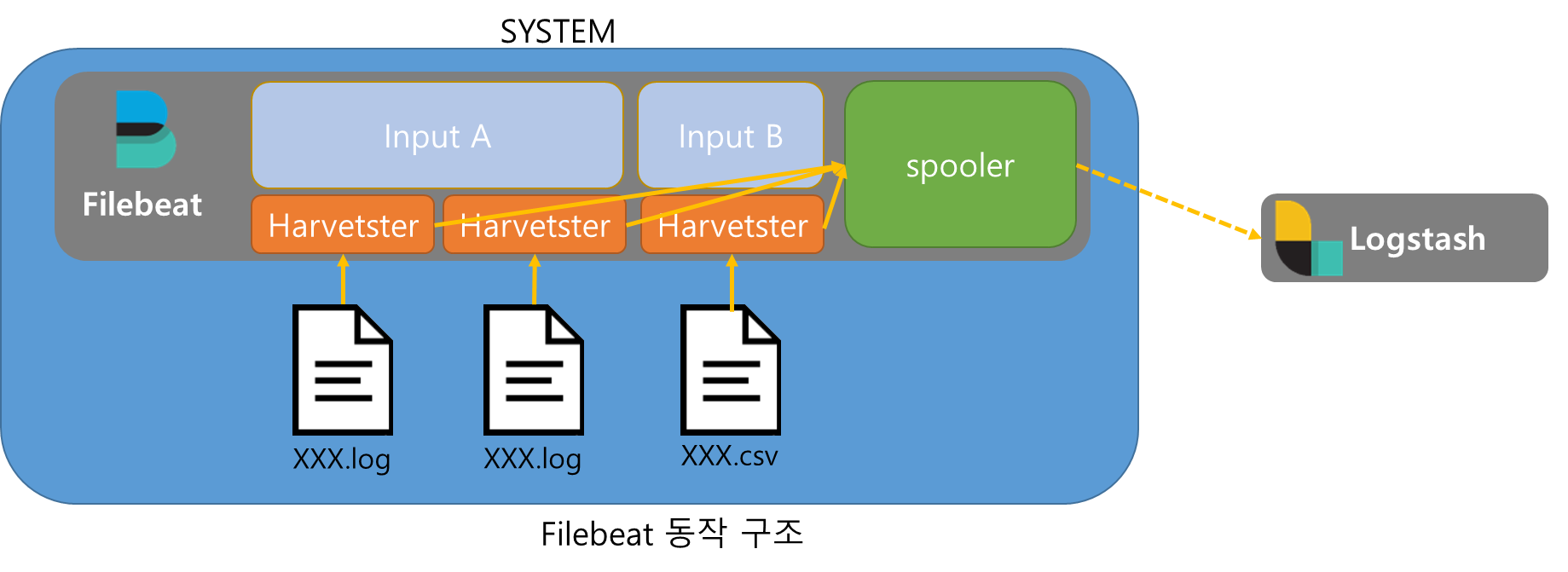
1.FileBeat 구조
Filebeat는 Input, Harvester, Spooler로 구성되어있다.
Harvester가 파일을 읽고 Spooler에 저장하여 Spooler가 지정된 Output(그림에서는 Logstash)에 데이터를 전송한다.
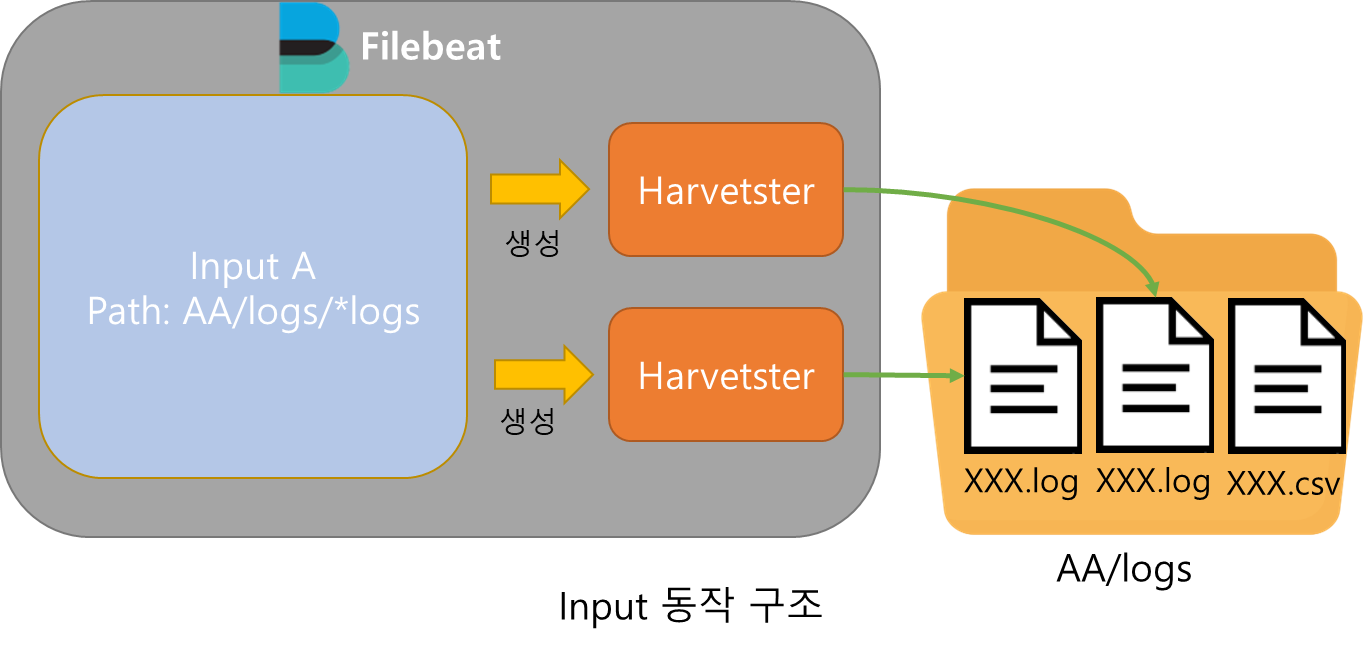
Input
Input은 경로를 입력받아 해당 경로에 존재하는 파일을 식별하고 각각의 파일에 Harvester를 생성하고 관리하는 역할을 맡는다.
한 Filebeat는 여러개의 Input을 가질 수 있으며 각각의 Input은 자신만의 경로를 가진다.
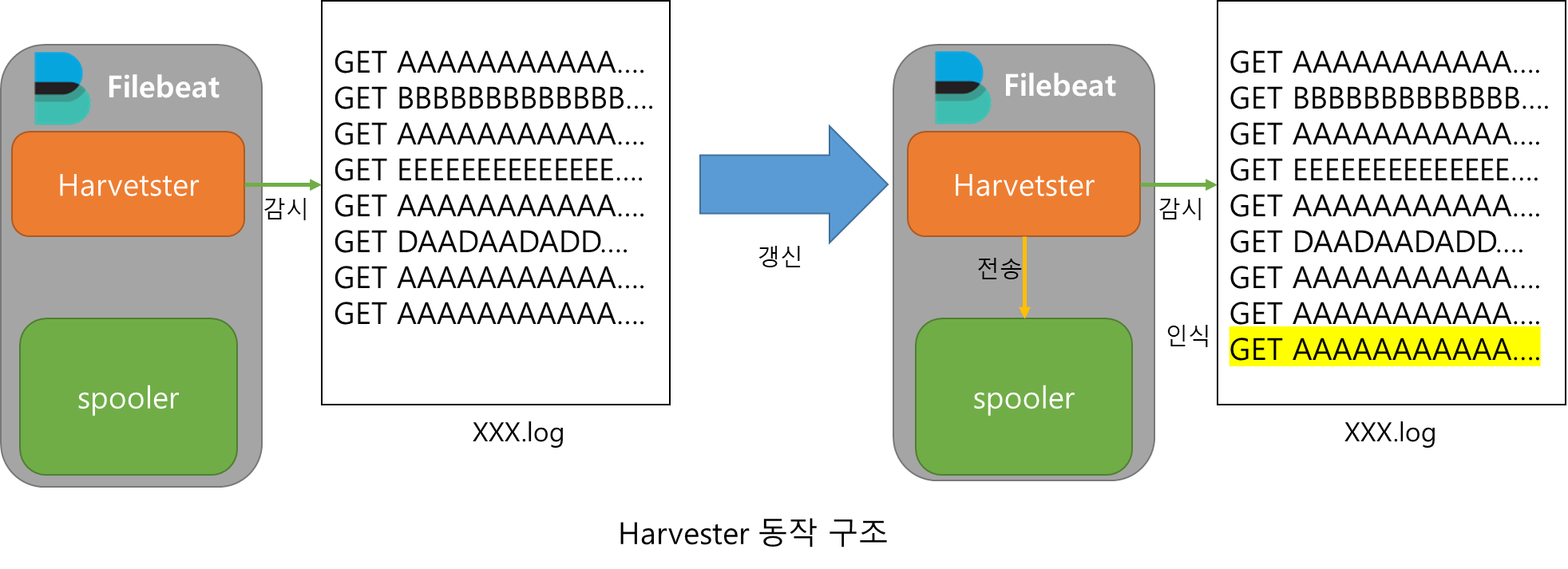
Harvester
Harvester는 자신이 타겟으로하는 파일을 라인별로 읽어들이며 지속적으로 갱신 여부를 확인한다.
파일이 변경되면 이를 인지하고 새로운 데이터를 읽어들여 Spooler에 저장한다.
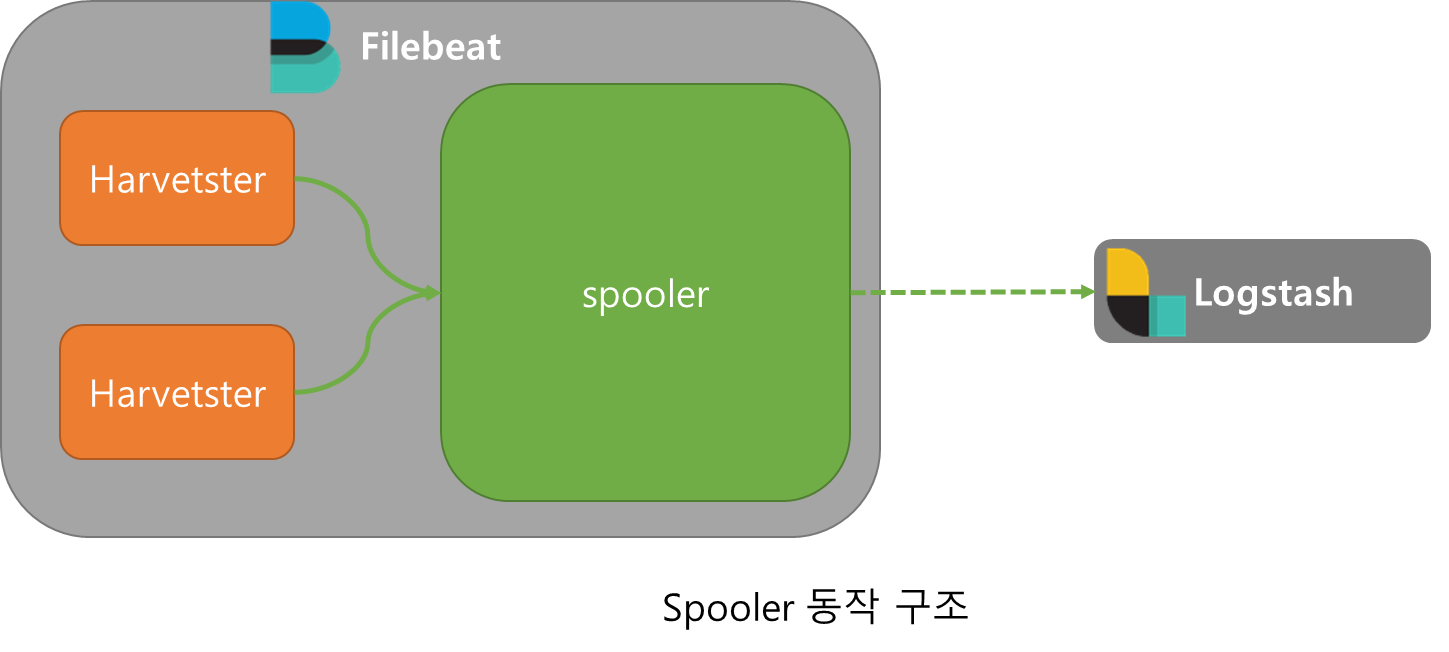
Spooler
Spooler는 데이터를 적재하는 메모리 큐로 저장된 데이터를 타겟 Output으로 출력한다.
2.FileBeat 설정
FileBeat 설정은 FileBeat설치 폴더 내에 Filebeat.yml파일로 설정할 수 있다.
문법이 매우 엄격한 yaml파일이므로 띄어쓰기 개수가 틀리면 에러가 발생한다.
Input
Input은 다음과 같은 형태로 설정한다.
filebeat.inputs:
- type: filestream
id: input_csv
enabled: true
paths:
C:\csvtest\logs\*.csv
tags: ["csv"]
- type: filestream
id: input_log
enabled: true
paths:
C:\logtest\logs\*.log
tags: ["access"]yaml list타입으로 input을 설정하므로 각각의 input은 (-)로 시작한다.
type은 가장 기본적으로 file을 읽어들이는 filesteam외에도 AWS S3, Kafka, Redis, TCP등의 여러가지 input이 존재한다.
각각의 input은 파일 상태를 추적하기 위해 id를 부여받아야한다.
paths는 여러개를 지정할 수 있다.
Tag를 지정해두면 Logstash에서 Tag로 분류가 가능해 데이터 필터링이 쉬워지는 장점이 있다.
Output
output은 다음과 같은 형태로 설정한다
output.logstash:
hosts: ["localhost:5044", "localhost:5045"]
loadbalance: true
output.elasticsearch:
hosts: ["localhost:9200"]편의상 elasticsearch와 logstash 2개의 output을 기술하였으나 output은 1개만 선언 가능하다.
logstash의 필터링은 부하가 크므로 여러 logstash를 사용할 경우 loadbalance 기능을 사용하여 각각의 logstash에 분산하여 전송 가능하다.
hosts도 elasticsearch,logstash외에 Redis, Kafka, File등의 여러 output이 존재한다.
