✅ 객체를 배열로 순회하기
- 자바스크립트는 배열안에 내장 메서드에 좋은 라이브러리가 제공 되고 있습니다.
Object.kets()
- 주어진 객체의 속성 이름을 반복문과 동일한 순서로 순회하여 열거할 수 있는 배열로 반환합니다.
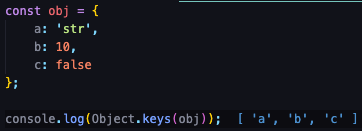
객체의 key가 순서에 맞게 배열로 반환 되었습니다.
Object.values()
- 주어진 객체의 값을 열거할 수 있는 배열로 반환합니다.

객체의 value가 순서에 맞게 배열로 반환 되었습니다.
Object.entries()
- key와 value를 쌍의 배열로 반환합니다.
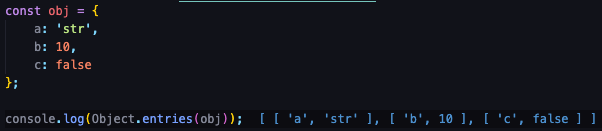
배열 안에 배열이 나열되어 있습니다.(중첩된 배열)
,를 기준으로 나뉘고 있습니다.[key, value], [key, value]
✅ 요소 추가와 제거
배열의 내용을 변경합니다.
원본 배열을 복사하지 못하기 때문에 주의하여야 합니다.
- 추가
- unshift : 배열의 앞에 요소 추가
- push : 배열의 끝에 요소 추가
unshift
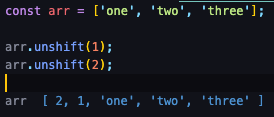
push

- 제거
- shift : 배열의 앞에 요소 제거
- pop : 배열의 끝에 요소 제거
shift
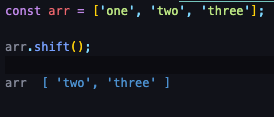
pop

- 인덱스 기반 추가 및 삭제
- splice : 배열의 인덱스 기반으로 요소 추가 및 삭제(몇번부터 몇번까지)
arr.splice(시작 인덱스, 갯수, 추가할 인덱스);splicer 추가
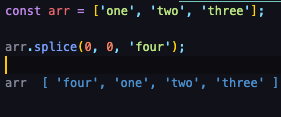
인덱스를 삭제하지 않고 'four'를 추가하였습니다.
splice 삭제
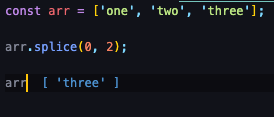
0번 인덱스부터 시작하여 2개의 인덱스를 삭제하여 3번 인덱스만 남았습니다.
중간에 추가하고 싶으면 0번 인덱스가 아닌 1번 인덱스나 2번 인덱스로 바꿔서 사용하면 됩니다.
✅ 요소 병합(배열 합치기)
concat()- 기존 배열과 추가된 배열을 더해서 새 배열을 반환합니다.
- 원본 배열을 해치지 않습니다.
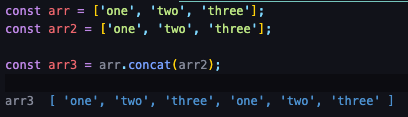
concat()인자로 들어오는 것이 뒤에 붙습니다.
...으로 병합하기
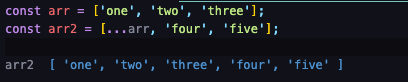
...은 뒤에 붙이면 원본 배열 뒤에 붙습니다.
✅ 고차 함수로 조작하기 (내장 메서드)
-
배열의 내장 메서드는 정말 많지만 고차 함수처럼 활용할 수 있는 메서드를 알아보겠습니다.
-
map- 필수로
return이 필요합니다.- 배열 요소 하나에 접근할 때 마다 실행됩니다.
- 기존 배열을 해치지 않습니다.
- 배열을 새롭게 조작해서 새로운 배열로 반환할 때 사용합니다.
- 필수로

배열 요소마다
function이 실행됩니다. (예제 출력화면 확인)
Function()인자 부분에 요소가 하나 하나 넘어옵니다.
filter()- 자바스크립트 특정 조건에 맞는 배열을 만들 수 있습니다.
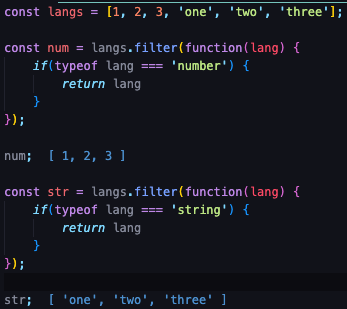
num은 lang의 type이 number일 때, 숫자만 출력하도록 만들었고
str은 lang의 typedl string일 때, 문자열만 출력하도록 만들었습니다.
-
화살표 함수를 이용하여 간결하게 작성할 수 있습니다.

-
reduce- 누적된 값을 다룹니다.

누적된 값을 다루기에 매우 용이합니다.
1.total에1이 들어간 뒤current에2가 들어오고 연산이 된 뒤에,total로 들어갑니다.
2.total에 값3을 가져와서return total에 넣은 뒤,current에3이 들어가고total로 값이 들어갑니다.
3.total에 값6을 가져와서return total에 넣은 뒤,current에4가 들어가고
total로 값이 들어갑니다.
4. 반복
✅ 요소 정렬
-
sort()
- 요소를 정렬할 때 사용합니다.
-
숫자 정렬

a와 b를 계속 비교하여 나열하게 됩니다. 반대로 적으면 역순으로 배열됩니다.
-
문자열 정렬

localeCompare를 이용하여 정렬하였습니다.
localeCompare는 문자열과 문자열을 비교하고, 정렬순서에 따른 비교를 할 수 있습니다.
✅ 값 검색
-
배열에 원하는 값을 찾은 후 출력합니다.
-
find
* 찾는 값이 있으면 출력합니다.

find를 이용하여 값이 있는지 없는지를 알아보았습니다.
result는 숫자 1이 있기 때문에 1을 출력하였고,result2는 6이 없기 때문에 undefined를 출력 하였습니다. -
findIndex
- index 위치 찾기

1의 인덱스 위치는 0이기 때문에 0을 출력하였습니다.
없는 인덱스는 -1을 출력합니다.
(indexOf도 비슷하게 사용이 가능하지만lastIndexOf는 역순으로 찾습니다.)
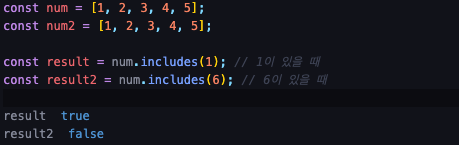
- includes
- find와 비슷하지만 불리언으로 출력합니다.
- 사용법이 매우 간단합니다.
- 최신 문법이라 옛날 브라우저에서는 지원하지 않습니다.