
오늘은 publish된 여러 FL Framework중, Flower라는 Framework에 대해 다뤄보도록 하겠습니다.
Federated Learning Framework Issue
일반적으로 알려져있는 Federated Learning Framework는 몇가지 issue가 존재합니다.
OpenFL
- Github : https://github.com/intel/openfl
Intel에서 제공하는 OpenFL Framework → single server기준으로 serial하게 구현되어 있습니다.
(e.g., Client 0 -> Client 1 -> Client 2 -> Client 3 -> Client 4 -> Client 5.... Client 10)
.png)
Figure 1. OpenFL slack
- OpenFL does not support parallel trainings
OpenFL은 single gpu 기준으로 local client가 serial하게 학습하도록 구현이 되어있기에, computing time이 많이 소요된다는 단점을 지닙니다.
그럼 computing time을 줄이려면 어떻게 해야 할까요?
Flower - A Friendly Federated Learning Framework
오늘 소개드릴 Framework인 Flower는 각 local client를 서로 parallel하게 학습하도록 구현되어 있습니다. Framework document 및 해당 github link는 다음과 같습니다.
- Flower documentation : https://flower.dev
- Flower git : https://github.com/adap/flower
Process
Process과정에 대해 살펴보도록 하겠습니다.
1. 각 client에게 할당할 cpu수 지정
client_resources = {
"num_cpus": args.num_client_cpus} # each client will get allocated 1 cpus우선적으로, 각 client에게 할당할 cpu갯수를 지정해줍니다. 만약 client가 10명이고 client에게 할당할 cpu수를 1로 두면 10개의 cpu를 사용하게 됩니다. 서버 환경에 맞게 cpu수를 조절하시면 됩니다. (e.g., nproc를 통해 확인)
2. Data partition
fed_dir = do_fl_partitioning(
train_path, pool_size=pool_size, alpha=1000, num_classes=10, val_ratio=0.1)pool_size는 dataset의 partions을 의미합니다. (즉, pool_size는 client수를 의미)
만약 MNIST를 partition한다고 해보자.
- MNIST(trainset) : 60000
- Pool_size를 100 → 각 client는 600개의 data를 갖게 됨(iid setting인 경우)
- 그러나 realistic setting에선 각 client가 가지는 data수는 다 다를 것임. (client 1 : 10, client 2 : 100, client 3 : 75, client 4 : 60)
- 그러나 realistic setting에선 각 client가 가지는 data수는 다 다를 것임. (client 1 : 10, client 2 : 100, client 3 : 75, client 4 : 60)
- Alpha값을 통해 각 client가 가지는 label의 distribution을 조절함 (Dirichlet distributions)
Alpha값에 따른 histogram
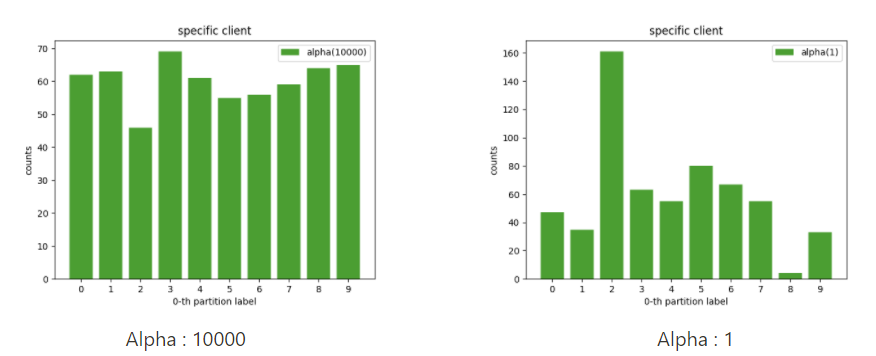
위 그림은 첫번째 client가 가지는 label의 distribution을 의미합니다. Alpha값이 1일때, non-iid 경향이 큼을 확인 할 수 있고, Alpha값을 키울수록 iid에 가까워짐을 확인 할 수 있습니다.
3. Server strategy(aggregation method)
strategy = fl.server.strategy.FedAvg(
fraction_fit= 0.1,
fraction_eval = 0.1,
min_fit_clients = 10,
min_eval_clients = 10,
min_available_clients=pool_size, # All clients should be available
on_fit_config_fn=fit_config, #send a configuration
eval_fn=get_eval_fn(testset), # centralised testset evaluation of global model
각 local client에 대해 학습을 진행한후, 각 client가 가지는 weight를 aggregation해서 server에 넘겨줘야 합니다.
Aggregation method(strategy) : FedAvg
- Fraction_fit / Fraction_eval : train / val에 참여할 client 비율의 의미함.
- 전체 client를 100명, fraction_fit(0.1)로 두면 매 round 학습에 참여하는 client는 10명
- Min_fit_clients / min_eval_clients : train / val에 참여하는 min client
- Min_available_clients = pool_size → 전체 client수
- Eval_fn → global model에 대한 evaluation
4. Start simulation(aggregation method)
fl.simulation.start_simulation(
client_fn=client_fn,
num_clients=pool_size,
client_resources=client_resources,
num_rounds=args.num_rounds,
strategy=strategy)
Client, server, strategy를 통해 간단하게 simulation을 진행해 보았습니다.
Experiment settings
Dataset
- Mnist (60000/10000)
Client
- Client : 100
- fraction rate : 0.1
- Local epoch : 1
- Local batch : 64
- num_client_cpus : 1
Server
- Global batch : 128
- Global epoch : 500
Model
- CNN (parameters : 21,840)
Experiment results
.png)
Process
- 매 round마다 전체 client의 10%를 무작위로 추출하여 학습에 반영
- 전체 client 100명 → 매 round마다 10명씩 추출.
- 각 client → parallel하게 학습을 진행(multi process) → weight aggregation(FedAvg)
- Aggregation weight → global model → evaluation(testset)
Training time
- Client : 0.68s / epoch
- Server(eval) : 2.4s / epoch
- 1round : about 3.1s → 500round : 25m 40s
Training time 비교
동일한 세팅으로 serial / parallel training time check
- Serial : 51m
- Parallel : 25m
→ parallel로 setting후 실험을 진행했을때, 약 36분 단축
Loss / Accuracy
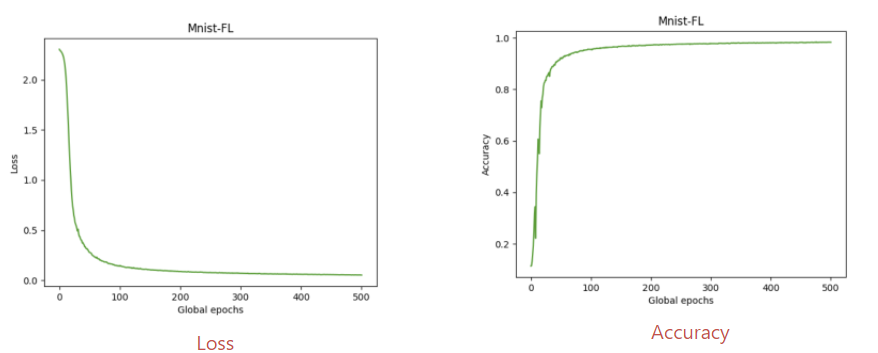
- Loss가 잘 converge함을 확인 할 수 있음.
- 마지막 global epoch기준, accuracy 98.3%
Conclusions
-
Federated Learning을 parallel하게 구현된 Framework인 Flower에 대해 살펴봄
-
Mnist dataset에 대해 test진행
Issue
- 추가로 cifar10에 대해 학습을 진행(이때, Mnist와 동일한 세팅)
- Loss가 수렴하지 않는 issue 발생
궁금증이 해결되지 않아서 slack을 통해 여쭈어 보았다.
Framework developer의 답변 : 노력해볼게! (Probably ㅎㅎ..)
내가 해봐야지..
