학습내용
Logistic Regression, Polynomial regression, SelectKBest를 이용한 classification 및 모델 검증
데이터 생성
df = pd.read_csv('https://ds-lecture-data.s3.ap-northeast-2.amazonaws.com/cardio/cardio_train.csv', sep=';')EDA 및 전처리
#id drop
df.drop('id', axis = 1, inplace = True)
#missing value
miss = df.isna().sum().sum()
print('missing value : ', miss)
#중복 확인
print('중복 제거 전 length : ',len(df))
df.drop_duplicates(inplace = True)
print('중복 제거 후 length : ', len(df))#correlation 확인
plt.figure(figsize=(8,6))
sns.heatmap(df.corr()[['cardio']].sort_values('cardio', ascending=False), annot=True);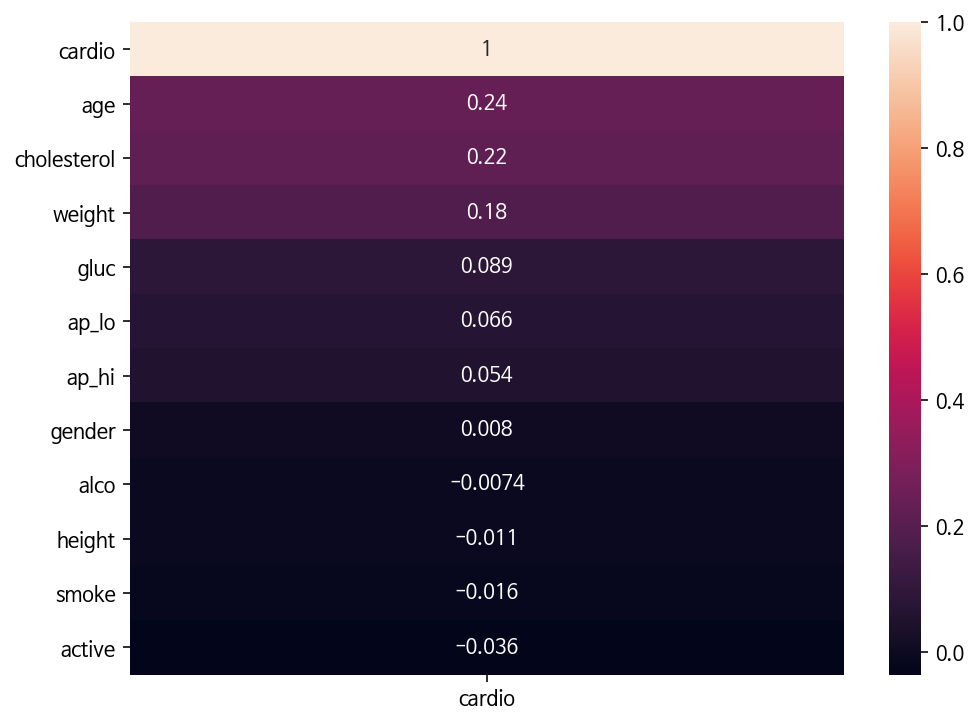
#각 칼럼별 분포확인
plt.figure(figsize = (20,12))
plt.title('Distribution')
for i, col in enumerate(df.columns):
plt.subplot(3,4,i+1)
sns.distplot(df[col])
plt.show()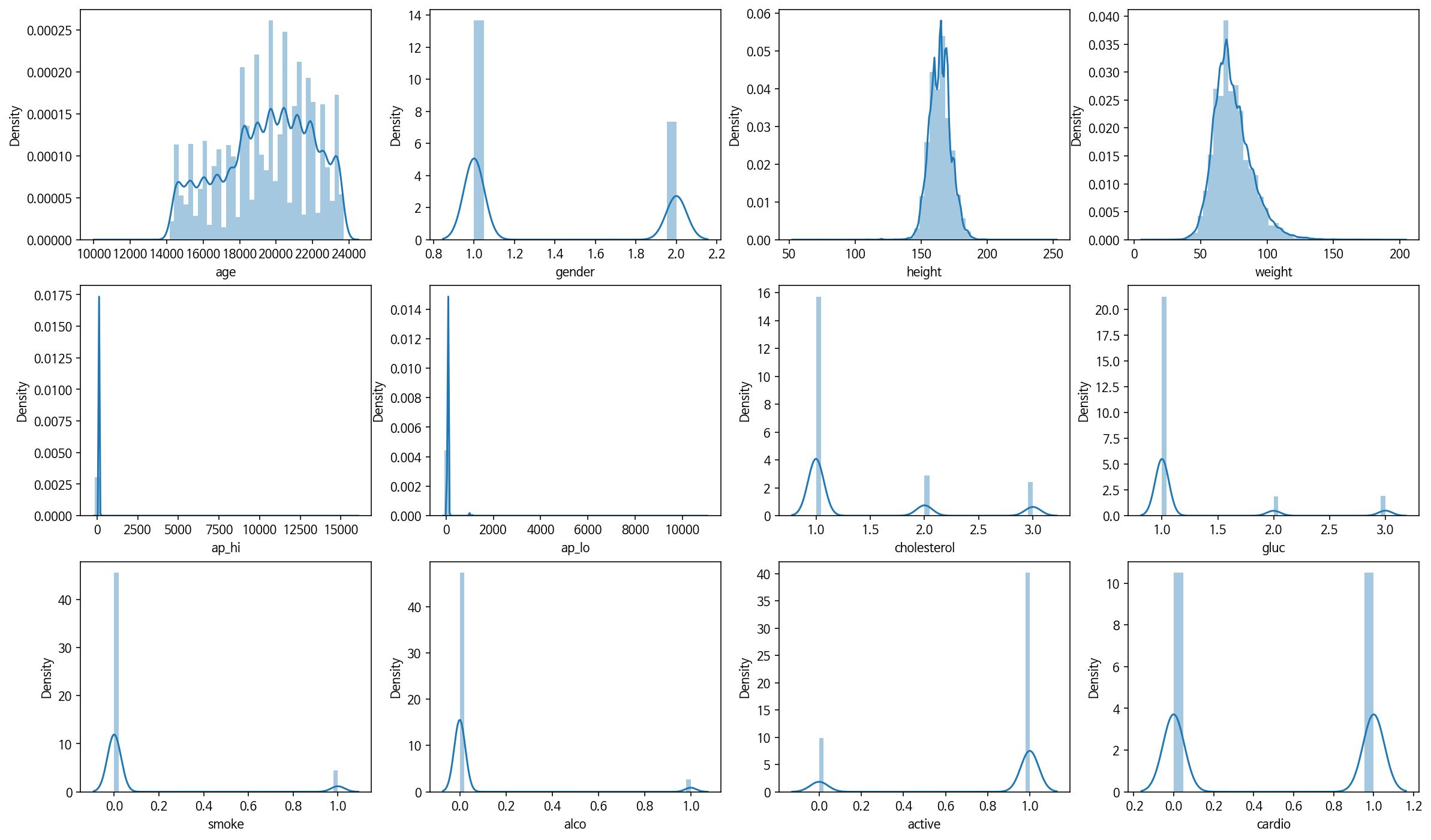
#심장박동 boxplot
plt.figure(figsize=(15,6))
plt.subplot(1,2,1)
plt.boxplot(df['ap_hi'])
plt.title('ap_hi')
plt.subplot(1,2,2)
plt.boxplot(df['ap_lo'])
plt.title('ap_lo')
plt.show()
#사람의 심장박동가능 범위로 이상치 처리
condition1 = (df['ap_lo'] > 50) & (df['ap_lo'] <= 200)
condition2 = (df['ap_hi'] > 50) & (df['ap_hi'] <= 150)
df = df[condition1 & condition2]
df.head()#scaling
#min-max
from sklearn.preprocessing import MinMaxScaler
scaler_M = MinMaxScaler()
df[['age', 'height', 'weight', 'ap_hi', 'ap_lo']] = scaler_M.fit_transform(df[['age', 'height', 'weight', 'ap_hi', 'ap_lo']])
#standardscaler
# from sklearn.preprocessing import StandardScaler
# scaler_S = StandardScaler()
# df[['age', 'height', 'weight', 'ap_hi', 'ap_lo']] = scaler_S.fit_transform(df[['age', 'height', 'weight', 'ap_hi', 'ap_lo']])features = list(df.columns)
features.remove('cardio')
target = ['cardio']
X = df[features]
y = df[target]
# test-train split
X_train_val, X_test, y_train_val, y_test = train_test_split(X, y, test_size = 0.2, random_state=2)
# train-validation split
X_train, X_val, y_train, y_val = train_test_split(X_train_val, y_train_val, test_size = 0.2, random_state=2)Feature engineering
polynomial feature들을 selectkbest를 이용하여 유의미한 순서로 10개 select하여 feature extraction하는 방식을 취함
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import make_pipeline
from sklearn.feature_selection import f_regression, SelectKBest
poly = PolynomialFeatures(2)
poly_X_train = poly.fit_transform(X_train)
all_names = pd.DataFrame(poly.get_feature_names(X_train.columns)) #polynomial column들을 all_names에 dataframe으로 저장
selector = SelectKBest(score_func = f_regression, k = 10)
selector.fit_transform(poly_X_train, y_train)
mark = selector.get_support()
select_names = all_names[mark]
poly_select_X_train = pd.DataFrame(poly_X_train[:,select_names.index], columns = select_names[0]) #선택된 10개의 column을 가지는 X_train 생성
poly_select_X_train
#위의 처리과정을 함수로 생성
def to_poly_select(X):
poly = PolynomialFeatures(2)
poly_X = poly.fit_transform(X)
poly_select_X = pd.DataFrame(poly_X[:,select_names.index], columns = select_names[0]) #선택된 10개의 column을 가지는 X_train 생성
return poly_select_XModeling 및 검증
#X_val, X_test 형태 변환
poly_select_X_val = to_poly_select(X_val)
poly_select_X_test = to_poly_select(X_test)
Logistic = LogisticRegression(C = 0.1, max_iter = 1000)
Logistic.fit(poly_select_X_train, y_train)print('Min-Max scaling')
print('Validation R2 : ', Logistic.score(poly_select_X_val, y_val))
print('Test R2 : ', Logistic.score(poly_select_X_test, y_test))Min-Max scaling
Validation R2 : 0.713045175139038
Test R2 : 0.714252263502966
print('Standard scaling')
print('Validation R2 : ', Logistic.score(poly_select_X_val, y_val))
print('Test R2 : ', Logistic.score(poly_select_X_test, y_test))Standard scaling
Validation R2 : 0.7009464337984194
Test R2 : 0.6997346237901967
