
[Dacon] 건설기계 오일 상태 분류 AI 경진대회 베이스 라인 공부
1. 패키지 불러오기.
일단 Y_LABEL (오일 정상 여부)를 분류하는 것이기 때문에, (0: 정상, 1: 이상) 이진 분류이다.
import torch # pytorch 불러오기.
import torch.nn as nn # 신경망 만들기.
import torch.nn.functional as F # 신경망 만들기.
import torch.optim as optim # optimizer
from torch.utils.data import DataLoader, Dataset # 방대한 데이터를 불러올 때 사용하는 기능이다. 하나씩 불러와서 사용한다.
from sklearn.metrics import f1_score
from sklearn.preprocessing import StandardScaler # 평균 0, 분산 1로 지정한다.
from sklearn.preprocessing import LabelEncoder # 문자를 숫자로 매핑하기.
from sklearn.model_selection import train_test_split # 훈련 데이터와 테스트 데이터 나누기.
import os
import pandas as pd
import numpy as np
from tqdm.auto import tqdm # print를 많이 사용하면, 메모리가 터질 수 있기 때문에 꼭 사용해야한다.
import random
import warnings # 경고창 무시하는 코드
warnings.filterwarnings(action='ignore')
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu') # pytorch에서 GPU 사용 설정하기.-
딥러닝 발달 계보
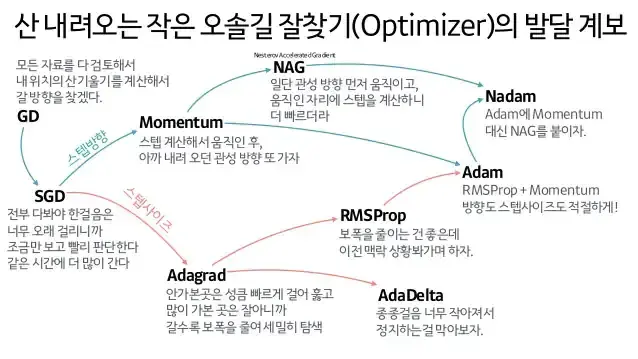
-
참고 블로그 : [ML] 신경망에서의 Optimizer - 역할과 종류
2. 하이퍼 파라미터 세팅하기.
- 미니 배치가 5인 그림
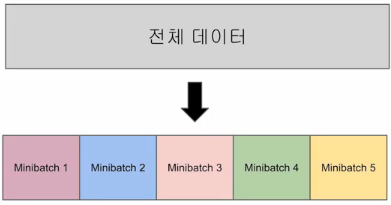
CFG = {
'EPOCHS': 30, # 전체 훈련 데이터가 학습에 한 번 사용된 주기가 30회이다.
'LEARNING_RATE':1e-2, # gradient의 보폭을 의미한다.
'BATCH_SIZE':256, # 전체 데이터를 256개로 나누어서 학습시키기.
'SEED':41 # 숫자가 중요한 부분이 아니고, 서로 다른 시드를 사용하면 서로 다른 난수를 생성한다는 점 기억하기.
}3. seed를 고정하는 코드
# seed를 고정하는 코드이다.
def seed_everything(seed):
random.seed(seed) # python 자체의 random seed를 고정시키기.
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed) # numpy library의 random seed를 고정시키기.
# pytorch의 random seed를 고정시키기.
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = True # 고정시키면 학습 속도가 느려짐을 알 수 있다. 정확한 모델 성능 재현이 필요하지 않은 경우에는 꺼두기.
seed_everything(CFG['SEED'])4. 데이터 불러오기.
train = pd.read_csv('./train.csv') # 훈련 데이터
test = pd.read_csv('./test.csv') # 테스트 데이터5. 데이터 전처리하기.

- 범주형 특징과 수치형 특징 분리하기.
categorical_features = ['COMPONENT_ARBITRARY', 'YEAR']
# Inference(실제 진단 환경)에 사용하는 컬럼
test_stage_features = ['COMPONENT_ARBITRARY', 'ANONYMOUS_1', 'YEAR' , 'ANONYMOUS_2', 'AG', 'CO', 'CR', 'CU', 'FE', 'H2O', 'MN', 'MO', 'NI', 'PQINDEX', 'TI', 'V', 'V40', 'ZN']len(train.columns) # 54
len(test_stage_features) # 54개 중에서 18개를 뽑아왔다.우리가 고민해야 하는 점은 train columns에서 유의미한 특징들만을 골라서 학습을 시켜야 한다는 점이다.
🥺 어떻게 해야 할까...?
5-1. 결측치 처리하기.

train = train.fillna(0) # 결측치에 0을 대입하기.
test = test.fillna(0)5-2. Train / Validation 분할하기.
all_X = train.drop(['ID', 'Y_LABEL'], axis = 1) # 모든 x 데이터에 ID, Y_LABEL 제거시키기.
all_y = train['Y_LABEL'] # 모든 y 데이터에 Y_LABEL만 남겨놓기.
test = test.drop(['ID'], axis = 1) # test 데이터에 ID 제거시키기.
train_X, val_X, train_y, val_y = train_test_split(all_X, all_y, test_size=0.2, random_state=CFG['SEED'], stratify=all_y)
# train : test = 8 : 2로 지정하고, 아까 고정시킨 seed를 random_state로 지정하고, y 데이터에서 계층적 데이터 추출 옵션 (분류 모델에서 추천!)- train_X, train_y : 훈련 데이터
- val_X, val_y : 검증 데이터
- test : 테스트 데이터 (성능 평가에 이용할 것이다.)

5-3. Data label-encoding, scaling
def get_values(value):
return value.values.reshape(-1, 1) # 열을 1개로 만들어주기.
# 1. 데이터 전처리 : 평균 0, 분산 1로 만들어주기.
for col in train_X.columns: # 훈련용 X 데이터 칼럼 불러오기.
if col not in categorical_features: # 'COMPONENT_ARBITRARY', 'YEAR'가 없으면
scaler = StandardScaler() # 평균 0, 분산 1로 만들어주기. (데이터 전처리하기.)
train_X[col] = scaler.fit_transform(get_values(train_X[col])) # train_X[col]의 value 값 가져와서 fit()을 통해서 설정한 뒤에 이를 기반으로 학습 데이터의 transform()을 수행하되 학습 데이터에서 설정된 변환을 위한 기반 설정을 그대로 테스트 데이터에도 적용하기 위해서입니다.
val_X[col] = scaler.transform(get_values(val_X[col])) # 검증 데이터도 마찬가지로 처리시켜주기.
if col in test.columns: # 테스트 데이터 칼럼 불러오기.
test[col] = scaler.transform(get_values(test[col])) # test data에서는 fit_transform을 이용하지 않는다.
# 2. 인코딩 : 문자를 수치화하기.
le = LabelEncoder()
for col in categorical_features: # 카테고리 특징 불러오기.
train_X[col] = le.fit_transform(train_X[col]) # 훈련 데이터 문자에서 수치화하기.
val_X[col] = le.transform(val_X[col]) # 검증 데이터 문자에서 수치화하기.
if col in test.columns: # 테스트 칼럼 불러오기.
test[col] = le.transform(test[col]) # test data에서는 fit_transform을 이용하지 않는다.범주형 특징과 수치형 특징을 나눈 뒤에 필요한 특징만 가져온다. 그리고 수치형 특징은 표준화로 전처리 시킨 뒤에 처리해주고, 범주형 특징은 문자를 수치화하는 인코딩을 이용한 뒤에 처리해준다.
- 참고 블로그 : 비지도 학습과 데이터 전처리 - 데이터 전처리와 스케일 조정
- 참고 블로그 : transform()과 fit_transform()의 차이점
le.classes_ # 어떻게 인코딩했는지 확인할 수 있다.6. CustomDataset 제작하기.
- 참고 문서 : 위키독스 클래스 문서
- class의 개념 : 객체가 각각의 역할을 수행하게 만들기 위함이다. (다른 객체의 결과값과 독립적인 결과를 가짐.)
- class : 붕어빵 틀 (1개의 클래스로 많은 객체를 만들 수 있다.)
- 객체 : 붕어빵
(예시) 사칙연산 클래스 만들기.
- 클래스 구조 만들기.
- 객체에 숫자 지정할 수 있도록 만들기.
def setdata(self, first, second): # 메서드의 매개변수
self.first = first # 메서드의 수행문
self.second = second # 메서드의 수행문- 기능 제작하기.
class FourCal:
def setdata(self, first, second):
self.first = first
self.second = second
def add(self):
result = self.first + self.second
return result
def mul(self):
result = self.first * self.second
return result
def sub(self):
result = self.first - self.second
return result
def div(self):
result = self.first / self.second
return result숫자를 넣어줘야 하기 때문에 객체에 함수를 불러와야 한다.
a=FourCal()
b=FourCal()
a.setdata(4,8)
b.setdata(6,2)- init 함수 이용하기.
class FourCal:
def __init__(self, first, second): # __init__ 함수 이용하기.
self.first = first
self.second = second
def add(self):
result = self.first + self.second
return result
def mul(self):
result = self.first * self.second
return result
def sub(self):
result = self.first - self.second
return result
def div(self):
result = self.first / self.second
return result객체 자체에 숫자를 넣어주면 된다.
a=FourCal(8,4) # 객체에 값을 넣어주기.- 참고 문서 : pytorch CustomDataset & DataLoader 문서
- 참고 블로그 : Dataset과 Dataloader 설명 및 custom dataset & dataloader 생성
정리하자면...
- 아까 만든 train_X, train_y, val_X, val_y를 이용하여 CustomDataset (사용자 정의 데이터셋) 을 만들어주고, (RAM 터지지 않게 하기 위함이다.)
- DataLoader를 이용하여 샘플에 쉽게 접근할 수 있도록 순회 가능한 객체(iterable)로 감싸기. (목표는 데이터에 더 쉽게 접근할 수 있도록 하기.)
1. 사용자 정의 데이터셋 만들기. (CustomDataset)

🥺 왜 CustomDataset을 만드는가? : 모든 데이터를 한번에 불러와서 학습시키면 RAM 터질 확률이 크다. 그래서 조금씩 가져오는 사용자 정의 데이터셋이 필요하다.
class CustomDataset(Dataset): # 사용자 정의 데이터셋 만드는 클래스 (붕어빵 틀)
# RAM 터지지 않게 하기 위하여 사용자 정의 데이터셋 만드는 과정이다.
def __init__(self, data_X, data_y, distillation=False): # 객체 생성 시 1번 이용한다.
super(CustomDataset, self).__init__()
self.data_X = data_X # input feature
self.data_y = data_y # label 혹은 정답
self.distillation = distillation # 증류
def __len__(self): # 데이터 샘플 개수를 반환한다.
return len(self.data_X)
def __getitem__(self, index): # 주어진 인덱스 idx 에 해당하는 샘플을 데이터셋에서 불러오고 반환한다.
if self.distillation:
# 지식 증류 학습 시
teacher_X = torch.Tensor(self.data_X.iloc[index])
student_X = torch.Tensor(self.data_X[test_stage_features].iloc[index])
y = self.data_y.values[index]
return teacher_X, student_X, y
else: # 지식 증류 학습 아닐 시
if self.data_y is None:
test_X = torch.Tensor(self.data_X.iloc[index])
return test_X
else:
teacher_X = torch.Tensor(self.data_X.iloc[index])
y = self.data_y.values[index]
return teacher_X, y훈련용 사용자 데이터셋 객체와 검증용 사용자 데이터셋 객체를 생성하였다.
train_dataset = CustomDataset(train_X, train_y, False) # 훈련 사용자 데이터셋 객체
val_dataset = CustomDataset(val_X, val_y, False) # 검증 사용자 데이터셋 객체2. 간편한 API DataLoader

복잡한 과정을 간단한 API로 만든 것이다.
train_loader = DataLoader(train_dataset, batch_size = CFG['BATCH_SIZE'], shuffle=True)
val_loader = DataLoader(val_dataset, batch_size = CFG['BATCH_SIZE'], shuffle=False)3. 딥러닝 모델 지식의 증류 기법 (교사 - 학생 지식 증류 기법 이용하기.)
- 참고 블로그 : 딥러닝 모델 지식의 증류기법
- 참고 블로그 : Knowledge Distillation 구현
- 참고 블로그 : Why Knowledge Distillation Work?
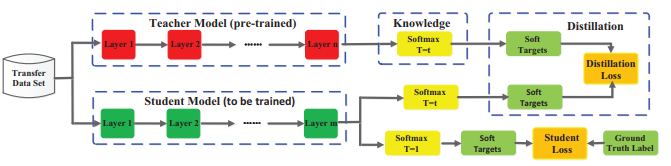
지식 증류 (모델 경량화) : 잘 학습된 모델 경향성(soft label)을 학습하는 것이다. 두 가지 모델을 불러오고, 두 가지 loss를 합치는 것 외에는 모든 과정이 동일하다.
- Teacher Model : 이미 학습된 무거운 모델
- Student Model : 학습할 가벼운 모델
7. Teacher Model (이미 학습된 무거운 모델) 정의하기.
- 참고 블로그 : Activation Function 종류
7-1. Teacher Model 신경망 구현하기. (순전파를 이용하여 예측값 구하기.)
class Teacher(nn.Module): # 교사 모델 신경망 만드는 코드이다. (학습용 feature 데이터를 넣어서 예측값 구하기.)
def __init__(self): # 생성자에서 사용하려는 모든 레이어를 선언하기.
super(Teacher, self).__init__()
self.classifier = nn.Sequential(
nn.Linear(in_features=52, out_features=256), # 단순 선형 회귀, input_size=52, output_size=256
nn.BatchNorm1d(256), # 1 Dim batch normalization
nn.LeakyReLU(), # dying Relu 현상 해결하기 위함이다. (0보다 작은 구간은 기울기가 0이기 때문이다.)
nn.Linear(in_features=256, out_features=1024),
nn.BatchNorm1d(1024),
nn.LeakyReLU(),
nn.Linear(in_features=1024, out_features=256),
nn.BatchNorm1d(256),
nn.LeakyReLU(),
nn.Linear(in_features=256, out_features=1),
nn.Sigmoid()
)
def forward(self, x): # 입력부터 출력까지 모델이 실행되는 방식을 선언하기.
output = self.classifier(x)
return output이 코드는 단순 선형 회귀와 1차원 배치 정규화, 그리고 활성화 함수는 leaky Relu와 Sigmoid 함수를 이용하였다.
7-2. 데이터 분포를 맞추기 위한 해결책, batch-normalization (배치 정규화)
- 참고 블로그 : batch-normalization
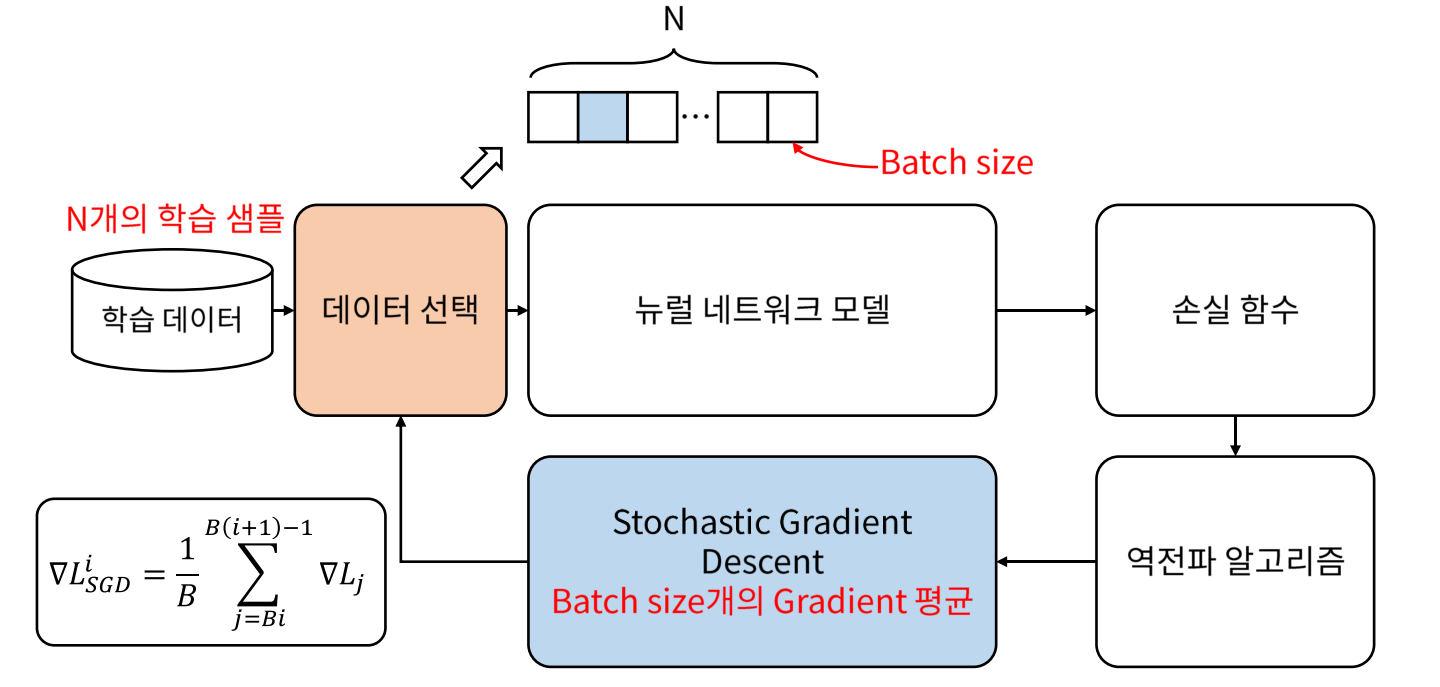
한번에 많은 데이터를 사용할 수 없기 때문에, batch size로 나눠서 데이터를 이용한다.
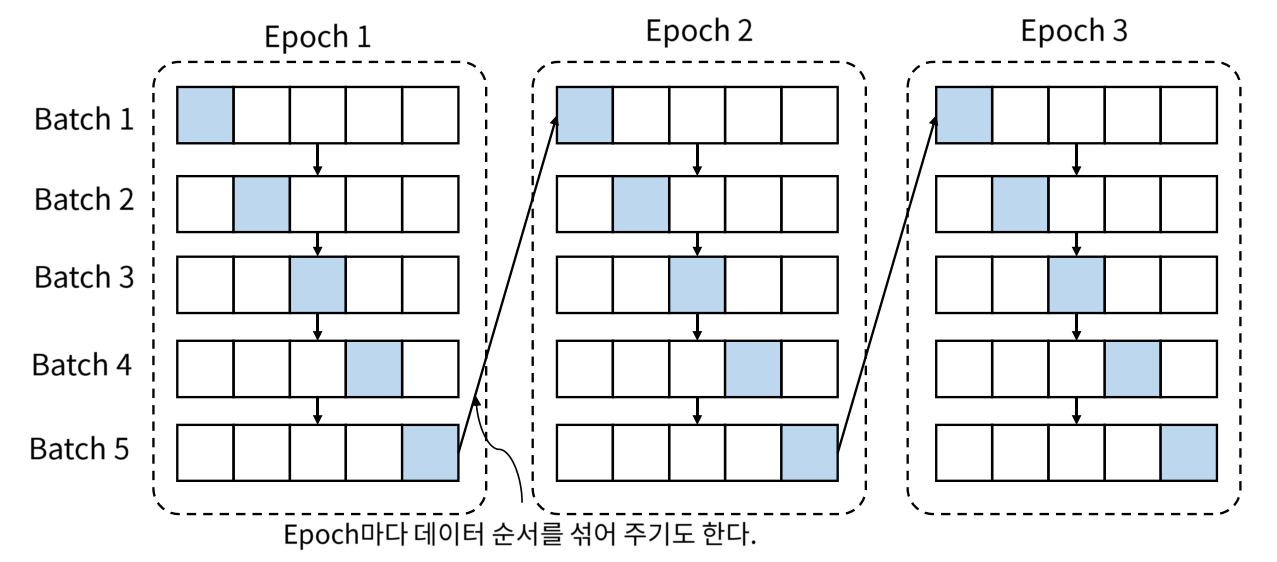
- epoch : 학습 데이터를 전체적으로 한번 학습하는 것을 의미한다.
- batch : 학습 데이터를 일정한 개수로 나눈 횟수를 의미한다.
하지만 batch 단위로 학습하는 경우 문제점이 생긴다. (데이터의 분포에 대한 문제) 그래서 batch-normalization을 이용하여 데이터의 분포를 맞춰준다.
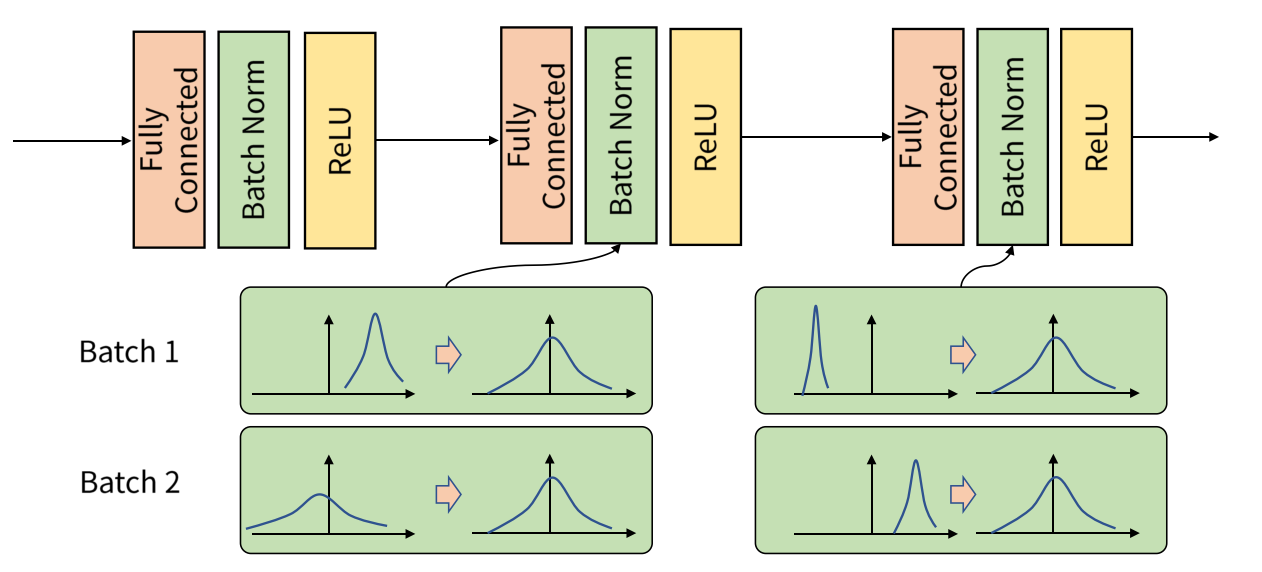
7-3. 훈련 데이터 교사 모델과 검증 데이터 교사 모델 이용하여 loss를 최소로 하는 가중치 구하기.
- 참고 블로그 : 딥러닝 학습 방법 및 순서
(cf) 딥러닝 학습 순서
1. 학습용 feature data를 이용하여 예측값 구하기. (순전파)
2. 예측값과 실제값 사이의 오차 구하기. (loss, 손실 함수 값)
3. loss를 줄일 수 있는 가중치 값을 업데이트하기. (역전파)
4. 1 ~ 3번을 계속 반복하여, loss를 최소로 하는 가중치 값을 구하기.
def train(model, optimizer, train_loader, val_loader, scheduler, device): # 학습 데이터에 대한 교사 모델 학습하기.
model.to(device)
best_score = 0
best_model = None
criterion = nn.BCELoss().to(device)
for epoch in range(CFG["EPOCHS"]):
train_loss = [] # 학습 데이터 손실함수 구하기.
model.train() # 모델을 학습시키기.
for X, y in tqdm(train_loader): # tqdm : enumerate 대신 사용하기. DataLoader로 학습 데이터 준비하기.
X = X.float().to(device)
y = y.float().to(device)
optimizer.zero_grad()
y_pred = model(X) # 모델을 이용한 예측값 구하기.
loss = criterion(y_pred, y.reshape(-1, 1))
loss.backward() # 역전파를 이용하여 가중치를 업데이트하기.
optimizer.step()
train_loss.append(loss.item()) # 손실 함수 정의하기.
val_loss, val_score = validation_teacher(model, val_loader, criterion, device)
# 검증 데이터를 이용한 교사 모델 이용하여 손실함수 값과 점수 구하기.
print(f'Epoch [{epoch}], Train Loss : [{np.mean(train_loss) :.5f}] Val Loss : [{np.mean(val_loss) :.5f}] Val F1 Score : [{val_score:.5f}]')
if scheduler is not None:
scheduler.step(val_score)
if best_score < val_score: # score가 작으면 작을수록 좋은 모델이다.
best_model = model
best_score = val_score
return best_model - f1-score : 모델 성능을 평가하는 지표
- loss (손실 함수 값) : 실제값과 예측값 사이의 오차
def competition_metric(true, pred):
return f1_score(true, pred, average="macro")
def validation_teacher(model, val_loader, criterion, device):
model.eval()
val_loss = []
pred_labels = []
true_labels = []
threshold = 0.35
with torch.no_grad():
for X, y in tqdm(val_loader):
X = X.float().to(device)
y = y.float().to(device)
model_pred = model(X.to(device)) # 모델을 이용한 예측값 구하기.
loss = criterion(model_pred, y.reshape(-1, 1))
val_loss.append(loss.item()) # 검증 데이터의 손실 함수 값 구하기.
model_pred = model_pred.squeeze(1).to('cpu')
pred_labels += model_pred.tolist() # 예측 라벨 구하기.
true_labels += y.tolist() # 실제 라벨 구하기.
pred_labels = np.where(np.array(pred_labels) > threshold, 1, 0) # 예측 라벨 구하기.
val_f1 = competition_metric(true_labels, pred_labels) # 실제 라벨과 예측 라벨 비교하기.
return val_loss, val_f1 # 검증 데이터 손실함수 값, f1-score 값7-4. Teacher Model 돌리기.
model = Teacher() # 교사 모델 객체 만들기.
model.eval()
optimizer = torch.optim.Adam(model.parameters(), lr=CFG['LEARNING_RATE']) # optimizer를 Adam 이용하기.
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='max', factor=0.5, patience=1, threshold_mode='abs',min_lr=1e-8, verbose=True)
teacher_model = train(model, optimizer, train_loader, val_loader, scheduler, device)8. Student Model (학습할 모델) 정의하기.
다시 정리하자면 순전파를 이용하여 예측값을 구하고, 예측값과 실제값의 오차인 손실 함수 값을 구하고, 역전파를 이용하여 손실 함수가 최소가 되는 가중치를 찾아야 한다.
8-1. Student Model 신경망 구현하기. (순전파를 이용하여 예측값 구하기.)
class Student(nn.Module): # 학생 모델 신경망 만드는 코드이다.
def __init__(self): # 생성자에서 사용하려는 모든 레이어를 선언하기.
super(Student, self).__init__()
self.classifier = nn.Sequential(
nn.Linear(in_features=18, out_features=128),
nn.BatchNorm1d(128),
nn.LeakyReLU(),
nn.Linear(in_features=128, out_features=512),
nn.BatchNorm1d(512),
nn.LeakyReLU(),
nn.Linear(in_features=512, out_features=128),
nn.BatchNorm1d(128),
nn.LeakyReLU(),
nn.Linear(in_features=128, out_features=1),
nn.Sigmoid()
)
def forward(self, x): # 입력부터 출력까지 모델이 실행되는 방식을 선언하기.
output = self.classifier(x)
return output이 코드는 단순 선형 회귀, 1차원 배치 정규화, 그리고 Leaky Relu와 Sigmoid 함수가 이용된다.
8-2. 교사 - 학생 지식 증류 손실 함수 값 정의하기.
일단 위의 신경망 코드의 마지막 레이어가 시그모이드로 끝나기 때문에, BCELoss를 이용해야 한다.
- 참고 블로그 : PyTorch로 Knowledge Distillation(2014) 구현하기
- 미니 배치 단위로 손실 함수 계산하는 코드

- 지식 증류 손실 함수 계산하는 코드

# 지식 증류 loss 계산하는 코드이다.
def distillation(student_logits, labels, teacher_logits, alpha):
distillation_loss = nn.BCELoss()(student_logits, teacher_logits) # BCELoss 손실 함수 이용하기.
# BCELoss는 마지막 레이어가 Sigmoid나 Softmax인 경우에 이용한다.
student_loss = nn.BCELoss()(student_logits, labels.reshape(-1, 1)) # 학생 손실 삼수도 BCELoss 손실 함수 이용하기.
return alpha * student_loss + (1-alpha) * distillation_loss # 미니 배치 단위로 loss 계산하는 코드이다.
def distill_loss(output, target, teacher_output, loss_fn=distillation, opt=optimizer):
loss_b = loss_fn(output, target, teacher_output, alpha=0.1)
if opt is not None:
opt.zero_grad()
loss_b.backward()
opt.step()
return loss_b.item()8-3. 훈련 데이터 학생 모델과 검증 데이터 학생 모델 이용하여 loss를 최소로 하는 가중치 구하기.
Teacher Model과 동일한 코드이다.
def student_train(s_model, t_model, optimizer, train_loader, val_loader, scheduler, device):
s_model.to(device)
t_model.to(device)
best_score = 0
best_model = None
for epoch in range(CFG["EPOCHS"]):
train_loss = []
s_model.train()
t_model.eval()
for X_t, X_s, y in tqdm(train_loader):
X_t = X_t.float().to(device)
X_s = X_s.float().to(device)
y = y.float().to(device)
optimizer.zero_grad()
output = s_model(X_s)
with torch.no_grad():
teacher_output = t_model(X_t)
loss_b = distill_loss(output, y, teacher_output, loss_fn=distillation, opt=optimizer)
train_loss.append(loss_b)
val_loss, val_score = validation_student(s_model, t_model, val_loader, distill_loss, device)
print(f'Epoch [{epoch}], Train Loss : [{np.mean(train_loss) :.5f}] Val Loss : [{np.mean(val_loss) :.5f}] Val F1 Score : [{val_score:.5f}]')
if scheduler is not None:
scheduler.step(val_score)
if best_score < val_score:
best_model = s_model
best_score = val_score
return best_modeldef validation_student(s_model, t_model, val_loader, criterion, device):
s_model.eval()
t_model.eval()
val_loss = []
pred_labels = []
true_labels = []
threshold = 0.35
with torch.no_grad():
for X_t, X_s, y in tqdm(val_loader):
X_t = X_t.float().to(device)
X_s = X_s.float().to(device)
y = y.float().to(device)
model_pred = s_model(X_s)
teacher_output = t_model(X_t)
loss_b = distill_loss(model_pred, y, teacher_output, loss_fn=distillation, opt=None)
val_loss.append(loss_b)
model_pred = model_pred.squeeze(1).to('cpu')
pred_labels += model_pred.tolist()
true_labels += y.tolist()
pred_labels = np.where(np.array(pred_labels) > threshold, 1, 0)
val_f1 = competition_metric(true_labels, pred_labels)
return val_loss, val_f1 8-4. Student Model 돌리기.
Teacher Model과 동일한 코드이다.
train_dataset = CustomDataset(train_X, train_y, True) # 훈련 사용자 정의 데이터셋
val_dataset = CustomDataset(val_X, val_y, True) # 테스트 사용자 정의 데이터셋
train_loader = DataLoader(train_dataset, batch_size = CFG['BATCH_SIZE'], shuffle=True)
val_loader = DataLoader(val_dataset, batch_size = CFG['BATCH_SIZE'], shuffle=False)student_model = Student()
student_model.eval()
optimizer = torch.optim.Adam(student_model.parameters(), lr=CFG['LEARNING_RATE'])
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='max', factor=0.5, patience=1, threshold_mode='abs',min_lr=1e-8, verbose=True)
best_student_model = student_train(student_model, teacher_model, optimizer, train_loader, val_loader, scheduler, device)9. Threshold (임계값) 추론하기.
모델링을 통해 구한 확률을 임계값을 기준으로 0 또는 1로 변경한다. (정보 손실)
9-1. 훈련용 데이터셋으로 최적의 임계값과 최적의 f1-score 구하기.
def choose_threshold(model, val_loader, device):
model.to(device)
model.eval()
thresholds = [0.1, 0.2, 0.25, 0.3, 0.35, 0.4, 0.45, 0.5]
pred_labels = [] # 예측 라벨
true_labels = [] # 실제 라벨
best_score = 0
best_thr = None
with torch.no_grad():
for _, x_s, y in tqdm(iter(val_loader)):
x_s = x_s.float().to(device)
y = y.float().to(device)
model_pred = model(x_s)
model_pred = model_pred.squeeze(1).to('cpu')
pred_labels += model_pred.tolist()
true_labels += y.tolist()
for threshold in thresholds:
pred_labels_thr = np.where(np.array(pred_labels) > threshold, 1, 0) # 예측 라벨을 임계값보다 크면 1, 작으면 0으로 변경하기.
score_thr = competition_metric(true_labels, pred_labels_thr) # competitiom_metric : f1-score를 리턴해주는 함수이다.
if best_score < score_thr:
best_score = score_thr
best_thr = threshold
return best_thr, best_score # 계속 반복하여 최적의 임계값과 최적의 f1-score를 리턴한다.최적의 f1-score (모델 평가 지표에 이용)와 최적의 임계값 (모델을 통하여 구한 확률을 0 또는 1로 변경하는 기준점)을 구할 수 있다.
best_threshold, best_score = choose_threshold(best_student_model, val_loader, device)
print(f'Best Threshold : [{best_threshold}], Score : [{best_score:.5f}]')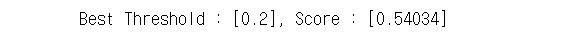
9-2. 위에서 구한 최적의 임계값을 이용하여 테스트 데이터셋의 확률을 0 또는 1로 변경하기.
test_datasets = CustomDataset(test, None, False)
test_loaders = DataLoader(test_datasets, batch_size = CFG['BATCH_SIZE'], shuffle=False)
def inference(model, test_loader, threshold, device):
model.to(device)
model.eval()
test_predict = []
with torch.no_grad():
for x in tqdm(test_loader):
x = x.float().to(device)
model_pred = model(x)
model_pred = model_pred.squeeze(1).to('cpu')
test_predict += model_pred
test_predict = np.where(np.array(test_predict) > threshold, 1, 0)
print('Done.')
return test_predict
preds = inference(best_student_model, test_loaders, best_threshold, device)10. 이진 분류 결과 제출하기.
submit = pd.read_csv('./sample_submission.csv')
submit['Y_LABEL'] = preds # 아까 0 또는 1로 바꾼 결과를 submit의 Y_LABEL에 넣어주기.
submit.head()f1-score를 이용하여 모델을 평가했으니, 그에 맞는 정확도 코드를 찾아서 넣어주면 우리의 모델의 성능을 더 쉽게 알 수 있다.
submit.to_csv('./submit.csv', index=False) # submit 파일을 csv로 저장하기.