🔸 Neural network에는 parameter(weight, bias)와 hyperparameter 존재
🔸 Parameter
🔹 train결과에 의해 결정된 값으로, 값을 마음대로 변경할 수 없음
🔸 Hyperparameter
🔹 network의 구조를 결정하는 model hyperparameter(hidden layer의 개수, 각 hidden layer의 neuron의 개수)와 학습 방식을 결정하는 training hyperparameter(learning rate) 존재
💡 hyperparameter를 어떻게 지정하는지에 따라 학습 결과 달라짐
📌 Fine-Tuning Neural Network Hyperparameter
1. Flexibility of neural networks: also one of main drawbacks
🔸 hyperparameter는 사용자가 임의로 지정하기 때문에 neural network의 flexibility는 굉장히 커 다양한 모델을 구성할 수 있다는 장점이 있지만, 너무 크기 때문에 어떤 값이 최적의 hyperparameter인지 찾기 어렵다는 단점 존재
1) network topology: number of layers, neurons per layer, type of activation function and so on
🔸 hyperparameter가 network의 topology 결정
🔸 hyperparameter 예시: number of layers, neurons per layer, type of activation function
2) there are many hyperparameters to tweak
🔸 try many combinations of hyperparameter
🔸 => GridSearchCV or RandomizedSearchCV
🔹 GridSearchCV
: 모든 가능한 조합의 hyperparameter를 시도하여 최상의 조합을 찾음 => 주어진 범위 내에서 항상 가장 좋은 결과 나타냄
🔹 RandomizedSearchCV
: GridSearchCV에서와 같이 범위를 줬을 때 모든 조합을 모두 train하는것이 아니라 무작위로 선택한 hyperparameter 조합에서 교차 검증을 수행 => random하게 뽑아 train 진행하므로 최적의 결과가 나온다는 보장은 없음. 하지만 train 횟수 지정하므로 적은 횟수로 학습하고 결과 나타낼 수 있음
🔸 EX. simple Sequential model for univariate regression: 변수가 하나인 regression을 진행하는 sequential model
def build_model(n_hidden=1, n_neurons=30, learning_rate=3e-3, input_shape=[8]):
model = keras.models.Sequential()
model.add(keras.layers.InputLayer(input_shape=input_shape)) #input layer
for layer in range(n_hidden):
model.add(keras.layers.Dense(n_neurons, activation="relu"))
model.add(keras.layers.Dense(1)) #output layer
optimizer = keras.optimizers.SGD(learning_rate=learning_rate)
model.compile(loss="mse", optimizer=optimizer)
return model
keras_reg = keras.wrappers.scikit_learn.KerasRegressor(build_model)
keras_reg.fit(X_train, y_train, epochs=100, validation_data=(X_valid, y_valid), callbacks=[keras.callbacks.EarlyStopping(patience=10)])
mse_test = keras_reg.score(X_test, y_test)
y_pred = keras_reg.predict(X_new)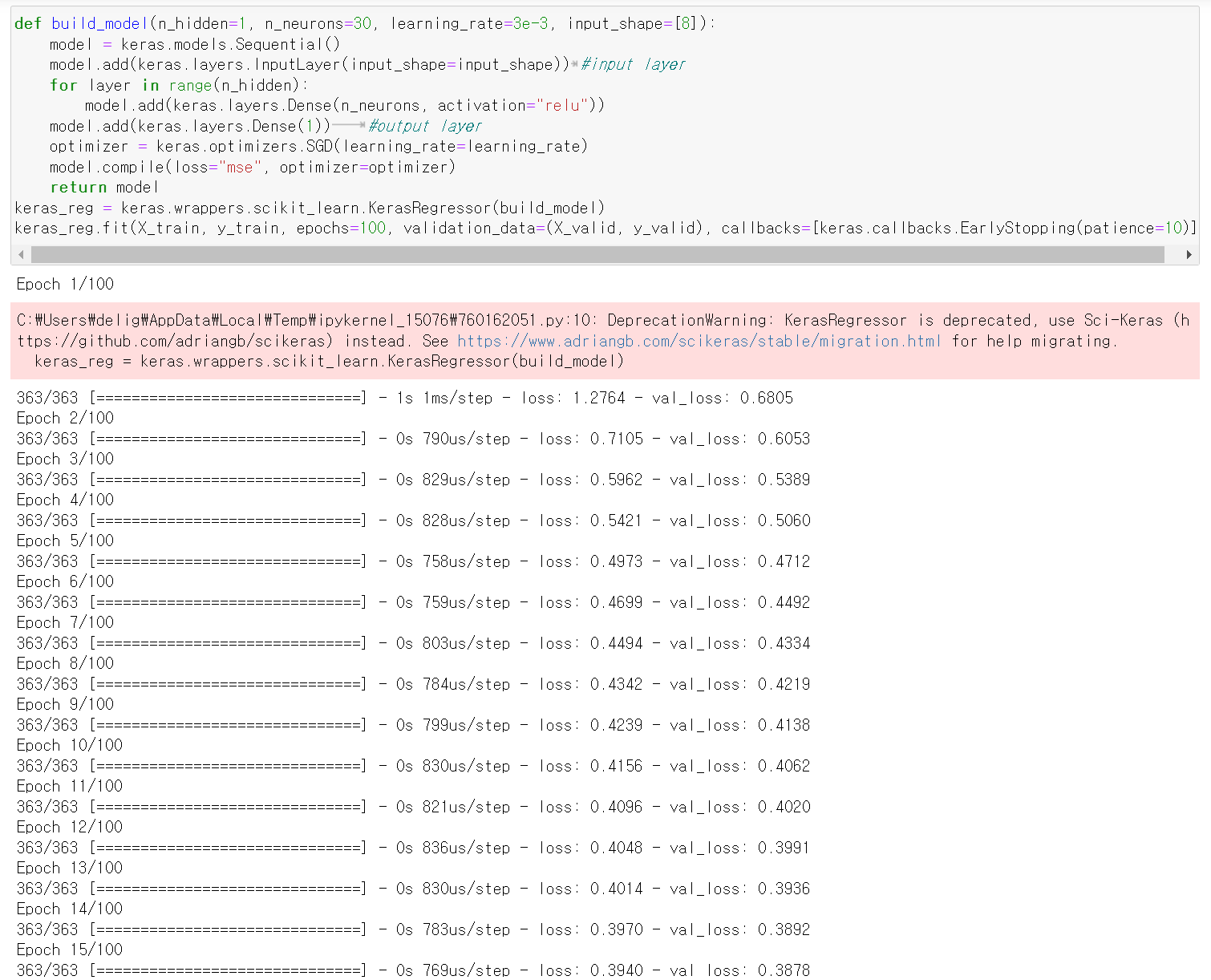
🔹 위의 모델을 RandomizedSearchCV 방식으로 최적의 hyperparameter 찾기 => fine-tuning
🔹 가장 좋은 parameter를 찾는 것은 시간이 오래 걸려, 일부 search하고 next level에 search하는 manual hierarchical search 방식으로 진행
🔸 rnd_search_cv = RandomizedSearchCV(keras_reg, param_distribs, n_iter=10, cv=3)
: keras_reg를 param_distribs의 범위, n_iter=10, cv=3을 가지고 RandomizedSearchCV 진행
n_iter: random search 탐색 횟수
cv : cv 검증(교차검증)을 위한 분할 검증(fold) 횟수
🔸 param_distribs에서 가능한 조합은 n_hidden 개수 4개, n_neurons의 개수 100개, learning_rate의 개수 2개가 존재해 총 조합의 수는 41002 = 800개. n_iter=10이므로 800개 중 random하게 10개의 조합 선택해 학습 진행해 그 중 가장 학습 결과가 좋은 결과 출력
🔸 validation_data는 earlystopping을 위해서만 사용
from scipy.stats import reciprocal
from sklearn.model_selection import RandomizedSearchCV
param_distribs = { #parameter의 범위 지정
"n_hidden": [0,1,2,3], #network hyperparameter
"n_neurons": np.arange(1,100), #network hyperparameter
"learning_rate": reciprocal(3e-4, 3e-2)} #training hyperparameter
rnd_search_cv = RandomizedSearchCV(keras_reg, param_distribs, n_iter=10, cv=3)
rnd_search_cv.fit(X_train, y_train, epochs=100, validation_data=(X_valid, y_valid), callbacks=[keras.callbacks.EarlyStopping(patience=10)])📌 Fine-Tuning Neural Network model Hyperparameters
🔸 model hyperparameter: 네트워크의 구조를 결정하는 hyperparameter
🔸 다양한 hyperparameter의 특성과 의미를 알아야 최적의 hyperparameter를 찾을 수 있는 범위를 더 좁게 설정할 수 있음
1. Number of Hidden Layers
🔸 deep neural network를 사용하는 것이 좋지만, hidden layer의 수는 dataset의 feature dimension에 따라 결정됨 => 정해진 값이 있는 것이 아니라 학습하면서 알아볼 것
1) MLP with one hidden layer can model complex functions with enough neurons for long time
🔸 hidden layer 하나가 많은 neuron을 가지고 오래동안 학습하면 복잡한 모델을 만들 수 있음
2) Deep networks: much higher parameter efficiency
🔸 => exponentially fewer neurons than shallow nets
🔸 => much faster to train
🔹 hidden layer의 수를 늘리면 적은 neuron으로도 하나의 hidden layer를 가진 모델의 복잡도와 비슷한 복잡도를 가지는 모델을 생성할 수 있음
🔹 더 작은 수의 neuron을 가지기 때문에 parameter 연산량이 줄어 더 빠르게 학습 가능
🔹 deep neural network는 학습 자체가 어렵다는 단점이 있는데, backpropagation으로 해결 가능
3) Deep networks: suitable for hierarchical data structure
🔸 Local feature for lower hidden layer: line segments of various shapes and orientations
🔹 input과 가까운 hidden layer의 경우 local feature를 나타냄. ex. 모양과 방향의 line segment, 선
🔸 Intermediate features for intermediate layer: squares, circles
🔹 중간 layer에서는 중간 단계의 feature 나타냄. ex. line segment가 모여 만든 직사각형 또는 원, 눈 또는 코 또는 입
🔸 Global features for higher layer: faces
🔹 higher layer에서는 global feature 나타냄. ex. 얼굴, 팔, 다리
🔸 Ex. drawing forest: Leaf-branch-tree
🔹 Single layer: copy and paste leaves only to form a forest
🔹 Deeper layer: copy and paste leaves to form a branch -> tree -> forest: much faster and efficient
4) Deep networks improves their ability to generalize to new datasets
🔸 Deep network가 generalize하는데 성능이 더 좋음 => transfer learning
💡 generalize: 학습하지 않은 새로운 data에 적용하는 것
🔸 Transfer learning: Training using pretrained weights of lower layers instead of random initialization
🔹 이미 학습된 lower layer의 parameter를 사용해 초기화시키고 내가 원하는 학습시키고자하는 data 학습
🔹 원래는 weight에 random initialization 진행하여 원하는 결과까지 도달하는데 오랜 시간이 걸리는 반면 transfer learning은 어느정도 결과와 비슷한 값을 가지고 시작하기 때문에 학습이 더 빠름.
🔸 => faster and easy to find solutions
🔸 Ex. Network for face recognition => hairstyle
🔹 얼굴 구분하는 네트워크가 있을 때, 헤어스타일을 구분하는 네트워크를 만들 때 사용할 수 있음
2. Number of Neurons per Hidden Layer
1) input and output layers: type of input and output
🔸 input과 output은 설계하고자하는 입력과 출력에 따라 정해지므로 hyperparameter라고 할 수 없음. input은 feature dimension, output은 얻고자하는 값의 dimension 또는 class의 개수로 결정됨
🔸 Ex. MNIST: 28x28 inputs. 10 outputs
2) Hidden layers:
🔸 Fewer and fewer neurons to the output (commonly, many low level features, and small high level features) -for FC layers
🔹 일반적으로 output에 가까워질수록 neuron의 수가 서서히 줄어듬. 인접한 hidden layer의 neuron 수의 차이가 크면 성능 좋지 않음
🔹 input layer에서 output layer로 갈수록 neuron의 개수가 계속해서 줄어들 수 있고, 늘어나다가 줄어들 수도 있음
🔹 input layer와 가까운 low level feature은 많고, output layer와 가까운 high level feature는 적음. 이 때 feature는 neuron의 개수 의미
🔹 feature가 복잡한 경우 neuron의 수를 늘리고, 복잡하지 않을 경우 neuron의 수가 작아도 됨
🔸 The same number of neurons for simple tuning => 최적의 해를 찾기는 어렵지만 학습 간단하고 빠름
🔹 fine tuning 진행하면서 단순하게 모델을 만들고 싶을 경우 neuron의 수를 통일
🔸 Increase the number of neurons gradually until overfitting
🔹 neuron의 수가 증가할수록 모델이 복잡해지는데 복잡한 모델의 파라미터를 구하기 위해서는 dataset의 instance의 개수와 feature dimension이 충분히 커야함
🔹 overfitting이 될 때까지 neuron의 수를 증가시키면 상대적으로 data의 양이 적어져 overfitting 발생하는데, overfitting이 발생하기 직전의 neuron 수로 설정
🔸 => Better way: enough number of neurons with early stopping and regularization("Stretch pants") => increased computation
🔹 충분히 큰 neuron과 epoch 수를 설정하고 overfitting 발생하기 전에 early stopping을 통해 최적의 해를 구하고 학습을 멈추고, regularization을 통해 overfitting 방지. But neuron이 많기 때문에 연산량이 많다는 단점이 있음
🔸 No perfect solution
📌 Fine-Tuning Neural Network training Hyperparameters
🔸 training Hyperparameters: model의 구조는 결정되었고 학습할 때 어떤 조건으로 학습시킬지 학습 방법 결정
🔸 Learning Rate, Batch Size, and Other Hyperparameters
1. Learning rate
1) the most important hyperparameter
2) affects training time and accuracy
3) large: fast but possibly no optimal solution
4) small: slow and possibly stick to local minima
2. Optimizer: Better optimizer than plain old Mini-batch Gradient Descent
🔸 optimizer를 지정하지 않으면 SGD 방식(mini-batch Gradient Descent)이지만 이보다 더 좋은 optimizer를 사용하면 사용 학습 속도 및 성능이 좋아짐
🔸 대부분의 경우에 optimizer를 사용하는 것이 좋은 결과를 야기함
3. Batch size
🔸 Mini-batch Gradient Descent에서 한 번에 몇 개의 data를 학습시켜 parameter(weight) 업데이트시킬 것인지
1) Large: efficient processing for HW accelerators, but may result in training instability
🔸 많은 데이터를 한 번에 학습시켜 weight를 완만하게 수렴시킬 수 있음
🔸 GPU나 NPU와 같은 HW accelerator를 사용할 경우 batch size가 클 수록 효율이 좋음(연산 앞뒤로 overhead 발생하는데 batch size가 커야 연산시간의 비율이 더 커짐)
🔸 training instability(학습의 안정성을 떨어트릴 수 있음) 문제 발생
2) 2017 paper: very large batch sizes(up to 8,192) using warming up the learning rate
🔸 learning rate는 일반적으로 크게 설정했다가 점점 감소시키는데 batch size가 클 때 learning rate도 크면 instability 발생
🔸 warmup: 초기의 learning rate가 alpha이면, 처음 learning rate를 alpha로 바로 두지 않고 더 작게 설정한 후 alpha까지 서서히 올라가 안정된 학습이 진행되도록 함. 그 이후로는 본격적인 학습 진행됨
3) Large batch size, using learning rate warmup: if training is unstable or poor performance => smaller batch size instead
🔸 batch size가 큰데 학습이 불안정하거나 성능이 좋지 않을 경우, learning rate를 warmup 방식으로 진행하면 좋아질 수 있음
🔸 warmup 방식으로도 해결이 되지 않는다면 batch size 줄이기
4. Activation Fuctions
1) ReLU works well in most cases for hidden layers: fast and non-saturate for large input
🔸 대부분의 경우 ReLU 사용
🔸 0보다 작은 경우 0, 0보다 큰 경우 입력을 그대로 출력해 연산 단순
🔸 saturation 되지 않고 nonlinearity 제공
2) Softmax for output in case of exclusive classification
3) No activation for regression
🔸 출력이 linear하게 나와야하므로 activation function 사용하지 않음
5. Number of iterations: large number with early stopping
🔸 Number of iterations는 epoch 수 의미
🔸 큰 수로 설정하고 early stopping 진행
