
[Dacon] 데이콘 월간 데이콘 KOSPI 기반 분석 시각화 경진대회
안녕하세요, KOSPI 기반 분석 시각화 경진대회에 참여하게 되었습니다. 주식에 대해 배경 지식이 없어서, 좋은 결과를 얻진 못했지만 (12등/15등) 좋은 경험이라고 생각합니다. 금융 도메인을 쌓은 뒤에 다시 시각화 대회에 참여할 예정입니다.
1. 데이터 둘러보기.
1-1. 칼럼 설명
- Date : 1981.05.01 ~ 2022.08.31 까지의 날짜
- Close : 종가 (종료 시 가격)
- Open : 시가 (시작 시 가격)
- High : 고가 (가장 높은 가격)
- Low : 저가 (가장 낮은 가격)
- Volume : 거래량 (매매된 주식의 수 (ex) 주)
- Change : 등락률 (전일대비 등락률, 일정한 기간에 어떠한 기준 값이 오르거나 내리는 비율 - 음수이면 전일대비 떨어진 것이고, 양수이면 전일대비 오른 것이다.)
(cf) 등락률 = (현재 종가 - 전일 종가) / 전일 종가, 전월비(%) = 등락률 x 100
df에 주어진 데이터 프레임을 불러오고, 원본 데이터를 보존하기 위하여 copy를 이용하여 복제해서 df_copy에 넣어주었습니다.
결측치는 아예 없었고, 날짜도 겹치는 날짜가 아예 없었습니다.
1-2. 범주형 변수 vs 수치형 변수
- [범주형 변수] : Date - 범주를 나눠서 그래프를 그릴 수 있습니다.
- [수치형 변수] : Close, Open, High, Low, Volumn, Change - 통계적 수치를 이용하여 그래프를 그릴 수 있습니다.
데이터의 개수는 77168 개 입니다.
데이터의 결측치의 개수는 0 개 입니다.
2. 데이터 정비하기.
2-1. 칼럼을 모두 소문자로 변경하기.
칼럼을 모두 소문자로 통일하는 것이 데이터 분석 시에 더 편리합니다.
2-2. 전월비 칼럼 생성하기.
전월비 = 등락률 x 100
전월비 칼럼을 monthly_ratio 라고 지정해주었습니다.
2-3. date 칼럼을 datetime으로 변경해주고, 쪼개주기.
date 칼럼을 datetime으로 변경해주고, 데이터 분석을 더 꼼꼼하게 하기 위하여 연도, 월, 일, 요일로 쪼개주었습니다.
2-4. 전일 종가 칼럼을 만들어서, 원래 칼럼에 넣어주기.
등락률 = (현재 종가 - 전일 종가) / 전일 종가
전일 종가 = 현재 종가 / (등락률 + 1)
pd_close에 전일 종가를 넣어주었습니다.
2-5. 전날 날짜 구하기.
from datetime import timedelta datetime에서 timedelta를 이용하여 전날 날짜를 구할 수 있습니다. 그래서 yesterday 칼럼을 만들어서 전날 날짜를 넣어주었습니다.
3. 데이터 전처리 (EDA)와 시각화하기.
3-1. 날짜 별, 연도 별 분포 알아보기.
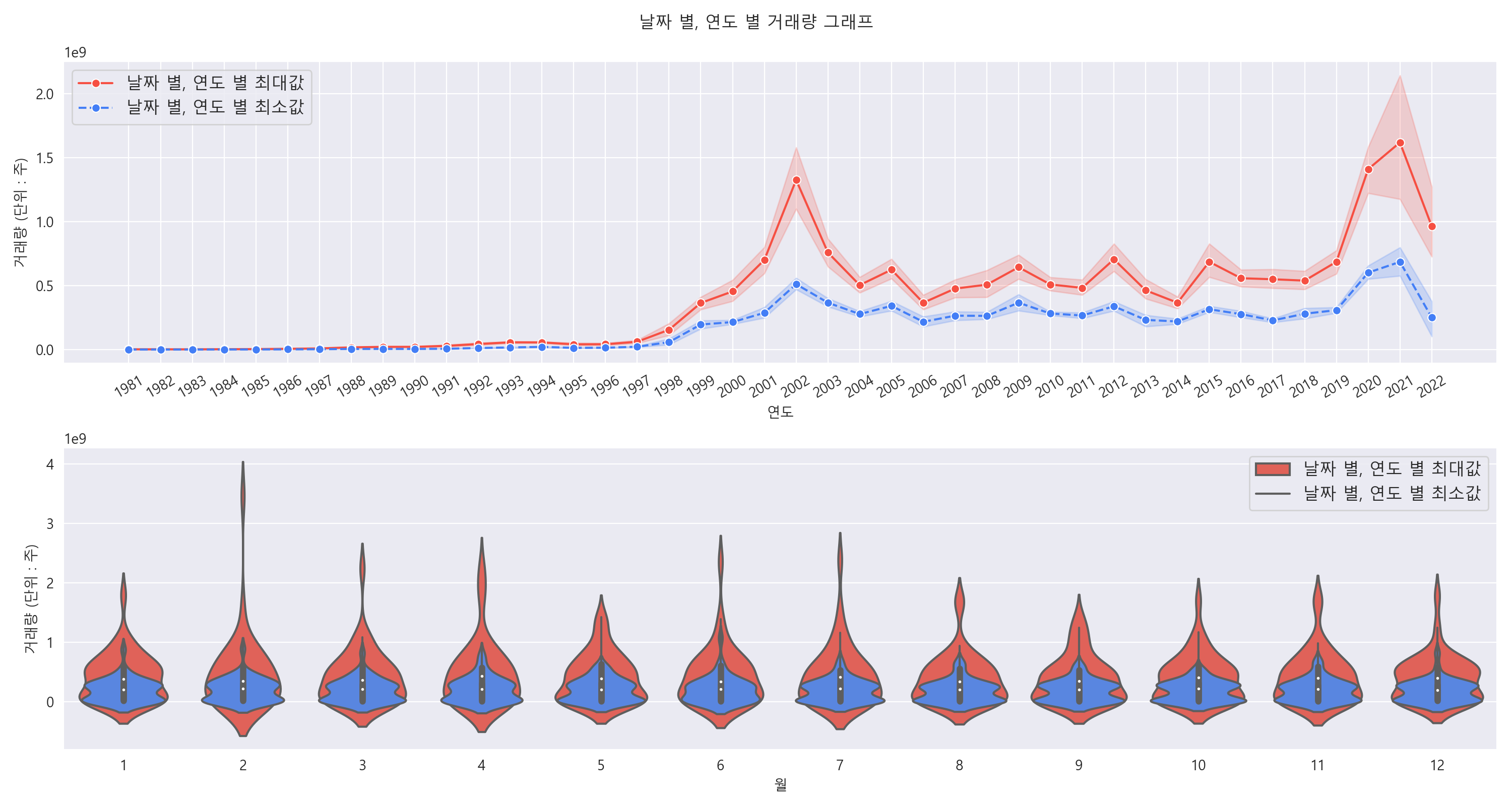
거래량이 가장 많은 달은 거래량 분포 범위가 4e^9 주까지도 분포합니다. 대부분 최대 거래량 분포 범위가 2e^9 주 언저리까지 분포합니다. 그리고 최소 거래량은 0 주 ~ e^9 주 사이에 가장 많이 분포되어 있음을 알 수 있습니다. 최소 거래량인 달은 0 주 근처에 가장 많이 분포되어 있음을 알 수 있습니다. 그리고 최대 거래량일 때와는 거래량 분포 범위도 많이 차이가 남을 알 수 있습니다. 최대 거래량은 0 ~ e^9 주 사이에서 많이 분포되어 있음을 알 수 있습니다.
연도 별로 확인해보면, 1981년 ~ 1997년 까지는 연도 별 최대 거래량과 최소 거래량이 비슷함을 알 수 있습니다. 하지만 1998년부터 차이가 나기 시작하였고, 2002년과 2021년에 가장 차이가 크게 나타났습니다. 그리고 전체적으로 증가하는 경향을 띄고 있습니다.
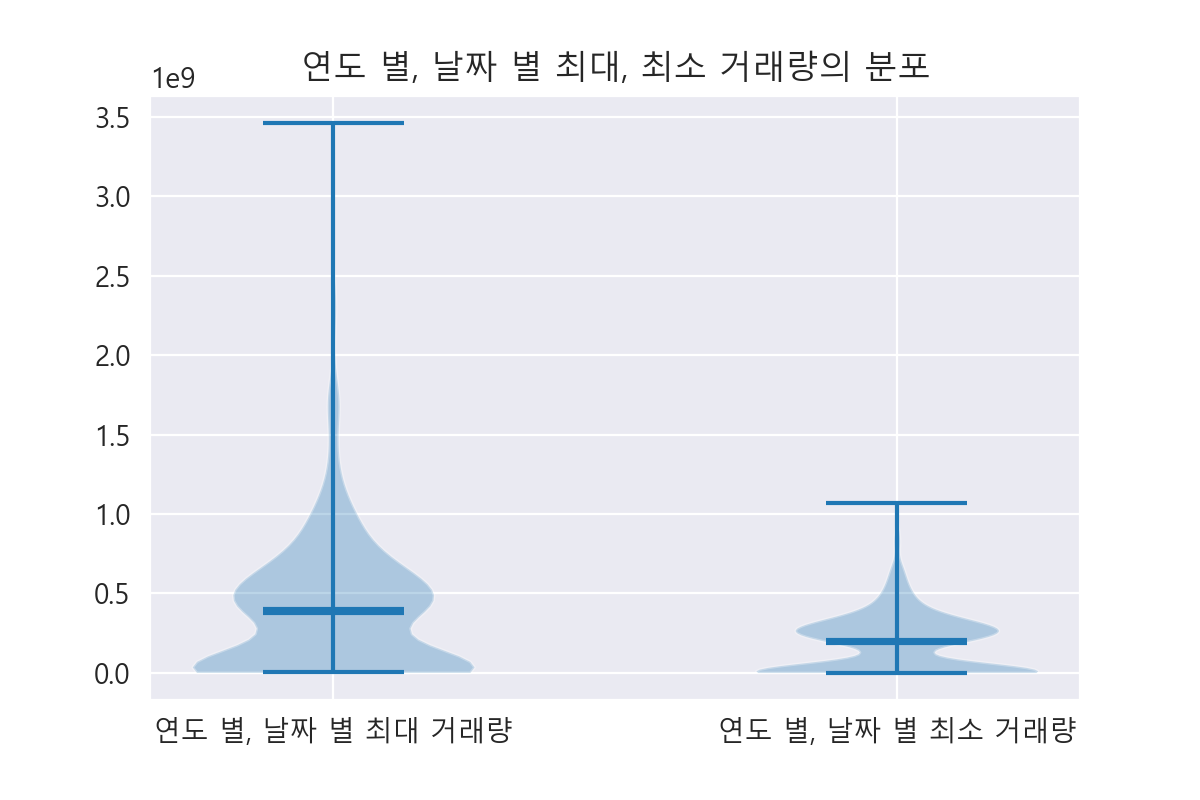
df_min, df_max를 연도, 월로 나누지 않고 전반적으로 바라보는 경우
- 최대 거래량의 분포는 0에서 가장 많았고, 그 다음으로 0.5에서 많았습니다. 거래량은 0 ~ 3.5e^9 주까지 분포합니다.
- 최소 거래량의 분포는 0에서 가장 많았고, 그 다음으로 0 ~ 0.5에서 많았습니다. 거래량은 0 ~ e^9 주 언저리까지 분포합니다.
거래량이 많은 순서대로 상위 10개를 살펴보니, 2021년과 2002년이 많았습니다. 2021년과 2002년에 어떤 일이 일어났었는지 알아봐야 합니다.
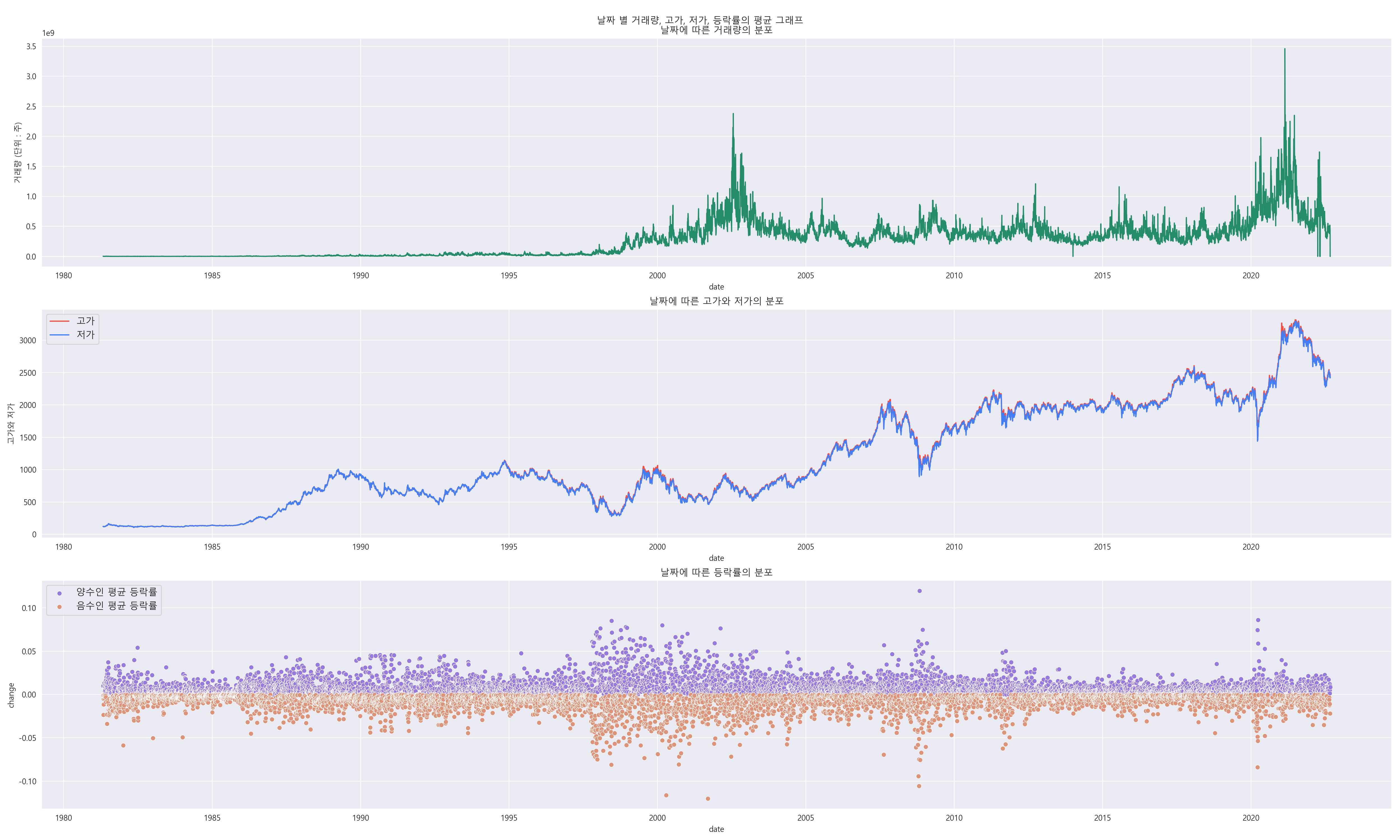
대체적으로 고가와 저가는 같이 증가하는 추세를 보이고 있습니다. 그리고 거래량은 2002년과 2021년에 급격하게 증가하였습니다. 하지만 계속 증가하는 추세를 띄고 있지는 않습니다. 마지막 그래프는 등략률의 양수와 음수를 나누어서 평균의 분포를 알아보았습니다. 등락률의 평균의 차이가 큰 부분들은 전년도에 비해 변화한 정도의 평균을 의미하고 있습니다. 즉, 평균 변화가 큰 지점을 의미합니다. 그리고 등락률의 차이가 큰 지점과 거래량이 큰 지점이 동일하지는 않습니다. (등락률과 거래량의 관계가 있다고 볼 수 없습니다.)
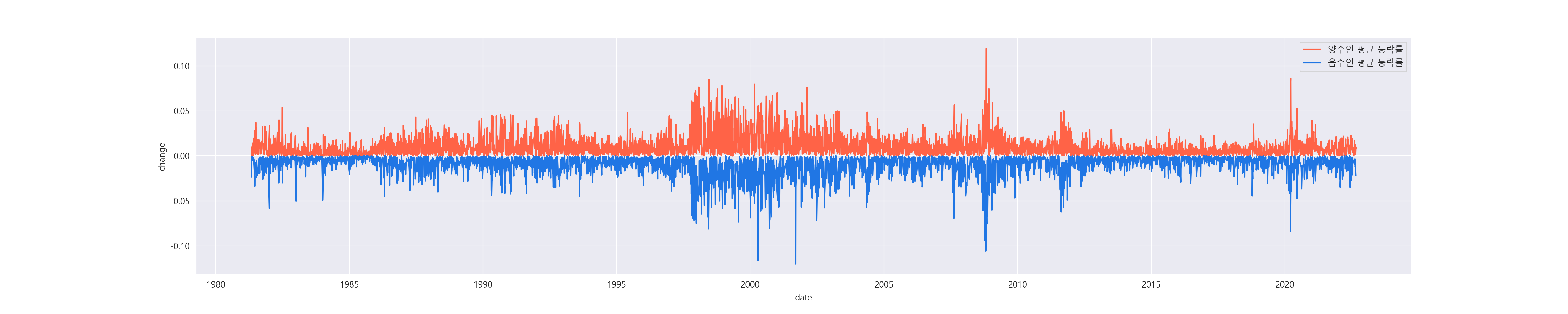
양수인 평균 등락률이 큰 상위 3개의 지점은 2008년 10월, 2020년 3월, 그리고 1998년 6월 입니다.
3-2. 상관계수를 통한 상관관계 그래프 알아보기.

- 완벽한 정비례 관계 & 연관성이 큼 : 자기 자신과의 관계가 1이기 때문에, 상관계수가 1이면 완벽한 정비례 관계를 의미합니다.
- close ~ open
- close ~ high
- close ~ low
- open ~ high
- open ~ low
- high ~ low
- change ~ monthly_ratio
- close ~ pd_close
- open ~ pd_close
- high ~ pd_close
- low ~ pd_close
- 정비례 관계 : 상관계수가 양수이기 때문에, 연관성이 꽤 있는 편입니다.
- year ~ pd_close
- close ~ year
- open ~ year
- high ~ year
- low ~ year
- 반비례 관계 : 상관계수가 음수이기 때문에, 연관성이 꽤 약한 편입니다.
- open ~ month
- close ~ month
- high ~ month
- low ~ month
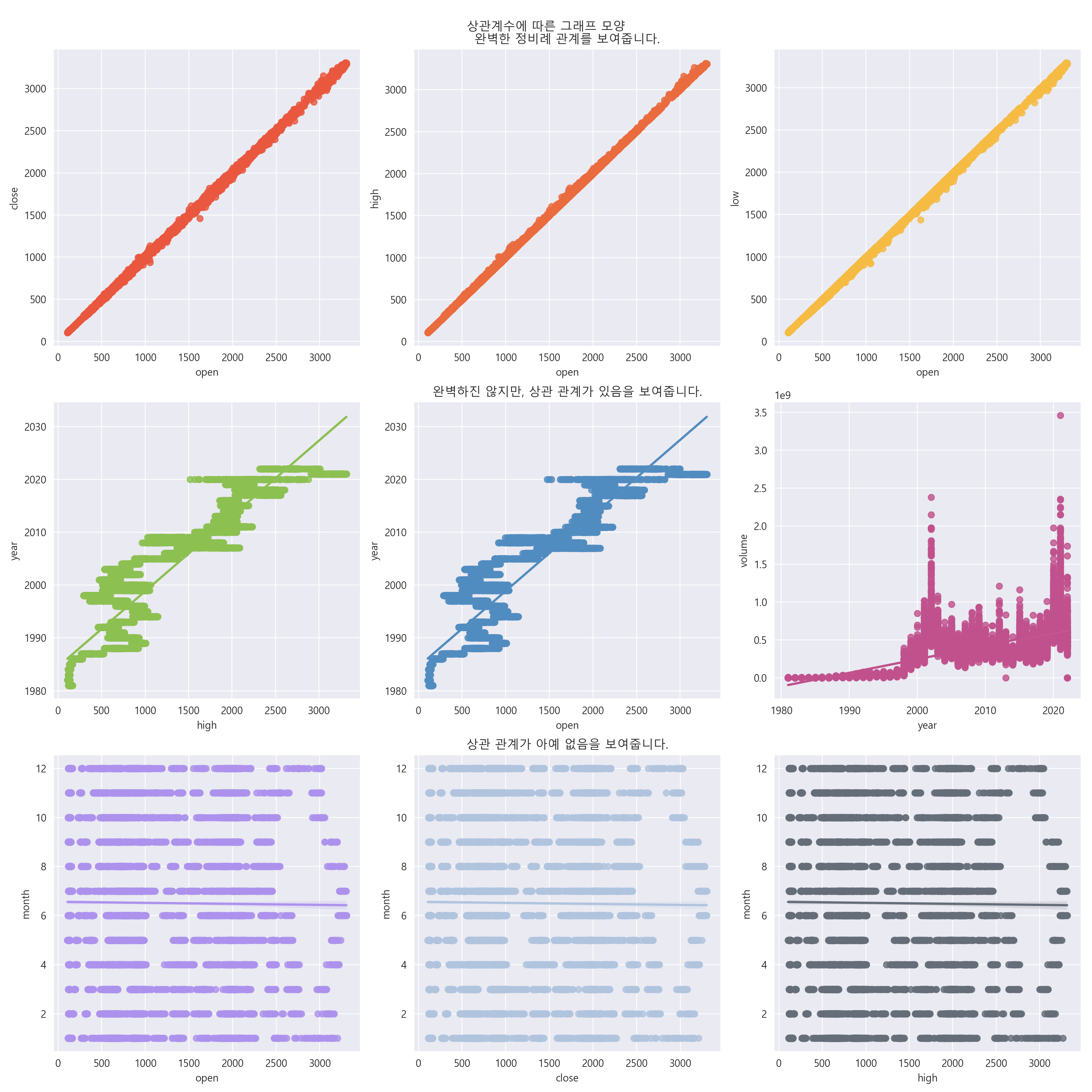
- 완벽한 상관 관계 : 상관 계수가 1임을 의미하고, 완벽한 정비례를 보여줍니다.
- 상관 관계가 있는 관계 : 완벽한 정비례는 아니지만, 선 근처에 데이터가 존재함을 알 수 있습니다.
- 상관 관계가 아예 없는 관계 : 선 근처에 데이터가 존재하지 않음을 알 수 있습니다.
3-3. 연도 별 양수 등락률과 음수 등락률의 분포 알아보기.
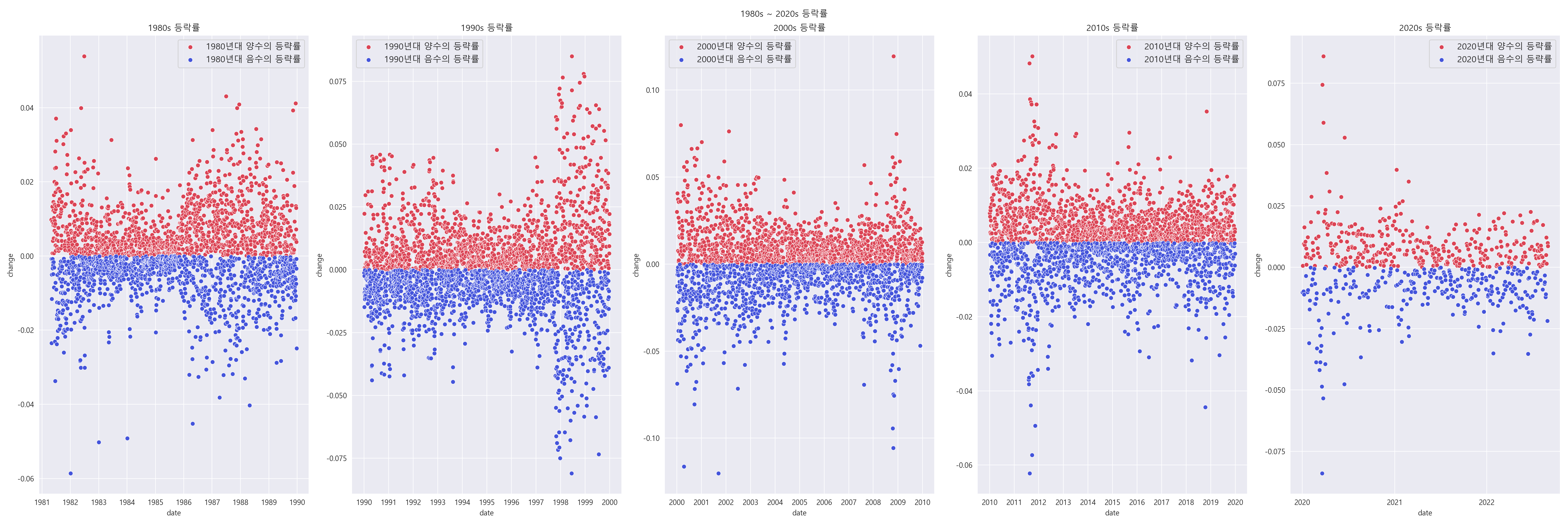
- 1980 년 대에는 1985 ~ 1986 년에 가장 등락률의 변화가 적었다. (그 사이에 경제의 변화가 크지 않음을 알 수 있습니다.)
- 1990 년 대에는 1998 ~ 2000 년에 가장 등락률의 변화가 컸다. (그 사이에 경제의 변화가 큼을 알 수 있습니다.)
- 2000 년 대에는 2009 년 언저리에 가장 등락률의 변화가 컸다.
- 2010 년 대에는 2011 ~ 2012 년에 가장 등락률의 변화가 컸다.
- 2020 년 대에는 2020 년 초반에 가장 등락률의 변화가 컸다.
- 대부분의 양수 등락률은 ∪ 자 형태를 띄고 있고, 음수 등락률 또한 ∩ 자 형태를 띄고 있습니다.
- 대략적으로 0을 기준으로 대칭인 형태를 띄고 있습니다.
3-4. 종가와 전일 종가 분포 알아보기.
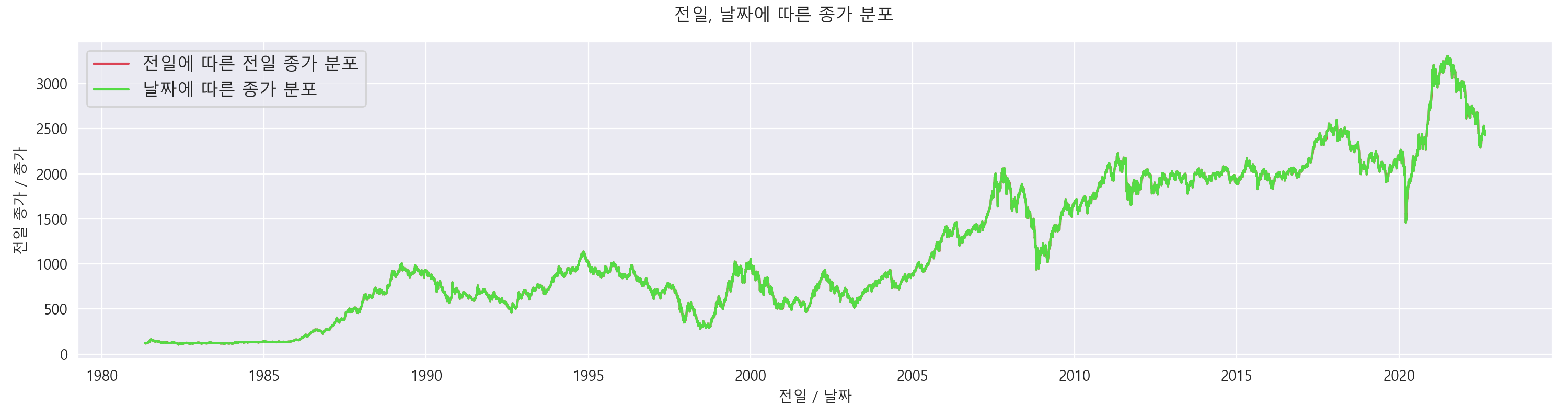
전체적으로 종가도 증가하는 추세를 보이고 있습니다. 전일 종가와 종가가 크게 차이를 보이는 곳은 없어보입니다. (거의 오차가 없어 보입니다.) 전체적으로 조금씩 증가함을 보여주고 있습니다.
3-5. 누적 분포 알아보기.
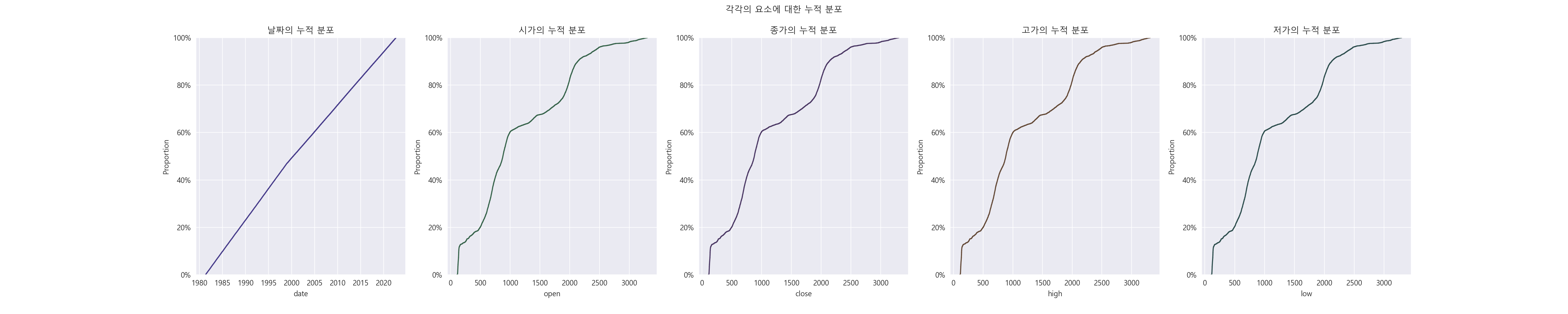
- 날짜인 경우에는 누적 분포의 비율이 그래도 비슷한 편에 속합니다. 2005년 기준 날짜의 60% 정도를 차지하고 있습니다.
- 시가, 종가, 고가, 저가인 경우, 50 ~ 1000인 경우에 20%로 가장 많은 비율을 차지하고 있고, 4개의 그래프 모두 비슷한 분포를 가지고 있음을 알 수 있습니다.
3-6. 전체 평균 기준 violinplot으로 분포 알아보기.
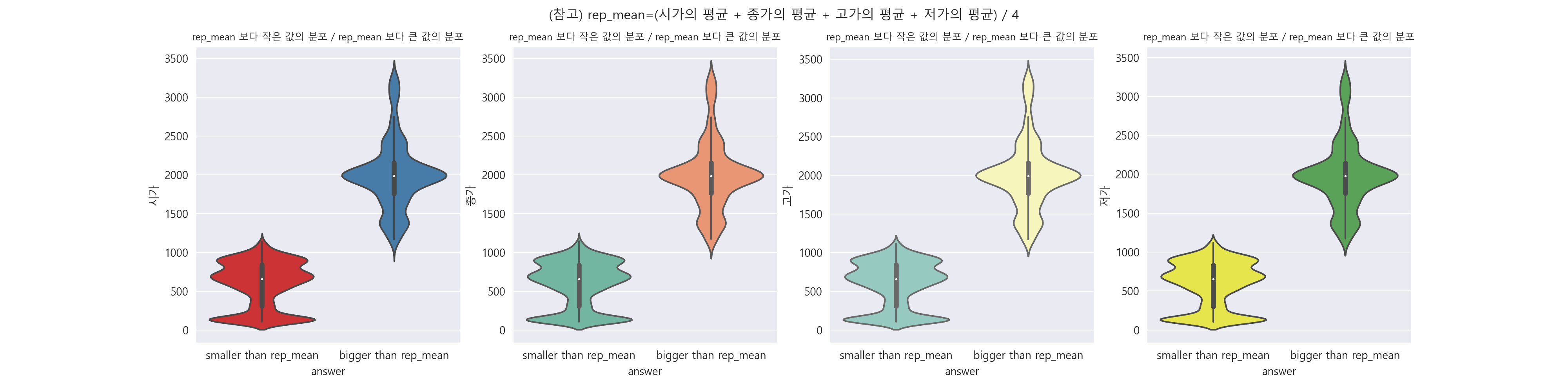
rep_mean 보다 크거나 작은 값으로 나눠서 분포를 알아보니 시가, 종가, 고가, 저가 모두 분포가 동일함을 알 수 있습니다. 그리고 rep_mean 보다 작은 데이터에서는 100 언저리와 500 ~ 1000 사이에 분포가 가장 많음을 알 수 있고, rep_mean 보다 큰 데이터에서는 2000 근처에도 꽤 많이 분포함을 알 수 있습니다.
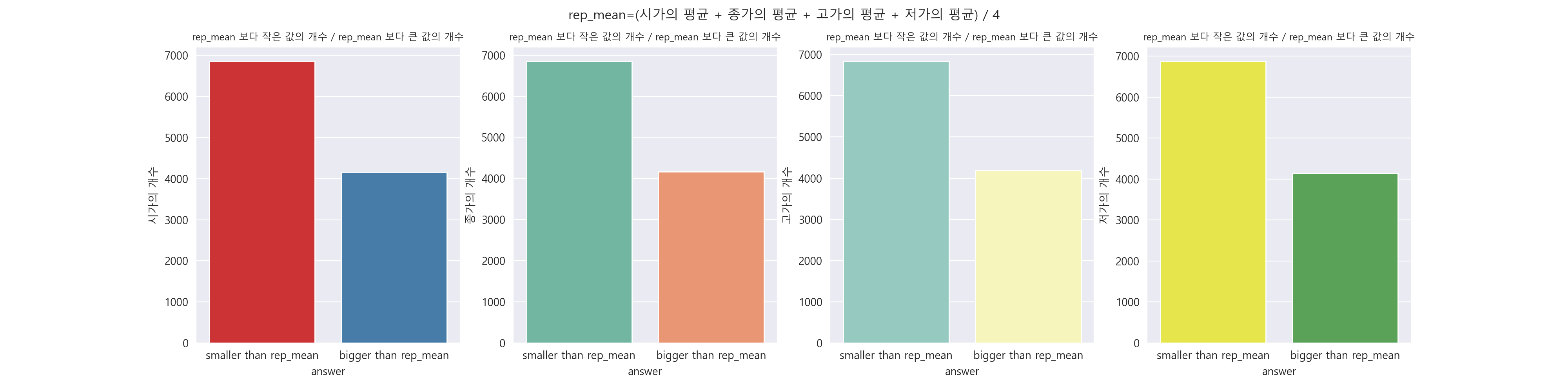
3-7. histplot으로 분포 알아보기.
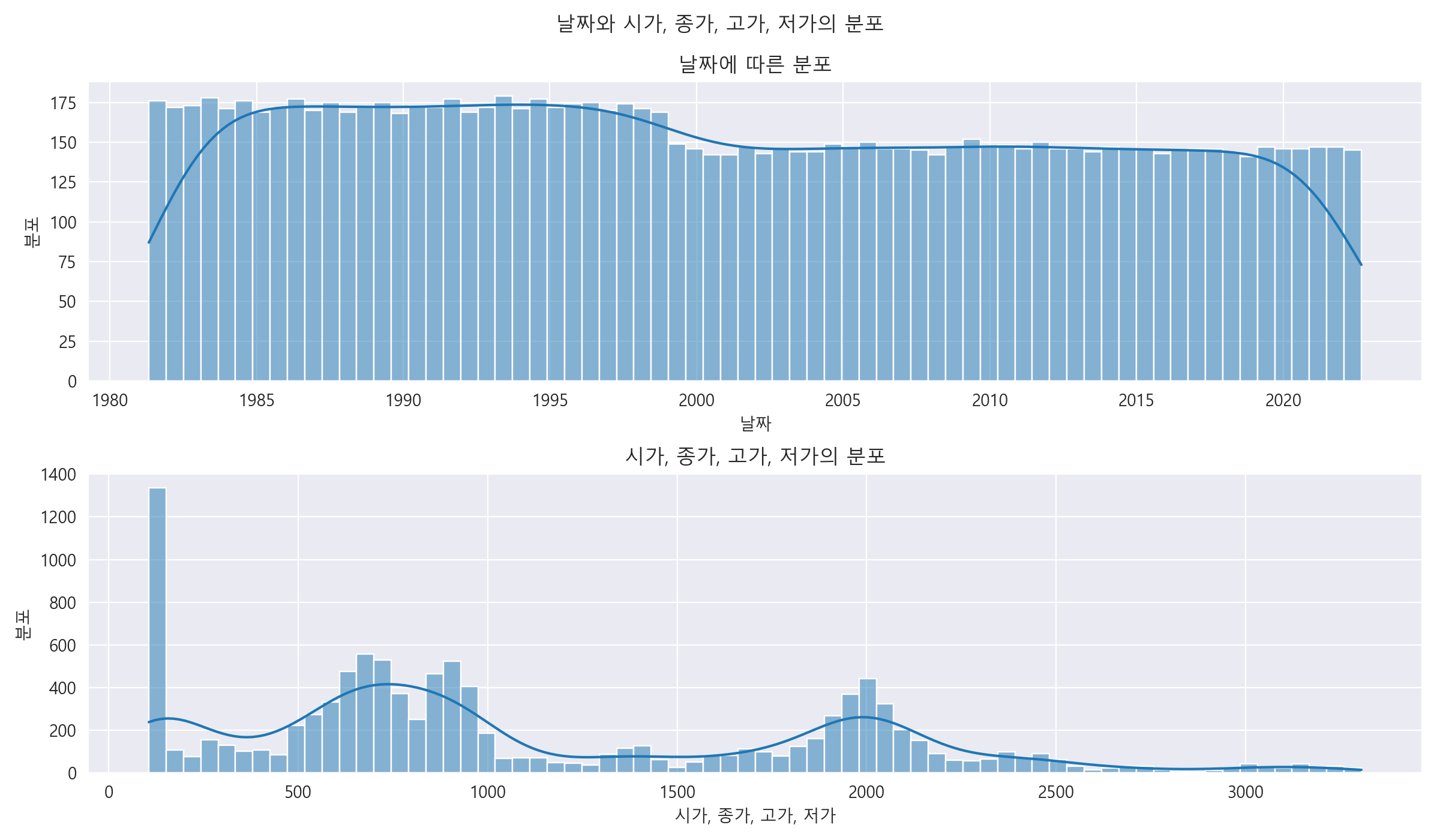
bins의 개수를 70개로 잡고, 분포를 알아보았습니다.
- 날짜는 대체로 비슷한 분포를 띄고 있습니다. 하지만 1990년 대 후반까지 좀 더 많은 분포를 차지하고 있습니다. 분포 모양은 ∩ 형태 입니다.
- 시가, 종가, 고가, 저가는 확실히 다른 분포를 띄고 있습니다. 약 100 언저리에 가장 많은 분포를 차지하고, 500 ~ 1000 사이에 누적 분포가 가장 많아보입니다. 그리고 2000 에서도 많은 분포를 차지하고 있습니다.
3-8. 요일 별 거래량의 분포 알아보기.
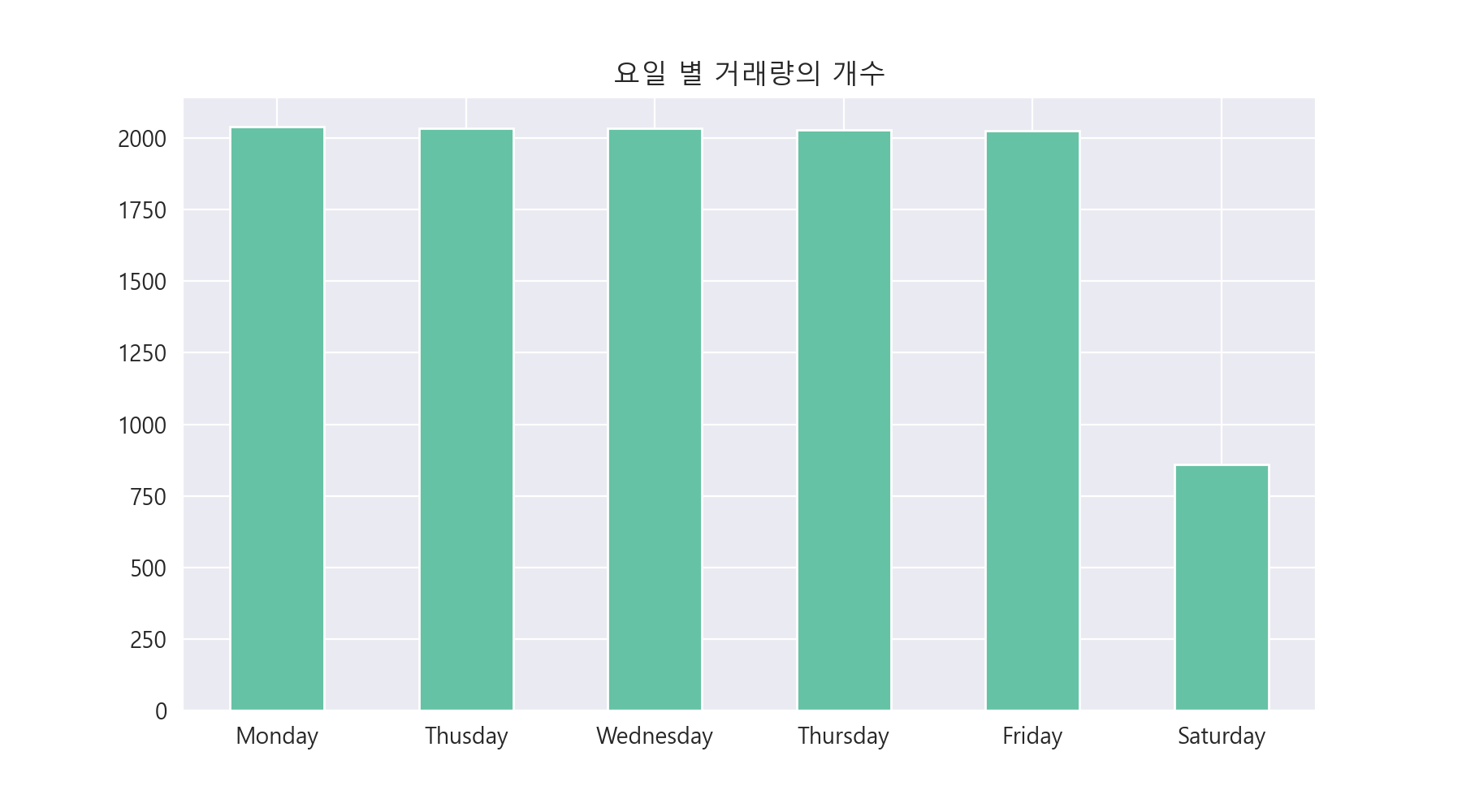
요일 별 거래량의 개수를 알아보았습니다. 일단 월요일, 화요일, 수요일, 목요일, 금요일은 거래량이 거의 동일함을 알 수 있습니다. (2000 언저리) 하지만, 토요일에는 거래량이 가장 적음을 알 수 있습니다. 보통 주식 거래를 평일 오전 9시부터 11시 사이까지 많이 해서 평일에 횟수가 많은 것으로 추정할 수 있습니다.
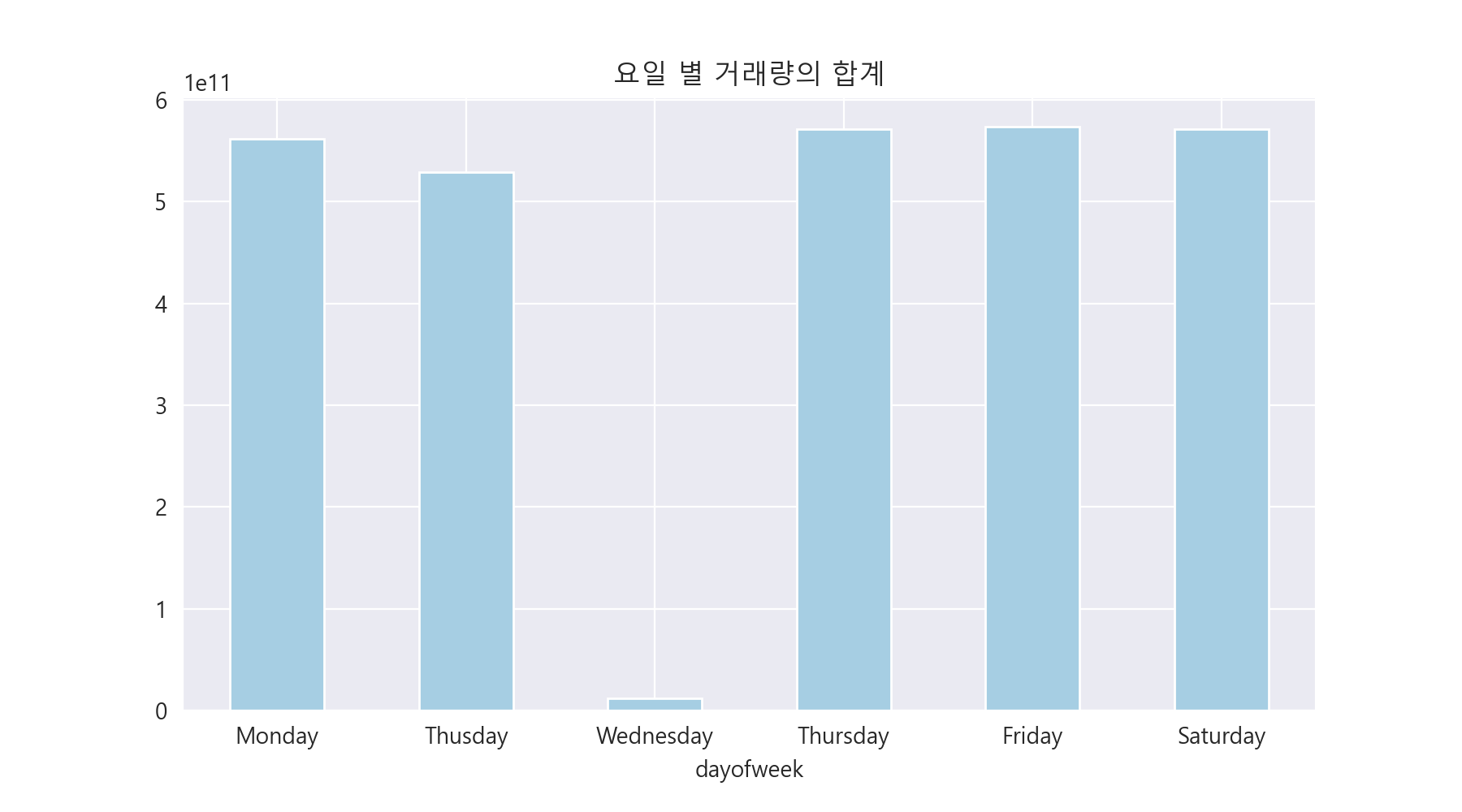
요일 별 거래량의 합계를 알아보니, 수요일에 가장 적은 거래량이 나왔습니다. (거의 거래량이 없음을 알 수 있습니다.) 거래 횟수는 많지만, 실질적인 거래량은 적음을 알 수 있습니다. 의외로 토요일이 수요일을 제외한 다른 평일과 거래량이 비슷했습니다. 토요일은 거래량이 적은 대신에, 거래량의 합계가 많은 것을 알 수 있습니다.
4. 외부 데이터를 이용하여 데이터 전처리 (EDA)와 시각화하기.
외부 데이터 출처 : Kaggle Stock Index
이번에 같이 이용할 데이터는 주가 지수 데이터입니다. 주가 지수는 시가 총액법으로 계산된 데이터이고, 시가 총액이 클수록, 차지 비중이 높습니다.
4-1. 칼럼 설명
- date : 날짜
- s&p500 : USA 주가 지수
- jpx400 : JAPAN 주가 지수
- ssec : CHINA 주가 지수
- kospi : KOREA 주가 지수
- kospi 공식
kospi = ((오늘의 시가 총액) / (1980.1.4 까지 시가 총액)) x 100
- 하지만, 우리는 1981년 데이터부터 있기 때문에, 원래 자료에서 kospi를 구할 수 없습니다.
4-2. 데이터 전처리(EDA)하기.
- 모든 칼럼들을 소문자로 변경시켰습니다.
- 결측치를 확인해보니, 결측치가 존재하였습니다.
- 나라 별 각각 평균을 구하여 결측치에 넣어주었습니다.
- date 칼럼을 datetime으로 변경하였습니다.
4-3. 나라 별 주가 지수의 분포 알아보기.
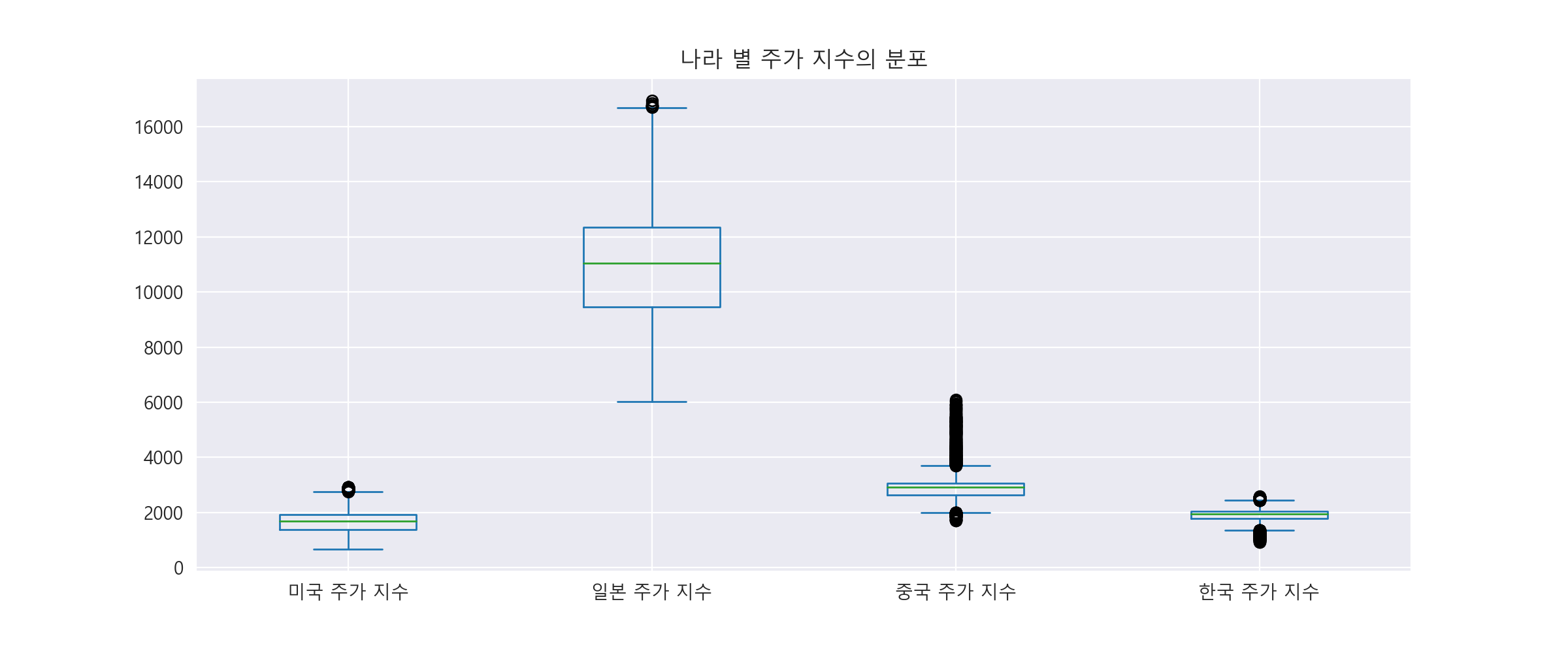
박스 플롯을 이용하여, 각각의 주가 지수에 대해 분포를 알아볼 수 있습니다.
- 미국 주가 지수와 한국 주가 지수는 분포의 범위가 좁은 편입니다.
- 중국 주가 지수 또한 분포의 범위는 좁은 편이지만, 이상치가 많은 편입니다.
- 일본 주가 지수가 가장 분포의 범위가 넓고, 중앙값 및 사분위 수가 가장 큰 편 입니다.
4-4. 연도 별 주가 지수의 분포 알아보기.
각각의 주가 지수 평균보다 주가 지수가 큰 부분과 주가 지수가 작은 부분을 나눠주었습니다.
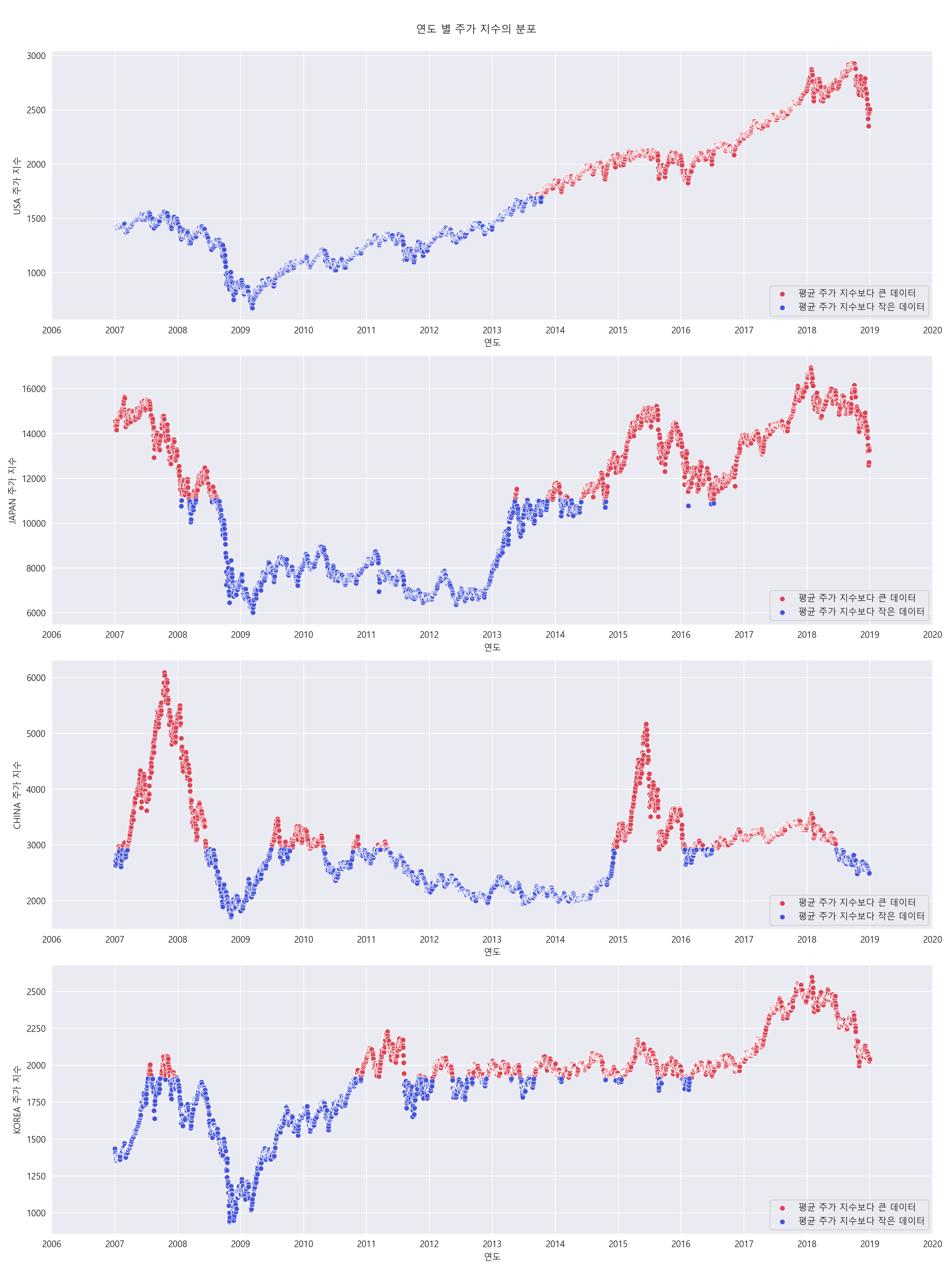
각각의 평균을 기준으로 평균보다 큰 주가 지수를 가진 데이터는 빨간색, 평균보다 작은 주가 지수를 가진 데이터는 파란색으로 표기하였습니다.
- 미국 주가 지수 : 전반적으로 계속 증가하는 형태를 띄고 있습니다.
- 일본 주가 지수 : 2008년 초반 ~ 2015년 후반까지는 평균보다 작은 형태를 띄고 있습니다. 나머지는 평균보다 큰 데이터 입니다.
- 중국 주가 지수 : 평균보다 큰 주가 지수와 평균보다 작은 주가 지수의 데이터가 섞여 있습니다.
- 한국 주가 지수 : 평균보다 큰 주가 지수와 평균보다 작은 주가 지수의 데이터가 섞여 있습니다.
미국 주가 지수를 제외하고 나머지는 전반적으로 들쑥날쑥한 형태를 띄고 있습니다.
4-5. 주가 지수 상관 계수 알아보기.
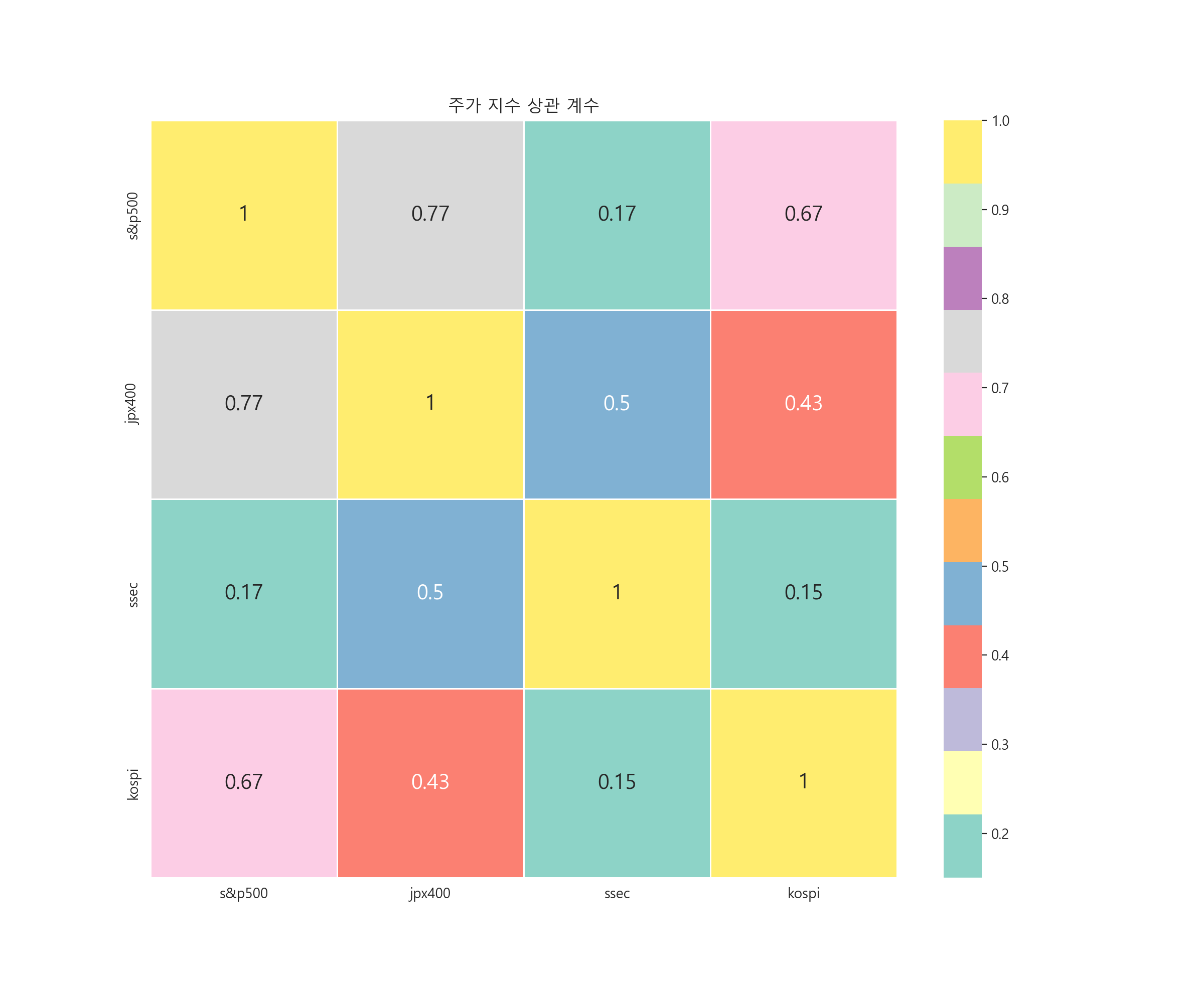
- 상관 관계가 높은 관계
- 미국 주가 지수 ~ 일본 주가 지수
- 일본 주가 지수 ~ 미국 주가 지수
- 미국 주가 지수 ~ 한국 주가 지수
- 한국 주가 지수 ~ 미국 주가 지수
- 상관 관계가 낮은 관계
- 중국 주가 지수 ~ 한국 주가 지수
- 한국 주가 지수 ~ 중국 주가 지수
미국와 일본, 그리고 한국과 미국은 주가 지수 간의 관계성이 큰 편입니다. (종속적이다. 서로 영향을 끼치고 있습니다.)
중국과 한국은 주가 지수 간의 관계성이 거의 없는 편입니다.
4-6. 나라 별 주가 지수의 분포 알아보기.
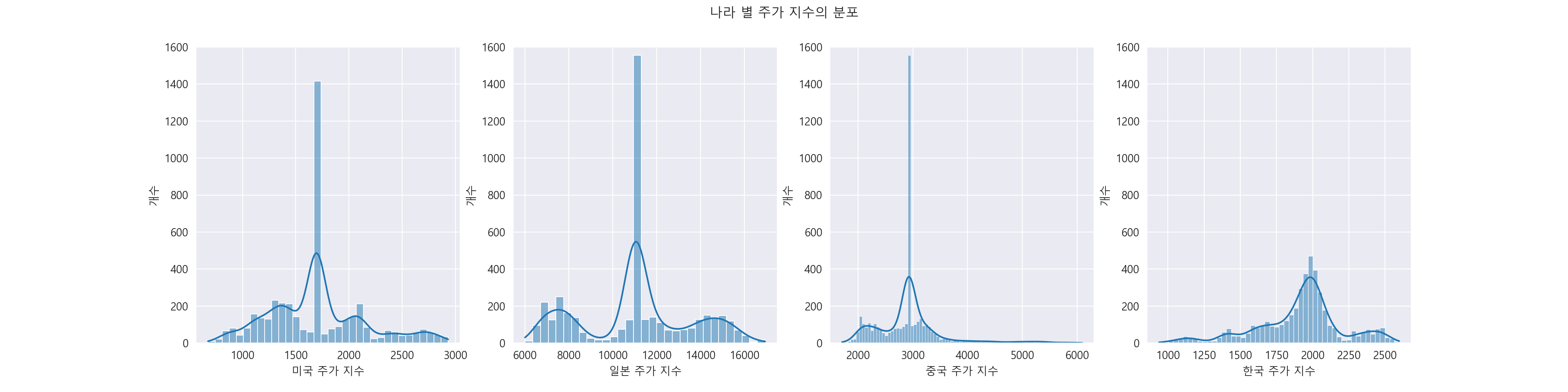
나라 별 주가 지수의 분포를 알 수 있습니다. 한국 주가 지수는 다른 나라에 비해 대체로 비슷하게 분포되어 있습니다. (다른 나라는 어느 한 지점에서 분포가 많이 되어 있음을 알 수 있습니다.) 그리고 이 그래프에서도 일본 주가 지수가 다른 나라에 비해 높음을 알 수 있습니다.
5. Review
5-1. Dacon 관련 데이터 Review
- 연도 별, 날짜 별 거래량 최대, 최소 분포 알아보기.
- 전체적으로 ~ 4e^9주까지 분포합니다.
- 최대 분포는 ~2e^9주까지 분포하고, 0 ~ e^9주 사이에 많이 분포합니다.
- 최소 분포는 0에서 가장 많이 분포합니다.
- 2002년, 2021년에 가장 많이 차이 나고 전체적으로 증가하는 그래프를 가지고 있습니다.
- 월, 연도로 나누지 않고 전반적으로 바라보았을 때, 분포 알아보기.
- 최대 분포는 0에서 가장 많았고, 그 다음에 0.5에서 많았습니다. 0 ~ 3.5e^9 주 사이에 분포합니다.
- 최소 분포는 0에서 가장 많았고, 그 다음에 0 ~ 0.5에사 많았습니다. 0 ~ e^9 주 언저리에 분포합니다.
- 고가와 저가의 분포
- 전체적으로 같이 증가하는 그래프를 가지고 있습니다. (계속 증가하는 그래프는 아닙니다.)
- 전체 거래량이 2002년, 2021년에 급격하게 증가하였습니다.
- 등락률 차이가 큰 지점과 거래량이 큰 지점이 일치하지 않습니다. 서로 관계가 없음을 알 수 있습니다.
- 상관 관계
(1) 완벽한 정비례 관계 & 연관성이 큼 : 자기 자신과의 관계가 1이기 때문에, 상관계수가 1이면 완벽한 정비례 관계를 의미합니다.
- close ~ open
- close ~ high
- close ~ low
- open ~ high
- open ~ low
- high ~ low
- change ~ monthly_ratio
- close ~ pd_close
- open ~ pd_close
- high ~ pd_close
- low ~ pd_close
(2) 정비례 관계 : 상관계수가 양수이기 때문에, 연관성이 꽤 있는 편입니다.
- year ~ pd_close
- close ~ year
- open ~ year
- high ~ year
- low ~ year
(3) 반비례 관계 : 상관계수가 음수이기 때문에, 연관성이 꽤 약한 편입니다.
- open ~ month
- close ~ month
- high ~ month
- low ~ month
5-2. 외부 데이터 Review
- 각각의 주가 지수에 대한 분포 알아보기.
- 미국 주가 지수와 한국 주가 지수는 분포의 범위가 좁은 편입니다.
- 중국 주가 지수 또한 분포의 범위는 좁은 편이지만, 이상치가 많은 편입니다.
- 일본 주가 지수가 가장 분포의 범위가 넓고, 중앙값 및 사분위 수가 가장 큰 편 입니다.
- 평균보다 큰 주가 지수와 평균보다 작은 주가 지수의 분포 알아보기.
각각의 평균을 기준으로 평균보다 큰 주가 지수를 가진 데이터는 빨간색, 평균보다 작은 주가 지수를 가진 데이터는 파란색으로 표기하였습니다.
- 미국 주가 지수 : 전반적으로 계속 증가하는 형태를 띄고 있습니다.
- 일본 주가 지수 : 2008년 초반 ~ 2015년 후반까지는 평균보다 작은 형태를 띄고 있습니다. 나머지는 평균보다 큰 데이터 입니다.
- 중국 주가 지수 : 평균보다 큰 주가 지수와 평균보다 작은 주가 지수의 데이터가 섞여 있습니다.
- 한국 주가 지수 : 평균보다 큰 주가 지수와 평균보다 작은 주가 지수의 데이터가 섞여 있습니다.
미국 주가 지수를 제외하고 나머지는 전반적으로 들쑥날쑥한 형태를 띄고 있습니다.
- 상관 관계
(1) 상관 관계가 높은 관계
- 미국 주가 지수 ~ 일본 주가 지수
- 일본 주가 지수 ~ 미국 주가 지수
- 미국 주가 지수 ~ 한국 주가 지수
- 한국 주가 지수 ~ 미국 주가 지수
(2) 상관 관계가 낮은 관계
-
중국 주가 지수 ~ 한국 주가 지수
-
한국 주가 지수 ~ 중국 주가 지수
-
미국와 일본, 그리고 한국과 미국은 주가 지수 간의 관계성이 큰 편입니다. (종속적이다. 서로 영향을 끼치고 있습니다.)
-
중국과 한국은 주가 지수 간의 관계성이 거의 없는 편입니다.
- 나라 별 주가 지수의 분포 알아보기.
- 한국 주가 지수는 다른 나라에 비해 대체로 비슷하게 분포되어 있습니다. (다른 나라는 어느 한 지점에서 분포가 많이 되어 있음을 알 수 있습니다.)
- 이 그래프에서도 일본 주가 지수가 다른 나라에 비해 높음을 알 수 있습니다.
참가 인증서

