1.Logstash 구조
Logstash는 Input, Filter, Output순서의 pipeline 구조로 이루어져있다.
하나의 Logstash는 여러개의 pipeline을 가지며 각각의 pipeline은 여러개의 Input, Filter, Output을 가질 수 있다.
데이터 수집과 정제기능을 수행하지만 정제 기능이 자원을 많이 사용하므로 LoadBalance나 Queue를 사용하기도 한다.
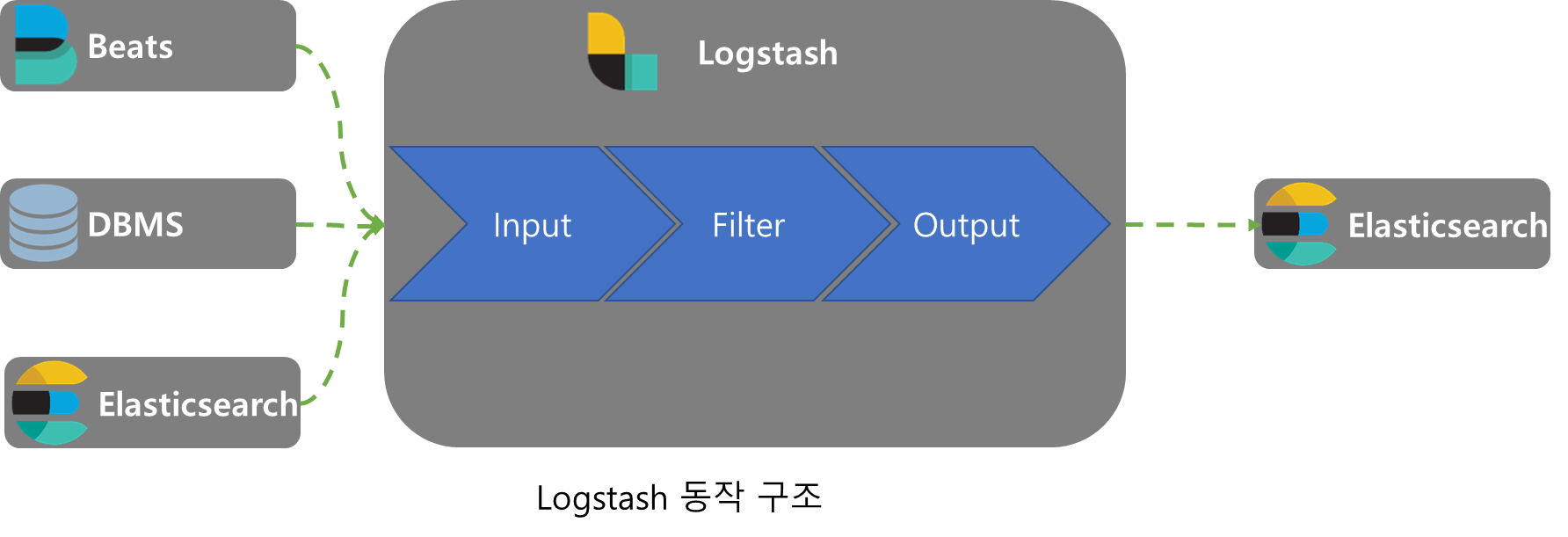
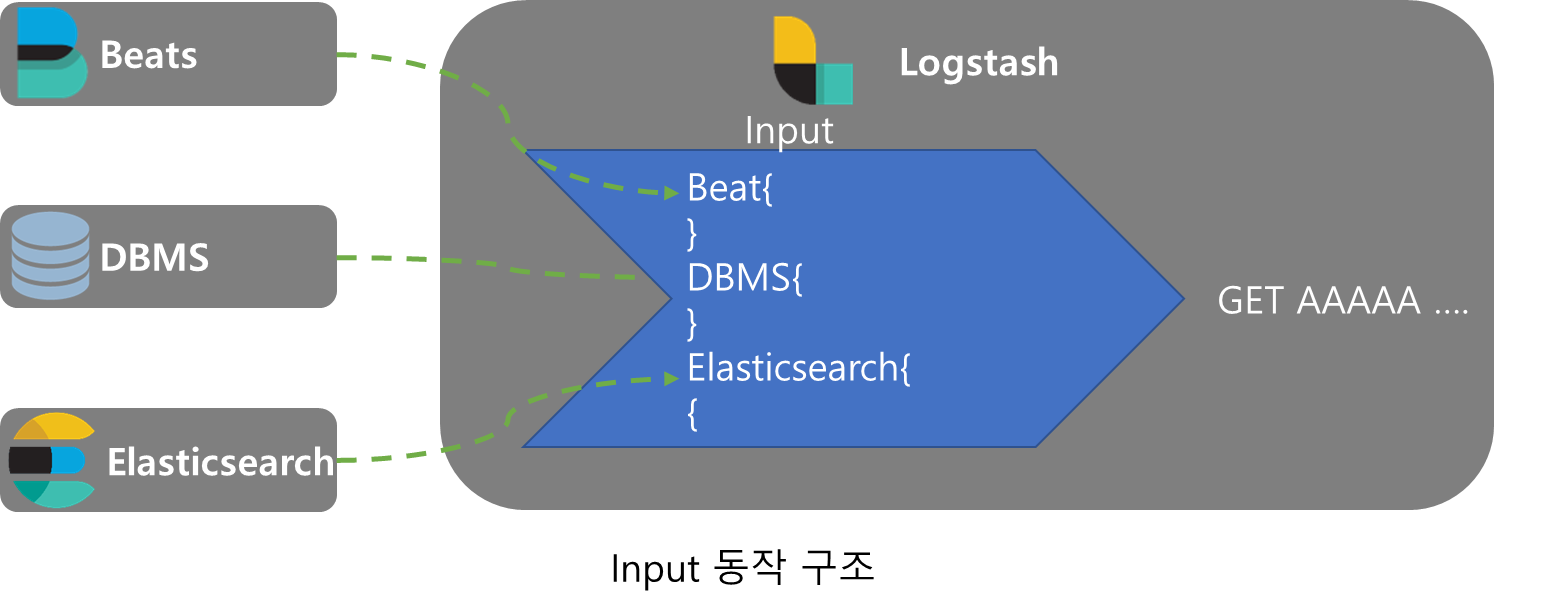
Input
input은 여러 종류의 plugin으로 여러 소스에서 데이터를 받아와서 4개의 기본 Logstash데이터(@version, message, @timestamp, host)를 추가하여 Fliter로 보낸다.
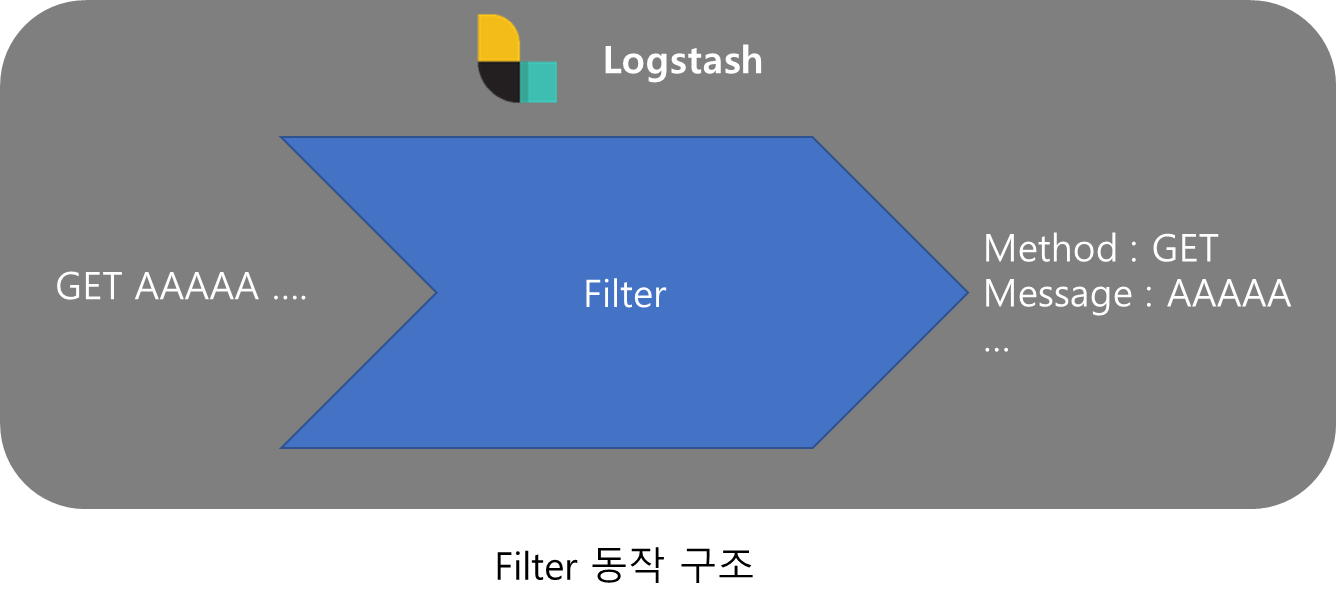
Filter
Filter는 Logstash의 핵심 기능으로 받은 데이터를 분류하고 분석하여 정규화하거나 불필요하거나 보안에 관련된 데이터를 삭제하는 등의 데이터 조작을 실행하는 단계로 각각의 기능은 여러가지의 plugin으로 이루어져 있다.
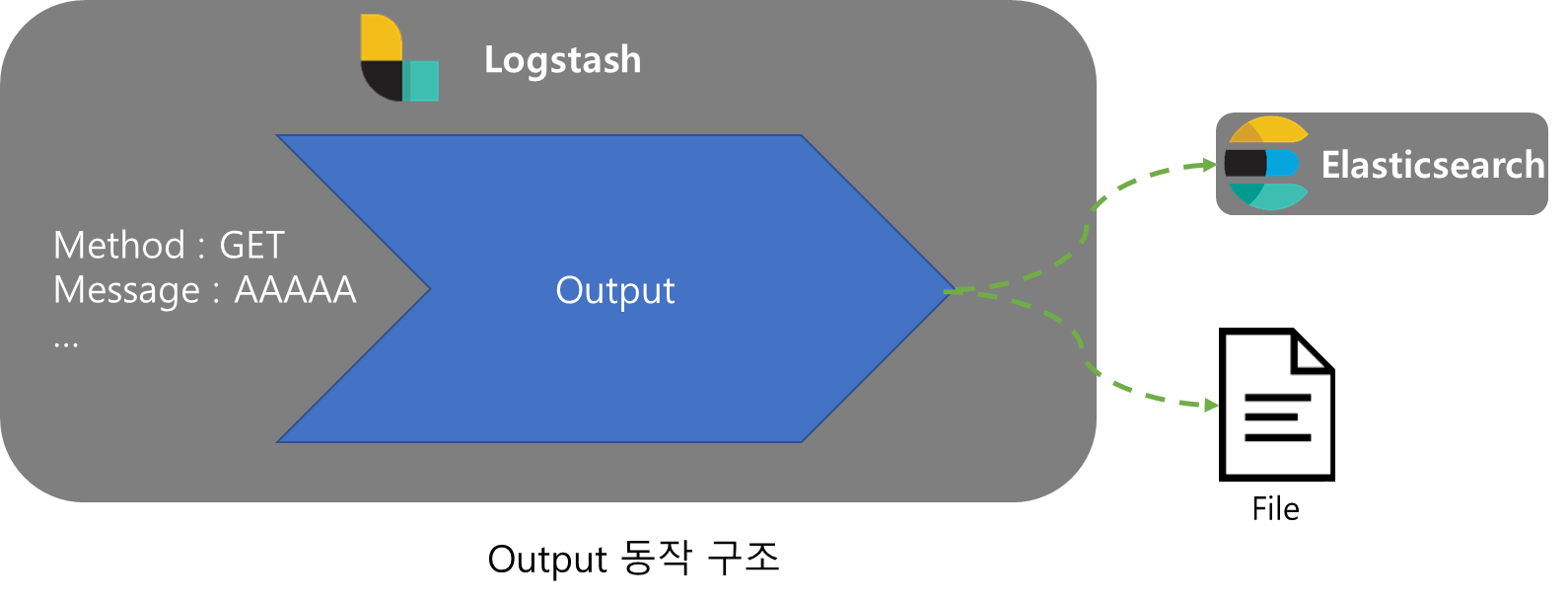
Output
Filtering된 데이터를 출력하는 작업을 실행하며 여러기자 plugin으로 동시에 다양한 타겟으로 출력이 가능하다.
2.Logstash.conf
Logstash는 Logstash.conf 파일로 pipeline을 설정한다.
Input
input은 다음과 같은 형태로 설정한다.
input {
beats {
port => 5044
}
tcp {
port => 50000
}
}각각의 plugin별로 port를 지정해줄 수 있으며 기본적인 beats, tcp, udp 등과 Redis, s3, JDBC등의 DB를 포함하여 여러가지 input plugin이 탑재되어 있다.
Filter
filter는 다음과 같은 형태로 설정한다.
filter {
if "access" in [tags]{
grok {
match => { "message" => "%{TIMESTAMP_ISO8601:logstamptime}%{DATA:traceid} %{GREEDYDATA:body}" }
remove_field => ["@version","@score","message","log.file.path"]
}
if [traceid] == "[traceId=]" {
drop{ }
}
grok {
match => { "body" => "%{WORD:debuglevel} %{DATA:javaclass} - HTTP/%{NUMBER:http_event_nm} %{URIPATH:uri_addr_nm} %{WORD:mth_evnt_nm} %{IPV4:dert_ip_nm} %{NUMBER:dert_port_nm} %{DATA:dert_pamt_nm} %{TIMESTAMP_ISO8601:req_str_dtm} %{IPV4:arvl_ip_nm} %{NUMBER:arvl_port_nm} %{TIMESTAMP_ISO8601:req_end_dtm} %{GREEDYDATA:response}" }
remove_field => ["traceid","body","javaclass"]
}
json {
source => "response"
remove_field => "response"
}
json {
source => "dert_pamt_nm"
remove_field => ["dert_pamt_nm","password"]
}
}
if "dbCRUD" in [tags]{
grok{
match => { "message" => "%{BASE10NUM:id}\s*,\s*%{BASE10NUM:prod_nm}\s*,\s*%{DATA:matnr_no}\s*,\s*%{BASE10NUM:plant_no}\s*,\s*%{WORD:proc_tp_cd}\s*,\s*%{TIMESTAMP_ISO8601:sysm_reg_dtm}\s*,\s*%{WORD:sys_upid_nm}\s*,\s*%{TIMESTAMP_ISO8601:sysm_updt_dtm}"}
}
}
}filter에서는 특정 데이터를 기준으로 if문을 사용하여 분류하고 각각을 여러 filter를 통해 데이터를 정제하여 이해하기 쉬운 데이터를 만들어 낼 수 있다. beat나 타겟 프로그램(Spring)등에서 log 설정시 tags를 남겨 if문을 이용하면 쉽게 해당 기능을 사용할 수 있다.
문자열 1개로 들어온 데이터는 grok plugin을 이용하여 데이터 타입에 맞게 분리하고 key값을 지정할 수 있으며 json 형태의 데이터는 json plugin으로 쉽게 데이터를 정제할 수 있다.
해당 plugin외에도 다양한 plugin이 있으며 plugin은 따로 정리하도록 하겠다.
grok plugin참고 사이트
grok debugger http://grokdebug.herokuapp.com/
grok patterns https://github.com/elastic/logstash/blob/v1.4.2/patterns/grok-patterns
Output
Output은 다음과 같이 설정한다.
output {
if "access" in [tags]{
elasticsearch {
hosts => "elasticsearch:9200"
user => "elastic"
password => "changeme"
index => "access"
}
}
if "dbCRUD" in [tags]{
elasticsearch {
hosts => "elasticsearch:9200"
user => "elastic"
password => "changeme"
index => "rm"
}
}
elasticsearch {
hosts => ["121.177.207.82:9200"]
user => "elastic"
password => "changeme"
}
}output에서도 filter와 같이 특정 데이터를 기준으로 if문을 사용할 수 있으며 여러 출력이 가능하나 ELK에서 사용하는 elasticsearch plugin을 기본으로 설정하였다.
host로 대상 elasticsearch를 설정하고 인증에 필요한 user와 password는 필수적으로 필요하며
index 설정은 필수적이지는 않으나 설정하지 않을시에 기본 index에 모든 데이터가 저장되므로 설정하는 것이 좋다.
logstash의 output기능을 이용한 elasticsearch 적재는 데이터의 id값이 자동으로 저장되어 id를 이용한 crud에는 부적합하다.
참조
Logstash docs https://www.elastic.co/guide/en/logstash/current/plugins-outputs-file.html
Logstash 동작 구조 설명 https://www.elastic.co/guide/en/logstash/current/pipeline.html
grok debugger http://grokdebug.herokuapp.com/
grok patterns https://github.com/elastic/logstash/blob/v1.4.2/patterns/grok-patterns
