🎢 FlashAdventure: A Benchmark for GUI Agents Solving Full Story Arcs in Diverse Adventure Games
🔗 논문: https://arxiv.org/abs/2509.01052
💻 GitHub : FlashAdventure: A Benchmark for GUI Agents Solving Full Story Arcs in Diverse Adventure Games
🧐 학회: EMNLP 2025 submitted
✏️ 논문 정리
1. 이 논문을 읽는 이유가 무엇인가요?
⇒ 현재 분석 중인 Orak 논문을 인용하고 있는 논문이라 살펴보았다. Orak과 Flash 모두 KRAFTON이 논문 작성에 참여한 것을 보아 논문을 같이 작성했다는 생각도 들었다.
2. 논문 제목의 의미는 무엇인가요?
⇒ 다양한 이야기 구성 어드벤쳐 게임으로 구성된 벤치마크 FlashAdventure를 통해 GUI Agent의 성능을 평가하는 논문이다. 제목에는 나와있지 않지만 FlashAdventure 외에도 CUA as a Judge, COAST와 같은 아이디어가 담겨있다.
3. 논문의 등장배경은 무엇인가요?
⇒ 논문은 GUI 모델의 성능, 그 중에서도 Full story arc game에서의 성능을 평가하기 위해 등장하였다. 하지만 기존의 벤치마크들은 game의 다양성이 부족하거나, Full story adventrue 게임이 아니거나, 너무 짧은 등 한계가 존재했다. 그래서 논문에서는 34개의 다양한 게임을 통해 GUI Agent의 성능을 평가하기 위한 벤치마크를 구축하였다.
4. 논문을 1~2줄로 요약하세요
⇒ 논문은 Observation Behavior Gap 문제에 주안점을 두고 있다. GUI Agent의 Observation Behavior Gap 해결 능력을 평가하기 위해 단서 발견시점과 사용시점의 간극이 큰 벤치마크 FlashAdventure를 구축하였고, 자동 평가 방식 CUA as a Judge도 제안하였다. 또 Observation Behavior Gap를 해결하기 위해 COAST라는 Agentic 프레임워크를 제안한다.
📄 Abstract
🔷 디지털 세상으로 확장 중인 LLM
- 현재 LLM을 활용한 GUI 에이전트들이 다양한 디지털 환경과 상호작용 중이다.
- 비디오 게임, 그 중에서도 복잡하고 서사 중심의 어드벤쳐 게임은 GUI 에이전트의 성능 평가에 많이 활용된다.
🔷 현재 벤치마크의 한계
- 하지만 기존 벤치마크는 다양성이 부족하며, 전체 게임 스토리를 완료하는 능력을 평가하는 부분이 부족하다.
🔷 벤치마크 Flash Adventure 제안
- 이러한 한계를 극복하기 위해 34개의 플래시 기반 어드벤처 게임으로 구성된 벤치마크, FlashAdventure를 제안한다.
- FlashAdventure는 게임 중 얻은 단서를 오랫동안 기억한 후 게임 후반부에 활용하는, 관측 결과와 행동의 간극이 있는 Observation behavior gap을 처리할 수 있는 능력을 평가하는데 초점이 맞춰져 있다.
🔷 그 외에 다른 아이디어 2가지 제안
- CUA as a Judge : LLM을 활용하여 게임을 자동으로 평가한다.
- COAST : 장기 단서 기억을 통해 더 앞서 정의한 Observation behavior gap을 해결할 수 있는 에이전틱 프레임워크이다.
🔷 실험도 해 보았더니!?
- 평가 결과 현재 많은 GUI 모델들은 이야기 중심의 Task에 어려움을 겪는다.
- COAST가 Observation behavior gap 문제를 해소하여 이러한 문제를 완화하였다.
- 하지만 여전히 사람과 비교하면 성능이 많이 뒤떨어진다.
🧐 논문 살펴보기
🔷 Q1. GUI agent를 왜 Video 게임에서 평가하지?
-
현재 LLM은 디지털 환경과 상호작용하는 방향으로 발전 중이다.
-
Graphic User Interface (GUI) agent와 Computer Using Agent(CUA)가 대표적이다.
-
Video 게임은 계속해서 환경이 변하고 복잡한 task를 요구하기 때문에 GUI Agent의 성능을 평가하기 좋다.
-
예를 들어, 웹페이지에서 GUI를 평가할 때는 웹페이지가 정적이지만, 게임 환경에서는 계속해서 시각적 환경이 변하고, 다양한 대화, 도구, 섬세한 행동 등을 처리할 수 있는 능력을 평가할 수 있다.
🔷 Q2. 논문에서 GUI agent의 능력 중 조금 더 주목한 능력이 있나?
-
게임은 시나리오 중심의 맥락 이해가 중요한 장르도 있고, 스트리트 파이터처럼 순간순간의 판단 능력이 중요한 경우도 있다.
-
논문에서는 다양한 task를 처리하고, 이야기 중심의 게임을 처리할 수 있는 능력에 초점을 맞춘 것 같다.
-
그리고 현재 GUI Agent는 이러한 능력이 부족하다는 점에 주목한다.
🔷 Q3. 이러한 능력은 어떻게 평가하지?


-
논문에서는 34개의 Adventure 게임을 통해 FlashAdventure 벤치마크를 설계하여, GUI 모델의 이야기 중심 게임 수행 능력을 평가한다.
-
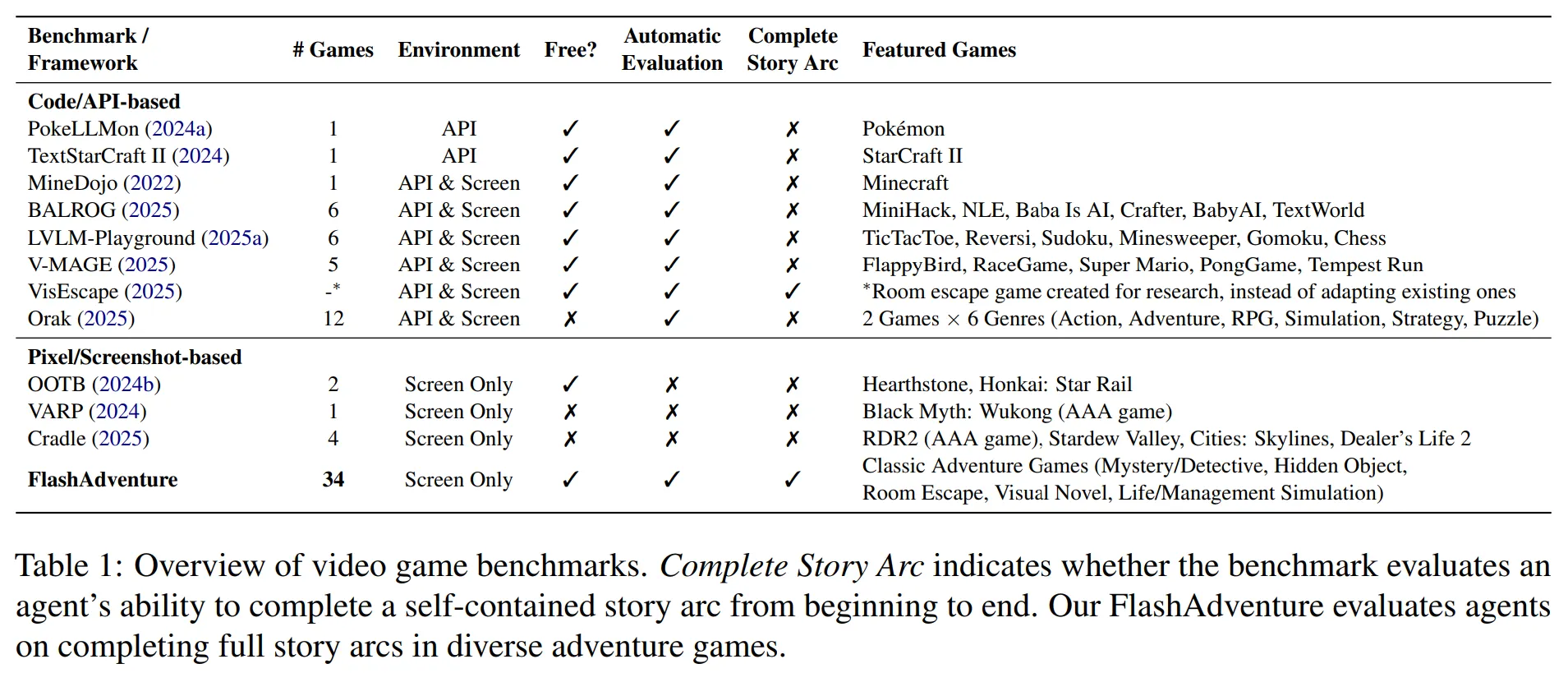
Table 6은 34개의 게임을 6개의 장르로 구분한다.
-
게임을 선정할 때는 아래의 3가지 기준을 따랐다.
-
다양한 장르를 다루는 무료 게임이어야 한다.
-
제한된 시간이나 빠른 행동을 요구하지 않고, 추론에 집중하는 게임이어야 한다.
-
이야기 중심이며 중간 목표가 명확하게 정의되어 있어야 한다.
-
🔷 Q4. 그런데 기존의 벤치마크로 평가하면 안되나?
-
기존의 벤치마크는 게임의 다양성이 부족한 경우가 많다.
-
또 자동으로 평가하지 못하여 사람이 평가해야 하는 벤치마크도 있고, 이야기 중심이 아닌 경우가 많다.
-
Vis-Escape의 경우 다양한 자동 평가도 가능하고 이야기 중심이지만 너무 짧다는 한계가 존재한다.
🔷 Q5. 그렇다면 FlashAdventure의 특징이 뭐지?
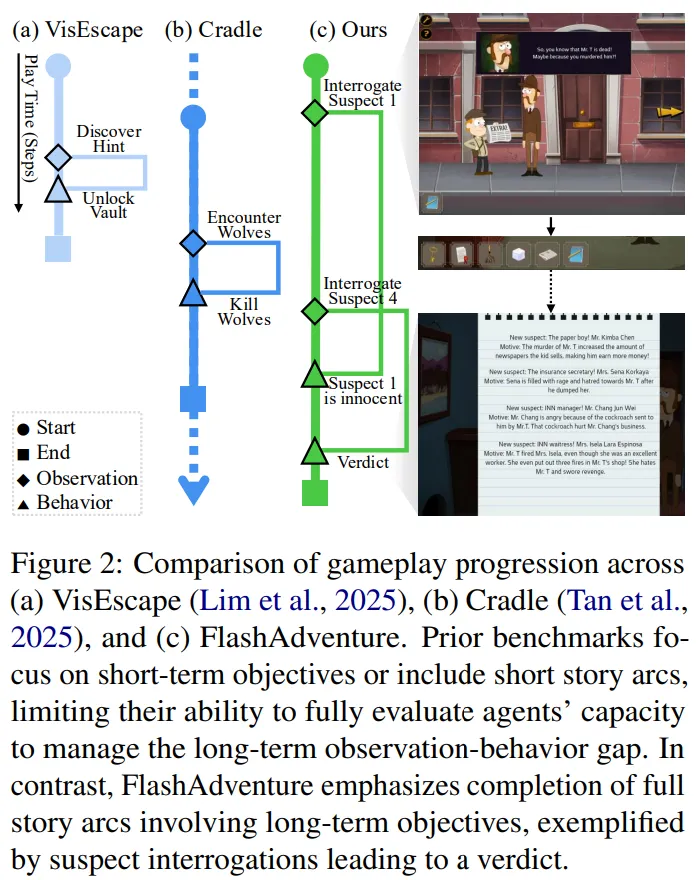
🔻 A1. Milestone 즉 게임의 중간 목표를 설정하여, 게임 과정을 평가합니다.
- 중간 목표는 논문의 저자들이 서로 논의하여 결정하였으며, 논문의 Appendix를 보면 확인할 수 있다.
🔻 A2. Agent에게 Observation behavior gap를 처리할 능력을 요구합니다.
-
FlashAdventure는 다른 벤치마크와 달리 단서를 발견한 시점과 단서를 사용하는 시점 간의 간극이 크다.
-
모델은 이러한 간극 속에서도 이전에 발견한 단서를 활용하여 문제를 해결할 수 있어야 한다.
🔻 A3. 자동으로 게임 과정 평가가 가능하다.
-
FlashAdventure는 Milestone을 통해 단순히 게임 성공, 실패를 넘어서 게임을 어느 정도 진행하였는지 평가가 가능하다.
-
그리고 논문의 핵심 아이디어 중 하나인 CUA as a Judge를 통해 자동 평가를 수행한다.
🔷 Q6. CUA as a Judge는 어떻게 자동 평가를 가능하게 하지?
-
CUA as a Judge의 CUA는 Computer Using Agent의 약자이다.
-
GUI를 통해 평가한다고 이해하면 된다.
🔻 A1. CUA as a Judge는 LLM 모델을 활용하여 평가하는 방식이다.
- 논문에서는 Claude-3.7-Sonnet computer-use 모델을 활용하였다.
🔻 A2. CUA as a Judge는 직접 GUI를 조작하여 스크린을 보고 평가한다.

-
CUA as a Judge는 게임 로그가 아닌, 실제 게임 화면을 조작하여 점수나 인벤토리 상태 등 게임 상태를 확인하여 평가한다.
-
평가는 Milestone, 즉 중간 목표가 달성되었는지 확인하는 방식으로 진행된다.
-
Figure 11을 보면 CUA as a Judge가 직접 GUI를 조작하여 중간 목표 달성 여부를 확인하는 것을 볼 수 있다.
🔻 A3. 추가로 CUA as a Judge를 신뢰할 수 있을지에 대한 검토도 이루어졌다.
-
CUA as a Judge의 정확도는 94% 이며, 인간 평가와의 피어슨 상관계수는 0.9999를 보였다.
-
물론 한번에 여러 요소를 평가해야 하는 Milestone에서는 성능이 떨어진다는 한계도 존재한다.
🔷 Q7. FlashAdventure 벤치마크와 CUA as a Judge 외에도 논문에서 제안하는 것이 있나?
-
논문에서는 GUI Agent가 Observation behavior gap 문제를 잘 처리하지 못한다는 한계에 집중한다.
-
이를 해결하기 위해 COAST라는 에이전틱 프레임워크를 제안한다.
🔷 Q8. COAST가 뭔가요?
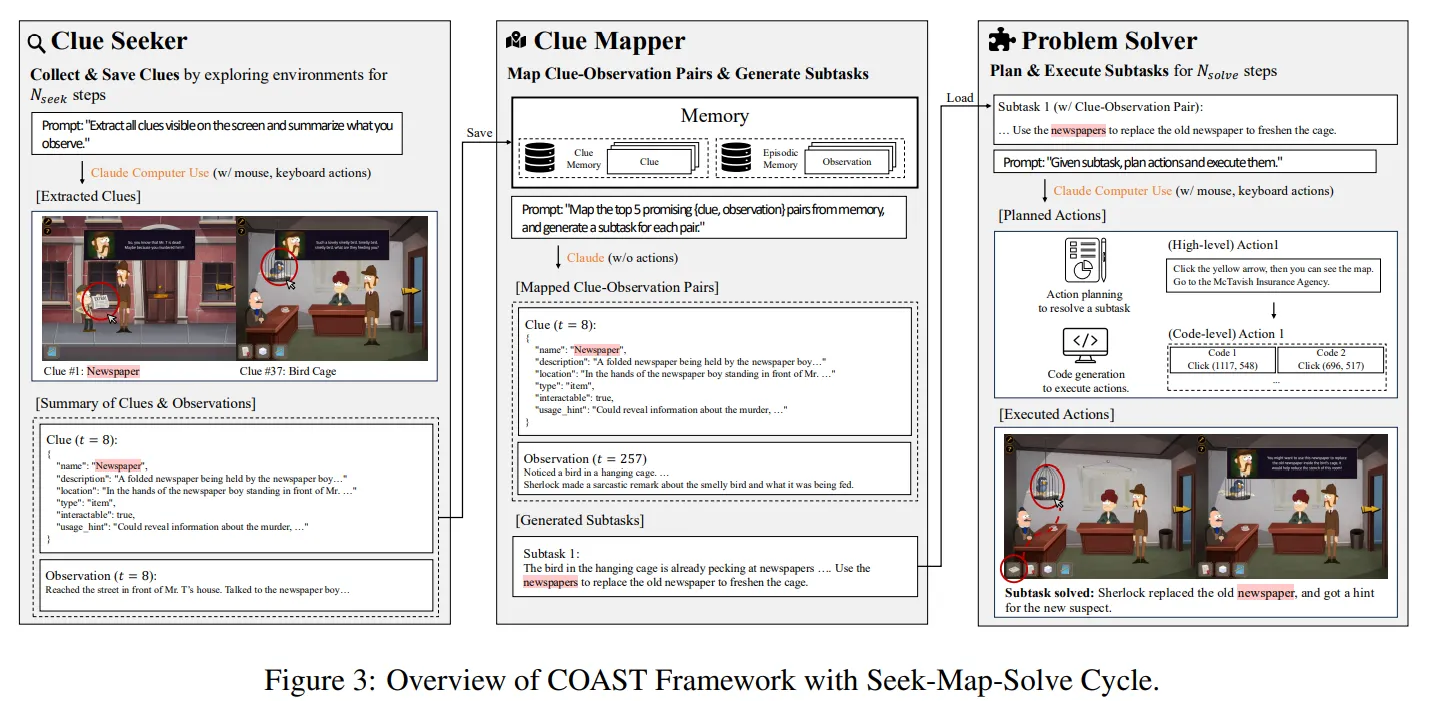
🔻 A1. COAST는 단서에 대한 기억을 잘 활용할 수 있도록 설계된 프레임워크이다.
-
COAST는 Clue Oriented Agent for Sequential Tasks의 약자이다.
-
COAST는 단서를 찾는 Clue Seeking 단계, 단서를 통해 가설을 세워 Task를 설계하는 Clue-Observation Mapping 단계, 설계된 Task를 수행하는 Problem Solving 단계로 이루어진다.
🔻 A1-1. Clue Seeking
-
Clue Seeking 단계에서는 Clue Seeker라는 모듈이 정해진 step 동안 단서를 수집한다.
-
이 과정 동안에는 문제를 직접적으로 해결하는데 집중하기 보다는, 단서를 찾는 것에 집중한다.
-
발견한 모든 정보는 memory 에 저장된다.
🔻 A1-2. Clue Observation Mapping
-
Clue Observation Mapping 단계에서는 단서를 통해 시험해볼 만한 목표를 설계한다.
-
이때 단서에만 집중하지 않고, ⭐모델이 지금까지 수행해왔던 Trajectory 를 함께 참고하여 목표를 설계⭐한다.
-
설계된 목표는 goal candidate set 에 저장된다.
🤔 COAST의 핵심은 Clue Observation Mapping?
-
사실 COAST의 아이디어를 본 순간 예전에 읽었던 EscapeBench 논문이 떠올랐다.
-
EscapeBench에서도
Reflection Module을 통해 해야할 Task를 수집하고,Foresight Module을 통해 시험해볼 만한 가설을 만들어 실행해보는 과정이 있다. -
물론 완전히 동일하지는 않겠지만, COAST는 이 아이디어에 Clue Observation Mapping 단계, 그 중에서도 Trajectory 를 활용한다는 점이 조금 더 개선된 아이디어인 것 같다.
-
그래서 이후의 Ablation Study에서도 Clue Observation Mapping의 성능 향상에 집중해서 살펴보았다.
📃 논문리뷰 : [논문리뷰] EscapeBench: Towards Advancing Creative Intelligence of Language Model Agents
🔻 A1-3. Problem Solving
-
Problem Solving 단계에서는 설계된 목표를 정해진 step 동안 여러 방식으로 수행해본다.
-
성공한 목표는 resolved set 에 저장된다.

- 구체적인 Pseudo 코드도 제시하였는데 한번 읽어보면 프로세스를 이해하는 데 도움이 된다.
🔷 Q9. FlashAdventure를 통해 GUI 모델을 평가하여 어떤 결과를 얻었지?
🔻 A1. FlashAdventure를 통해 7개의 GUI 모델을 평가하여 아래의 패턴을 발견하였다.
-
Weak planning capability
-
모델이 동일한 장소를 계속 가거나 똑같은 행동을 반복하는 현상을 관측하였다.
-
이는 모델이 관측한 사실을 적절한 행동으로 연결하는 능력이 부족하다고 정리할 수 있다.
-
저자는 이러한 행동의 근본적인 원인을 메모리 문제와 계획 능력이 부족이라고 판단했다.
-
-
Poor visual perception
- GUI Agent는 복잡한 형태의 이미지를 처리하는데 어려움을 겪었다.
-
Deficient Lateral thinking
-
GUI Agent는 유연하게 사고하는 데 어려움을 겪었다.
-
예를 들어 방 탈출 게임에서는 방을 탈출하기 위해 단서를 찾는 것에 집중해야 하는데, 계속해서 탈출이라는 목표만 생각하여 문 근처에서만 행동하는 모습을 보였다.
-
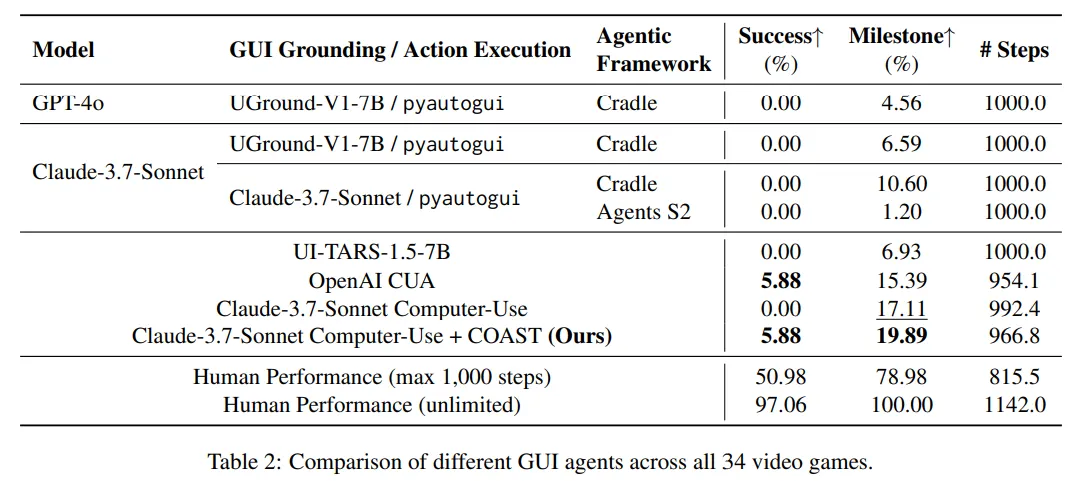
🔻 A2. COAST 프레임워크를 위 문제를 일부 해결할 수 있었다.
-
COAST 모듈은 단서를 찾는 것에 집중하는 Clue Seeking 단계와 중간 목표를 설계하는 Clue-Observation Mapping 단계를 통해 planning 능력과 Lateral thinking 능력을 향상시킬 수 있었다.
-
Table 2를 통해 COAST를 적용하였을 때 성공률은 5.88%, Milestone을 성공한 비율은 19.89%로 성능이 향상된 것을 확인할 수 있다.
-
하지만 visual perception은 계획 능력보다는 Backbone LLM의 성능에 좌우되는 경향이 있어 성능 개선이 미미하였다.
-
또한 사람과 비교하면 아직 개선할 부분이 많은 것 같다.
🔻 A3. Ablation Study를 통해 COAST 각 단계의 필요성도 확인해보았다.
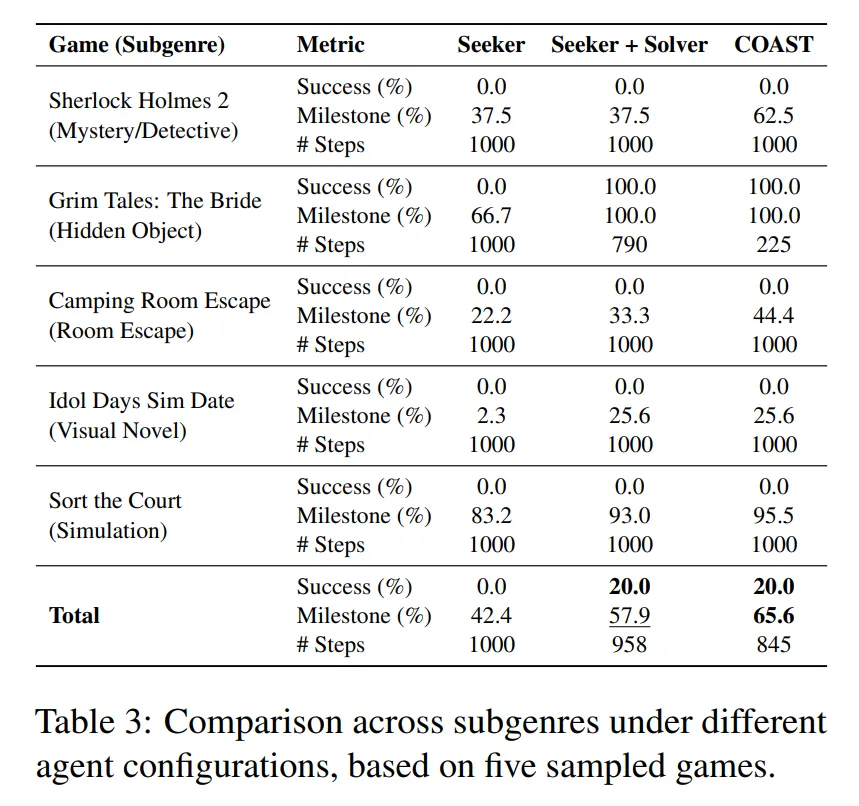
- Table 3을 보면 어떤 한가지 단계에 성능이 의존하기 보다는 모든 단계가 필요하다는 것을 알 수 있다.
🤔 Table 3에 대한 개인적인 생각
-
Seeker 단계가 적용되지 않은 baseline도 보여주면 단서를 수집하는 것의 기여도를 확인할 수 있을 것 같다.
-
개인적으로 Clue Observation Mapping이 이 논문의 차별점이라고 생각했는데, Table 3은 Clue Observation Mapping의 기여도를 확인하기에는 애매한 것 같다.
🔷 Q10. 이 논문에 대해 정리하자면?
-
논문은 34개의 Flash Adventure 게임으로 구성된 FlashAdventure 벤치마크를 제안한다.
-
FlashAdventure를 통해 GUI Agent의 전체 이야기 게임을 수행하는 능력을 평가하였다.
-
FlashAdventure는 CUA as a Judge를 통해 Milestone에 대한 자동평가를 할 수 있다.
-
논문은 Observation behavior gap에 초점을 맞추었으며, FlashAdventure 역시 이를 고려하여 설계되었다.
-
또한 Observation behavior gap을 해결하기 위해 COAST라는 에이전틱 프레임워크를 제안하였다.
🧐 논문을 읽은 후
FlashAdventure는 Orak과 달리 스크린샷 이미지를 통해 모델이 추론을 하도록 설계한 점이 조금 더 멀티모달스러워서 좋았다. 논문에서는 예전에 읽었던 지금 살펴보고 있는 Orak 논문의 문제점에 대해서 언급해준 점 역시 좋았다. Appendix를 조금 더 자세히 살펴보면 연구자로써 배울 부분도 있는 것 같아 그 부분이 좋았고, Pseudo code를 통해 핵심 알고리즘을 명확하게 제시해줘서 이해하기 편했다. 방탈출 게임을 포함해서 현재의 GUI 모델이 아직 많은 개선이 필요하다는 점을 다시 확인할 수 있었다. 사실 논문 정리 방식이 처음 시도해본 방식이라 글이 다소 산만했다. 솔직히 다시는 이 방식으로 정리하고 싶지는 않다.
