h1n1 캐글 대회
작성코드
라이브러리 import
import numpy as np
import pandas as pd
from pandas_profiling import ProfileReport
import pandas_profiling
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, f1_score
from sklearn.impute import SimpleImputer
from sklearn.pipeline import make_pipeline
from sklearn.tree import DecisionTreeClassifier, export_graphviz
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import GridSearchCV
import seaborn as sns
import matplotlib.pyplot as plt
import graphviz
EDA
target = ['vacc_h1n1_f']
train_val = pd.merge(pd.read_csv('train.csv'), pd.read_csv('train_labels.csv')['vacc_h1n1_f'], left_index = True, right_index = True)
test = pd.read_csv('test.csv')
ProfileReport(train_val, minimal=True).to_notebook_iframe()
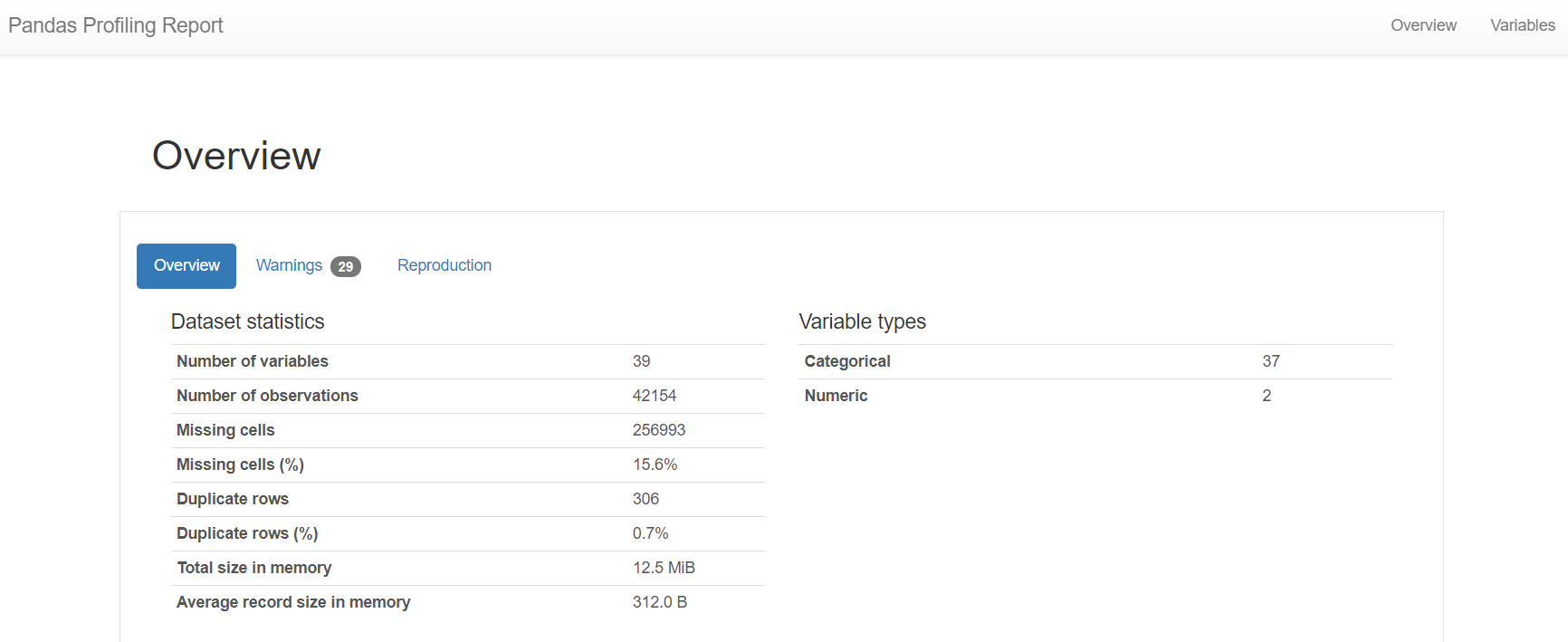
print('class 비율 : \n', train_val[target].value_counts(normalize = True))
y_pred = len(train_val) * [0]
acc = accuracy_score(train_val[target], y_pred)
print('\n기준모델의 accuracy : ', round(acc,2))
전처리 및 Feature engineering
train_val.drop_duplicates(inplace = True)
train_val.drop(['state', 'employment_occupation', 'employment_industry'], inplace = True, axis = 1)
train_val.dropna(how = 'any', inplace = True)
le = LabelEncoder()
cols = list(train_val.columns)
for col in cols:
train_val[col] = le.fit_transform(train_val[col])
X_train_val = train_val.copy()
X_train_val.drop(target, inplace = True, axis = 1)
y_train_val = train_val[target]
X_train, X_val, y_train, y_val = train_test_split(X_train_val, y_train_val, test_size=0.2, random_state = 1)
모델링
param_grid = {
'min_samples_split' : [50, 100, 200, 300, 400, 500, 600, 700, 800, 900, 1000],
'min_samples_leaf' : [50, 100, 200, 300, 400, 500, 600, 700, 800, 900, 1000],
'max_depth' :[10, 30, 50]
}
grid = GridSearchCV(DecisionTreeClassifier(), param_grid, cv = 5)
grid.fit(X_train_val, y_train_val)
print('best parameters : \n', grid.best_params_)

pipe = make_pipeline(
DecisionTreeClassifier(
min_samples_split = 50,
min_samples_leaf = 50,
max_depth = 30,
random_state=1,
criterion = 'entropy')
)
pipe.fit(X_train_val, y_train_val)

print('training accuracy : ', pipe.score(X_train, y_train))
print('validation accuracy : ', pipe.score(X_val, y_val))

y_pred = pipe.predict(X_val)
print('validation f1 score : ', f1_score(y_val, y_pred))

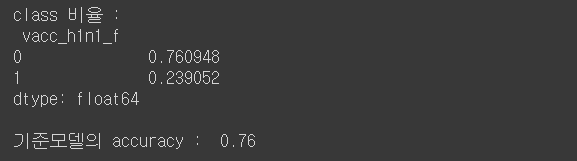
model_dt = pipe.named_steps['decisiontreeclassifier']
dot_data = export_graphviz(model_dt
, max_depth=3
, feature_names=X_train.columns
, class_names=['no', 'yes']
, filled=True
, proportion=True)
graphviz.Source(dot_data)
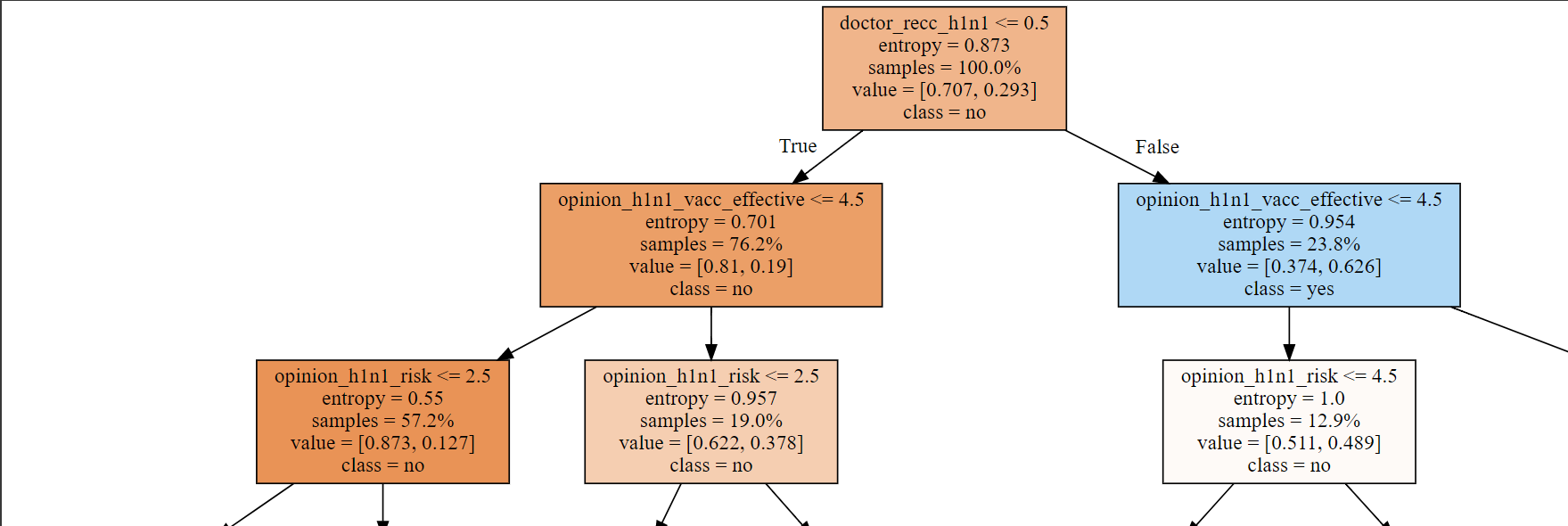
importances = pd.Series(model_dt.feature_importances_, X_train.columns).sort_values()
plt.figure(figsize=(10,8))
importances.plot.barh();
예측 데이터 캐글 제출 준비
imp = SimpleImputer(missing_values = np.nan, strategy = 'most_frequent')
cols = list(test.columns)
test = pd.DataFrame(imp.fit_transform(test), columns = cols)
for col in cols:
test[col] = le.fit_transform(test[col])
test.drop(['state', 'employment_occupation', 'employment_industry'], inplace = True, axis = 1)
y_pred = model_dt.predict(test)
result = pd.DataFrame(y_pred, columns = ['vacc_h1n1_f'])
result.reset_index(drop = False, inplace = True)
result.rename(columns = {
'index' : 'id'
}, inplace = True)
result.set_index('id', inplace = True)
result.to_csv('submission3_0412.csv')
추가 학습내용학습내용
selected_cols = df.select_dtypes(include = ['float', 'object'])
selected_cols.nunique()
LogisticRegression(n_jobs=-1)
