FederatedReverse: A Detection and Defense Method Against Backdoor Attacks in Federated Learning
Federated-Learning
.png)
이번에 소개드릴 논문은 다음과 같습니다.
FederatedReverse : A Detection and Defense Method Against Backdoor Attacks in Federated Learning
Background
먼저 Federated Learning에 대해 살펴보도록 하겠습니다.
현재까지 Data가 가지는 privacy/security issue는 계속적으로 증가하고 있습니다.
Federated Learning이란, 각 client가 가지는 data를 local에서 학습시키고 개별 client로부터 학습된 각 local model의 weight값을 aggregation이후 server로 전달하여 global model의 weight를 update시키는 방식을 의미합니다.
.png)
Figure 1 : Federated Learning architecture
Server는 local client가 가지는 data에 접근할 수 없기 때문에, 각 local client가 가지는 data의 privacy issue를 해결할 수 있습니다.
Federated Learning가 가지는 issue
본 연구는 Federated Learning이 가지는 여러 issue중, backdoor attack을 중점적으로 다룹니다.
- 악의적인 local client가 local data에 접근할 수 있다는 가정
Backdoor attack의 목적
- 특정 공격자(attacker)가 image에 trigger를 추가하여 공격자(attacker)가 사전에 정의한 label로 학습
- 고양이 image에 trigger를 추가하여 강아지로 예측
- Backdoor가 심어진 classfier는 이러한 trigger로 인하여 image를 오분류 할 수 있음
Backdoor attack의 목적
- Main task에 대해선 성능을 유지
- Backdoor가 심어진 data에 대해서 높은 공격 성공률을 달성
Method
.png)
Figure 2 : FederatedReverse schematic diagram
FederatedReverse의 전체적인 process는 다음과 같습니다.
Client → Global model → Generate reverse trigger → Central aggregation server → Outlier Detection → Model Repair
- Reverse Engineering 하기에 앞서, 각 client는 이전 round()에서 얻은 Global model을 사용.
1. Reverse Engineering
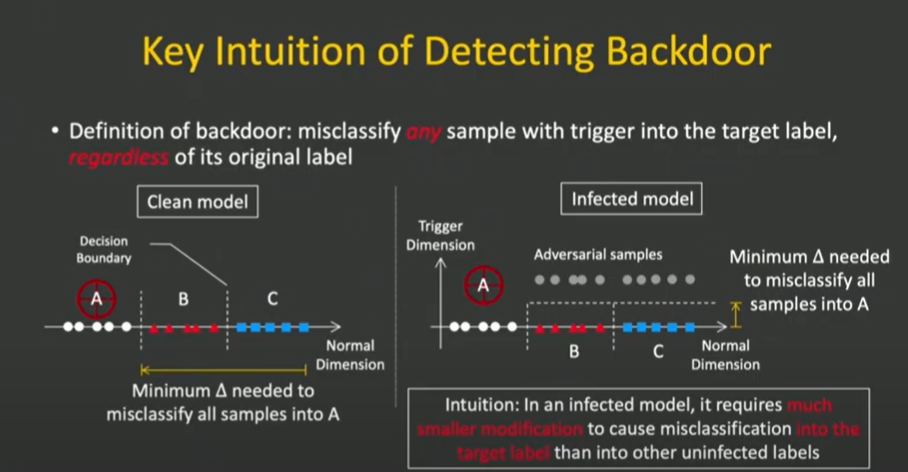
Figure 3 : Principles of reverse engineering
모든 sample을 특정 label로 식별하기 위해 필요한 perturbation을 로 정의해 보겠습니다.
Benign model
- Class B / C → Label A로 오분류하는데 드는 perturbation은 (, )로 정의됩니다.
- : Class B / C에 속한 sample을 Class A로 분류하는데 필요한 perturbation
Poisoned model
만약 Class A가 공격을 받으면 decision boundary가 변경됨
- Class B / C(Clean label) → Infected label : 약간의 perturbaton를 가해도 Class A로 예측 가능 ()
- Clean label → Clean label : data자체를 바꾸는데 필요한 perturbation값이 매우 큼(개 → 고양이)
→ 즉, 는 , 보다 값이 작다는 사실을 도출 할 수 있습니다.
각 local client는 local data의 각 label에 해당하는 reverse trigger를 구하게 됩니다. (e.g., , , )
예를 들어, 첫번째 client가 총 3개의 class(A, B, C) 정보를 담고 있는 data를 가지고 있다고 가정해보자.
- 첫번째 client로부터 얻을 수 있는 reverse trigger : , ,
How to make trigger?
Reverse trigger를 만드는 과정은 다음과 같습니다.
Notation
: original image
: mask matrix (Reverse trigger’s magnitude)
: pixel intensity pattern (Reverse trigger pattern)
- Mask matrix()는 [0,1] 사이의 값을 2-dimension matrix로 original image()에 적용할 범위를 나타냄.
- Pixel intensity pattern()은 original image()와 동일한 dimension을 나타냄.
An image with a trigger
- 우선 original image 를 가지고 , 를 통해 생성
- 생성된 로부터 Objective function을 minimize하는 , 값을 도출
Objective function of training reverse trigger
- : Regularization term을 의미
- : Mask matrix의 size를 조절해주는 norm
- : Mask와 pixel intensity pattern을 조절해주는 term을 의미
- : 특정 local participant가 가지는 sample set의 label
- : Cross entropy term (local participant가 가지는 , 의 output)
즉, 각 local client는 가지는 sample set의 각 label에 대해 reverse trigger를 구하게 됩니다.
Example
첫번째 Local client가 3개의 class(A, B, C)에 속한 데이터를 가지고 있다고 가정.
Class A → , , Class B → , , Class C → , 가
- 각 Class로부터 얻은 , 값을 server로 전달
, 의 역할 (Reverse trigger)
- : the magnitude of the trigger by the L1 norm of the mask
- : trigger pattern
2. Global Reverse Trigger Generation
.png)
- 각 local client로부터 생성된 local reverse trigger(, ) → Central server로 보냄
- 각 local client에 대해 동일한 label로 aggregation
Example
3명의 Client가 있고, 각 Client는 class(A, B, C)를 가지고 있다고 가정
Notaion
- , : 첫번째 client, class A 에 해당하는 , 집합
Local reverse trigger
- Client 1 : { , , }, {, , }
- Client 2 : { , , }, {, , }
- Client 3 : { , , }, {, , }
Global reverse trigger
각 client로부터 도출된 , 를 Label기준으로 aggregation후 global reverse trigger생성
- Label A : {}, {}.
- Label B, Label C도 위와 동일
→ 논문에 Global reverse trigger에 대한 설명이 명시되어 있지 않음.. (논문 5-3)
3. Outlier Detection
Global reverse trigger생성 후, 이상치 탐지 과정을 수행합니다.
본 연구에서는 이상치 감지 알고리즘으로 absolute median method를 사용하였습니다.
Abnormal score()
- 각 label에 해당하는 global reverse trigger()값으로부터 L1 norm값을 구합니다.
Example
- Label A, B, C →
- 와 값을 통해 각 label에 대한 Abnormal score을 계산
- Abnormal score() → 특정 값(2로 명시)을 넘으면 outlier로 처리 → Infected label
만약 Label A가 abnormal score가 2를 넘으면 Infected label로 간주
4. Model Repair
만약 Global model이 공격받은 대상으로 detection되었을때, unlearning technology를 적용하여 model을 repair 수행하게 됩니다.
Unlearning technology
- Model이 image 특정 pattern의 영향을 잊게 하는것
- Model은 attacker가 심은 trigger와 label간의 관계를 학습하지 못하도록 적용
- 감염된 label에 대응하는 reverse trigger를 clean data에 추가(동일한 label)
→ Trigger의 영향을 제거하고 backdoor attack으로 부터 defense
Conclusions
- 본 연구에서는 Federated learning에서의 backdoor attack을 효과적으로 detect.
- Model repair를 통해 공격자(attacker)가 이식한 backdoor의 영향을 제거하는 방안 제안
- FederatedReverse
- Main task의 성능은 유지하면서 backdoor attack의 attack success는 낮춤
Reference
- Neural Cleanse: Identifying and Mitigating Backdoor Attacks in Neural Networks
