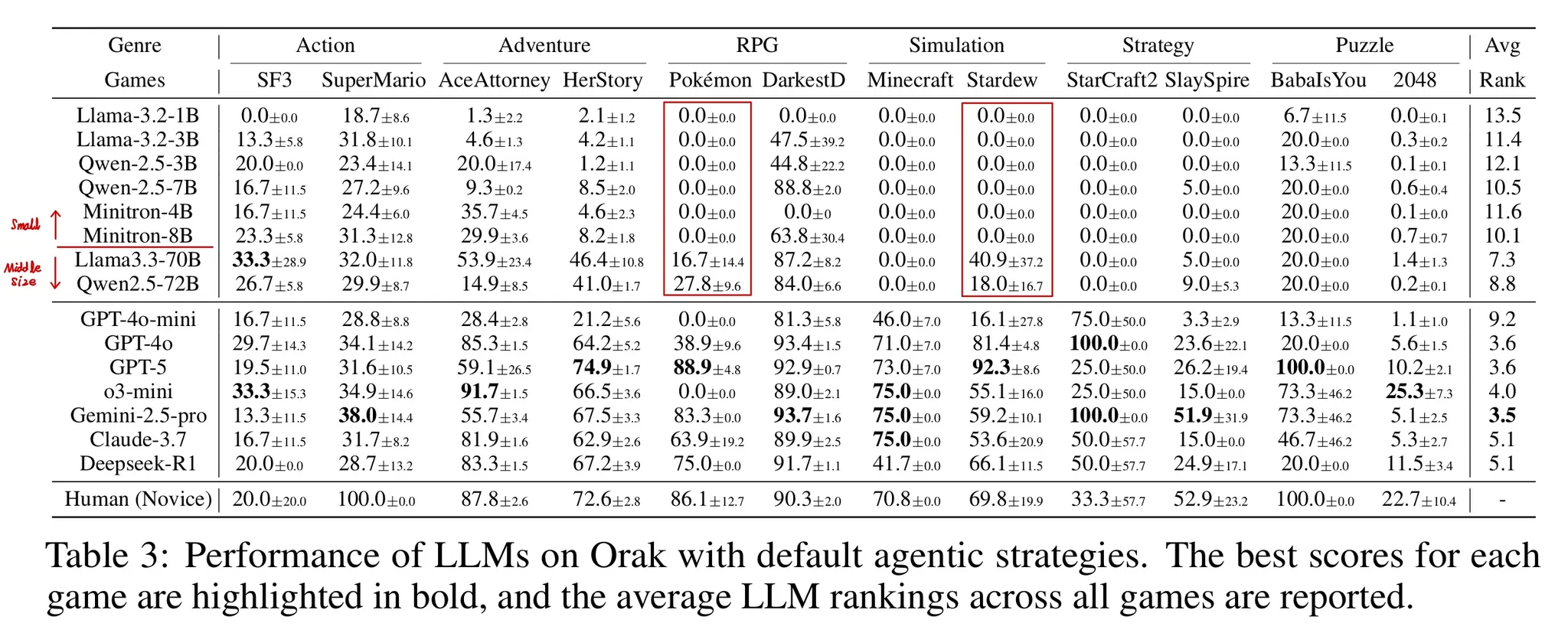
- Table 3을 보면 Closed source LLM이 월등히 뛰어난 성능을 발휘함을 알 수 있다.
- Pokemon을 보면 Small open source LLM은 0인 반면, Mid-size open source LLM에서는 성능이 개선됨을 알 수 있다.
🔷 3. LLM ARENA
- Orak 게임에서 Street Fighter III 와 StarCraft II은 두 플레이어의 대결이 가능하다.
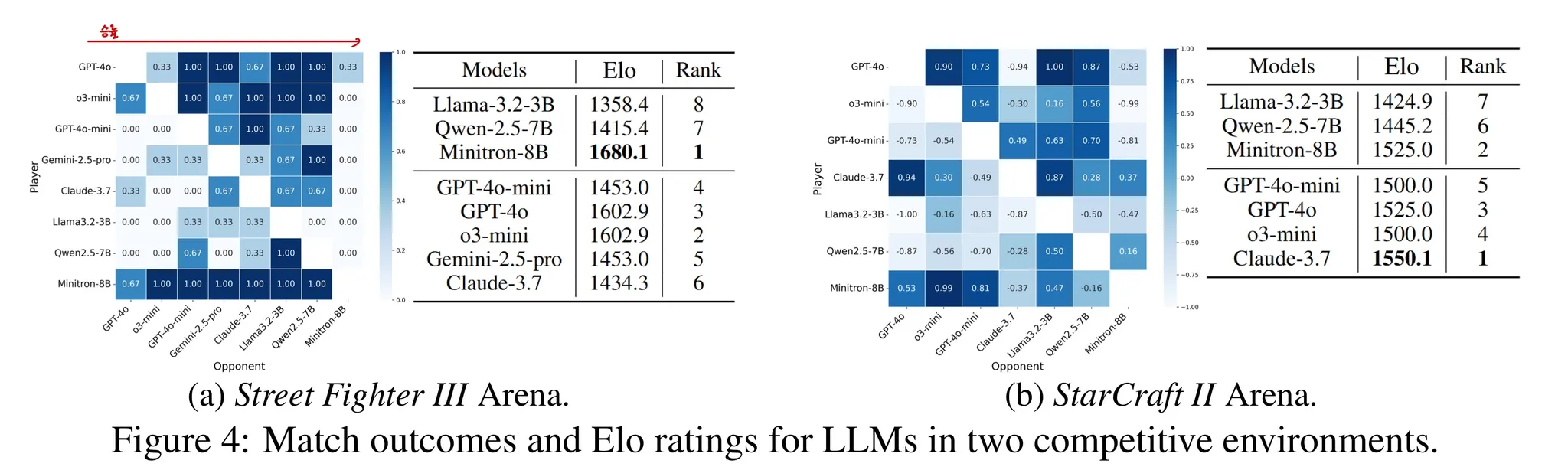
🔻 3-1. Street Fighter III
- 8개의 Zero-shot agent의 LLM을 활용하여 수행된다.
- 대결은 3전 2승제로 이루어지며, 모든 모델은
Ken이라는 동일한 캐리터로 플레이한다. - 게임은 모든 LLM들 간에 짝지어 이루어진다.
- Figure 4 (a)를 보면 Minitron-8B가 가장 뛰어난 승률을 보여준다.
- 대부분의 게임에서 Open source LLM의 성능이 낮다는 점을 생각하면 놀라운 결과이다.
🔻 3-2. StarCraft II Arena
- 7개의 LLM이 각각 짝지어 1번의 게임을 수행한다.
- 모든 LLM은
Protoss를 선택하여 플레이한다. - Figure 4 (b)를 보면 Claude-3.7이 가장 뛰어난 성능을 발휘함을 확인할 수 있다.
🔷 4. Ablation Study for Agentic Modules
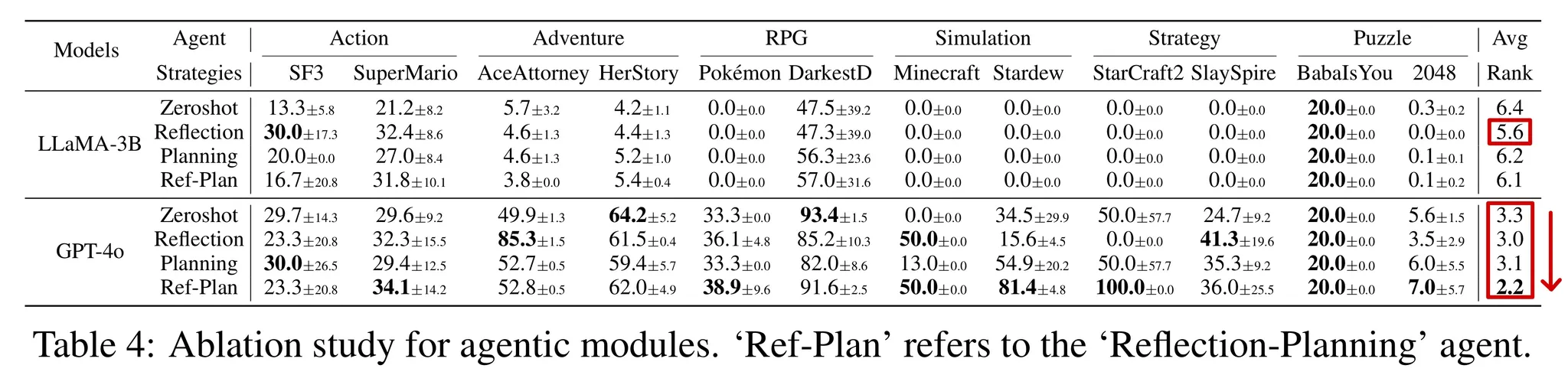
- Ablation Study에서는 각 모듈의 성능 기여도를 살펴보았다.
- GPT-4o는 모듈을 추가할 때마다 성능이 향상되는 것을 확인할 수 있다.
- LLaMA-3B의 경우 Ref-Plan 모듈보다 Reflection 모듈만 추가한 경우 더 뛰어난 성능을 발휘하였다.
- 작은 LLM은 모듈이 추가될수록 증가하는 프롬프트의 복잡성을 처리하는데 어려움을 겪는다는 것을 알 수 있다.
- 즉 최적의 Agentic Module을 찾는 전략에는 LLM의 성능 역시 고려되야 함을 시사한다.
🔷 5. Effect of Visual Input
Effect of Visual Input에서는 LLM이 전달받는 데이터의 형태(텍스트, 이미지)에 따라 어떤 성능 차이가 있는지 살펴본다.
🔻 5-1. Setup
- Group1 : 이미지(게임 화면)를 보고 LLM에게 전달되는 텍스트 정보를 모두 알 수 있는 경우 → Table 5
- Only Text, Only Image, (Text + Image) 형태로 LLM에게 정보를 전달 후 성능을 평가한다.
- Group2 : 텍스트 정보에 이미지를 통해 알 수 없는 정보가 전달되는 경우 → Table 6
- Only Text, (Text + Image) 형태로 실험을 수행한다. → Only Image에는 정보가 부족하여 제외
🔻 5-2. Result
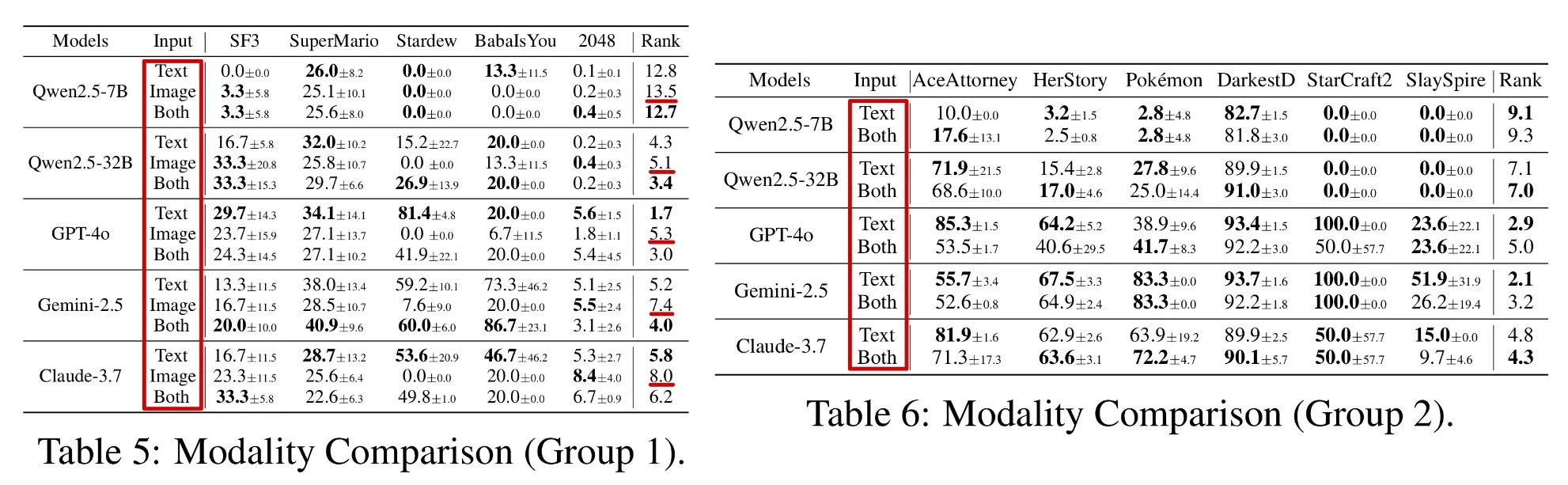
- Group1 에서 Image 데이터만 제공될 경우 모든 모델에서 성능이 하락함을 확인할 수 있다.
- Group1의 SF3(Street Fighter III)와 같이 Visual Context가 중요한 게임에서는 이미지 데이터의 추가가 긍정적인 효과로 이어졌지만, Group2와 같이 narrative 중심의 게임에서는 시각적 정보의 추가가 오히려 성능 저하를 일으키는 것을 확인할 수 있다.
🤔 인사이트
직관적으로 생각해보았을 때, 당연히 다양한 Modality의 정보가 추가되면 좋을 거라는 생각이 들지만, 실제로 이 정보가 필요한지는 실험을 통해 확인하는 작업이 중요하다.
🔷 6. Effect of Fine-tuning
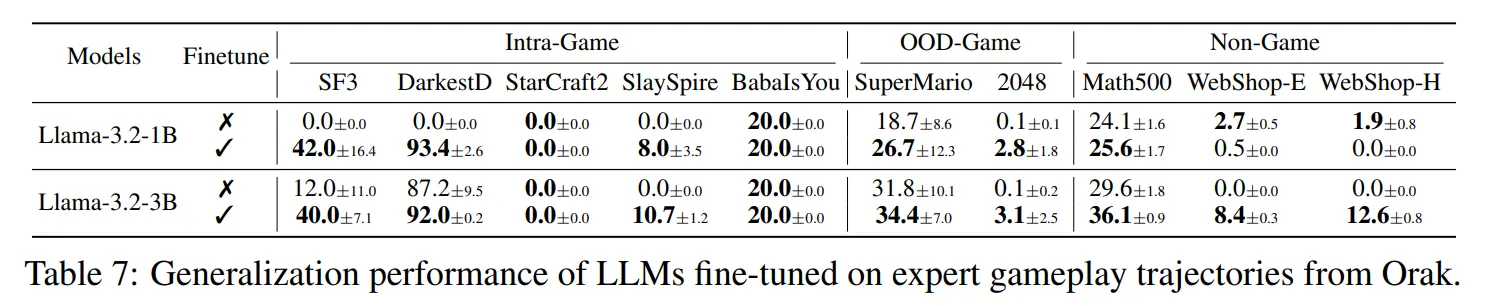
🔻 6-1. Intra-game Generalization
- Intra-game Generalization은 LLM을 특정 게임에 파인튜닝하였을 때, LLM이 해당 게임의 새로운 시나리오에서 성능 향상이 있는지 평가한다.
- Table 7을 통해 성능이 전반적으로 향상됨을 확인할 수 있다.
- DarkestD와 SlaySpire를 보면 파인튜닝을 통해 모델이 유효한 action을 생성할 수 있도록 학습한 것을 확인할 수 있다.
🔻 6-2. OOD-game Generalization
- OOD-game Generalization은 LLM이 특정 게임에 파인튜닝 되었을 때, 파인튜닝되지 않은 다른 게임에서 성능 향상이 있는지 평가한다.
- Table 7을 통해 SuperMario와 2048에서 성능이 향상됨을 확인할 수 있다.
- 이는 모델이 파인튜닝을 통해 게임 전반에 필요한 의사 결정 루틴을 학습함을 시사한다.
- 2048의 경우 Action의 형태가 유사한 2D Grid 게임인 Baba is you 게임의 구조적 유사성의 효과를 얻었다고 생각할 수 있다.
🔻 6-3. Non-game Generalization
- Non-game Generalization은 파인튜닝된 LLM이 게임과 관련이 없는 에이전트 작업에서 성능이 향상되었는지 평가한다.
- Table 7을 통해 Math 500과 Webshop에서 성능이 향상됨을 확인할 수 있다.
- Math500 : 복잡한 수학 문제 데이터셋
- WebShop : 웹 탐색 및 상품 구매를 평가하는 환경
- 파인튜닝 데이터셋이 게임 플레이와 같은 의사결정 능력을 향상시킨다고 이해할 수 있다.
6️⃣ Discussion
6장에서는 논문의 의의와 한계, 연구 방향에 대해 설명한다.
🔷 1. Conclusion
- Orak은 다양한 게임에 필요한 종합적인 능력을 평가할 수 있도록 한다.
- Orak은 Plug and Play 인터페이스를 통해 다양한 LLM, 다양한 모듈을 바꿔가며 일관된 평가를 할 수 있도록 한다.
- Orak의 파인튜닝 데이터셋을 통해 사전 학습된 LLM을 특정 게임에 학습할 수 있다.
🔷 2. Limitations
- Orak은 게임 상태를 그대로 전달하지 않고 구조화된 형태로 전처리한다.
- 게임에 불필요한 정보는 제거한다.
- 따라서 향후에는 게임 상태에 대한 전처리 없이 LLM에게 전달할 수 있는 방향으로 연구할 예정이다.
7️⃣ 내 생각
사실 VLM 모델에 대한 논문이길 기대했는데 LLM만 적용했다는 점이 아쉬웠다. 하지만 파인튜닝 데이터를 통해 유사한 게임 환경에서 모델 성능을 향상시킬 수 있다는 아이디어를 얻은 것 같다. 이 부분은 조금 더 깊게 파보면 좋을 것 같다는 생각이 들었다. 그 외에도 Appendix에 디테일한 설명이 있어서 좋았다. 논문과 별개로 연구실 서버에서 코드 실행을 위해서는 GUI가 필수였는데 이 부분은 최근에 잘 해결할 수 있어서 다행이었던 것 같다. 논문이 외국이 아닌 한국에서 작성되었다는 점이 가장 놀라웠다. 역시 게임 강국! 아직까지 파인튜닝 데이터셋은 공개되지 않아서 빨리 공개되면 더 좋을 것 같다.
