📌 Training an MLP with TensorFlow's Hight-Level API:Keras
🔸 MLP 학습시키는 방법 중 하나인 Keras를 이용한 학습 방법
🔸 Keras는 TensorFlow의 high-leverl API
1. TF.Learn API -> Slim -> Keras
2. Documentation (or specification) is available at https://keras.io/
🔸 순수 kears와 관련된 정보 제공
1) Also https://www.tensorflow.org/api_docs/python/tf/keras
🔸 tensorflow에서 구현된 keras와 관련된 정보 제공
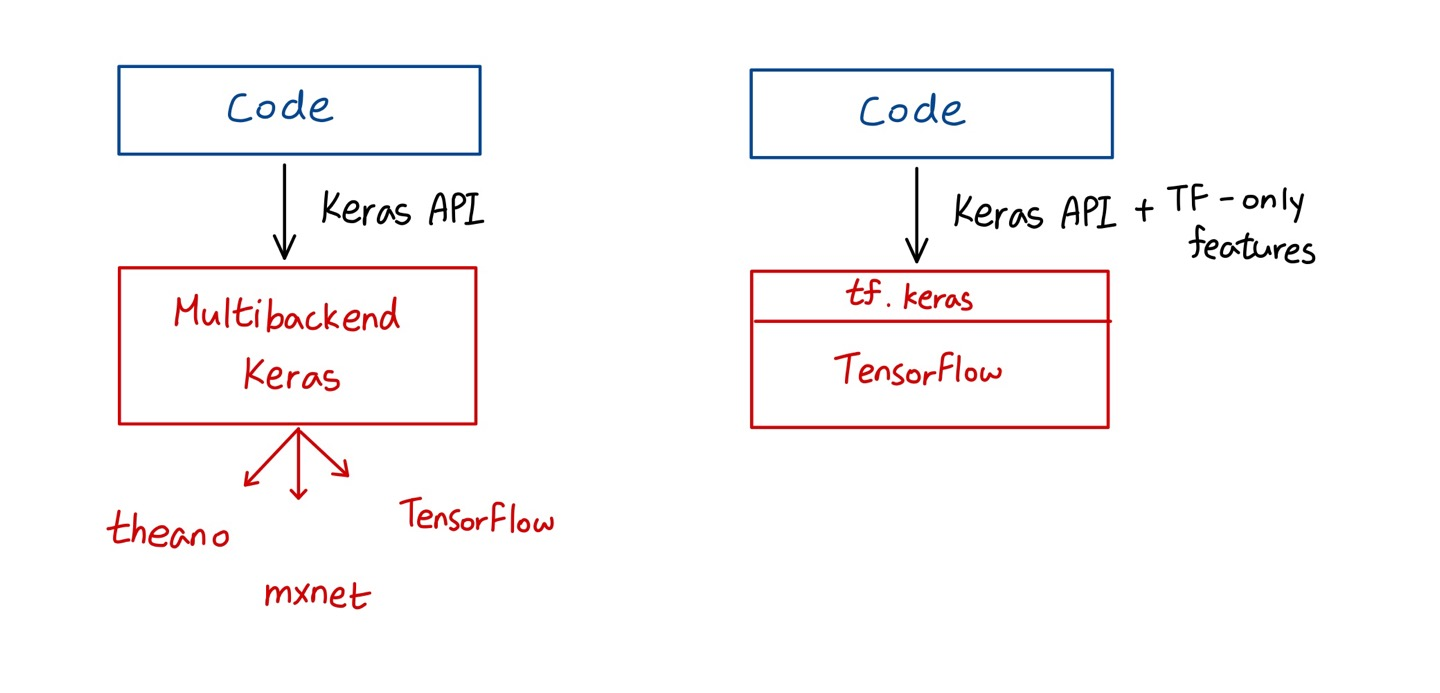
3. Multibackend Keras relies on computation backend
🔸 다양한 방식으로 keras 구현 가능. interface는 동일하지만 구현 방식에 차이 있음
1) TensorFlow, Microsoft Cognitive Toolkit(CNTK), and Theano
2) Other implementation: Apache MXNet, Apple's Core ML, Javascript or TypeScript and PlaidML
🔸 TensorFlow의 keras 중심으로 구현 방법 살펴볼 것
4. tf.keras: Keras implementation in tensorflow
1) Implementing Keras API and some very useful extra features (tensorflow-specific)
🔸 keras API 구현
🔸 tensorflow 한정으로 사용할 수 있는 기능들 존재. 다른 implementation에서는 사용 불가
2) Ex.Supports TensorFlow's Data API
🔸 순수한 keras API는 아니지만 tensorflow에서 사용 가능
🔸 데이터 처리 쉬워짐
3) https://www.tensorflow.org
🔸 순수한 Keras API를 이용한 code 작성 -> Multibackend keras에 따라 코드를 어떤 환경에서 사용할지 결정
🔸 code에 순수한 keras API 뿐만 아니라 TensorFlow에서만 사용할 수 있는 TF-only features가 존재한다면 tensorflow에서만 사용할 수 있음
5. PyTorch(facebook) library
🔸 tensorflow 외에도 deeplearning을 학습시키는데 사용하는 library는 facebook의 pytorch 라이브러리
1) Similar to Keras
2) Easy to switch
🌟 Classifier <- Regression은 이 이후
📌 Building an Image Classifier Using the Sequential API
1. Install tensorflow
2. Check installation
import tensorflow as tf
from tensorflow import keras
tf.__cersion__
keras.__version__3. Fashion MNIST- Dataset
1) exactly the same format as MNIST (70,000 grayscale images, 28x28 pixels and 10 classes)
2) but fashion items
🔸 fashion item이 class
3) class is more diverse, and significantly more challenging
4) a simple linear model: about 83% accuracy on Fashion MNIST
🔸 About 92% on MNIST
🔸 Fashion MNIST가 더 복잡하고 정교한 모델 사용해야함
🔸 Nueral network가 기본적인 머신러닝 모델보다 성능이 좋아 fashion MNIST 사용하는 것이 특성의 차이를 보는데 도움이 됨
🔸 class; Coat, Sneaker, Ankle boot, T-shirt/top, Trouser, Bag, Shirt, Dress, Sandal, Pullover
📌 Using Keras to load the dataset
1. Utility functions to fetch and load common datasets
🔸 load_data() 메소드를 이용해 train data와 test data 분리
🔸 fashion_mnist는 총 70000개의 data set을 가짐. X_train_full은 60000개, X_test는 10000개
fashion_mnist = keras.datasets.fashion_mnist
(X_train_full, y_train_full), (X_test, y_test) = fashion_mnist.load_data()🔸 image is represented as a 28x28 array; pixel intensities in integers (from 0 to 255)
🔹 Scikit-Learn: a 1D array of size 784; floats (from 0.0 to 255.0)
🔹 Scikit-Learn의 경우는 1D array의 float 타입이지만 keras의 fashion_mnist는 28x28의 2D array로 되어있고 값이 integer 형태 => scikit-learn과 데이터 형태가 다름
🔸 X_train_full의 shape은 60000개의 data가 28x28의 2D array 형태로 존재
🔸 X_train_full의 type은 unsigned integer
X_train_full.shape #(60000,28,28) 출력
X_train.full.dtype #dtype('unit8') 출력2. Data preprocessing
1) Validation set creating and scaling input features (for training using Gradient Descent)
🔸 X_valid, y_valid는 5000개, X_train,y_train은 55000개
🔸 input features로 scaling을 진행해(255.0으로 나누기) 0~255까지의 값을 0~1까지의 float point 값으로 변환 (Gradient Descent 사용하기 때문)
🔸 y_valid와 y_train은 나누기만 하고 scaling 진행하지 않음
X_valid, X_train = X_train_full[:5000]/255.0, X_train_full[5000:]/255.0
y_valid, y_train = y_train_full[:5000], y_train_full[5000:]2) List of class names
🔸 dataset에는 이름이 들어가있지않고 0~9까지의 class로만 표현됨 => 바로 알아차릴 수 없어 각 class 이름 표현
🔸 fashion_mnist에서 정한 class와 이름을 matching시킨것
class_names = ["T-shirt/top", "Trouser", "Pullover", "Dress", "Coat", "Sandal", "Shirt", "Sneaker", "Bag", "Ankle boot"]
class_names[y_train[0]] #'Coat' 출력
#만약 class_names 사용하지 않고 y_train[0]만 출력하면 4 출력될 것📌 Creating the model using the Sequential API_1
🔸 실제로 학습시킬 network model 생성
🔸 모델 생성시키는 방법이 여러 개 있는데, 간단한 Sequential API 사용
1. model = keras.models.Sequential()
🔸 Sequential API를 사용해 비어있는 Sequential model object 생성
🔸 model이라는 이름에 add를 사용하여 순차적으로 layer를 넣을 수 있음
2. model.add(keras.layers.Flatten(input_shape=[28,28]))
🔸 fashion_mnist의 instance가 28x28이었기에 input_shape=[28,28]로 지정, input_shape에는 batch size는 포함하지 않고 instance의 shape 지정
🔸 Flatten layer는 2D array를 1D array로 바꿔줌
3. model.add(keras.layer.Dense(300,activation="relu"))
🔸 model에 300개의 neuron을 가지고 activation 함수로 relu를 사용하는 hidden layer 추가
🔸 Dense layer는 fully connected layer와 같으며 MLP의 각 layer를 말함
🔸 Dense() 안의 첫번째 파라미터는 neuron의 개수, 두번째 파라미터는 activation function. activation function을 지정하지 않으면 default activation function은 none으로 activation function 적용하지 않고 바로 값 출력
🔸 regression의 경우 마지막 output layer의 activation function이 없는데 이를 제외하고는 항상 activation function 적용해야함
4. model.add(keras.layer.Dense(100,activation="relu"))
🔸 model에 100개의 neuron을 가지고 activation 함수로 relu를 사용하는 hidden layer 추가
5. model.add(keras.layers.Dense(10, activation="softmax"))
🔸 마지막 layer는 출력 layer. 출력 layer의 neuron은 class의 개수에 따라 결정됨. class가 10개이므로 neuron의 수도 10개
🔸 output layer의 activation function은 multiclass를 사용하고 있어 softmax 사용
💡 hidden layer의 neuron의 개수는 임의로 정하는 것이지만 입력 layer(input_shape=[28,28])와 출력 layer의 neuron의 개수(10)는 dataset에 따라 결정됨
model = keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape=[28,28]))
model.add(keras.layer.Dense(300,activation="relu"))
model.add(keras.layer.Dense(100,activation="relu"))
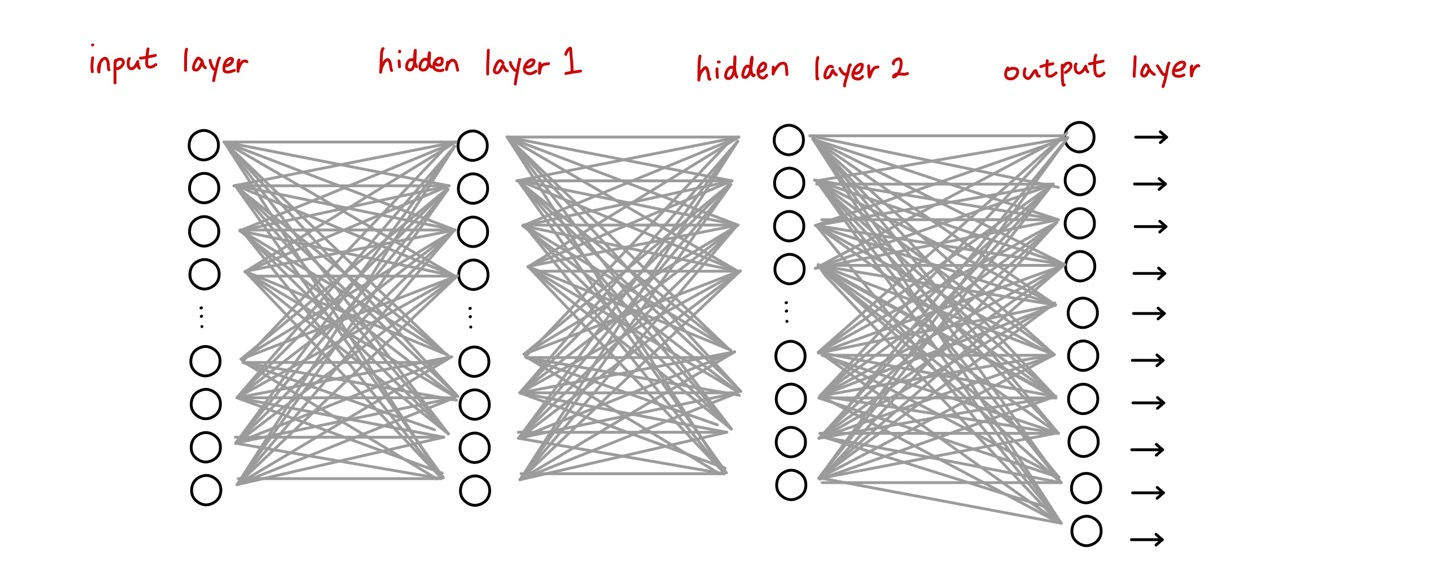
model.add(keras.layers.Dense(10, activation="softmax"))6. 모델
🔸 입력으로 28x28의 2D array가 들어오면 784개의 1D array로 만들어줌 => input layer의 neuron 수(입력 노드):784개
🔸 hidden layer1이 첫번째 Dense layer로 neuron 수:300, activation function: relu
🔸 hidden layer2가 두번째 Dense layer로 neuron 수:100, activation function: relu
🔸 output layer가 마지막 Dense layer로 neuron 수:10, activation function: softmax
📌 Creating the model using the Sequential API_2
🔸 Sequential API를 사용해 model 만드는 또다른 방법
🔸 이전에는 빈 model 생성 후 layer 하나씩 추가하는 방식이었는데, 이번에는 모델 생성과 동시에 layer 한 번에 정의
1. Sequential layer
🔸 Creating the weights and biases variables using Dense layer
🔹 Sequential layer를 사용해 dense layer를 추가하면 weight와 bias를 자동으로 생성해줌. connection의 weight가 생성되고 각 hidden layer마다 하나의 bias씩 추가
🔸 Proper initialization strategy(kernel_initializer)
🔹 kernel_initializer라는 파라미터를 이용해 적절한 initialization strategy를 결정. 사용하지 않을 경우 default initialization strategy 사용
🔸 No activation function by default
🔹 activation function의 default는 사용하지 않는 것이므로 사용하려면 반드시 지정해줘야함
🔸 Supports regularization parameters
n_inputs=28
n_hidden1=300
n_hidden2=100
n_outputs=10
model = keras.Sequential([
keras.layers.Flatten(input_shape=(n_inputs, n_inputs)),
keras.layers.Dense(n_hidden1, activation="relu"), #미리 정의된 함수, built-in activation function 사용할 때의 코드
keras.layers.Dense(n_hidden2, activation=tf.activations.relu), #미리 정의되어 있지 않으면 이처럼 지정해서 사용 가능. 위와 같은 코드
#keras.layers.Dense(n_hidden2), keras.layers.ReLU() 코드는 바로 위의 한 줄 코드와 동일한 의미
keras.layers.Dense(n_outputs, activation="softmax")
])🔸 binary classification일 경우, output activation function으로 softmax가 아닌 sigmoid(logistic regression) 사용
위에서는 class가 10개이기 때문에 output activation function으로 softmax 사용
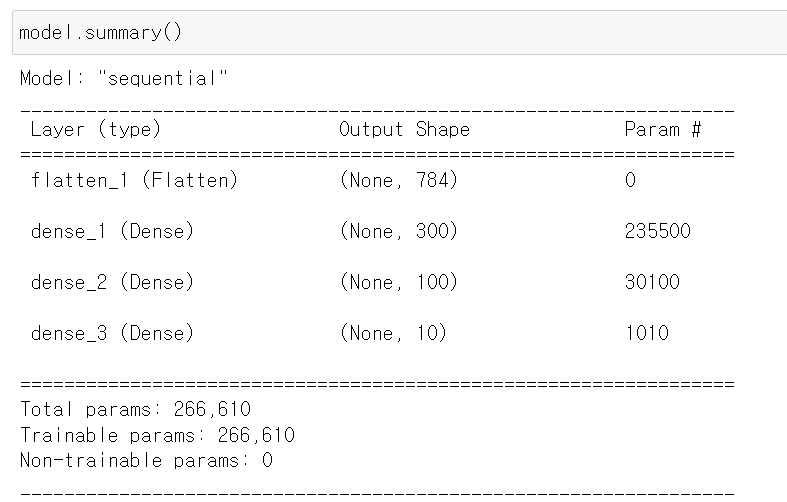
2. model.summary()
🔸 model 생성 후에는 확인해야함
🔸 param #은 weight와 bias를 나타냄.
🔹 hidden layer1의 neuron 입장에서 보면 input layer의 모든 neuron이 hidden layer의 neuron에 한번씩 들어오므로, hidden layer의 하나의 neuron은 784개의 weight를 가지고 이런 neuron이 300개 존재=> 784x300.
🔹 input layer에 있는 bias neuron도 각 hidden layer의 neuron에 한 번씩 weight를 보내므로 300 추가
🔹 총 784x300+300 = 235500개의 parameter 존재, 즉 (784+1)x300=235500
🔸 학습을 시키면서 값을 계속 바꿀수있는 parameter가 trainable params
🔸 parameter가 많을수록 많은 메모리를 필요로 하고 학습 시간이 오래 소요
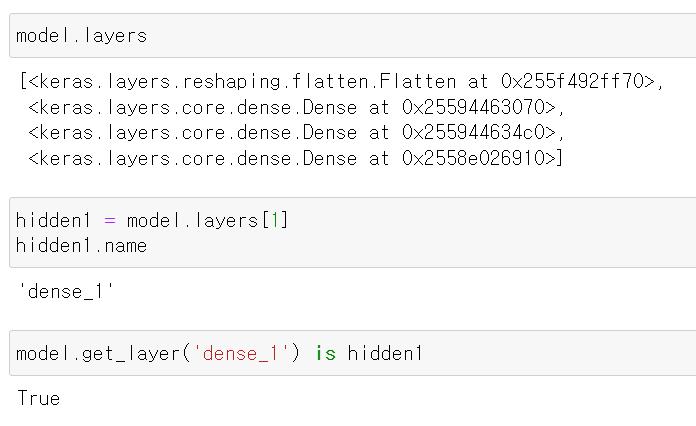
3. model.layers
🔸 summary()에서 layer에 대한 정보만 알려줌
🔸 각 layer의 이름과 memory 주소 알 수 있음
💡 Large number of parameter
=> a lot of flexibility to fit the training data: 복잡한 모델 학습시키기 좋음
=> runs the risk of overfitting, especially with not enough training data: training data가 충분하지 않을 경우 overfitting의 가능성 존재. 이 경우 paramter 수를 줄여 모델을 단순하게 만들어 방지
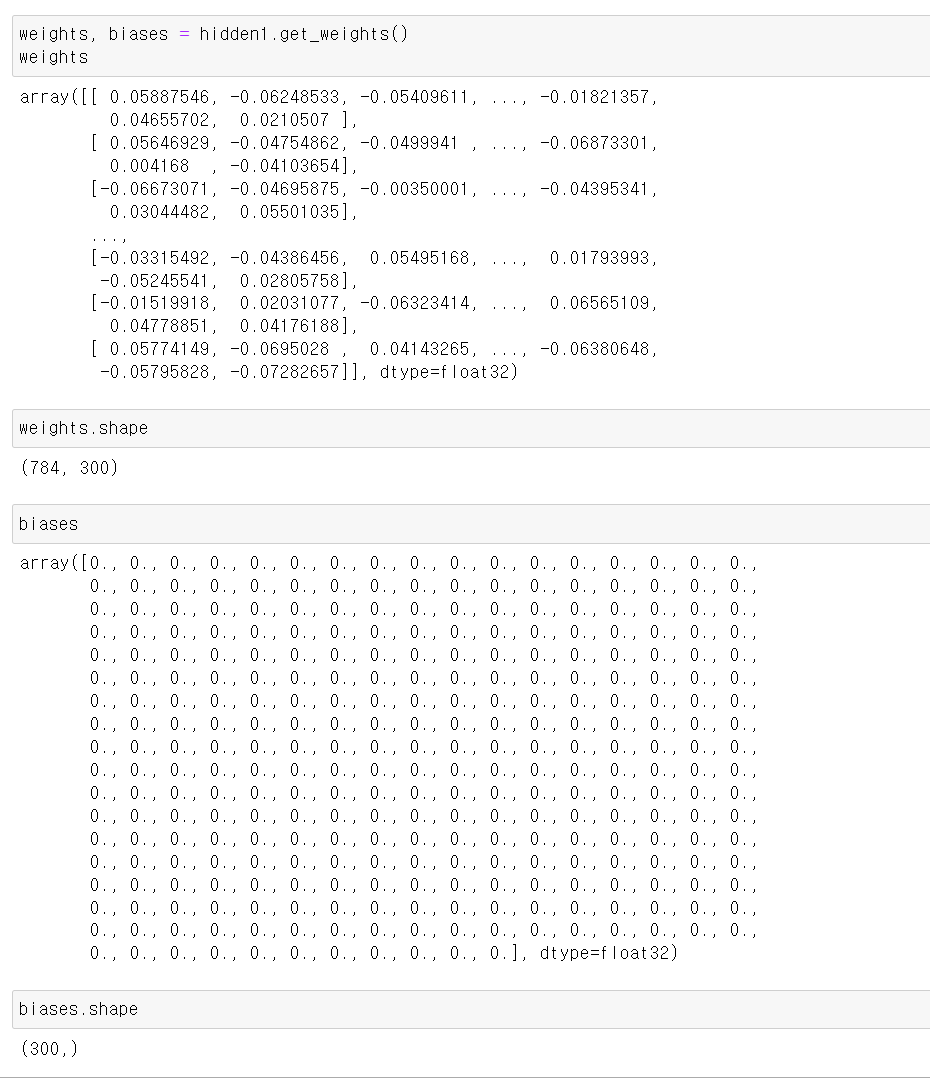
4. weights와 bias 값 별도로 저장
1) weights, biases = hidden1.get_weights()
weights, biases = hidden1.get_weights()
weights 2) weights.shape()
🔸 784개의 input neuron에서 300개의 neuron으로 weight 생성
3) biases
🔸 1D 형태로 300개