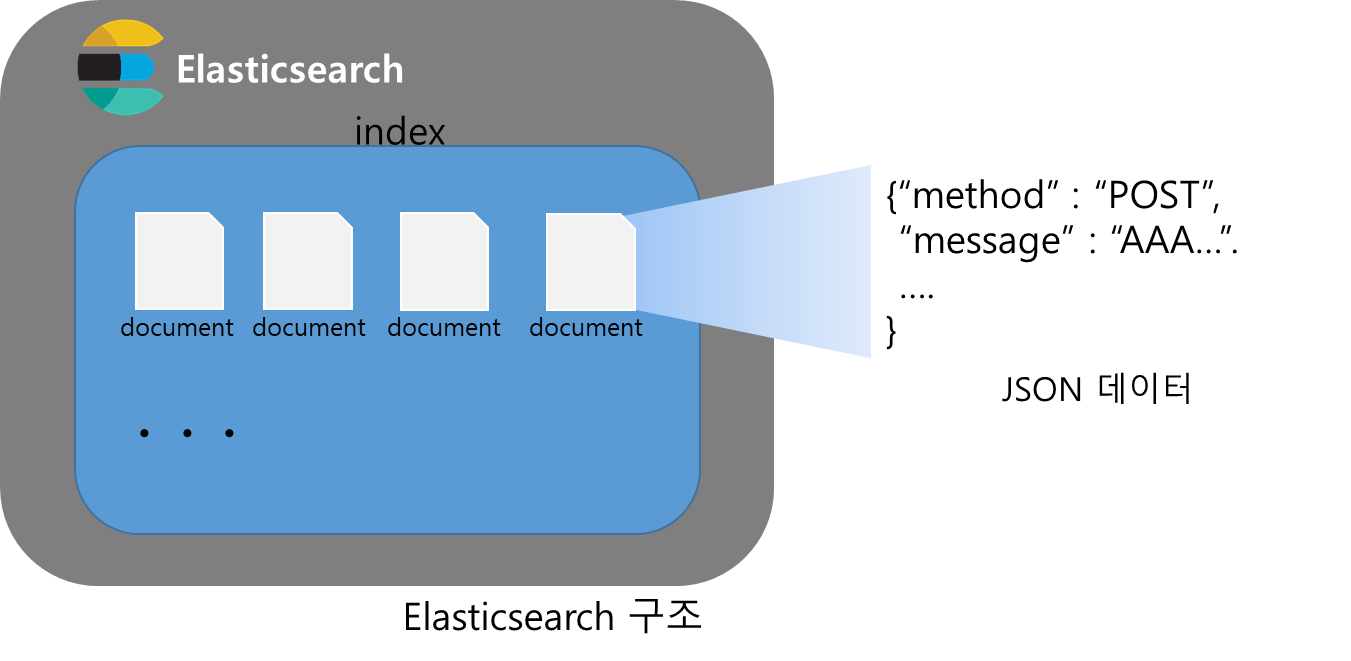
1.Elasticsearch 구조
JSON 형식으로 데이터를 분산 저장하고 검색 및 분석 기능을 제공하는 엔진으로 index, shard, document로 이루어져 있음
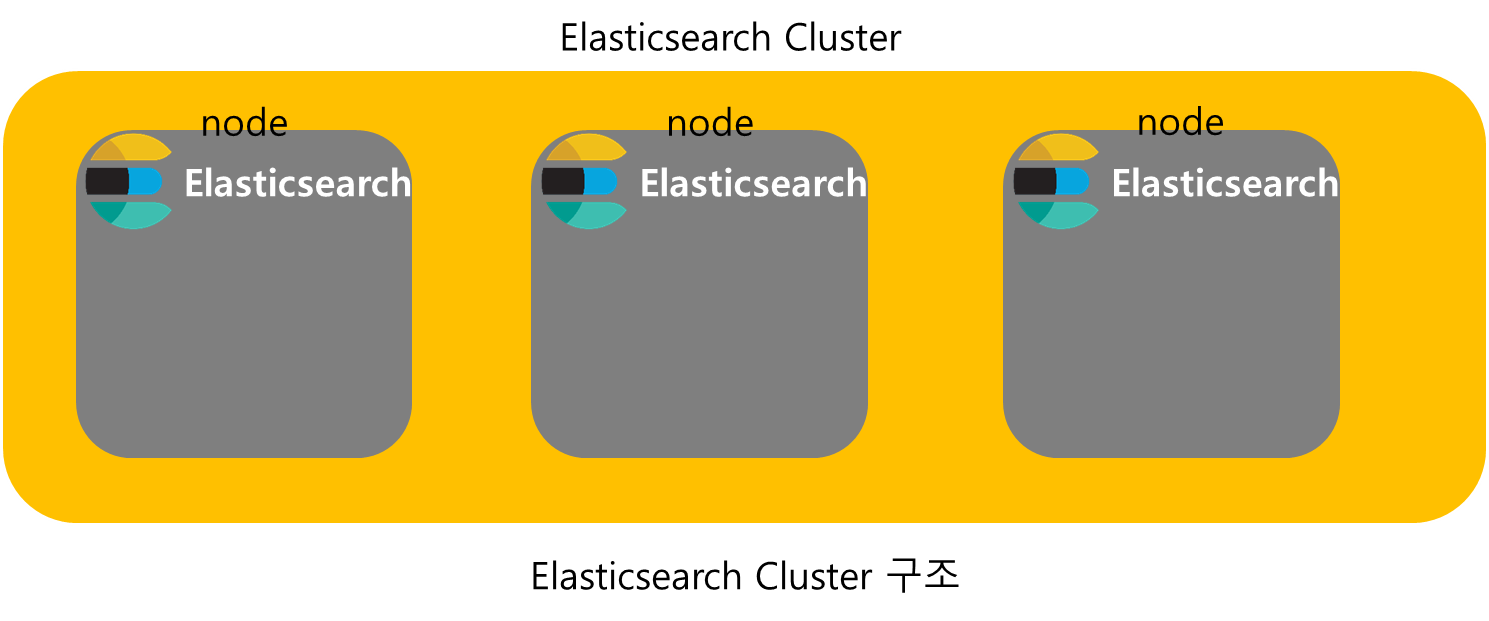
Cluster와 Node
elasticsearch에서 고가용성을 제공하기 위해 여러개의 Elasticsearch를 묶어 Cluster 형태로 사용할 수 있다.
각각의 elasticsearch는 node가 되어 각각의 node에 데이터가 분산 저장된다.
node는 데이터 저장 기능과 Node 관리 기능을 모두 수행하지만 MasterNode와 dataNode로 전문화가 가능하다.
MasterNode는 데이터 저장 기능을 수행하지 않고 node의 관리를 전문적으로 수행한다.
DataNode는 node 관리 기능을 수행하지 않고 data의 저장 기능만 담당한다.
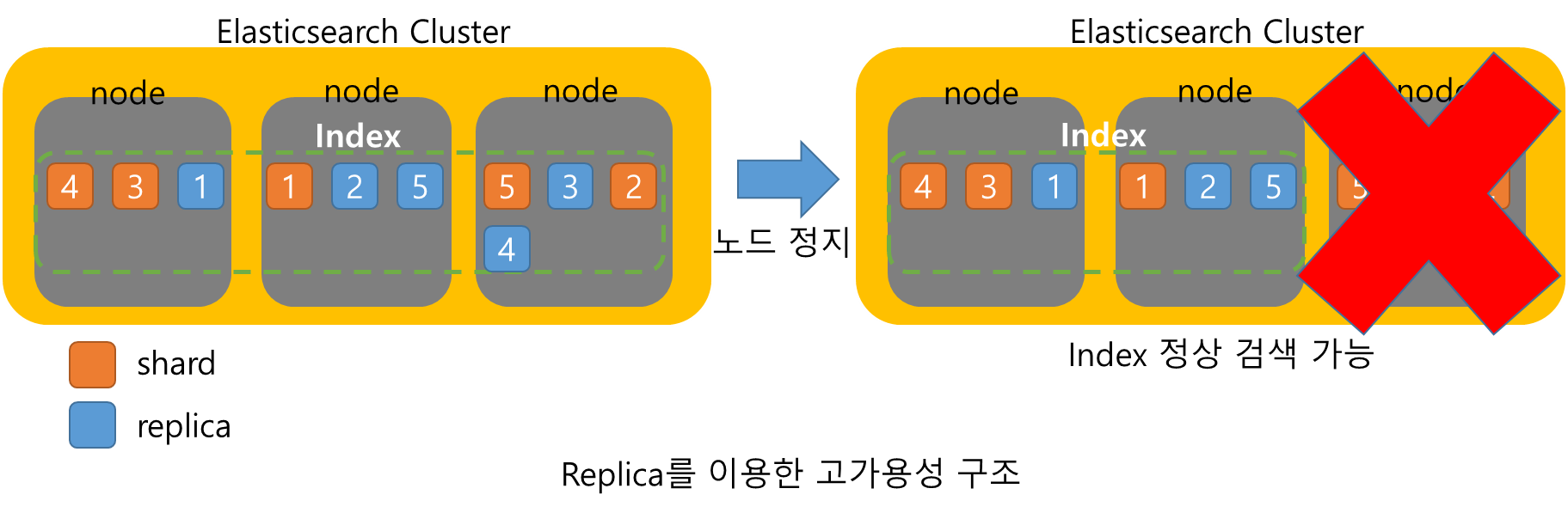
Index와 Shard
Index는 MasterNode를 제외한 node들에 Shard 형태로 분산 저장되어 있으며 원본 Shard를 복사하여 replica shard를 생성하고 원본과 겹치지 않게 배치하여 일부 node가 비활성화 되더라도 정상적인 검색을 가능하게 한다.
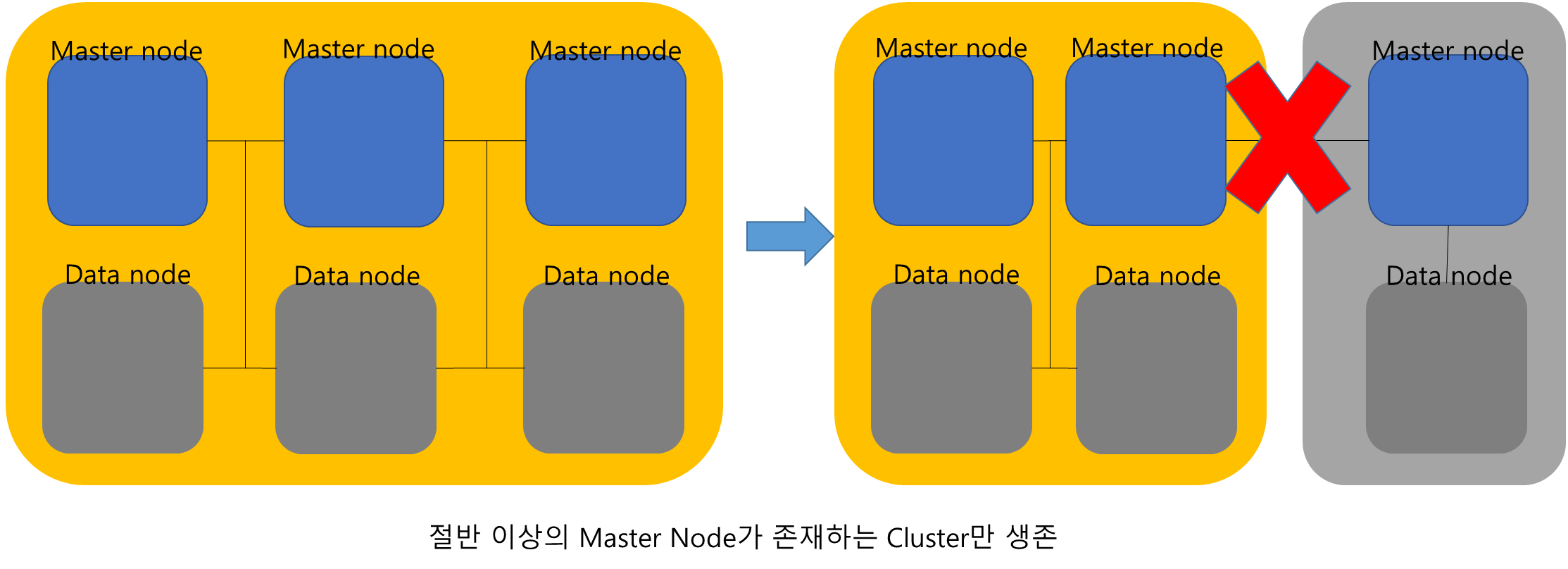
Split Brain
Master Node가 짝수로 존재할 시에 Master Node 사이의 네트워크가 단절될 시에 각각의 Master Node는 절반 이상일 경우가 생길 수 있다.
이 경우 분리된 Master Node들이 각각 cluster로써 동작하여 네트워크가 연결되었을때에 데이터에 문제기 생길 수 있다.
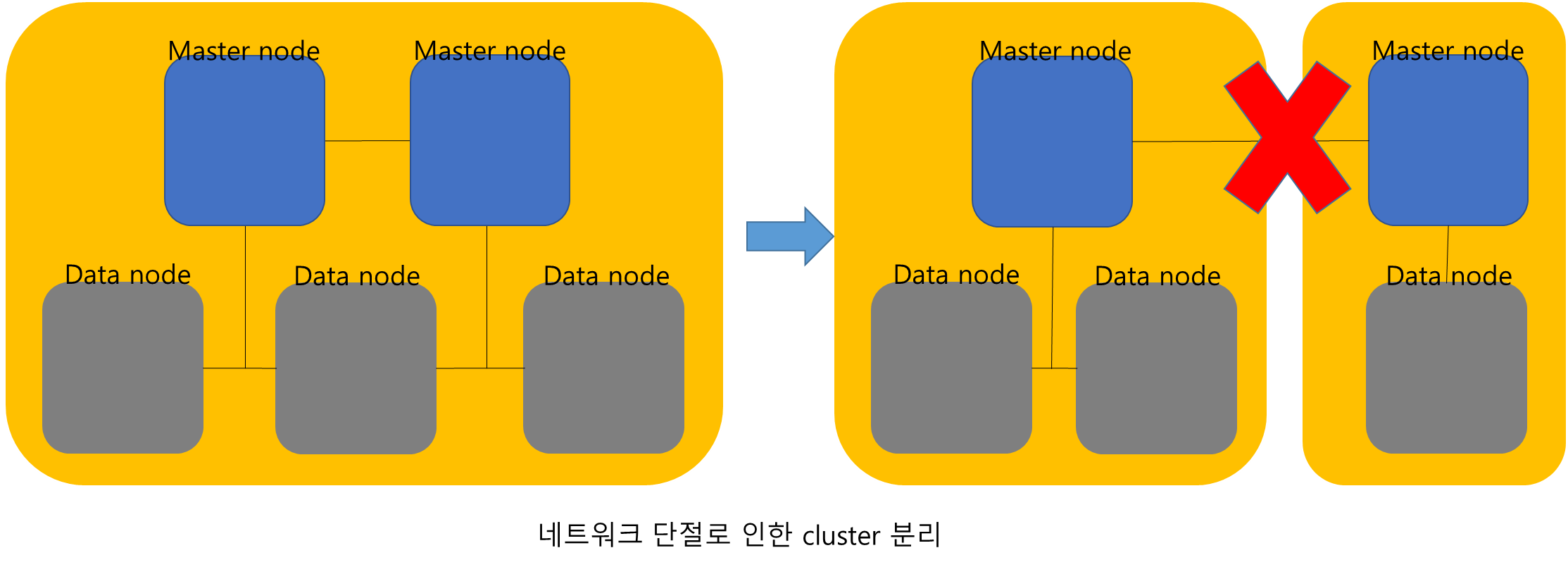
이를 막기 위해 Master Node는 홀수 개수로 생성하여야 하며 홀수일 경우 네트워크 단절이 일어나도 절반 이하의 Cluster와 절반 이상의 Cluster가 생성되어 절반 이하인 Cluster는 동작을 정지하고 연결이 복구되었을 때에 데이터를 동기화하여 해당 문제를 극복할 수 있다.