📌 Using Callbacks
🔸 학습 진행 과정에서 특정 시점의 결과물을 필요로 하는 경우 존재 ex. fit() 도중의 중간 결과 저장할 필요가 있는 경우
1. callbacks argument
🔸 keras가 특정 object list를 지정하면 필요할 때 불러올 수 있음
1) specify a list of objects that Keras will call
🔸 at the start and end of training, each epoch, and each batch
🔹 저장하고 불러오는 시점은 학습의 시작과 끝, 한 epoch의 시작과 끝, 각 batch의 시작과 끝
🔹 각 시점에서의 학습 결과(모델, 파라미터 관련된 내용 저장) 저장 및 불러오기 가능
2) ModelCheckpoint callback: saves checkpoints at regular intervals during training
🔸 학습을 진행하는 도중 주기적으로 학습 결과 저장해 일정한 간격으로 학습 결과가 어떻게 변하는지 알 수 있음
🔸 Jupyter에서 fit() method 사용할 경우 performance 위주로 결과가 나오지만, performance 외의 모든 data(model parameter, parameter) 저장
🔸 by default at the end of each epoch
🔹 ModelCheckpoint의 기본 주기는 한 epoch이 끝날 때 결과 저장
🔸 checkpoint_cb = keras.callbacks.ModelCheckpoint("my_keras_model.h5")
: checkpoint_cb라는 object 선언, 결과를 "my_keras_model.h5"에 저장
🔸 history = model.fit(X_train, y_train, epochs=10, callbacks=[checkpoint_cb])
: 각 epoch이 끝날 때마다 "my_keras_model.h5"에 결과 누적해서 저장
#build and compile the model
checkpoint_cb = keras.callbacks.ModelCheckpoint("my_keras_model.h5")
history = model.fit(X_train, y_train, epochs=10, callbacks=[checkpoint_cb])3) Early stopping: save_best_only = True
너무 많은 epoch 은 overfitting을 발생시키고 너무 작은 epoch 은 underfitting을 발생시킴. 이 epoch을 결정하는데 사용되는 것이 early stopping. Early stopping은 무조건 epoch 을 많이 돌린 후, 특정 시점에서 멈추는 것
🔸 default는 save_best_only = False
🔸 early stopping을 하고 싶을 경우 save_best_only = True로 설정
🔸 save model when its performance on the validation set is the best so far
🔹 각 epoch이 끝날 때마다 validation 진행(evaluate)하는데 이전의 validation 결과와 비교하여 더 좋은 결과가 나올 때마다 저장
🔹 마지막에는 train하는 과정에서 가장 높은 validation을 나타낸 결과를 저장되어있기 때문에 가장 성능이 좋은 모델을 저장할 수 있음
🔸 load_model을 사용해 해당 파일 읽으면 가장 좋은 성능을 내는 모델의 data assign됨
checkpoint_cb = keras.callbacks.ModelCheckpoint("my_keras_model.h5", save_best_only = True)
history = model.fit(X_train, y_train, epochs=10, validation_data=(X_valid, y_valid), callbacks=[checkpoint_cb])
model = keras.models.load_model("my_keras_model.h5")4) EarlyStopping callback
🔸 interrupt training when no progress on the validation set for a number of epochs (patience argument)
🔹 validation set으로 evaluate 진행했을 때 더 좋은 결과가 나오지 않으면 멈춰야하는데, patience argument만큼 진행했을 때 좋은 결과 나오지 않으면 멈추고 가장 좋은 결과가 나왔던 epoch의 결과를 best model로 선정
🔹 patience: 개선이 안된다고 바로 종료시키지 않고, 개선을 위해 몇 번의 epoch를 기다릴지(더 진행할지) 설정
🔸 optionally roll back to the best model
🔸 patience=10: 어떤 결과 나온 후 10 epoch만큼 더 진행했는데 더 좋은 결과를 얻지 못하면 거기서 멈춤
🔸 restore_best_weights=True: 10개의 epoch만큼 진행했지만 더 좋은 결과를 얻지 못했을 경우 이전의 좋은 결과가 나왔던 weight(즉, parameter) 저장해 roll back
🔸 epoch을 충분히 크게 잡아두는 것이 중요
🔸 callbacks=[checkpoint_cb, early_stopping_cb]: 모든 epoch마다 결과 저장하고(=>checkpoint_cb), 가장 좋은 결과가 나왔을 때부터 patience만큼 더 진행해 더 좋은 결과가 나오지 않을 경우 멈추고, 그 이전에 얻었던 가장 좋은 결과를 저장 (roll back()) (=> early_stopping_cb)
checkpoint_cb = keras.callbacks.ModelCheckpoint("my_keras_model.h5")
early_stopping_cb = keras.callbacks.EarlyStopping(patience=10, restore_best_weights=True)
history = model.fit(X_train, y_train, epochs=100, validation_data=(X_valid, y_valid), callbacks=[checkpoint_cb, early_stopping_cb])💡 결과: save checkpoints and interrupt training
interrupt training
모델 학습 도중 학습을 일시 중지하고 저장된 가중치를 사용하여 학습을 다시 시작하는 것
2. Custom callback
1) Ex. display the ratio between the validation loss and the training loss during training
🔸 to detect overfitting
🔹 validation loss / train loss 값은 학습이 진행될 수록 1에 수렴. But 1보다 커질 경우 overfitting 발생
🔸 on_epoch_end: epoch이 끝날 때마다 ratio 나타내기
class PrintValTrainRatioCallback(keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs):
print("\nval/train: {:.2f}".format(logs["val_loss"] / logs["loss"]))2) on_train_begin(), on_train_end(), on_epoch_begin(), on_epoch_end(), on_batch_begin(), and on_batch_end()
3) For evaluation, on_test_begin(), on_test_end(), on_test_batch_begin(), or on_test_batch_end()
🔸 called by evaluate(): evaluate()할 때 언제 위 함수를 진행할지
4) for prediction, on_predict_begin(), on_predict_end(), on_predict_batch_begin, or on_predict_batch_end()
🔸 called by predict(): predict()할 때 언제 위 함수를 진행할지
📌 Using TensorBoard for Visualization
1. Tensorboard
🔸 Tensorflow에서 제공
1) interactive visualization tool
🔸 학습 과정과 결과를 시각적으로 볼 수 있음
2) Usage
🔸 view the learning curves during training
🔹 학습 중의 learning curve
🔹 learning curve: epoch이 진행함에 따른 loss와 accuracy 값
🔸 compare learning curves between multiple runs
🔹 여러 번 학습할 때마다(학습 parameter 변경 해 여러 번 학습)의 learning curve 비교
🔸 visualize the computation graph
🔹 연산이 어떻게 진행되는지
🔸 analyze training statistics
🔹 학습 통계 자료
🔸 view images generated by your model
🔸 visualize complex multidimensional data projected down to 3D and automatically clustered
🔹 feature의 개수가 dimension의 개수인데, multidimensional data를 3D로 다운시키고 자동으로 cluster 진행해 보여줌
3) event files: special binary log files to visualize
🔸 Summary: binary data record
🔹 tensorboard 사용하기 위해서는 특별한 binary log file인 event file이 생성해야함
🔹 summary에 binary data가 record 형식으로 들어가있어 이 data를 이용해 시각화
4) monitor the log directory, and pick up the changes and update the visualizations
🔸 event file에 있는 log directory를 지켜보다가 변화가 발생했을 때 변화를 읽어 visualization을 update시킴
🔸 여러 번 학습했을 때의 learning curve를 볼 때, 한 번의 학습이 끝난 후 다음 학습이 진행된 후에 log directory의 새로운 event file 생성됨. 이를 시각화된 그래프에 추가
5) Comparing results of multiple runs
🔸 TensorBoard server points to a root log directory
🔹 tensorboard server가 root log directory 지정
🔸 writes to a different subdirectory for runs based on data and time
🔸 os.path.join(os.curdir, "my_logs")
: os의 정보를 가져와 curdir 지정하고 이름을 "my_logs"로 설정
🔸 각 run마다 시작 시간을 sub directory 이름으로 생성
🔸 각 run마다 새로운 directory 안에 event file이 생성
🔸 run_logdir = get_run_logdir()
: ./my_logs/run_2023_04_13-13_56_01 의 sub directory 생성
🔸 run이 계속 진행될 시 my_logs 안에 sub directory가 여러개 생성됨
import os
root_logdir = os.path.join(os.curdir, "my_logs")
def get_run_logdir():
import time
run_id = time.strftime("run_%Y_%m_%d-%H_%M_%S")
return os.path.join(root_logdir, run_id) #root_logdir에 run_id라는 이름으로
run_logdir = get_run_logdir()2. Keras provides a nice TensorBoard() callback
tensorboard_cb = keras.callbacks.TensorBoard(run_logdir)
history = model.fit(X_train, y_train, epochs=30, validation_data=(X_valid, y_valid), callbacks=[tensorboard_cb])1) creating the log directory and event files
🔸 sub log directory(ex.run_2019_06_07-15_15_22, 2019_06_07-15_15_49) 만들고 그 안에 sub directory로 train과 validation으로 나뉘고 그 안에 event file(ex. events.out...) 생성
2) writing summaries during training
🔸 train하면서 event file 안에 summary(ex.local.trace)들 기록
3) after running twice,
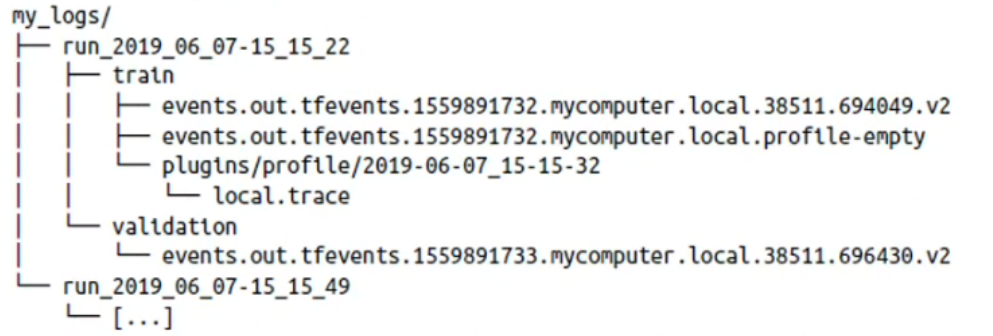
4) profiling traces: spending time for each part of model, across all devices
🔸 모든 device에서의 소요시간을 알 수 있어 profiling해 성능이 저하되는 부분 찾아 해결할 수 있음
🔸 great for locating performance bottlenecks
3. Start TensorBoard server
1) running a command
🔸 1. In a (Jupyter) terminal: check PATH variable before running => 새로운 창에 tensorboard 실행
🔹 path variable이 잘 잡혀있는지 확인
$ tensorboard --logdir=./my_logs --port=6006 #root directory 지정:my_logs
Or
$ python3 -m tensorboard.main --logdir=./my_logs --port=6006🔹 결과로 TensorBoard 2.0.0 at http://mycomputer.local:6006/
이 후 CTRL+C 눌러서 종료 후 웹브라우저 열기
🔹 open a web browser and go to http://localhost:6006
🔸 2. within Jupyter notebook(inline op.) => Jupyter notebook 내에서 tensorboard 실행
🔹 %load_ext tensorboard #
: tensorboard 열기
🔹 %tensorboard --logdir=./my_logs --port=6006
: directory와 port 지정
%load_ext tensorboard #
%tensorboard --logdir=./my_logs --port=60062) click the SCALARS tab to view the learning curves
🔸 learning curve 보기 위해서 SCALARS 탭 선택
💡 tensorboard에서 epoch_loss는 train loss를 의미
