
데이터 파악 및 불러오기
- 사용한 라이브러리 및 데이터 불러오기
import pandas as pd
import numpy as np
import seaborn as sns
from matplotlib import pyplot as plt
from collections import Counter
from matplotlib import font_manager,rc
from datetime import datetime
df = pd.read_csv("./data/NetflixOriginals.csv",
encoding = "utf-8")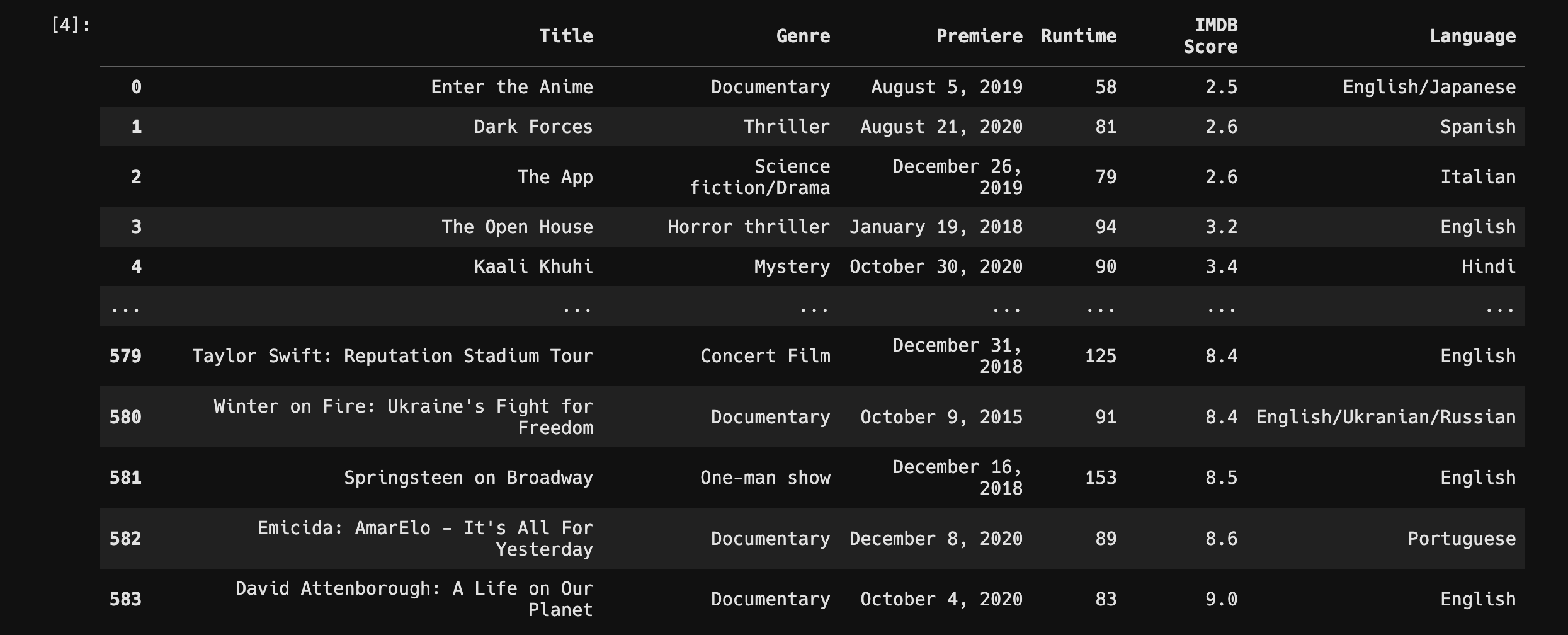
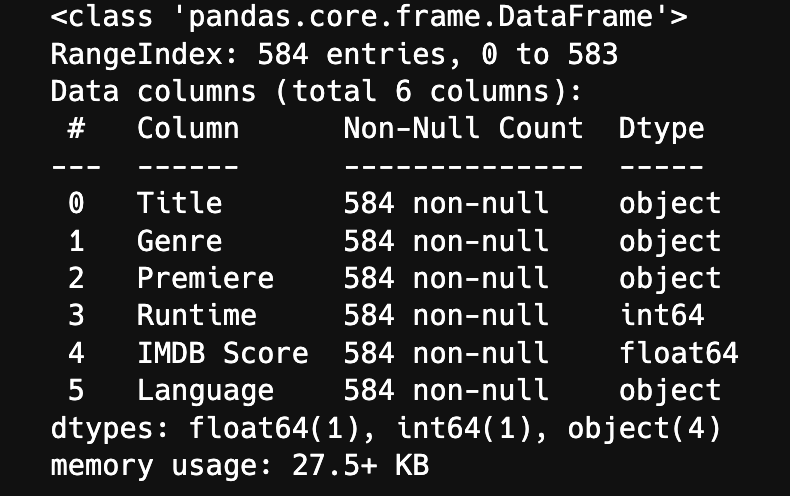
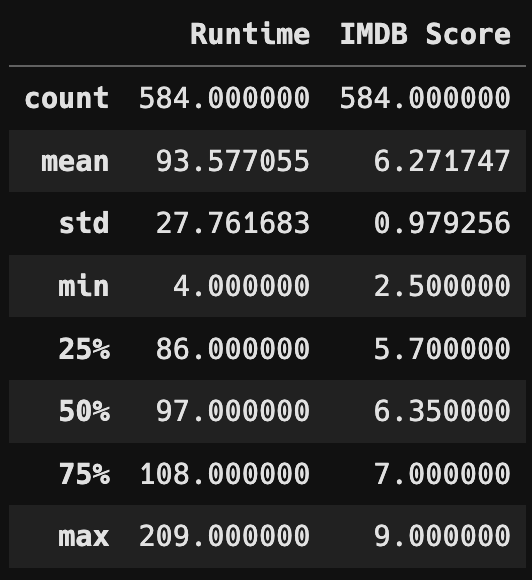
- 데이터 파악 (info, describe)
EDA
장르
- " / "로 뭉쳐있는 장르 분리해주고 비슷한 장르 묶기
tmp = []
for genre in df["Genre"]:
genre = genre.lower()
if "musical" in genre:
tmp.append("musical")
elif "comedy" in genre:
tmp.append("comedy")
elif "thriller" in genre:
tmp.append("thriller")
elif "drama" in genre:
tmp.append("drama")
elif "/" in genre:
genre = genre.split("/")[0].strip()
tmp.append(genre)
else:
tmp.append(genre)
df = df.drop("Genre", axis = 1)
df["Genre"] = tmp-
장르별 작품 수
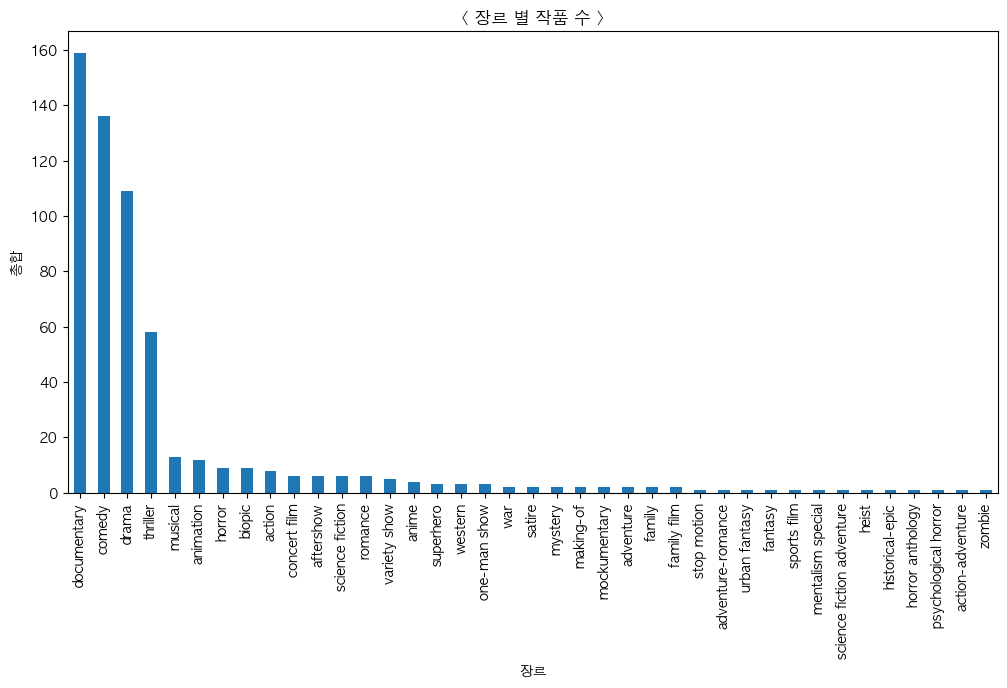
-
장르 별 평균 평점
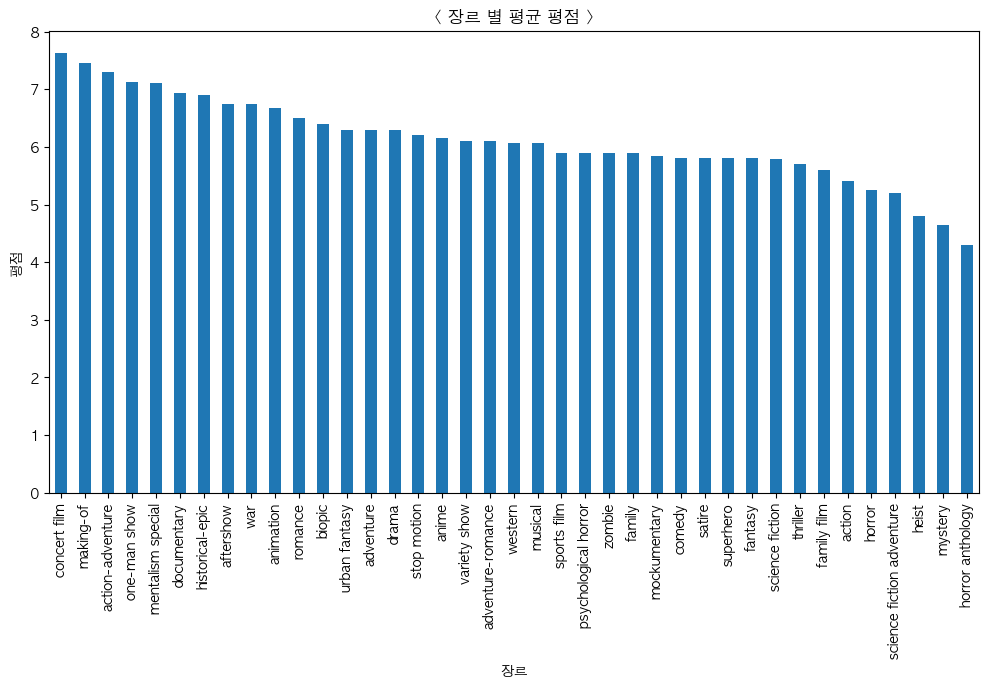
상영 시간
- 상영시간 별 평균 평점
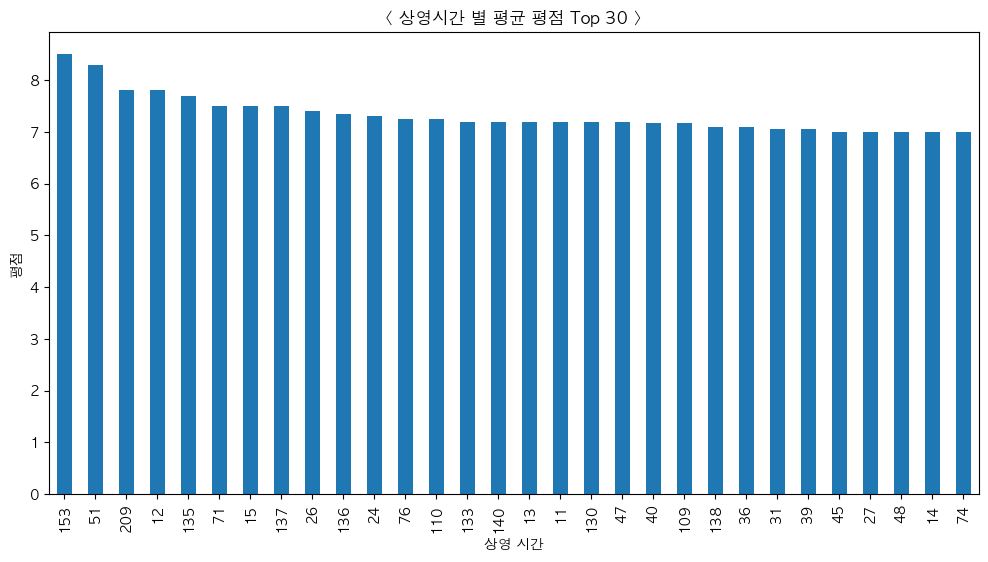
언어
-
전체 언어 카운트
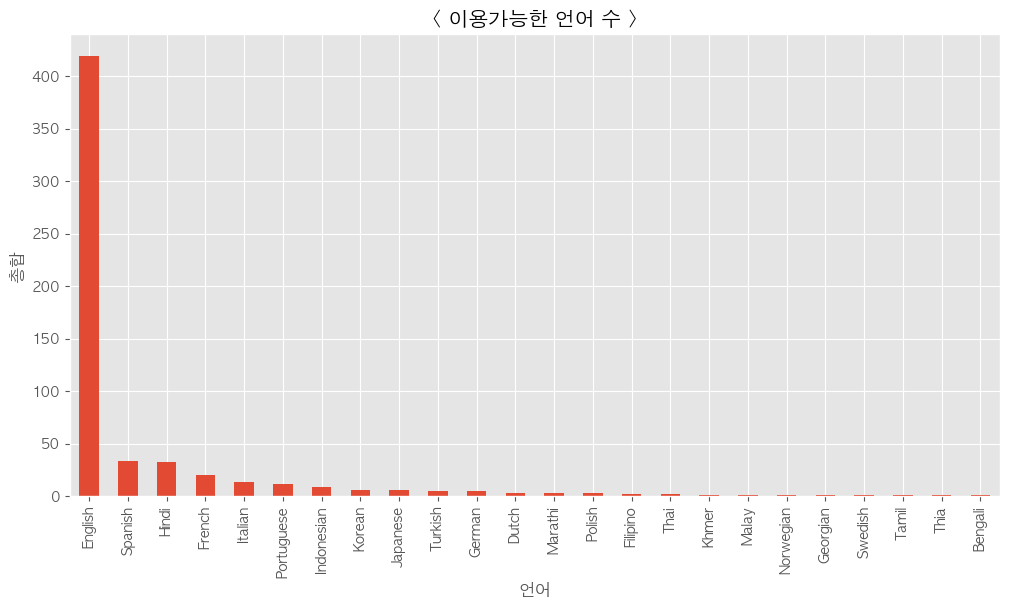
-
언어 별 평균 평점
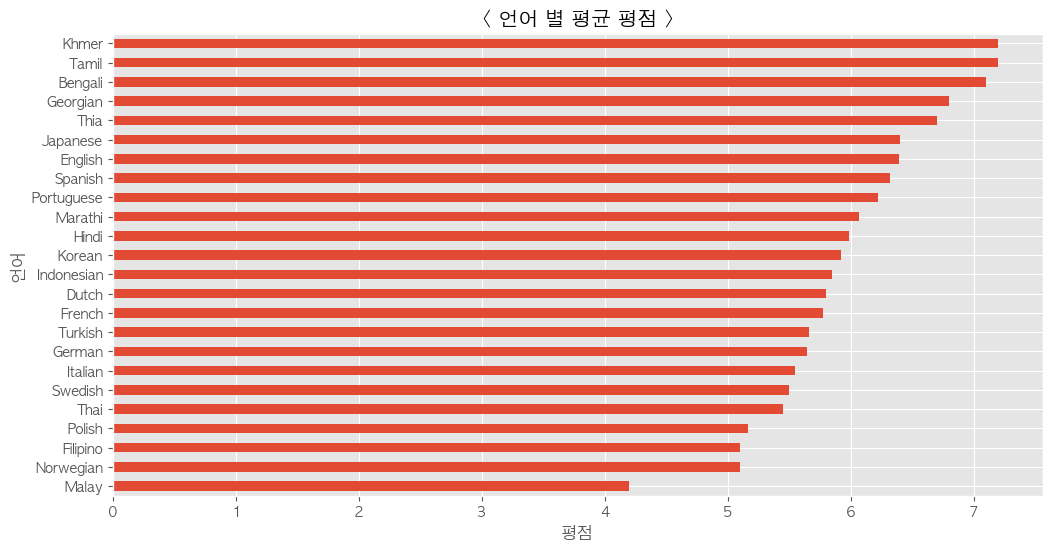
분석
장르
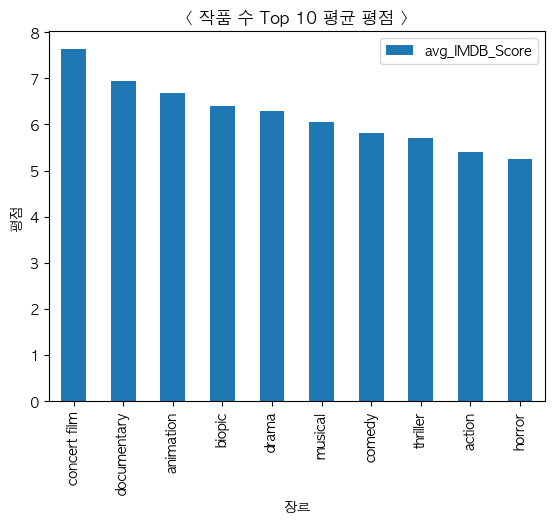
- 작품 수 TOP 10 평균 평점
top_ten_genre = df["Genre"].value_counts()[:10].keys()
for genre in top_ten_genre:
print(genre)
초연 날짜
year = []
month = []
for date in df["Premiere"]:
m = date.split(" ")[0]
y = date.split(" ")[2]
year.append(y)
month.append(m)
df["Premiere_Year"] = year
df["Premiere_Month"] = month
df = df.drop("Premiere", axis = 1)-
연도 별 작품 수, 평균 평점
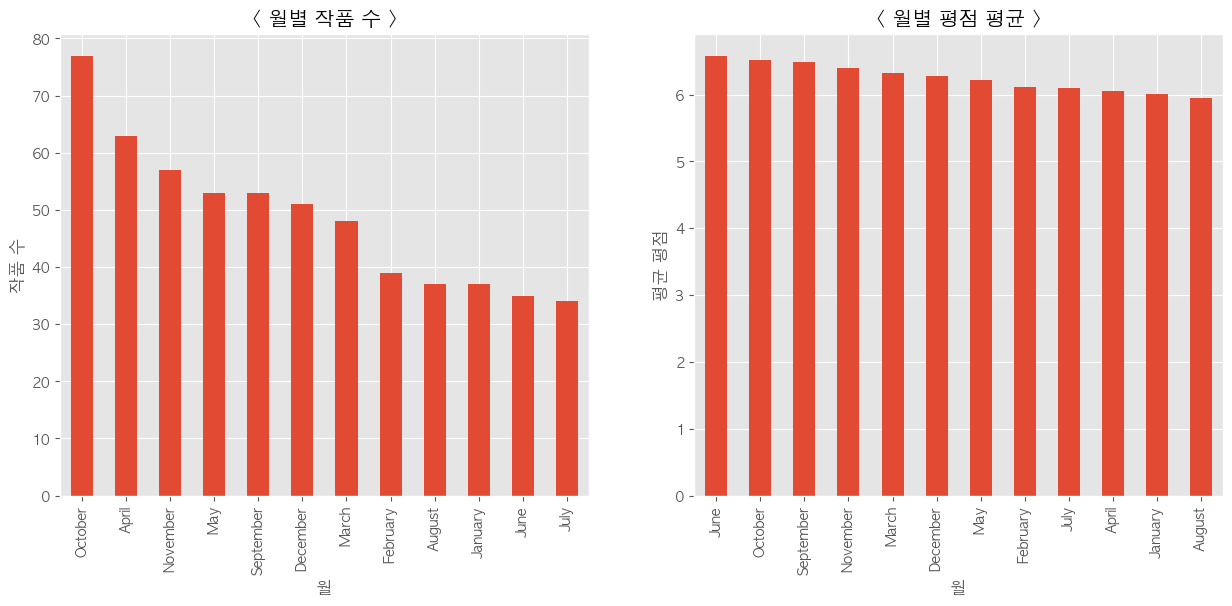
-
월 별 작품 수, 평균 평점
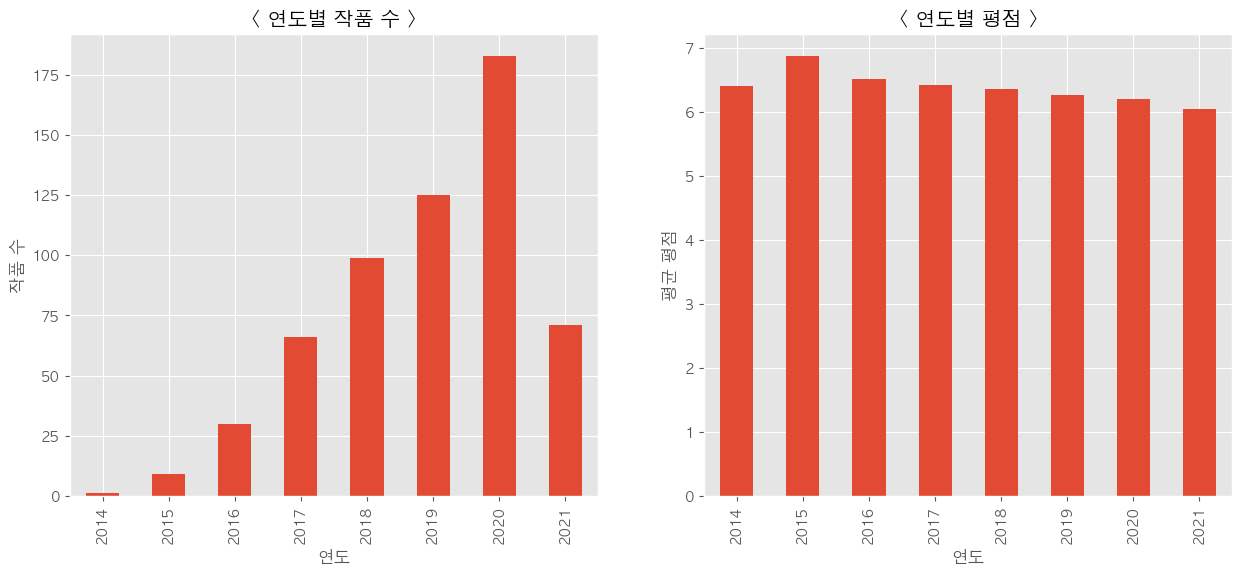
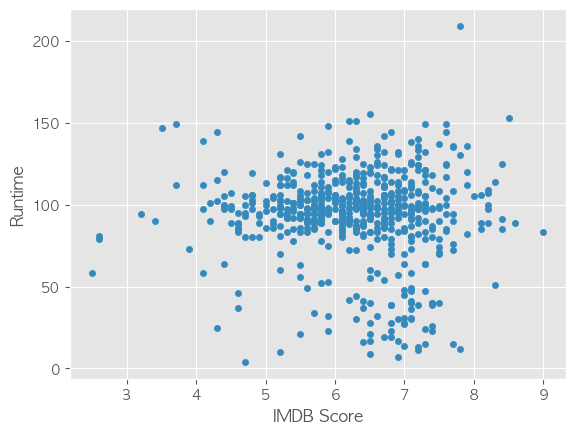
상영 시간
-
상영시간과 평점의 연관성 확인
-
30분 단위 그룹으로 묶은 후 그래프로 확인
tmp = []
for time in df["Runtime"]:
if time < 30:
tmp.append("under_30")
elif time >= 30 and time < 60:
tmp.append("under_60")
elif time >= 60 and time < 90:
tmp.append("under_90")
elif time >= 90 and time < 120:
tmp.append("under_120")
elif time >= 120 and time < 150:
tmp.append("under_150")
elif time >= 150 and time < 180:
tmp.append("under_180")
else:
tmp.append("over_180")
df["Runtime_Group"] = tmp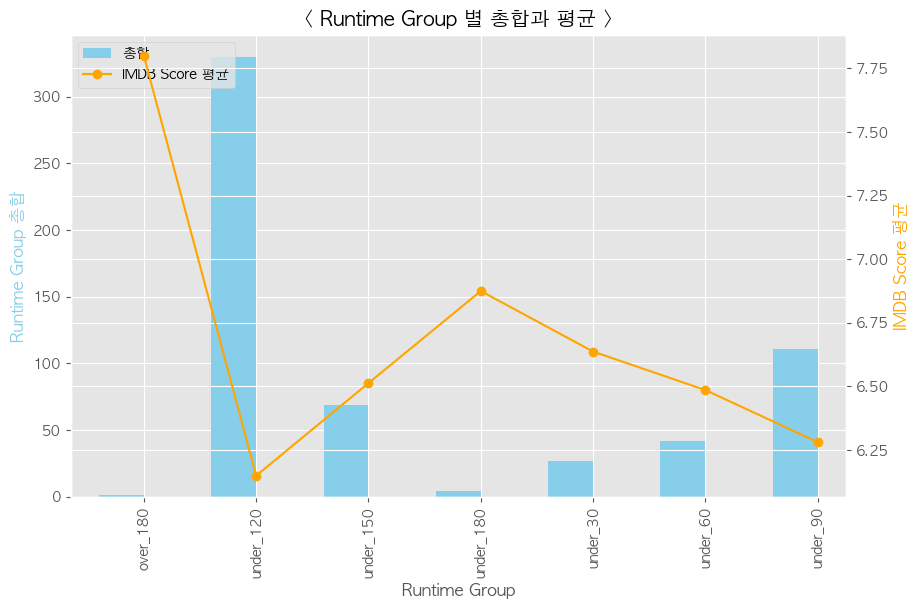
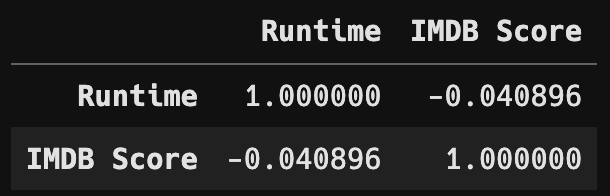
- 피어슨 상관계수로 연관성 한 번 더 확인
언어
- 작품에서 이용가능한 언어 수 별 평균 평점
tmp = []
for language in df["Language"]:
if "/" in language:
if language.count("/") == 1:
tmp.append(2)
elif language.count("/") == 2:
tmp.append(3)
else:
tmp.append(1)
df["Language_Count"] = tmp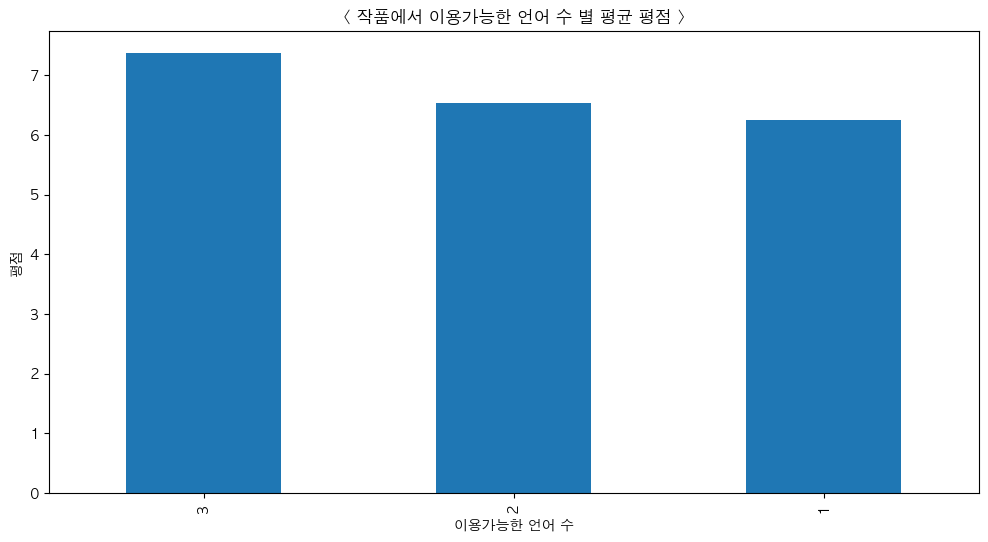
- 작품에서 가장 많이 이용가능한 언어 TOP 10 평균 평점
tmp = []
for language in df["Language"]:
if "/" in language:
tmp.append(language.split("/")[0])
else:
tmp.append(language)
df = df.drop("Language", axis = 1)
df["Language"] = tmp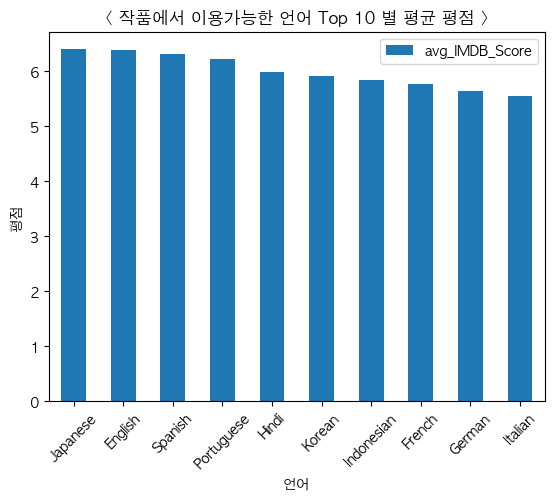
장르 T검정
- Concert film 검정
# 검정할 데이터 설정
not_cf_score = df[df["Genre"] != "concert film"]["IMDB Score"]
cf_score = df[df["Genre"] == "concert film"]["IMDB Score"]
# 등분산 검정
statistics, p_value = stats.levene(not_cf_score, cf_score)
print(p_value)
if p_value > 0.05:
print("등분산")
else:
print("이분산")
# 등분산이 나오므로 등분산으로 T검정 진행
t_statistics, p_value = stats.ttest_ind(
a = not_docu_score,
b = docu_score,
alternative = "less",
equal_var = True
)
# 결과 출력
print(p_value, p_value < 0.05)
- Documentary 검정
# 검정할 데이터 설정
not_docu_score = df[df["Genre"] != "documentary"]["IMDB Score"]
docu_score = df[df["Genre"] == "documentary"]["IMDB Score"]
# 등분산 검정
statistics, p_value = stats.levene(not_docu_score, docu_score)
print(p_value)
if p_value > 0.05:
print("등분산")
else:
print("이분산")
# 이분산이 나오므로 이분산으로 T검정 진행
t_statistics, p_value = stats.ttest_ind(
a = not_docu_score,
b = docu_score,
alternative = "less",
equal_var = False
)
# 결과 출력
print(p_value, p_value < 0.05)
- Horror Anthology 검정
# 검정할 데이터 설정
not_horror_score = df[df["Genre"] != "horror anthology"]["IMDB Score"]
horror_score = df[df["Genre"] == "horror anthology"]["IMDB Score"]
# 등분산 검정
statistics, p_value = stats.levene(not_horror_score, horror_score)
print(p_value)
if p_value > 0.05:
print("등분산")
else:
print("이분산")
# 등분산이 나오므로 등분산으로 T검정 진행
t_statistics, p_value = stats.ttest_ind(
a = not_horror_score,
b = horror_score,
alternative = "greater",
equal_var = True
)
# 결과 출력
print(p_value, p_value < 0.05)
- concert film, documentaty 장르가 IMDB Score를 높게 받은 것이 우연히 발생한 일이 아닌 원인이 있는 사건임을 T검정으로 확인
- horror anthology 장르가 낮은 점수를 받은 것도 우연히 발생한 일이 아닌 인과관계를 갖고 발생한 사건임을 T검정으로 확인
인사이트 도출
- 콘서트 필름, 다큐멘터리, 애니메이션 종류가 매니아 층이 있어서 그런지 좋은 평점을 받은 걸 확인할 수 있었다.
- 호러, 스릴러, 미스터리 같은 장르들은 낮은 평점을 받은 걸 확인할 수 있었다.
- 초연 날짜를 월로 정리한 그래프를 봤을 때 6월에는 평균적으로 많은 작품이 개봉되지 않는데 좋은 평가를 받은 작품들이 많은 것을 확인할 수 있었다.
- 이용가능한 언어가 다양할수록 시청가능한 고객들의 범위도 넓어져 평점이 좋아질 수 있다.
마무리
액션 아이템 제시
- 평균적으로 평점이 낮은 장르들이 나라 별로 잘 어울리는 시즌에 맞추어 평점이 좋았던 작품이나 인기가 많았던 작품을 추천해주는 방식으로 대중들에게 인기가 낮은 작품의 관심도를 올리게 만들어야한다.
- 매니아층들이 밀집되어있는 장르들 같은 경우에는 매니아들의 평가가 굉장히 후하기 때문에 매니아층의 소비자들을 이탈하지 않게 만들기 위해서는 타 OTT사이트보다 먼저 좋은 작품을 준비할 수 있도록해 더 나은 매니아층의 컨텐츠를 제공할 수 있도록 준비해야한다.
- 하나의 작품을 더 다양한 국가들에서 시청 가능하도록 번역 서비스를 제공해야한다. 그러나 번역가를 구하기 힘든 언어는 AI 번역을 활용하여 제공할 수 있도록 해야한다.
- 초연날짜 그래프를 보면 1월, 2월, 6월, 7월, 8월에 개봉하는 작품들이 현저히 적은 것을 확인할 수 있는데 아무래도 새로운 컨텐츠의 작품이 적은 달일 때에는 소비자의 유입이 줄어들 수 밖에 없고 이러한 상황에서 소비자들의 이탈을 최소화하기 위해서는 평가가 좋은 감독의 보장된 작품이나 신인 감독들의 창의적인 작품의 개봉일을 작품 개봉이 적은달로 잡아 늘 좋은 작품을 소비자들에게 경험할 수 있도록 해야한다.

어렵지만 이겨내보겠습니다