
프롤로그
석사과정 마지막 학기가 시작할 때쯤 부산시 대회(라곤 하지만 다니던 학교 재학생들이 거의 대부분)에 혼자 나가서 작업한 프로젝트가 있었다. 당시 '배경과 인물이 있으면 간단한 애니메이션 정도는 만들 수 있지 않을까?'라는 생각으로 프로젝트를 기획하였다. 이러한 과정들은 기존 딥러닝 기반 기술로 어느 정도 커버가 가능할 것 같았는데, 이를 프로토타입으로 만들었다고 보면 되겠다.
간단하게 과정을 읇어보자면, 실제 사진을 애니메이션풍 배경으로 만들 때에는 CartoonGAN과 AnimeGAN을 사용했고, 인물 사진을 메시로 만들 때 PIFu를 사용하고, MIXAMO로 리깅을 수행하고, 이 둘을 조합하기 위한 프로그램으로 Blender를 활용하면 되었다.
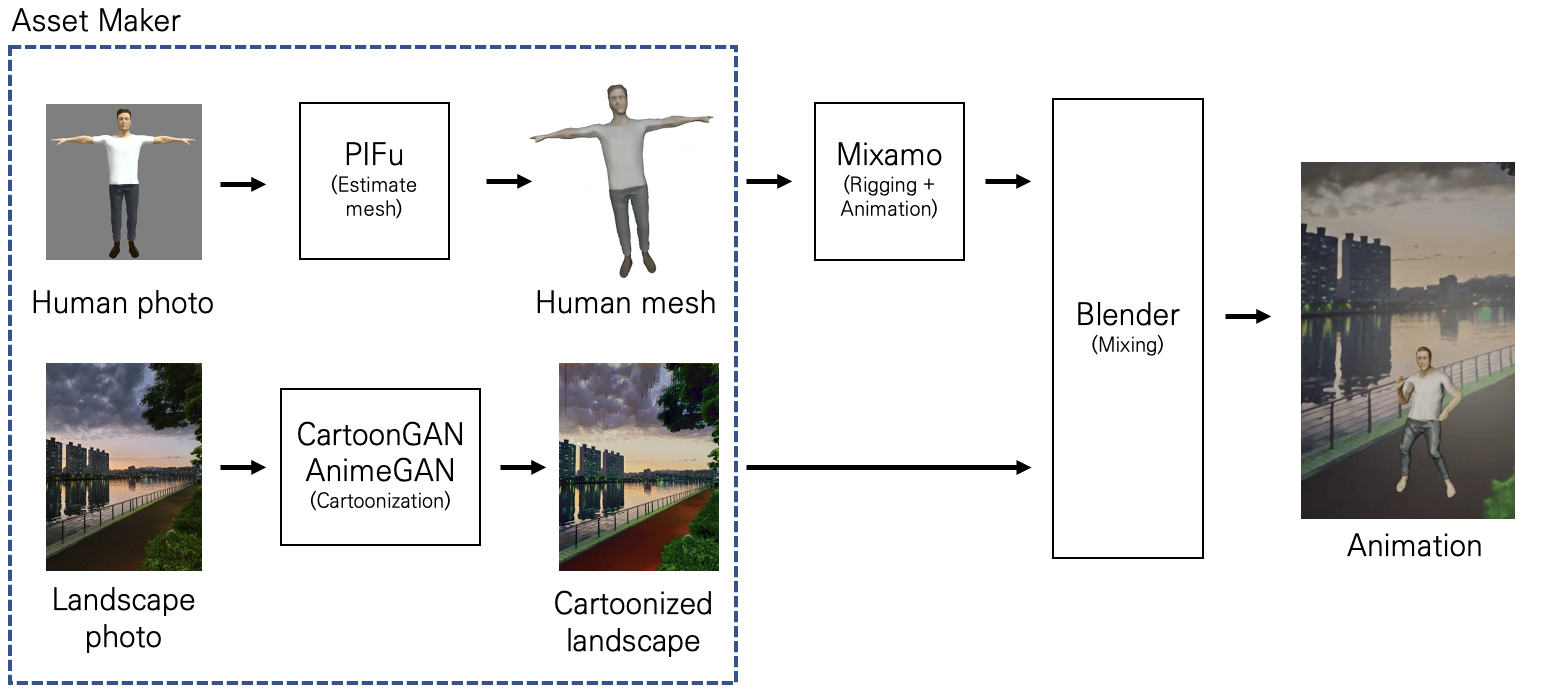
그 중 포스트의 주제갈 된 이미지 변환 부분의 UI이다. CartoonGAN과 AnimeGAN의 추론 결과들을 보여주었다. CartoonGAN의 경우 학습 중 색상 표현이 계속 달라지면서 불안한 모습을 보였다. AnimeGAN은 Color loss가 있어서, 그런 issue가 적은 것 같았다.
소스도 공개해야 했어서 UI와 모델 추론 부분으로 간단하게 공개는 했는데, 정작 중요한 소스는 비공개로 두었고, 학교를 졸업하면서 관리를 안한 결과, 어디론가 사라져버렸다.
뭐 여튼, 그 1달짜리 대회 기간 중 멘토링을 무려 2번이나 받아야 했었다. 필자는 이미 알고 있었던 분(구 개발자)께 자문을 받게 되었고, 간단하면서 아이디어도 좋다고 평을 들었다. 그리고 나중에 대회 끝나고 시간이 나게 되면 웹이나 안드로이드 상에서 추론하는 방식으로 방향을 잡으면 좋을 것 같다고 하셨다. 그렇게 시간이 지나고 최근이 되었고, 기술 책을 쓰려고 생각하는 중에 여러 챕터 중 한 챕터에 들어갈 프로젝트를 이걸로 하는 게 좋을 것 같아서, 관련된 글을 블로그로 먼저 써보려고 시도를 했는데 생각보다 시간이 많이 걸리게 되었다. 그런 김에 강의가 아니라 이런 글로 먼저 어떤 방식으로 시도했는지 남기는 것이 더 좋다고 판단했다.
카메라 영상을 실시간으로 보여주기
Android에서 실시간으로 모델을 통해 추론한 영상을 보여주기 위해서는, Android에서 실시간으로 카메라에서 나온 이미지를 모델에 넣을 수 있도록 전처리하고 이를 화면에 보여주는 파이프라인을 구성해야 한다. 또한 Android에서는 TFLite로 추론하기 때문에, 당시 PyTorch로 모델을 구현한 코드로 모델을 학습하고, 이를 TFLite로 변환하는 과정이 필요할 것 같았다.
먼저 대충 android tflite camera 비슷한 문구로 검색했고, 결과 중 한 문서를 기반으로 파이프라인을 구성해보았다.
근데 동작이 제대로 되지도 않았고 Kotlin Synthetic 방식을 사용하고 있었다. 처음 안드로이드에 입문했을 때에는findViewID 방식으로 사용했었는데, 최근 사이에 사용했던 방법 같았다. 여튼 View Binding 방식으로 넣기도 해야 하고, 카메라 사용 코드도 최신 것으로 사용할 겸 듀토리얼을 발견해 4번 과정까지 진행했더니 Preview 화면이 잘 나왔다. 여튼 CameraX를 활용하면 될 것 같았다.
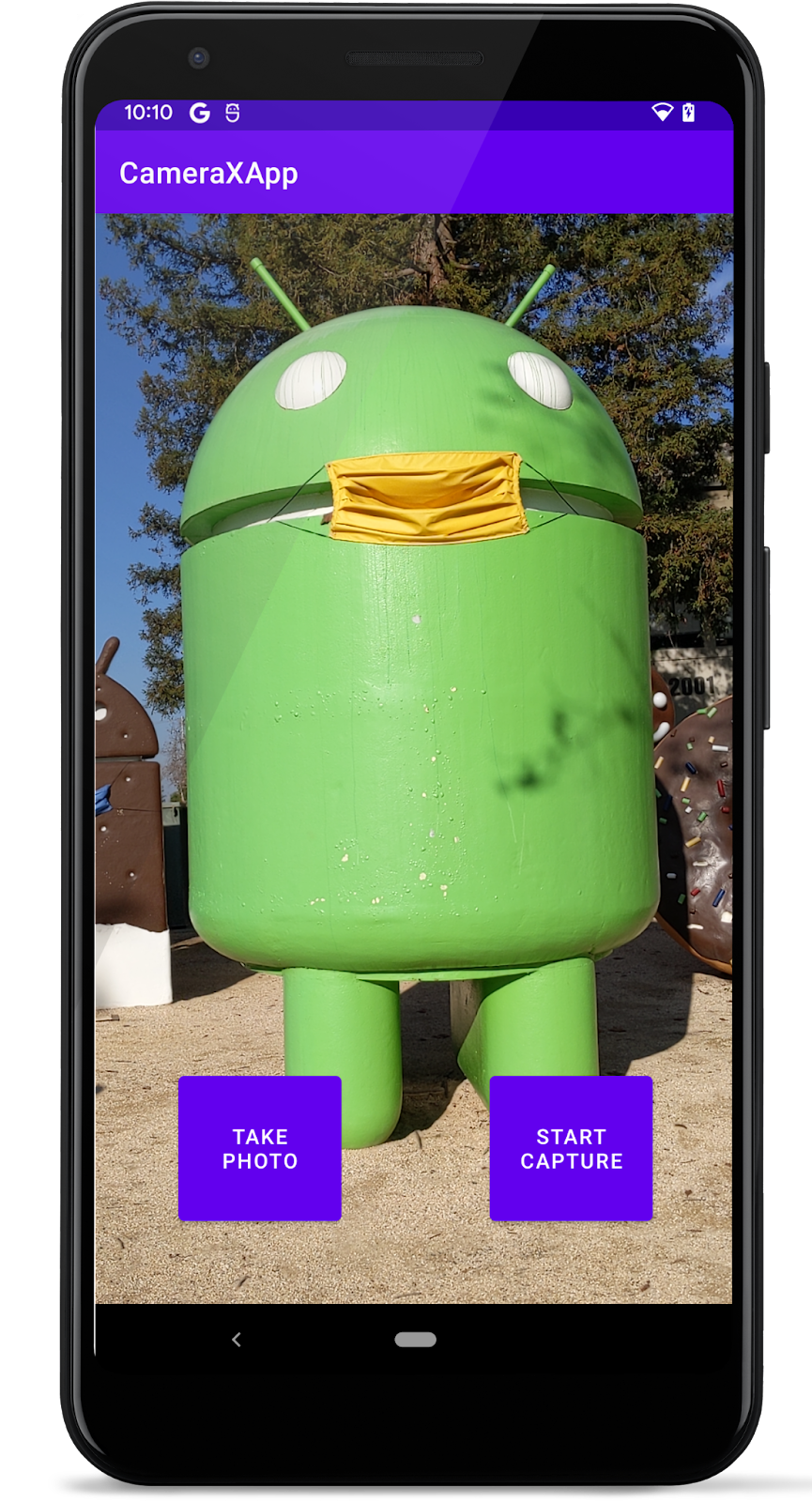
TFLite 모델에 이미지 통과시켜서 보여주기
그 다음에는 다시 그 문서로 돌아와서 파이프라인을 구성했다. 모델을 실시간으로 통과시키기 위해 액티비티 클래스에서 다음과 같은 코드를 사용했다고 한다.
//Image analysis(This time object detection)Use case
val imageAnalyzer = ImageAnalysis.Builder()
.setTargetRotation(cameraView.display.rotation)
.setBackpressureStrategy(ImageAnalysis.STRATEGY_KEEP_ONLY_LATEST) //Show only the preview image of the latest camera
.build()
.also {
it.setAnalyzer(
cameraExecutor,
ObjectDetector(
yuvToRgbConverter,
interpreter,
labels,
Size(resultView.width, resultView.height)
) { detectedObjectList ->
//Display of TODO detection result
}
)
}그 안에서 전처리를 이것저것 해야 한다. 간단하게 언급하자면,
- Preview
Image는 YUV 형식으로 오기 때문에YuvToRgbConverter로 RGB 형식으로 바꾼다. Image를Bitmap으로 바꾸고, 또TensorImage로 변환한다.ImageProcessor로 이미지의 resize와 normalize한다.
정도이다. 그리고 입력과 출력 버퍼를 interpreter의 run 메소드에 넣어 동작시킨다.
여기까지는 문서에 나온 파이프라인을 동작시키면 되었었다. 그런데 그 이후의 과정이 다르기 때문에 다시 구글링을 해야 했었다. 보통 이미지가 출력으로 나올 때 출력 텐서를 다시 비트맵으로 바꾸고 이를 뷰로 넣어주면 되는 것까지는 예상이 되었다. 일단 ImageView에 넣고 나중에 동작하면 바꾸는 방식으로 코드를 구성하기로 했다.
imageAnalyzer.setAnalyzer(
cameraExecutor,
ImageConverter(
yuvToRgbConverter,
loadModel(),
resources
) { bitmap: Bitmap ->
runOnUiThread {
val drawable = BitmapDrawable(resources, bitmap)
drawable.isFilterBitmap = false
viewBinding.imageView.setImageDrawable(drawable)
}
}
)ImageView에 보여주기 위해 BitMap을 BitmapDrawable로 바꿔서 보여준다. 나중에 SurfaceView같은 걸로 보여주면 바뀔 수 있다.
전체적인 그림은 이렇고, 이 과정들을 구현하면서 문제들이 매우 많았는데, 그 중 중요한 문제점들을 짚고, 해결 방법을 적어보았다.
문제 해결 1: 후처리 수행하기
입력의 전처리와 후처리가 골치가 아팠던 부분이다. 왜냐하면 전처리와 후처리 둘 중 하나만 잘못되어도 출력이 제대로 나오지 않아서 어느 부분이 잘못되는지 추론하기 힘들기 때문이다. 그래서 두 부분이 체인처럼 연결되어서 같이 조절했는데, 여기서는 분리해서 적어보겠다.
먼저 출력 부분이다. interpreter로 버퍼에 값이 쓰여지면, 이 버퍼를 기반으로 Bitmap을 만들든 후처리 과정을 거쳐야 한다. Bitmap으로 바꾸기 위해서는 Bitmap.Config.ARGB_8888 형식으로 버퍼를 구성해 넣으면 될 것 같았는데, 이를 가공하는 과정이 쉽지 않았다. 보통 출력 텐서의 버퍼로 TensorBuffer를 사용하는데, 이 형식을 다루는 게 쉽지 않았다. 특히, FloatArray로 바꾸면 flatten 되어서 공간 정보가 사라져서 어지러웠다.
해결 방법으로 출력 텐서 버퍼를 Array로 지정하는 것이다. 즉,
val outputImage =
Array(1) { Array(IMG_SIZE_X) { Array(IMG_SIZE_Y) { FloatArray(3) } } }방식으로 볼 수 있다. 그리고 이를 BitMap으로 넣기 위해 가져온 convertArrayToBitmap으로 변환하면 된다. 굳이 버퍼를 조절할 필요 없이 Bitmap의 각 픽셀에 접근할 때 계산하는 방식을 활용한 것 같다.
fun convertArrayToBitmap(
imageArray: Array<Array<Array<FloatArray>>>,
imageWidth: Int,
imageHeight: Int
): Bitmap {
val conf = Bitmap.Config.ARGB_8888 // see other conf types
val styledImage = Bitmap.createBitmap(imageWidth, imageHeight, conf)
for (x in imageArray[0].indices) {
for (y in imageArray[0][0].indices) {
val color = Color.rgb(
((imageArray[0][x][y][0] * 255).toInt()),
((imageArray[0][x][y][1] * 255).toInt()),
(imageArray[0][x][y][2] * 255).toInt()
)
// this y, x is in the correct order!!!
styledImage.setPixel(y, x, color)
}
}
return styledImage
}문제 해결 2: 전처리 제대로 하기
실질적으로 문제가 되었던 부분은 전처리였다. 결론부터 말하자면 문서에서 사용한 YuvToRGBConverter가 여기서는 이상하게 동작된 것이었으며, 이 문제의 증상은 출력된 화면에서 세로줄이 잘 보이면서 각 줄마다 RGB 색깔이 더 강한 느낌(?)으로 표현할 수 있겠다.
이는 StackOverflow을 보면서 해결했다. 위 detection 문서에서 사용한 YuvToRGBConverter를 사용하지 않고, 다음 코드를 활용해서 RGB 형식으로 바꾸고 Bitmap으로 반환하는 코드를 사용하니 해결되었다.
fun Image.toBitmap(): Bitmap {
val yBuffer = planes[0].buffer // Y
val vuBuffer = planes[2].buffer // VU
val ySize = yBuffer.remaining()
val vuSize = vuBuffer.remaining()
val nv21 = ByteArray(ySize + vuSize)
yBuffer.get(nv21, 0, ySize)
vuBuffer.get(nv21, ySize, vuSize)
val yuvImage = YuvImage(nv21, ImageFormat.NV21, this.width, this.height, null)
val out = ByteArrayOutputStream()
yuvImage.compressToJpeg(Rect(0, 0, yuvImage.width, yuvImage.height), 50, out)
val imageBytes = out.toByteArray()
return BitmapFactory.decodeByteArray(imageBytes, 0, imageBytes.size)
}문제 해결 3: GPU 사용하기
모바일의 경우 GPU로 추론하는 것이 가능하다고 생각했다. CPU로 추론하는 것보다 빠를 뿐만 아니라 부하 또한 줄일 수 있기 때문이다. 그래서 Interpreter에 다음과 같이 option을 넣는다.
private val interpreter: Interpreter by lazy {
val compatList = CompatibilityList()
val options = Interpreter.Options().apply{
if(compatList.isDelegateSupportedOnThisDevice){
// if the device has a supported GPU, add the GPU delegate
val delegateOptions = compatList.bestOptionsForThisDevice
this.addDelegate(GpuDelegate(delegateOptions))
} else {
// if the GPU is not supported, run on 4 threads
this.setNumThreads(4)
}
}
Interpreter(modelBuffer, options)
}CPU에서는 잘 추론되던 모델이 GPU에서 동작을 하지 않는다. transpose 함수를 지원하지 않는다고 한다. 문서에서도 없는 걸로 나오는데, 이 연산을 쓴 적이 없다고 생각하고 있었다. 짐작가는 게 있었고, 그냥 TF로 모델을 대충 만들어서 올려보았더니 동작하는 것을 확인했다.
그러면 PyTorch에서 TF로 바꾸는 과정에서 transpose 함수가 추가될 가능성이 있어 보였다. 왜냐하면, PyTorch (B, C, H, W)과 TF (B, H, W, C)는 텐서의 구조가 다르기 때문이다. 이를 netron으로 살펴보니, 실제로 그렇다는 것을 알 수 있었다.
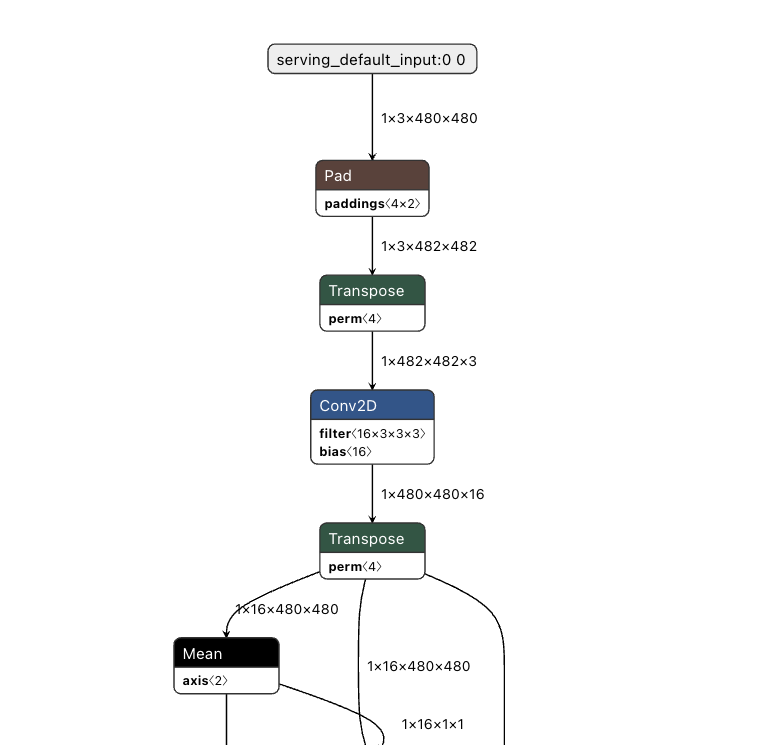
그래서 모델 단은 일단 냅두고 나중에 TF로 구현하기로 했다. 일단 컨볼루션 레이어 하나로 이루어진 모델을 대충 만들고, 입력된 이미지에 대해 그대로 출력하도록 학습하고, 이를 TFLite로 변환해서 넣었다.
구현 결과
그래서 TFLite로 모델로 추론한 모델을 성공적으로ImageView에 나타내었다. 참고로 전체 화면에 나온 화면이 카메라로 나온 PreviewView이고 가운데 작은 화면이 TFLite로 추론한 이미지를 나타낸 것이다. (잡다한 뷰들도 그대로 있다.)

그 다음에 해야할 것은 ImageView 대신에 SurfaceView를 사용해 보여주는 것과, AnimeGAN을 TF로 구현해 변환하는 것으로 볼 수 있겠다.
그리고 구글링하면서 느낀 점으로는 Image to Image로 실시간 추론 코드를 본 적이 거의 없었다는 것인데, 코드가 잘 정리되면 나중에 공개하면 좋을 것 같다.
