🔸 지금까지 다루었던 sequential API는 네트워크 구조가 고정되어있어 데이터의 방향이 한 방향으로 고정됨 => 복잡한 모델 모델링 어려움 => Functional API 사용
📌 Building Complex Models Using the Functional API
1. Wide&Deep neural network: One example of a nonsequential neural network
🔸 Sequential API의 경우 layer를 생성하면 반드시 그 layer를 지나야하기 때문에 Functional API의 Wide path의 data 흐름을 만들어 낼 수 없음
🔸 nonsequential network를 만들기 위해서는 functional API를 사용해야함
1) Learn both deep patterns (using the deep path) and simple rules (through the short path)
🔸 입력이 하나
🔸 hidden layer를 모두 지나는 deep pattern과 그림에서의 wide path(short path)를 지나는 simple rules로 학습 동시에 진행해야함 => Functional API 사용
🔸 각 layer마다 어떤 data를 input으로 받을지 지정
input_ = keras.layers.Input(shape=X_train.shape[1:]) #X_train이 어떤 타입인지 모를 경우 X_train.shape[1:] 형태로 정의
hidden1 = keras.layers.Dense(30, activation="relu")(input_) #input_을 input으로 받음
hidden2 = keras.layers.Dense(30, activation="relu")(hidden1) #hidden1을 input으로 받음
concat = keras.layers.Concatenate()([input_, hidden2]) #input_(short path)과 hidden2(deep path)를 묶음
output = keras.layers.Dense(1)(concat) #neuron이 1개인 layer, input이 concat
model = keras.Model(inputs=[input_], outputs=[output]) #model의 input과 output 지정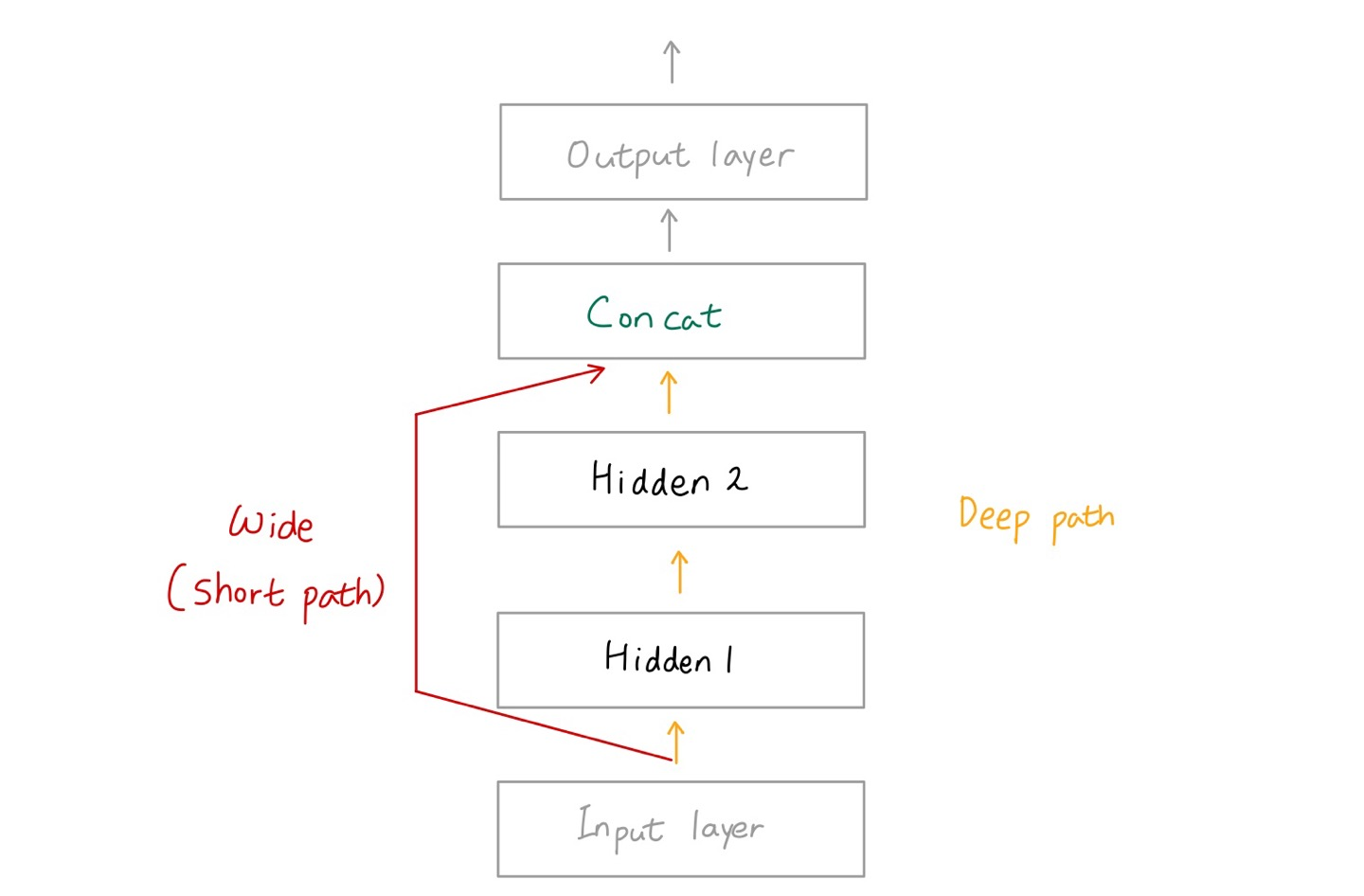
2) Multiple inputs
🔸 입력이 여러개가 존재하는 경우
💡 X_train_A와 X_train_B라는 두 개의 dataset을 pair로 묶어 network 통과시키고 fit() method를 사용해 학습
input_A = keras.layers.Input(shape=[5], name="wide_input") #shape은 size의미???
input_B = keras.layers.Input(shape=[6], name="deep_input")
hidden1 = keras.layers.Dense(30, activation="relu")(input_B)
hidden2 = keras.layers.Dense(30, activation="relu")(hidden1)
concat = keras.layers.concatenate([input_A, hidden2])
output = keras.layers.Dense(1, name="output")(concat)
model = keras.Model(inputs=[input_A, input_B], outputs=[output])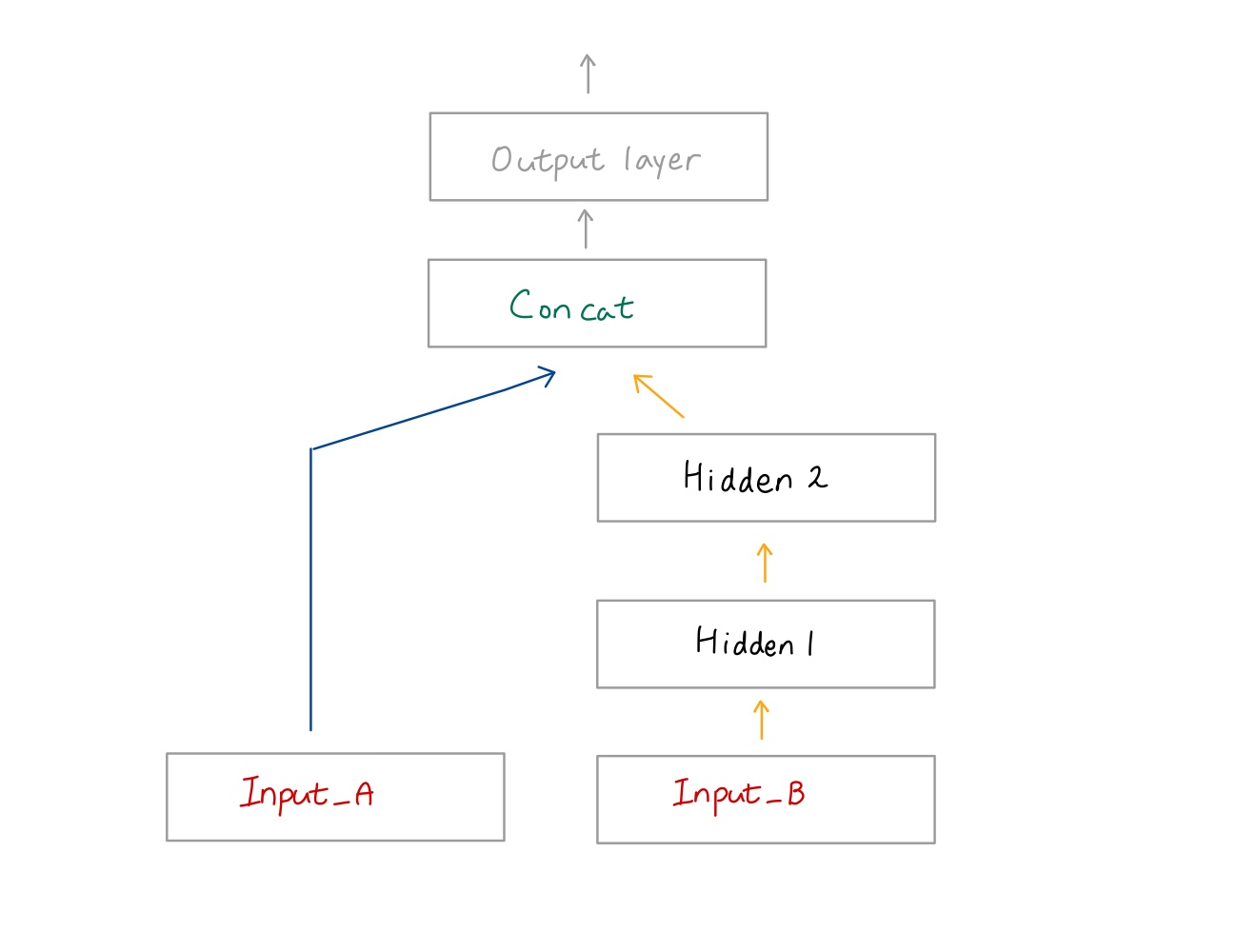
3) Compile (multiple inputs)
🔸 regression model이기 때문에 loss="mse"
model.compile(loss="mse", optimizer=keras.optimizers.SGD(learning_rate=1e-3)) #learning rate 1e-3으로 지정
X_train_A, X_train_B = X_train[:,:5], X_train[:,2:] #처음 5개 data가 X_train_A, 3번째 data부터 X_train_B
X_valid_A, X_valid_B = X_valid[:, :5], X_valid[:,2:]
X_test_A, X_test_B = X_test[:,:5], X_test[:,2:]
X_new_A, X_new_B = X_test_A[:3], X_test_B[:3] #prediction을 위해 새로운 data 정의. 각각 X_test_A, X_test_B 중 처음 3개의 data
history = model.fit((X_train_A, X_train_B), y_train, epochs=20, validation_data=((X_valid_A, X_valid_B), y_valid))
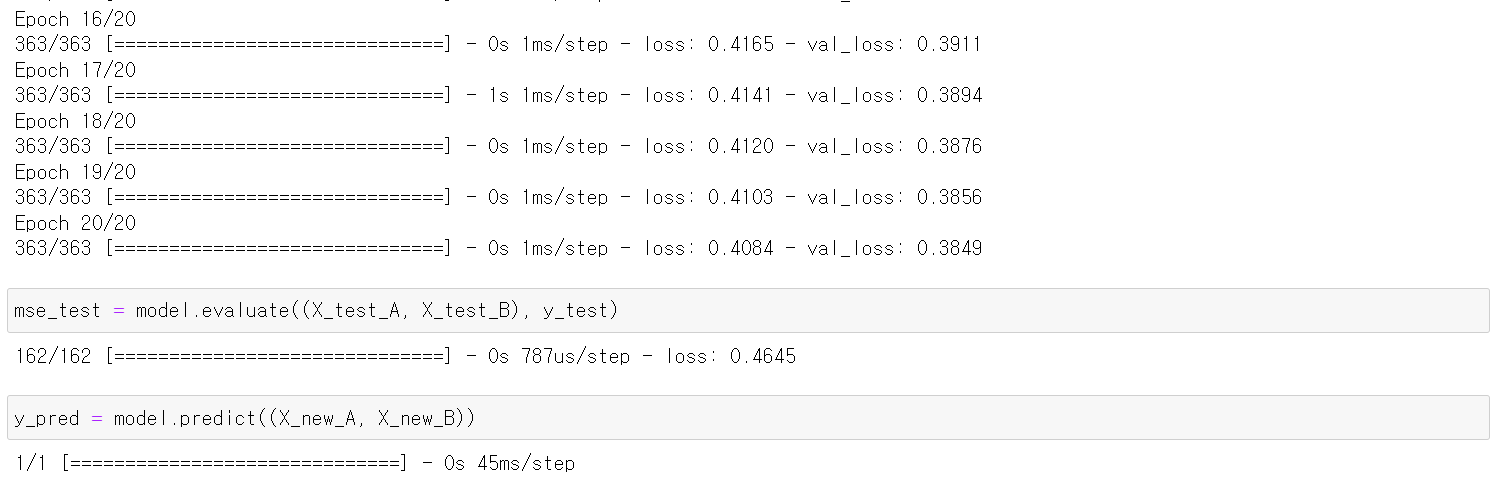
mse_test = model.evaluate((X_test_A, X_test_B), y_test)
y_pred = model.predict((X_new_A, X_new_B))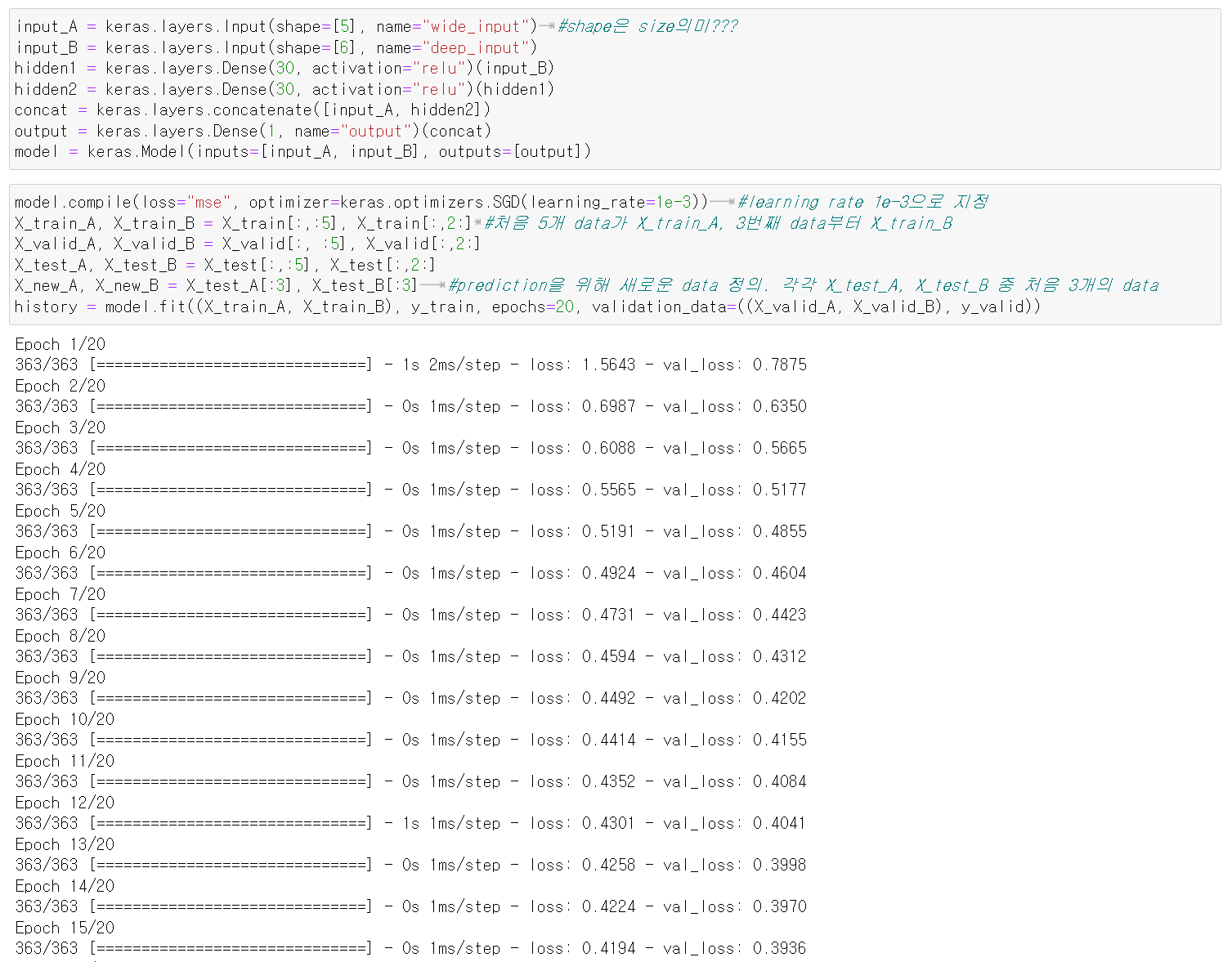
2. Multiple output(multiple independent tasks)
1) One neural network per task: 2NN for 2 tasks
🔸 일반적으로 하나의 task 당 하나의 neural network 사용
🔸 원칙적으로 2개의 task는 2개의 neural network 필요
2) A signle neural network with one output per task: often better results on all tasks
🔸 neural network can learn features in the data that are useful across tasks
🔹 task 당 하나의 output을 가지지만(따라서 여러 output 가짐) 하나의 neural network를 가지는 경우 존재 => 종종 모든 task에 좋은 영향을 줄 수 있음(항상 그렇지만은 않음)
🔹 Ex. face data: facial expression and wearing glasses => 두개의 output을 가지지만 하나의 neural network를 사용하는 것이 좋은 경우. 완전히 독립된 정보가 아니므로 하나의 task 훈련을 진행하면서 또다른 task에도 좋은 영향을 줌
3) Regularization technique
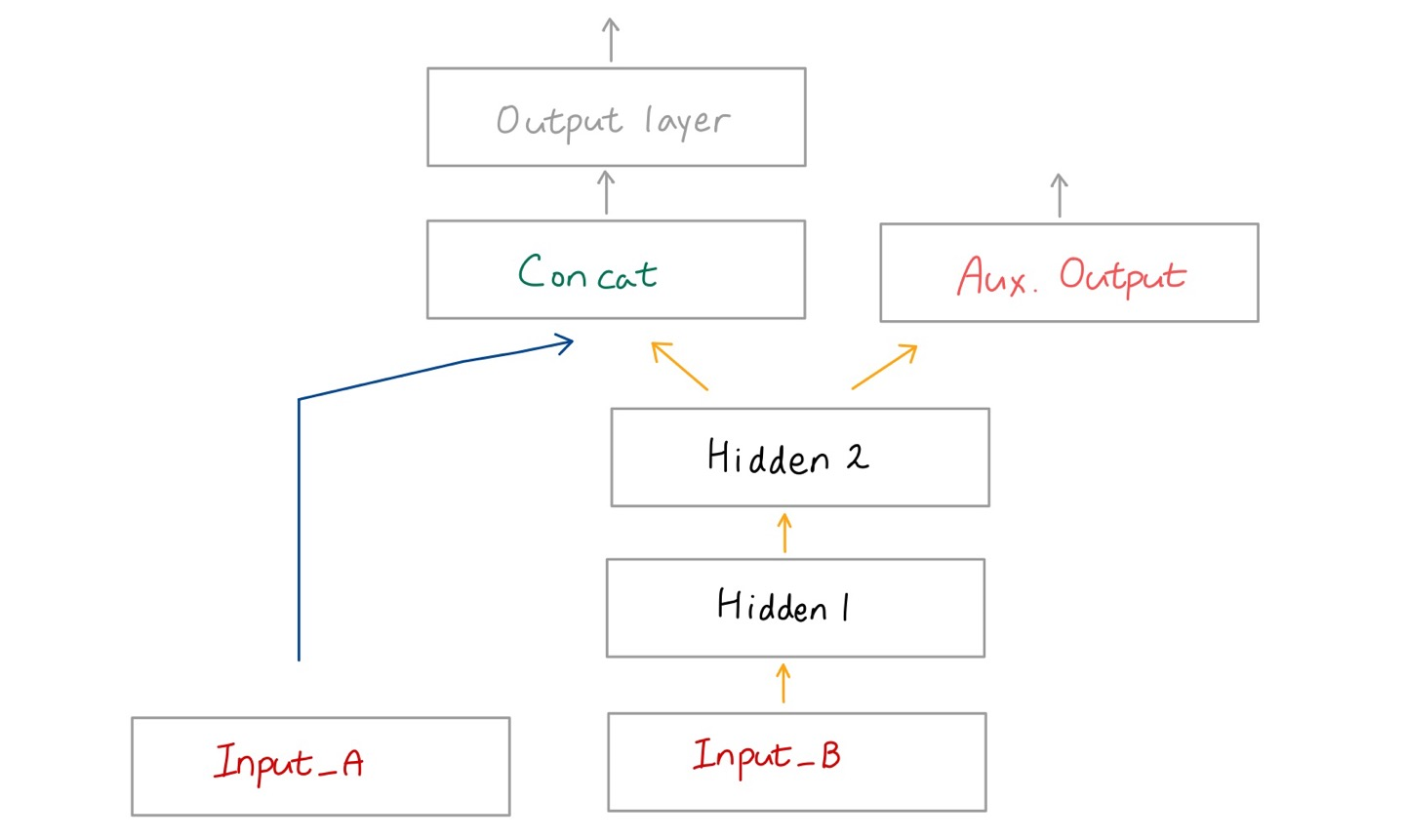
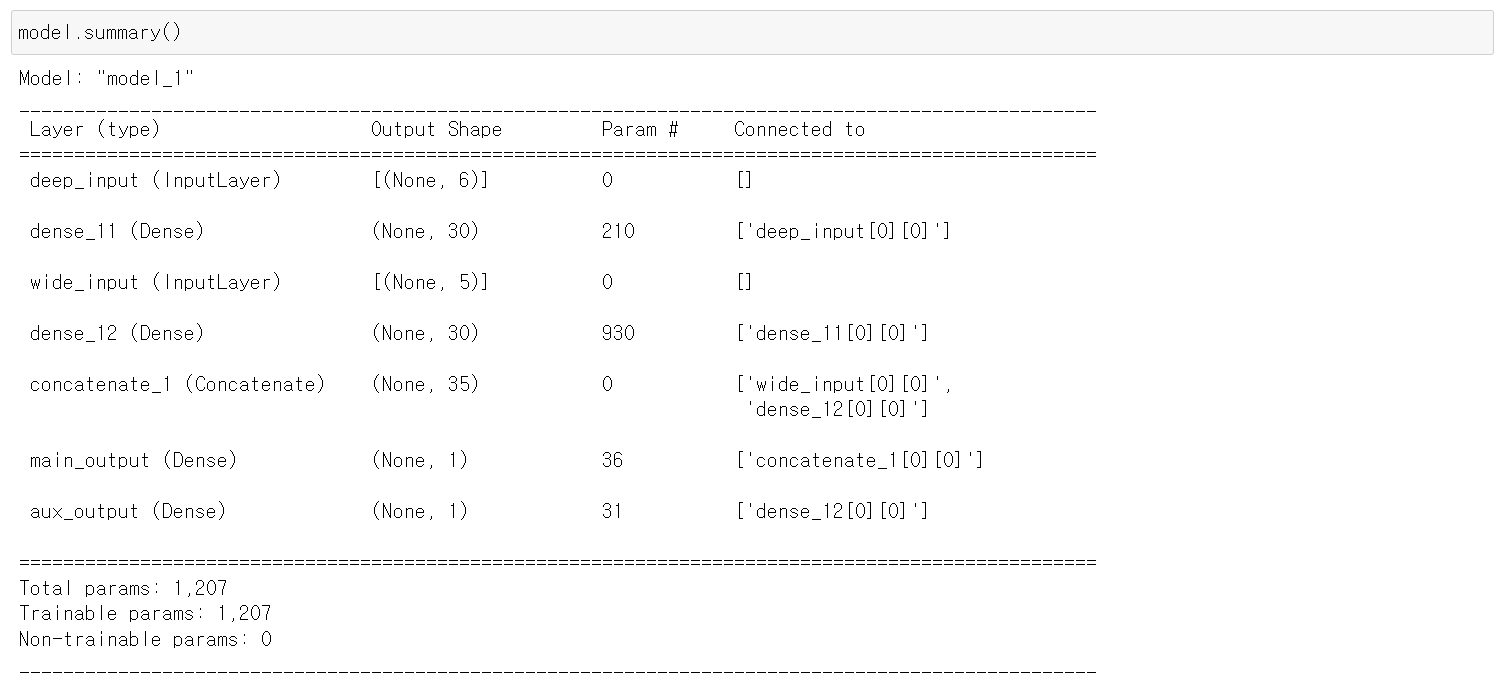
🔸 두 개의 input을 사용해 output을 만들 때 overfitting 등 문제가 발생할 수 있는데, 이 때 Aux. Output을 넣으면 Aux.Output을 위한 학습 과정에서 overfitting을 제한하는 등의 regularization technique 사용 가능
🔸 hidden layer1과 hidden layer2의 weight를 정하는 법이 달라지는데, 지나면서 data가 두 조건을 만족해야하므로 regularization 가능
🔸 compile시 각각의 output에 대해 loss function 지정. 이 때 loss function에 weight를 줄 수 있음
#model 생성
input_A = keras.layers.Input(shape=[5], name="wide_input")
input_B = keras.layers.Input(shape=[6], name="deep_input")
hidden1 = keras.layers.Dense(30, activation="relu")(input_B)
hidden2 = keras.layers.Dense(30, activation="relu")(hidden1)
concat = keras.layers.concatenate([input_A, hidden2])
output = keras.layers.Dense(1, name="main_output")(concat) #이름이 main_output
aux_output = keras.layers.Dense(1, name="aux_output")(hidden2)
model = keras.Model(inputs=[input_A, input_B], outputs=[output, aux_output])
#complie
model.compile(loss=["mse","mse"], loss_weights=[0.9,0.1], optimizer="sgd") #output layer의 가중치가 0.9, aux_output의 가중치가 0.1
#fit
history = model.fit([X_train_A, X_train_B], [y_train, y_train], epochs=20, validation_data=([X_valid_A, X_valid_B],[y_valid, y_valid]))
total_loss, main_loss, aux_loss = model.evaluate([X_test_A, X_test_B],[y_test, y_test]) #output의 loss가 main_loss, aux_output의 loss가 aux_loss, 그 둘을 앞서 지정한 loss_weights로 계산한 값이 total_loss
y_pred_main, y_pred_aux = model.predict([X_new_A, X_new_B])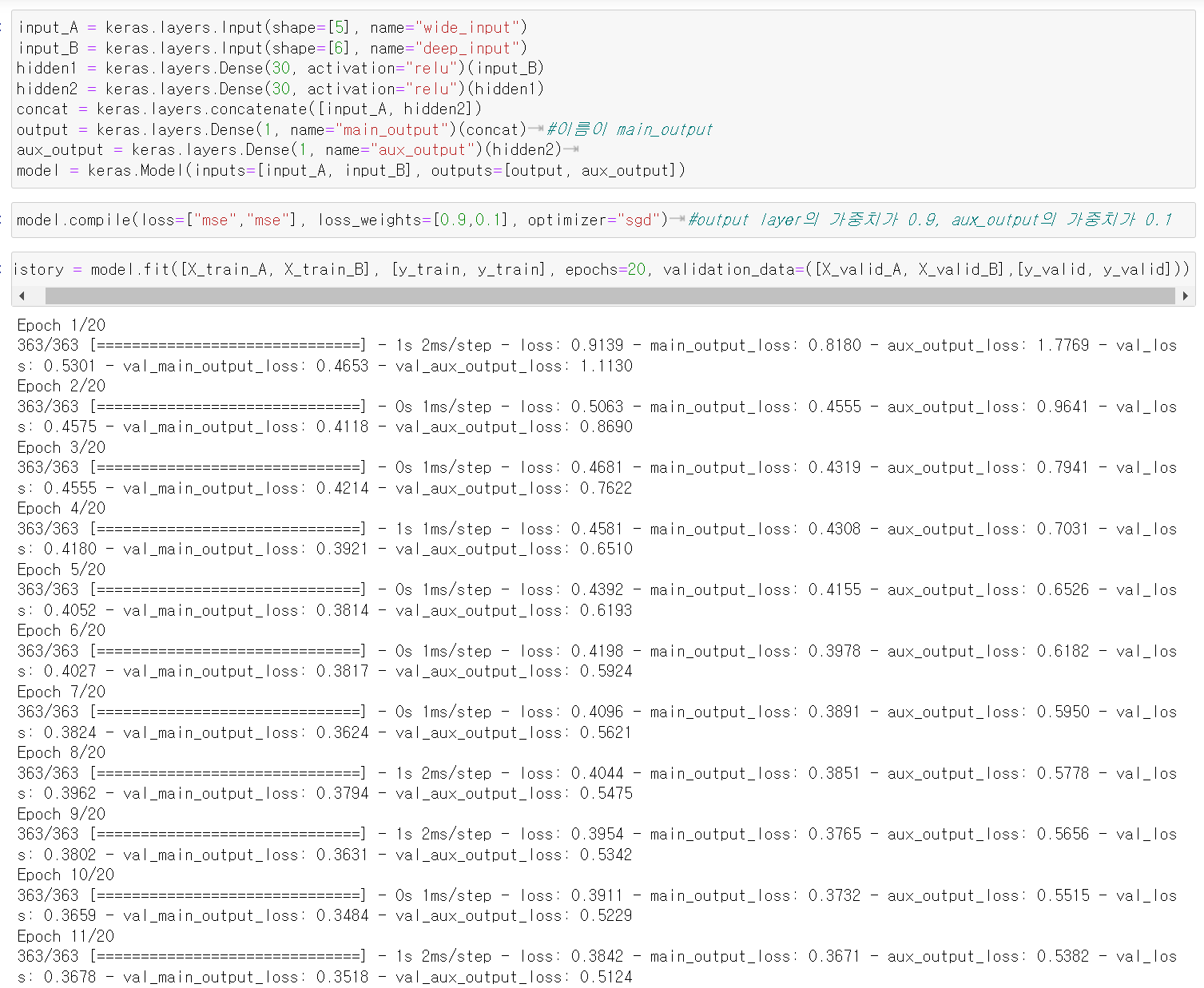
📌 Saving and Restoring a Model
1. HDF5 format to save (Sequential API or the Functional API)
🔸 아래의 정보가 HDF5 format으로 저장
1) model's architecture: layer's hyperparameters
🔸 layer 정보
2) model parameters for every layer (connection weights and biases)
🔸 model parameter => weights와 biases
3) optimizer including its (training) hyperparameters and any state
🔸 training hyperparameters => learning rate, epoch 등
🔸 compile method에 사용하는 parameter도 저장
코드
🔸 save(): 저장
🔸 keras.models.load_model(): fit()까지 완료한 model 다시 불러오기. 그 당시의 parameter도 모두 저장됨
#model 생성, compile, fit 모두 한 후에
#h5 format으로 model 저장
model.save("my_keras_model.h5")
#저장한 model load(restore)
model = keras.models.load_model("my_keras_model.h5")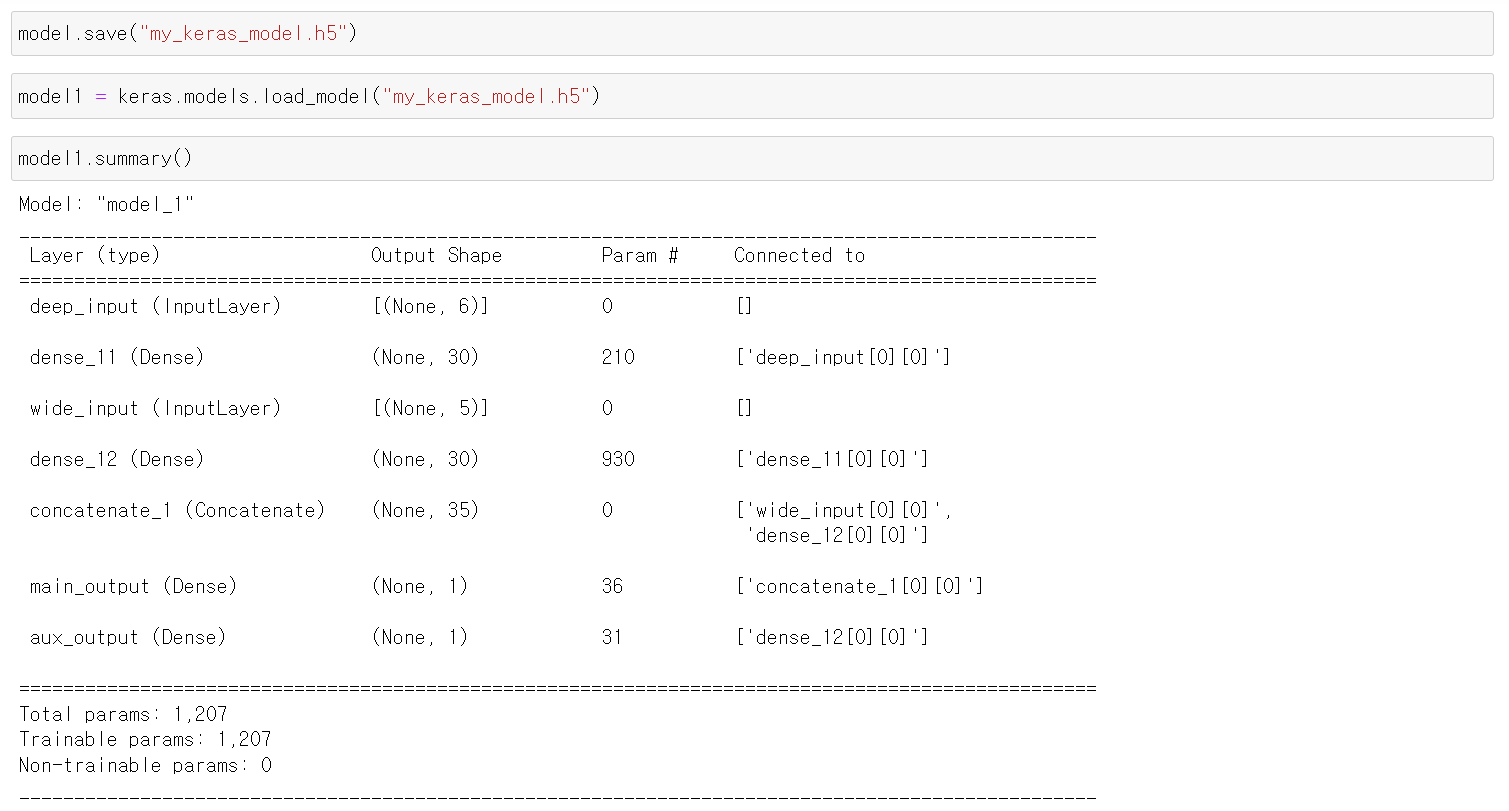
2. Model subclass
1) save_weights() and load_weights() to save and restore the model parameters
🔸 model parameter(weights와 biases)는 따로 저장 가능
2) save and restore everything else yourself
🔸 model parameter를 제외한 다른 hyperparameter는 코드를 직접 작성하여 저장 및 재사용해야함
