📌 Reusing Pretrained Layers
🔸 pretrained layer 재사용해 필요한 모델(내가 만들고자 하는 모델) 학습
1. Transfer learning
🔸 이미 잘 훈련된 모델이 있는 경우, 그 모델을 이용해 하고자하는 일을 할 수 있으면 시간 절약 가능
1) A pretrained neural network for a similar task => reuse the lower layers
🔸 비슷한 작업을 하는 이미 학습된 neural network가 있으면 lower layer 재사용
2) speeds up training considerably and requires much less training data
🔸 transfer learning 진행하면 훈련 속도가 빨라지고 더 적은 훈련 데이터를 요구
3) Requirement: similar low-level features
4) Retrain existing DNN for different dataset
5) Retrain modified DNN for the same or different dataset
🔸 transfer learning은 기존의 학습된 DNN을 그대로 다른 데이터셋에 적용하는 방식과 기존의 학습된 DNN을 수정하여 같거나 다른 데이터셋을 적용하는 방식 있음
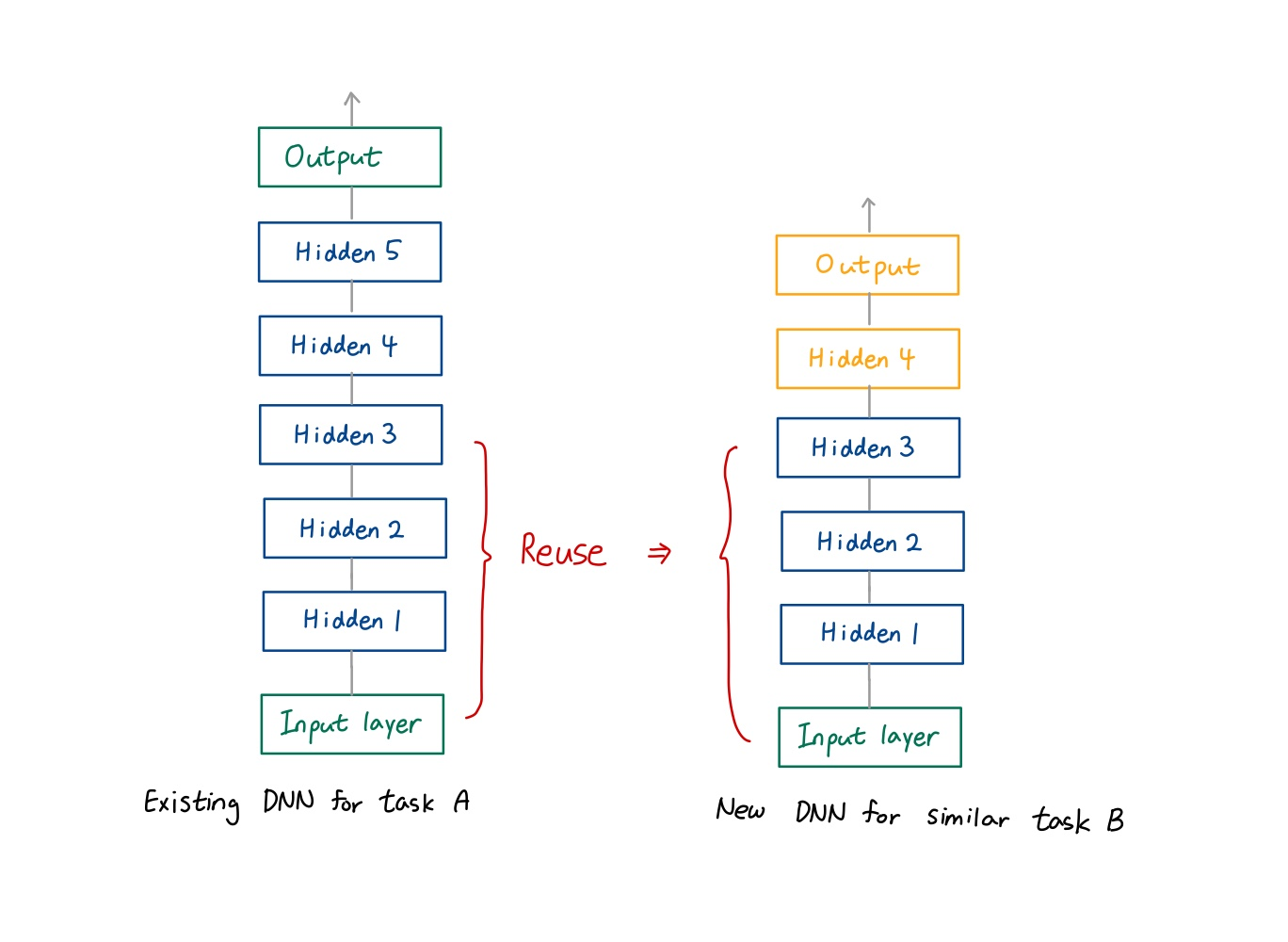
6) 예시
🔸 task A에 비해 task B의 data가 간단 => hidden layer 수 작음
🔸 hidden layer1~3까지의 parameter(weight 값) 재사용 => hidden layer1~3은 초기화하지 않고 task A에 있는 hidden layer1~3의 weight 가져와 그 값으로 초기화
🔸 hidden layer4만 초기화
🔸 hidden layer 1과 2의 weight는 바뀌지 않도록 fixed weights 사용, hidden layer 3과 4의 weight만 바뀌는 trainable weights => 잘 학습된 layer1과 2의 weight가 layer4로 들어오는 값에 의해 값이 바뀌어 학습 결과가 나빠질 수 있음
🔸 hidden layer 4의 weight 값이 가장 많이 바뀌고 hidden layer3도 그 영향으로 값이 바뀜
🔸 task A와 B가 비슷할 수록 layer3의 변화가 작음
7) 특징
🔸 fixed weight가 있는 상태에서 hidden 4를 통해 나온 결과를 끝으로 할 수 있고, 최적의 결과를 원하면 hidden 4가 안정적이어지면 fixed weight를 풀어 모든 layer가 학습되도록 함
🔸 hidden layer1~3의 weight 값들이 어느정도 학습된 상태에서 시작하므로 train 시간 짧음
🔸 기존보다 더 적은 데이터로 학습 가능
2. Ex
1) An existing DNN to classify pictures into 100 different categories, including animals, plants, vehicles, and everyday objects
🔸 사진을 100개의 카테고리로 분류하는 DNN
2) to train a DNN to classify specific types of vehicles
🔸 자동차의 종류를 분류하도록 학습
🔸 이때, 기존의 DNN에는 동물, 식물 등 다른 class들이 존재하는데 이는 일반적으로 자동차 분류에 좋은 영향을 줌
3) Different sized pictures:
🔸 add a preprocessing step to resize them
🔸 add or remove layers
🔸 => 사진의 크기가 다를 경우, 기존의 DNN 사이즈로 바꾸는 preprocessing 과정 필요
🔸 새로운 학습에 맞게 기존의 DNN layer를 추가하거나 줄이는 과정 필요
📌 Transfer Learning with Keras
1. Example
1) Model A: 8 class Fashion MNIST (excluding sandal and shirt), >90% acc
🔸 model A는 10개의 class를 가진 fashion MNIST에서 8개(sandal과 shirt 제외)의 class에 대해서만 분류 작업하는 모델
🔸 90% 이상의 accuracy 가짐
2) Task: train a binary classifier (positive=shirt, negative=sandal) with a dataset of 200 labeled images
🔸 전체 train data가 60,000개, 10개의 class이므로 각 class 당 6,000개의 data를 가지고 shirt와 sandal의 총 data 12,000개 중 200개의 image만을 사용해 transfer learning 진행
🔸 Model B (the same architecture as model A): 97.2% accuracy after training from scratch
🔹 transfer learning하지 않은 scratch 모델(처음부터 모델 생성)에 적은 data를 사용해 학습했는데도 높은 accuracy가 나온 것은 binary classifier이기 때문
3) Transfer learning
- model_A 불러와 copy
🔹 model_B_on_A transfer learning 진행
model_A = keras.models.load_model("my_model_A.h5") #학습 미리 진행한 후 "my_model_A"에 저장했다고 가정
model_B_on_A = keras.models.Sequential(model_A.layers[:-1]) #model A의 마지막 layer를 제외한 layer 복사
model_B_on_A.add(keras.layers.Dense(1, activation="sigmoid")) #마지막 출력 layer 추가- model_A의 clone 생성
🔸 Training model_B_on_A will also affect model_A => clone model_A
🔹 model_B_on_A가 model_A를 복사했기 때문에 model_A를 clone해서 따로 저장해야함
🔹 clone_model()을 사용해 model_A의 clone 생성
🔹 clone_model()은 모델의 모양만 clone하고 weight는 copy하지 않음 => set_weight()를 사용해 모델A의 weight 읽어와서 넣음
model_A_clone = keras.models.clone_model(model_A)
model_A_clone.set_weights(model_A.get_weights())- output layer의 weight가 reasonable할 때까지 이전 layer는 fixed => output layer만 학습 진행
🔸 Freeze the reused layers until the new layer learns reasonable weights and train
🔹 output layer를 제외한 재사용 layer는 weight 고정시키고 output layer만 학습 => output layer의 weight가 reasonable한 weight를 가질 때까지 weight 고정
for layer in model_B_on_A.layers[:-1]: #마지막 layer 제외한 layer 모두 fixed weight
layer.trainable = False #freeze
model_B_on_A.compile(loss="binary_crossentropy", optimizer="sgd", metrics=["accuracy"])
history = model_B_on_A.fit(X_train_B, y_train_B, epochs=4, validation_data=(X_valid_B, y_valid_B)) #output layer가 reasonable한 값을 가질 때까지만 진행하므로 epoch이 많을 필요는 없음. But 그 정도는 학습해봐야암- fixed weight 풀고 모든 layer 학습 진행
🔹 위에서 output layer의 weight가 나왔으므로 fixed weight 풀고 해당 layer도 학습 진행
🔸 Unfreeze the reused layers and train for fine-tuning
🔹 최적화된 결과를 얻기 위해서 fixed weight도 풀고 모든 layer를 학습해야함
🔹 learning rate를 1/100에서 1/10000로 바꿈 => 어느정도 모든 값이 정답 근처에 가있을 것이라고 생각해 fine tuning을 통해 가장 optimal한 값을 찾음. 정확히 어떤 값을 넣어야하는지는 학습을 해보면서 알아내야함
🔹 fixed weight가 있을 때의 epoch보다 더 많은 epoch동안 학습
for layer in model_B_on_A.layers[:-1]: #reused layer에서도 학습가능하도록
layer.trainable = True
optimizer = keras.optimizers.SGD(lr=1e-4) #default lr=1e-2
model_B_on_A.compile(loss="binary_crossentropy",optimizer=optimizer, metrics=["accuracy"])
history = model_B_on_A.fit(X_train_B, y_train_B, epochs=16, validation_data=(X_valid_B, y_valid_B))🔹 Final result: acc of 99.25%: error rate: 0.7% => scratch로 학습했을 때는 97.2%의 accuracy와 2.8%의 error rate 나타남
🔹 => transfer learning의 학습 결과가 훨씬 좋음. error rate 봤을 때 약 4배의 성능 + 사용한 epoch 수도 줄었음 + 200개밖에 안되는 data로 좋은 성능 얻음
model_B_on_A.evaluate(X_test_B, y_test_B)🔹 결과: [0.068879..., 0.9925] => shirt일 확률 0.068879... 이고 sandal일 확률 0.9925
🔸 It is the best case (choice of classes, and other hyperparameters): 가장 성능이 좋은 경우를 골라 scratch와 transfer의 성능 차이가 4배가 난 것. sandal과 shirt가 아닌 다른 class를 고르면 성능의 차이가 4배보다 작을 것
4) Transfer learning does not work very well with small dense networks
🔹 small dense network: layer와 neuron의 수가 작은 network
🔹 dense network = fully connected network
🔸 small networks learn few patterns => 뉴런의 수가 작아 학습 패턴이 적음
🔸 dense networks learn very specific patterns => 특정한(동일한) 데이터셋의 이미지 패턴에 맞는 specific한 패턴을 학습하는 경우가 많아 다른 데이터셋을 사용할 경우 이를 적용하기 어려움 => CNN의 경우 데이터셋이 달라지더라도 적용 가능
🔸 unlikely to be useful in other tasks
🔸 => 복잡한 dense network에서 효과 있음.
🔸 small dense network의 경우 transfer learning 효과 없어 scratch해서 사용. 좋은 결과내기는 어렵고 학습 시간을 줄이는 정도로만 만족해야함
🔸 학습이 전혀 안 되는 경우도 존재
5) Transfer learning works best with deep convolutional neural networks
🔸 tend to learn feature detectors that are much more general (especially in the lower layers)
📌 Unsupervised Pretraining
🔸 Unsupervised learning: label 없는 data clustering
1. Condition
1) Not enough labeled training data
2) No pretrained model on a similar task
3) Plenty of unlabeled training data
2. Action
1) reuse the lower layers of the autoencoder(ch.16) or the GAN's discriminator(ch.17)
🔸 unsupervised learning을 위한 neural network: autoencoder, GAN's discriminator
🔸 앞에서 공부한 것(supervised learning)과 달리 unsupervised learning을 진행한 결과의 lower layer 재사용
2) add the output layer on top, and
3) finetune the final network using supervised learning with the labeled data
🔸 충분하지 않은 data를 이용해 학습을 진행시키면 overfitting 발생할 가능성이 높아져 충분하지 않은 supervised data로 처음부터 학습시키기는 어려움
3. History
🔸 deep neural network 초창기에 많이 사용한 방식
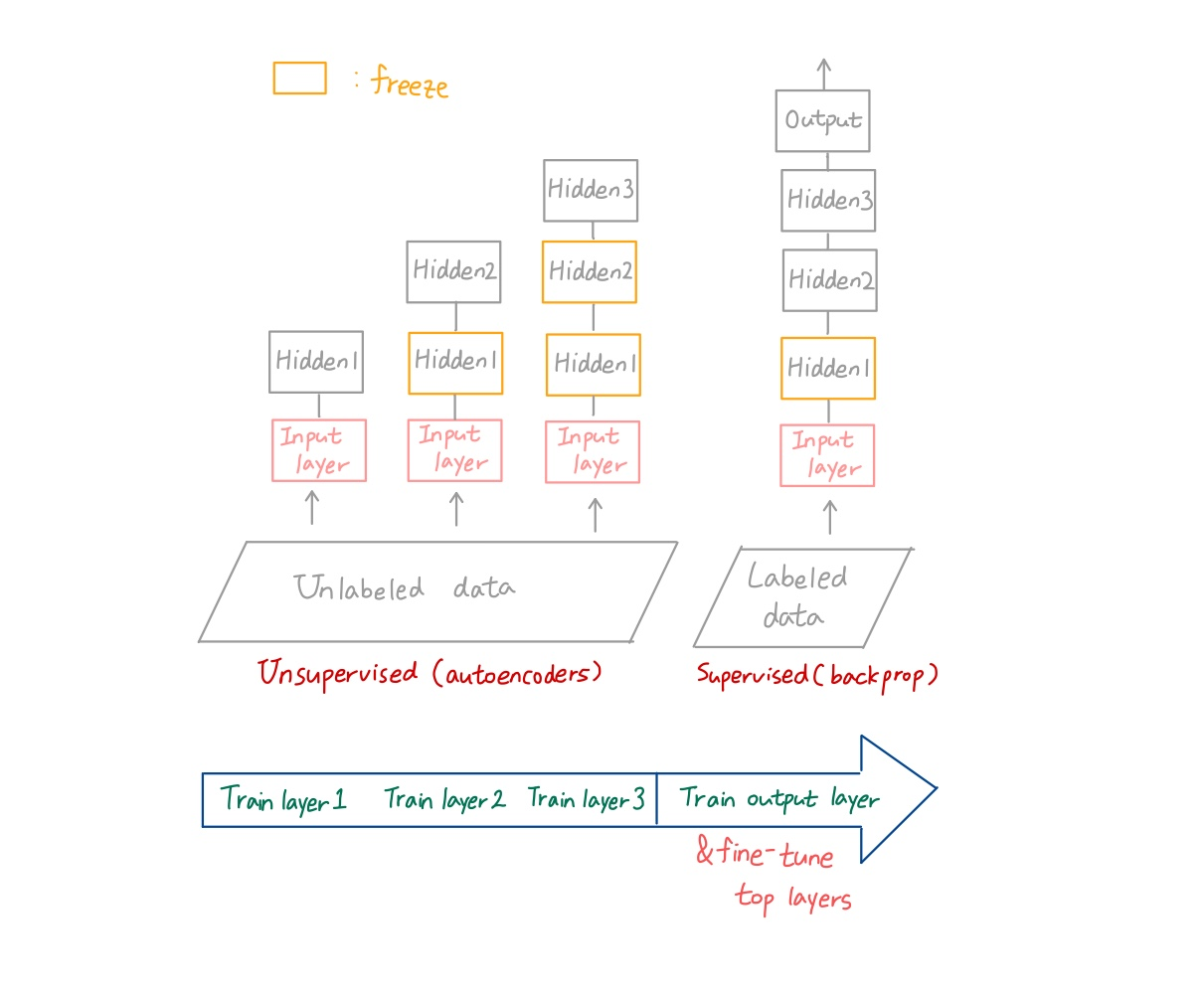
1) greedy layer-wise pretraining
🔸 : pretraining 방법 중 하나
🔸 => label 하나씩 unsupervised data로 unsupervised learning(autoencoder. label이 없기 때문에 backpropagation 못 함)학습 진행 + 앞에서 학습을 진행한 layer는 freeze(=fixed weight) + 적정한 수의 (lower) hidden layer를 freeze시킨 후 output layer 추가하고 labeled data를 이용해 supervised learning(backpropagation)으로 학습 진행
🔸 => 가장 많이 사용하는 것은 가장 위에 있는 hidden layer만 trainable하게 만들고 나머지는 freeze한 후 아래로 내려가면서 하나씩 풀어줌
🔸 Train the layers one by one, starting with the lowest layer => other layers freezed
🔸 fine-tune the networkusing supervised learning (with backpropagation)
🔹 supervised learning으로 fine tuning
2) Revival of neural network and Success of Deep Learning in 2006 by G.Hinton
3) Until 2010, unsupervised pretraining (typically with RBMs) was the norm for deep nets
4) Nowadays, one-shot training and using autoencoders or GANs rather than RBM
🔹 에전에는 RBM을 이용해 unsupervised learning 진행했지만 요즘은 autoencoder 또는 GANs을 이용
📌 Pretraining on an Auxiliary Task
🔸 Unsupervised pretrain하는 경우는 supervised learning을 위한 labeled data가 충분하지 않은 경우
1. Cheap unlabeled training examples, but quite expensive to label them
2. Train a first neural network on an auxiliary task (labelled training data can be easily obtained or generated) => reuse the lower layers for actual task
🔸 내 목적에는 맞지 않지만 label된 training data를 쉽게 얻을 수 있는 경우 해당 auxiliary(보조적인) task에 관한 neural network를 만든 후 lower layer 재사용
1) The first neural network's lower layers will learn feature detectors
🔸 첫번째 neural network의 lower layer는 입력 데이터의 feature를 detect
2) Ex. Face recognition system
🔸 Requires hundreds of pictures for each person => difficult to gather
🔸 Gather a lot of pictures of random people on the internet
🔸 Train a first NN: detect the same person on two different pictures => to learn good feature detectors for faces
🔸 => 얼굴 인식 시스템을 만들기 위해서는 각각의 사람의 수백개의 사진들이 필요한데 이는 실질적으로 어려움. 따라서 인터넷에 있는 사람의 사진을 random하게 수집하고 첫번째 neural network 학습: 두 개의 다른 사진에 동일한 인물이 있는지 detect하는 neural network 생성해 훈련 => lower layer는 얼굴을 인식해야하므로 얼굴에 대한 feature detect로써의 역할을 함
3) pretrain on an auxiliary task 순서
- Label all training examples as "good"
- Generate many new training instances by corrupting the good ones: labelled as "bad"
- Train a first neural network to classify instances as good or bad
🔸 학습하는 동안 lower layer들은 이미지의 local한 패턴(lower level pattern)들을 학습하는 feature detector로써 학습 진행
🔸 위에서 생성한 lower layer와 몇개의 layer를 추가해 별로 없는 label된 데이터로 학습시키면 충분하지 않은 데이터로도 학습 가능
4) Ex. NLP application: download millions of sentences (labelled as "good") => randomly change a word in each sentence (labelled as "bad")
🔸 NLP(Natural Language Processing, 자연어 처리 어플리케이션)
5) Ex. Randomly mask out some words and train a model to predict the missing words
🔸 단어를 가리고 사라진 단어를 예측하는 모델 학습
🔸 mask된 단어에 label이 붙기 때문에 predict한 단어와 mask된 단어를 이용해 supervised learning 가능
6) Self-supervised learning: automatically generate the labels from the data itself
🔸 위에서 말한 mask된 단어와 같이 데이터로부터 자동으로 label을 생성할 수 있는 학습 방식이 self-supervised learning
7) Max margin learning: train a network with score outputs
🔸 Use a cost function that results in max score difference between good and bad instances
