.png)
오늘은 Backdoor attack paper를 읽어보면서 federated learning에 backdoor를 어떻게 접목시켰는지 공부해보는 시간을 가져 보았습니다.
Backdoor Attack
Federated Learning에서 많이 사용되는 weight aggregation방식인 Federated average자체로 backdoor attack를 다소 완화시킬 수 있다고 알려져 있습니다.
Federated Learning Process는 다음과 같습니다.
→ Local client를 Local에서 학습 → Local model의 weight를 aggregation → aggregation된 weight를 평균내서 global model의 weight를 update.
Backdoor attack Assumption & Object
Method설명에 앞서 Backdoor Attack의 목적 및 가정에 대해 설명하도록 하겠습니다.
Backdoor attack 가정(Assumption)
Federated learning with poisoned attacks
- 공격자(attacker)는 local data/model(the training process)에 접근 가능
- Malicious client → single/multi
Backdoor attack 목적(Object)
- Federated learning to produce a joint model that achieves high accuracy
- main task/attacker-chosen backdoor subtask
Method(Backdoor attack #1)
How to backdoor Federated Learning
본 연구에서는 공격(attack)방법으로 Model replacement를 제안합니다. 이 방법은 공격자가 global model의 weight를 악의적으로 조작하는 방법을 의미합니다. 범용적으로 알려져있는 Federated Learning setting에서의 global model weight가 update되는 방식은 다음과 같습니다.
Notation
- Global model :
- Local model :
- Global learning rate :
- Local data sample :
Model replacement process
Local model은 communication round(global epoch)를 거치게 되면서 local model, global model간의 weight 차이가 근소해집니다. 본 연구에서 특정 공격자가 지정한 특정 Local 모델의 weight를 인위적으로 조작함으로써, 를 만들게 됩니다.
예를 들어, local model이 개라 가정해보자.
- 공격자(Attacker)가 지정한 model()을 제외한 개의 local/global model간의 차이는 0에 수렴
- Train locally on backdoored data
- Modify loss function
- Slow down learning rate during local training → backdoor stronger
위 과정을 통해 를 생성한 후, 서버에 공격자의 gradient를 전송합니다.
공격자(attacker)를 제외한 다른 participant와 global model의 gradient 값이 0에 수렴할때쯤 를 통해 공격을 진행하게 되고, 공격자의 gradient의 비중을 높임으로써 backdoor 공격 성공률을 높인다.
Model replacement attack's effect
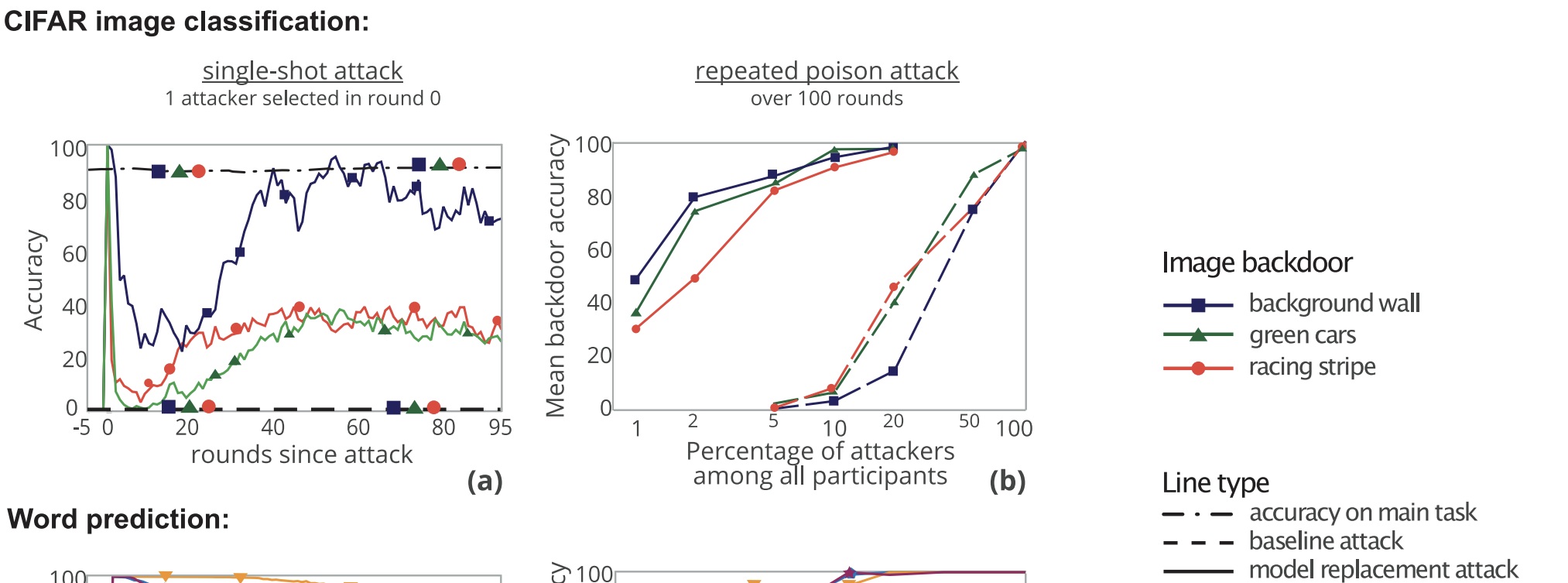
실험해석
5 rounds 이전 95 round 이후 single-shot attack을 진행
- Main task에 대해 성능 유지
- The accuracy of the global model on the backdoor task immediately reaches almost 100%, then gradually decreases
- reason #1 : objective landscape가 convex하지 않다는 가정
- 초반 round에 local minimum도달 → 다른 client(clean)가 참여함으로써 global minimum도달
- reason #2 : 공격자(attacker)는 낮은 learning rate를 이용하여 global model에 가까운 backdoor를 가진 모델을 찾는데 focusing
- reason #1 : objective landscape가 convex하지 않다는 가정
Repeated poison attack
- 공격자(attacker)의 비율이 증가함에 따라 backdoor accuracy증가
Method(Backdoor attack #2)
다음은 data poison attack에 대해 설명하도록 하겠습니다.
DBA : DISTRIBUTED BACKDOOR ATTACKS AGAINST FEDERATED LEARNING [ICLR 2020]
악의적인 client가 local data에 접근이 가능하다는 가정
.png)
Distributed backdoor attack on federated learning
Motivation
- The level of poison is weaker than centralized attackers → actually more difficult to detect whether that the gradient from poison the agent is uh it’s an outlier
- The gradient of from those poison agents is actually less is less obvious
- It’s realize because each agent now carries less poison
- It actually makes them more aligned to the regular gradient and hence its more difficult to detect
Centralized backdoor attack via DBA
- Centralized backdoor attack(e.g., Model replacement attack)
- Benign participants + centralized attacker
- Global trigger pattern(동일한 위치)
- Single attack
- DBA : distributed backdoor attack
- Benign participants + distributed attackers
- Decomposes global trigger into local patterns
- Single / multiple attack
Conclusions
- Federated Learning에 backdoor attack을 접목시킨 방법 설명.
- Backdoor attack은 크게 Centralized / Distributed attack으로 나눠짐.
- Model poisoning attack / Data poisoning attack
- Backdoor attack method로 Model replacement, DBA를 살펴봄.
- Local model에 backdoor attack을 가해도 attack에 성공함을 확인함.
- 이는 추후 security관점에서 중요한 issue가 될 것이라는 주관적인 판단.
Question
- 악의적인 client의 attack을 defense하는 방법은 있을까?
- Backdoor attack에 대한 defense관련 paper 읽기!
