CRS Survey Paper
CRS의 전반적인 동향을 파악하기 위해 해당 Survey Paper를 읽게 되었습니다.
다음과 같은 주요 질문에 초점을 맞추어 공부하였습니다.
- CRS가 기존 추천 시스템과 어떻게 다른가?
- CRS에서 활용되는 주요 기술과 연구 접근법은 무엇인가?
- 현재 CRS의 한계와 앞으로의 연구 방향은 무엇인가?
Abstract
추천 시스템은 정보 과부하 상황에서 사용자가 관심 있는 항목을 찾을 수 있도록 돕는 소프트웨어 애플리케이션입니다.
현재의 연구는 주로 사용자의 과거 관찰된 행동에 기반하여 선호도를 추정하고, 추천 항목의 순위 목록을 제시하는 일방향적인 상호작용 방식을 가정하고 있습니다.
대화형 추천 시스템(CRS)은 이러한 방식과는 다른 접근법을 취하며, 보다 풍부한 형태의 상호작용을 지원합니다.
- 예: 선호도 추출 과정을 개선하거나, 사용자가 추천 항목에 대해 질문하거나 피드백을 제공할 수 있도록 돕는 방식
최근 몇 년간 CRS에 대한 관심이 크게 증가했으며, 이러한 발전은
- 자연어 처리(NLP) 분야의 상당한 진전,
- 음성 제어가 가능한 홈 어시스턴트의 등장,
- 챗봇 기술의 사용 증가에 기인합니다.
본 논문에서는 대화형 추천에 대한 기존 접근법을 상세히 조사하였으며, 이를 여러 차원에서 분류하였습니다.
예: 지원되는 사용자 의도나 배경에서 활용되는 지식의 측면에서 접근 방식을 분석함.
또한, 기술적 접근법을 논의하고 CRS의 평가 방법을 검토하며, 앞으로 더 많은 연구가 필요한 여러 연구 공백을 식별하였습니다.
1. Introduction
추천 시스템은 실용적인 AI 성공 사례 중 하나로 손꼽힙니다.
일반적으로 이러한 시스템의 주요 과제는 사용자가 관심을 가질 만한 잠재적인 항목을 찾도록 돕는 것입니다.
많은 실제 애플리케이션에서 추천은 주로 한 번의 상호작용(one-shot interaction) 과정으로 이루어집니다.
- 예: 시스템이 사용자의 행동을 시간에 따라 모니터링한 후, 사용자가 서비스에 로그인할 때 맞춤형 추천 목록을 제시
하지만 이러한 접근 방식은 편리하긴 하나, 잠재적인 한계가 존재할 수 있습니다.
한계 사례
- 사용자의 과거 상호작용에서 신뢰할 수 있는 선호도 추정이 어려운 경우
- 과거 데이터가 충분하지 않을 수 있음
- 맥락에 따른 추천 항목 선택의 변동
- 사용자의 현재 상황이나 필요가 자동으로 파악되지 않음
- 사용자가 자신의 선호도를 미리 알고 있다는 가정의 불확실성
- 선호도가 대화를 통해 형성될 수 있음
대화형 추천 시스템(CRS)
이러한 문제들을 해결하기 위해 대화형 추천 시스템(CRS)이 제안되었습니다.
CRS의 일반적인 아이디어는 사용자가 다중 턴(multi-turn) 대화를 통해 과업 지향적인 상호작용을 할 수 있도록 지원한다는 것입니다.
본 논문에서는 CRS의 개념적 아키텍처의 주요 구성 요소를 기준으로 문헌을 검토합니다. 구체적으로:
- CRS의 정의와 개념적 아키텍처 (Section 2)
- CRS의 상호작용 방식 (Section 3)
- CRS가 사용하는 지식과 데이터 (Section 4)
- CRS에서 수행해야 할 계산 작업 (Section 5)
- CRS 평가 방법 (Section 6)과 미래 연구 방향
CRS가 기존 추천 시스템의 한계를 해결하는 방법
-
문제: 사용자의 과거 데이터 부족
- 기존 시스템은 과거 데이터를 기반으로 추천하지만, 데이터가 없거나 신제품(고관여 제품) 추천의 경우 신뢰도가 떨어짐
- 해결: CRS는 대화 중에 사용자 선호도를 실시간으로 파악하고 세부적으로 이해
-
문제: 맥락 의존적 추천
- 기존 시스템은 사용자의 현재 상황이나 필요를 제대로 반영하지 못함
- 해결: CRS는 다중 턴 대화를 통해 사용자의 현재 맥락을 이해하고, 이에 맞는 추천 제공
-
문제: 사용자 선호도 형성의 동적 특성
- 사용자는 선호도를 사전에 알지 못하고, 선택 과정에서 이를 형성할 수 있음
- 해결: CRS는 대화를 통해 사용자가 옵션을 학습하도록 돕고, 선호도가 형성되는 과정을 지원
-
문제: 상호작용의 제한성
- 기존 시스템은 정적이고 일방적인 추천 방식을 가짐
- 해결: CRS는 사용자가 피드백을 제공하고 추천에 대해 질문할 수 있는 쌍방향 대화 지원
연구 배경 및 동기
- CRS는 기존 추천 시스템의 한계를 보완
- NLP와 챗봇 기술의 발전은 CRS의 가능성을 한층 높임
- 다중 턴 대화와 사용자 맞춤형 상호작용은 보다 정교한 추천 시스템을 만드는 데 필수적
- 이 논문은 CRS 기술과 동향을 체계적으로 정리하고, 미래 연구를 위한 방향성을 제시
2. Definitions And Research Methodology
2.1 Characterization of Conversational Recommender Systems
CRS(Conversational Recommender Systems):
다중 턴 대화를 통해 사용자들의 추천 관련 목표를 지원하는 과업 지향적(Task-oriented) 소프트웨어 시스템.
주요 특징
- 과업 지향성
- 사용자 의사결정 지원
- 선호도 추출과 설명 제공
- 다중 턴 대화
- 대화의 흐름과 상태를 추적
- 지속적인 상호작용 가능
- 다양한 입력/출력 형식
- 음성, 텍스트, 버튼, 제스처 등 다양한 형태 지원
기존 Q&A 시스템과의 차별점
- 단순 질문-응답(Q&A) 방식이 아닌, 대화 상태 관리를 통해 사용자 의도를 지속적으로 반영
2.2 Conceptual Architecture of a CRS
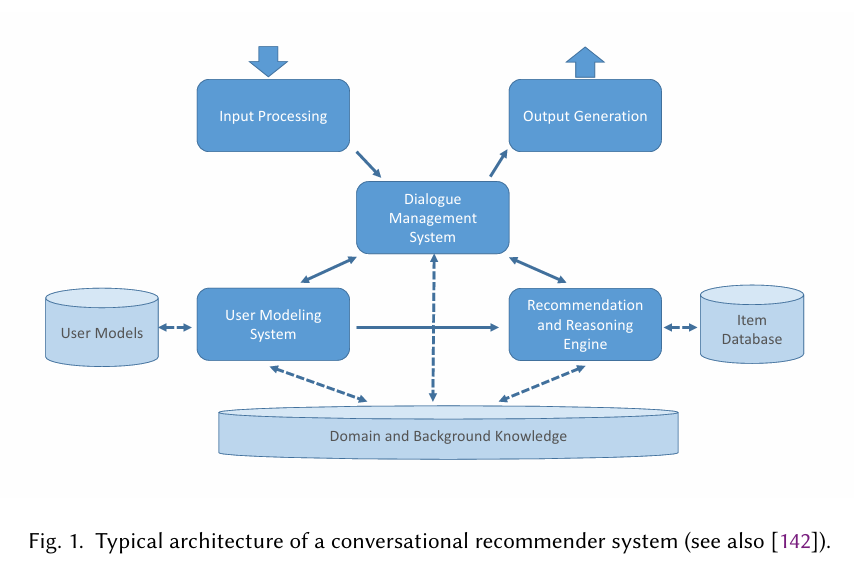
구성 요소
- 대화 관리 시스템 (Dialogue Management System)
- 대화 상태 추적
- 적절한 응답(추천, 질문 등) 생성
- 사용자 모델링 시스템 (User Modeling System)
- 사용자 선호도 모델링
- 장기 및 단기 선호도 반영
- 추천 및 추론 엔진 (Recommendation and Reasoning Engine)
- 대화 상태와 선호도 기반 추천 목록 생성
- 논리적 추론 수행
- 입출력 처리 모듈
- 음성-텍스트 변환, 의도 감지, 엔터티 인식 등
- 지식 요소
- 항목 데이터베이스: 추천 가능한 항목과 속성 정보
- 도메인/배경 지식: 대화 상태, 사용자 의도 및 전환 규칙 등
2.3 Research Method: Identifying Relevant Works
-
논문 선정 과정
- "대화형 추천 시스템", "상호작용 추천" 등 키워드로 디지털 라이브러리 검색
- 적합한 논문 121편 선정 및 분석
-
포함된 논문
- CRS 정의를 충족하며, 다중 턴 대화와 추천 작업을 지원하는 연구
-
제외된 논문
- 단순 Q&A 시스템, 일반 챗봇, 프로필 구축 중심 시스템 등
3. Interaction Modalities Of CRS
최근 대화형 추천 시스템(CRS)에 대한 관심은 NLP의 발전과 스마트폰 및 홈 어시스턴트와 같은 새로운 기술 장치의 등장으로 인해 증가하고 있습니다.
CRS는 사용자와의 상호작용을 자연어 입력과 출력에만 국한하지 않으며, 특정 장치에도 의존하지 않습니다.
3.1 Input and Output Modalities
대부분의 연구 논문에서 CRS는 다음 두 가지 주요 입력 및 출력 형태를 지원합니다:
- Forms and Structured Layouts
- 전통적인 웹 기반(데스크탑) 애플리케이션에서 사용
- Natural Language
- 텍스트 또는 음성 형태
Form-Based Approaches
- 버튼, 라디오 버튼 등 구조화된 텍스트를 기반으로 한 시스템
- 예: 웹 기반 인터랙티브 솔루션
Natural Language-Based Approaches
- 음성 또는 텍스트로만 이루어진 상호작용
- 대표적으로 Alexa, Google Home 등에서 사용
Hybrid Approaches
- 자연어와 다른 형태의 인터페이스를 결합
- 예: 자연어로 대화를 나누면서 시각적으로 결과를 출력
Application-Specific Modalities
- 지리적 맵, 손글씨 입력, 제스처 등 다양한 입력 방법을 지원
3.2 Application Environment
CRS는 다음 두 가지 형태로 구현될 수 있습니다:
- Stand-alone Applications
- 독립 실행형 애플리케이션
- 예: 모바일 관광 가이드, e-commerce 시스템
- Embedded Applications
- 다른 시스템에 통합된 형태
- 예: 전자상거래 플랫폼의 챗봇
3.3 Interaction Initiative
CRS의 설계에서 중요한 질문은 대화의 주도권을 누가 가지는가입니다:
- System-Driven
- 시스템이 대화의 주도권을 가지며 사용자로부터 정보를 수집
- User-Driven
- 사용자가 질문하고 시스템이 응답
- Mixed-Initiative
- 사용자와 시스템이 대화를 주고받으며 상호 작용
3.4 Discussion
CRS 설계에서 고려해야 할 요소들:
- 자연어 기반 인터페이스는 직관적이지만 사용성에 한계가 있음
- 시스템이 사용자 선호도를 더 잘 반영하기 위해 대화의 유연성을 조정할 필요
- 미래에는 더 많은 디바이스와 환경에서 CRS가 활용될 것으로 기대됨
4. Underlying Knowlegde And Data
4.1 User Intents
사용자가 대화에서 표현하는 의도를 어떻게 파악하고, 그에 맞춰 어떤 데이터(아이템 DB, 대화 로그, 외부 지식)를 활용할지 논의함.
사용자는 대화 과정에서 선호를 전달(Provide Preferences)하거나, 이유를 묻고(Obtain Explanation), 추천을 수락(Accept Recommendation) 또는 종료(Quit) 등 다양한 의도를 나타낼 수 있다는 점이 CRS 설계의 핵심이다.

-
주요 의도 유형
- 추천 요청 (“영화 추천해 줘”)
- 선호 전달 (“공포영화 좋아해”)
- 피드백 (“이건 별로다”) 등
-
데이터 연계
- 대화 데이터: 사용자의 ‘직접’ 표현(장르, 가격대 등)을 실시간으로 저장·분석하여 아이템 DB 검색에 활용
- 외부 지식: 사용자가 언급한 엔티티(감독, 지역, 브랜드 등)와 연결해 더 풍부한 추천 (“이 감독의 다른 작품도?”)
도메인 지식 활용 및 추천 개선
- 사용자의 의도를 파악할 때, 도메인 특화 지식(예: 여행 도메인에서는 “국내/해외,” “날씨,” “계절” 등)을 통해
- 대화 이해 정확도 ↑
- 사용자 요구 사항을 더 구체적으로 반영
- 예시: “나는 채식을 좋아해” → 음식점 DB에서 “채식 옵션” 속성이 있는 레스토랑을 우선 추천
4.2 User Modeling
CRS가 사용자 프로필, 선호도, 맥락 등을 반영하기 위해 어떤 데이터를 어떻게 축적·활용하는지 설명함.
-
아이템 데이터베이스
- 사용자 과거 평점·클릭 로그 + 메타데이터(장르, 가격, 지역 등)와 매칭
- 장점: 선호 아이템 속성 기반의 정교한 필터링 가능
- 도메인 지식: 항공권, 여행지, 식당 등 각 도메인에 특화된 속성(지역별 인기도, 메뉴, 교통 편의 등)
-
대화 데이터
- 대화 중 사용자 발화(질문, 감상, 제약 조건)를 통해 실시간 선호도 추론
- 장·단기 선호를 함께 고려(해당 세션 vs. 누적 기록)
-
외부 지식
- 지식 그래프(Wikidata, WordNet 등) 또는 도메인 DB(맛집/호텔 정보, 제품 스펙 등)를 참조해
- “비슷한 장르”나 “관련 엔티티” 추천 가능 → 개인화의 폭을 넓힘
도메인 지식 활용 및 추천 개선
- 속성 매핑(장르-영화, 도시-여행지 등)으로 사용자 발화 해석 정확도↑
- 과거 대화(또는 행동 로그)와 결합하여, “이전엔 코미디 좋아했지만 이번엔 다큐 찾음” 같은 맥락 변화도 즉시 반영
- 결과적으로, 사용자 맞춤형 추천의 품질이 높아짐
4.3 Dialogue States
대화가 진행되는 ‘상태’를 정의하고, 어떤 데이터(대화·아이템·외부 지식)를 어느 시점에 활용할지 결정하는 구조.
-
상태 설계
1) 선호 파악 상태 → 2) 추천 제안 상태 → 3) 피드백 상태 → 4) 종료/재시작 등- 각 상태 전환에 필요한 사용자 발화 정보와 도메인 지식을 규칙 또는 모델로 관리
-
데이터 활용
- 대화 데이터: “지금 대화 맥락에서 사용자 요구가 더 구체화됐는가?” 판단
- 아이템 DB: 추천 후보 목록 필터링(속성 일치 여부 등)
- 외부 지식: “사용자가 갑자기 감독이나 작가 정보를 묻는다면?” → 관련 지식 베이스 조회
도메인 지식 활용 및 추천 개선
- 사용자 취향뿐 아니라, 관련 엔티티·속성들을 대화 중간중간 제시하여 대화 흐름을 풍부하게 만듦
- 강화학습(RL) 기반 접근 시, 최적 정책 학습에 외부 지식을 활용해 의미론적 연결 고려
- 예) “이 배우 출연작 중 평점 높은 다른 영화를 먼저 추천”
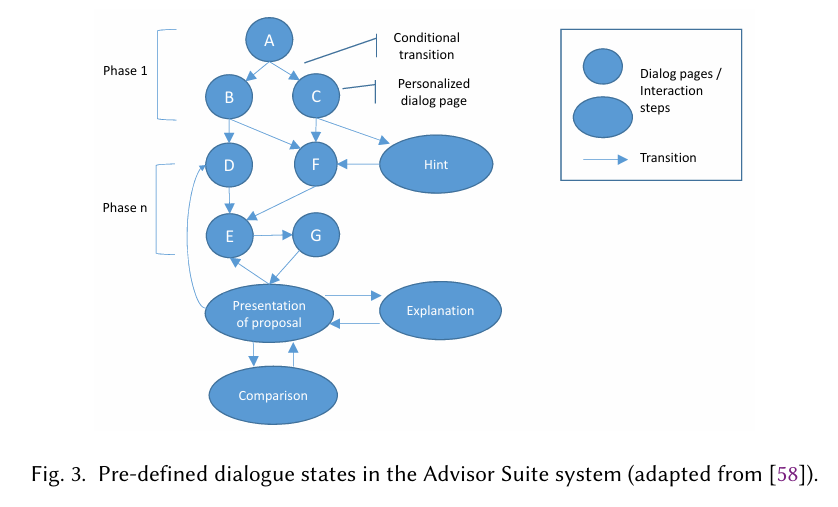
Advisor Suite라는 추천 프레임워크에서 직관적인 그래픽 편집 도구로 대화 흐름(상태 기획)을 구성한 예시
- 각 알파벳 A to G는 대화에서 특정 기능을 수행하는 상태를 의미합니다.
- 예: 사용자의 선호를 구제척으로 묻는 상태(A,B,C 등), 혹은 힌트를 제공하는 상태, 여러 아이템을 비교하는 상태, 최종적으로 추천을 제시하는 상태 등이 존재합니다.
- 전이는 “사용자가 어떤 답변을 했느냐” 또는 “현재까지 파악된 선호가 충분한가” 같은 조건들에 의해 결정됩니다.
4.4 Background Knowledge
CRS가 활용하는 배경 지식(Background Knowledge) 전반을 설명.
아이템 DB, 대화 코퍼스, 외부 지식베이스 등이 포함됨.
-
Item Database
- 영화, 도서, 음식점, 제품 등 대상 영역별로 정제된 구조적 DB
- 평점·장르·가격·지역 등 속성을 빠르게 조회해 후보 추천 가능
-
Dialogue Corpora
- 대화 텍스트(사용자-시스템 간 실제 발화 데이터)
- 사용자 선호 추론, 의도 분류 모델, 대화 전략(어떤 순서로 질문?) 학습에 사용
-
External Knowledge
- 지식 그래프(Wikidata, Freebase 등) 또는 도메인 DB(트립어드바이저, 메뉴 DB, 가격비교 사이트 등)
- 사용자 질문에 대한 추가 정보나 설명 근거 제시(“이 작품은 수상 경력이 있음”, “평균 평점 4.5점”)
- 연관 추천: “이 지역 명물, 이 작가의 다른 책” 등
도메인 지식 활용 및 추천 개선
- 풍부한 설명(Explainability): 단순히 아이템만 던지지 않고 “왜 추천하는지” 맥락 설명
- 사용자 유도: “요즘 인기 있는 이 장르도 혹시 관심 있으신가요?” 등 새로운 발화 유도 → 대화 자연스러움↑
- 추천 정확도: 도메인 속성(날씨, 시즌, 유형 등)을 세밀하게 고려해 맞춤형 제안 가능
4.5 Discussion
전체적으로 CRS가 어떤 데이터를 기반으로, 어떻게 도메인 지식을 통합해 추천 품질을 높일지 종합적으로 논의.
-
데이터 간 연계
- 아이템 DB + 대화 데이터 + 외부 지식이 상호 보완적으로 결합
- 예) 사용자 발화를 통해 특정 속성을 파악 → 아이템 DB에서 후보군 필터링 → 외부 지식으로 세부 정보 조회
-
도메인 지식의 가치
- 추천 다양성·설명 가능성·대화 유연성을 높임
- 도메인별 특수 속성을 반영해, 단순 필터링보다 훨씬 정교한 추천 제공
-
한계와 과제
- 공개 대화 데이터나 도메인 지식베이스가 부족한 영역에선 데이터 수집 자체가 어려움
- 지식 그래프나 외부 DB가 커질수록, 엔티티 추출 및 정합성을 유지하는 복잡도가 상승
5. Computational Tasks
5.1 Main Tasks
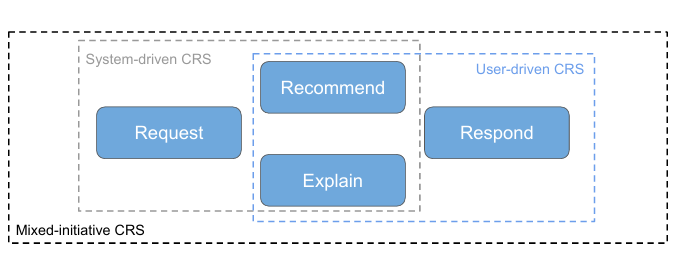
CRS(대화형 추천시스템)는 대체로 4가지 핵심 액션을 수행합니다:
- Request (사용자 정보 요청)
- Recommend (추천 수행)
- Explain (추천 이유 설명)
- Respond (사용자 발화에 응답)
Request: 사용자에게 속성/선호를 직접 물어보는 단계. 어떤 질문을 언제 할지 전략(규칙, RL 등)이 중요
Recommend: 본격 추천 생성. 기존 CF·콘텐츠 기반·하이브리드부터 딥러닝·강화학습 방식까지 다양
Explain: 추천 결과의 배경/근거를 설명하여 사용자 신뢰·이해도 제고. 템플릿, 그래프 탐색 등 활용
Respond: 사용자 발화 중 다른 형태(질문, 재시작, 오해 등)에 적절히 응답. 템플릿/규칙 기반 vs. 학습 기반(Seq2Seq 등) 접근이 있음. 대화 붕괴(conversational breakdown) 상황을 위한 대처(재요청·clarification 등) 전략도 필요
결론적으로, CRS에서 이 4가지 태스크(Request, Recommend, Explain, Respond)는 대화 흐름 전반을 구성하는 핵심 기능이며, 각각을 어떻게 구현·조합하느냐가 시스템 품질과 사용자 만족도에 큰 영향을 미칩니다.
5.2 Supporting Tasks
CRS가 사용자 의도를 정확히 이해하기 위한 Natural Language Understanding(Intent Detection, NER, Sentiment Analysis 등)와 특정 기능(Query Suggestion, Relaxation, Tightening 등)을 소개.
5.3 Discussion
다양한 알고리즘과 플랫폼을 적용할 수 있으나, 대화형 설명 기능이나 동적 대화 관리 등에는 아직 개선 여지가 큼을 지적.
전반적으로 챗봇 기술(NLU, 대화 관리)과 추천 알고리즘이 결합되는 형태로 발전 중이나, CRS 전용 연구와 인프라는 더 활성화될 여지가 많다는 점이 강조됩니다.
6. Evaluation Of Conversational Recommenders
CRS 평가 포인트
- 전통적 추천 지표(정확도, 다양성 등)뿐 아니라, 대화 품질(유창성, 이해도), 사용성(직관성, 신뢰도, 노력도) 등이 핵심
- 대화형 특성으로 인해 인터랙션(상호작용) 효율(턴 수, 소요 시간 등)과 사용자 경험(설명 이해도, 대화 흥미 등)이 중요
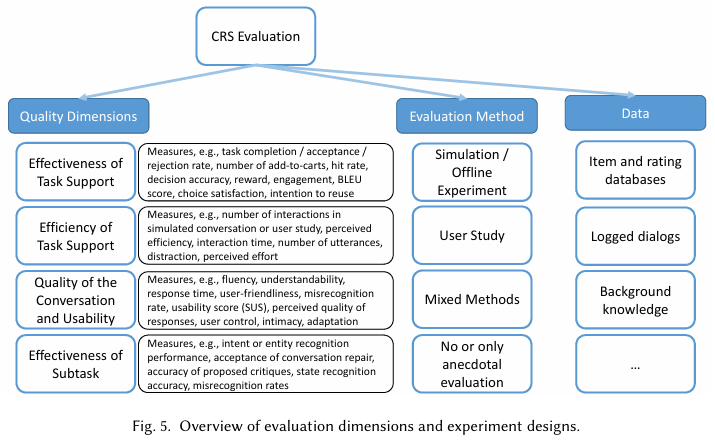
평가 방법
-
오프라인 실험/시뮬레이션
- 사용자 선호나 행동을 가상으로 재현해 대규모·반복 평가 가능
- 단, 실제 사용자의 선호 변화 등 현실 맥락 반영이 어려움
-
사용자 연구(유저 스터디)
- 실제 사용자가 시스템을 써 보고 주관적 만족도, 효율성 등을 조사
- 현실성↑, 하지만 실험 비용과 시간 소요↑
-
현실 배포(A/B 테스트)
- 실제 서비스 환경에서 매출, 클릭, 참여도 등 KPI 비교
- 가장 실제적이나, 구현·운영 부담과 자료 수집 한계 존재
-
혼합 접근
- 오프라인 실험 + 사용자 연구 병행 등
주요 평가 지표
- 효과성(Effectiveness)
- 추천 성능(정확도·성공률·사용자 만족도)
- 효율성(Efficiency)
- 대화 횟수·반응 시간 등으로 업무 달성 속도 평가
- 대화 품질 & 사용성
- BLEU 등 언어 평가 지표, 설문(유창성, 적절성, 이해도 등), 사용자 경험(인지부하·통제감 등)
- 부분 작업 성능
- 의도 인식률, 엔티티 추출 정확도 등
한계 및 향후 과제
- 자동 언어 평가(BLEU 등)와 실제 사용자 인식 간 불일치 → 주관적 평가 병행 필요
- 시뮬레이션 기반 실험은 사용자 취향이 대화 중 바뀔 수 있음을 완벽히 반영하기 어려움
- 대화형 설명 기능이나 사회적 대화 패턴(토론, 협상 등)을 더 심층 연구할 필요가 있음
해당 Survey Paper를 읽은 후, 질문에 대한 답변해보기
- CRS가 기존 추천 시스템과 어떻게 다른가?
- 1-1. 대화형 상호작용
전통적 추천 시스템은 사용자 행동 로그(클릭, 평가 등)나 프로필을 기반으로 비동기적으로 추천을 제공하는 반면, CRS는 실시간 대화를 통해 사용자의 선호와 의도를 직접 파악하고 즉각적인 피드백을 받으면서 추천을 조정합니다.- 1-2. 사용자 의도와 맥락 파악
CRS에서는 Chit-chat, 질문·응답(Q&A), 선호 수정 등 다양한 사용자 의도(Intent) 에 대응해야 하므로, 사용자와의 멀티턴(Multi-turn) 대화 흐름을 추적·관리하는 Dialogue Management가 중요해집니다.- 1-3. 핵심 평가 지표
기존 추천은 주로 정확도(Accuracy) 에 초점을 뒀다면,
CRS는 대화 효율성(턴 수·시간), 친화도(Chit-chat), 신뢰도(설명 가능성) 같은 상호작용 품질 또한 핵심 평가 지표가 됩니다.
- CRS에서 활용되는 주요 기술과 연구 접근법은 무엇인가?
- 2-1.대화 관리 & 사용자 모델링
- Finite State Machine 기반: 상태 전이 규칙을 사전에 정의 (ex. Fig 3)
- 강화학습(RL) 기반: 대화 정책(policy)을 학습해 “다음 질문”이나 “추천 제안”을 동적으로 결정
- 사용자 모델링은 단기·장기 선호, 아이템 속성, 외부 지식을 결합해 개인화 정확도를 높이는 핵심- 2-2. 언어처리(NLP) 기술
- 의도 분류(Intent Detection), 개체 인식(NER), 감정 분석(Sentiment Analysis) 등을 통해 사용자 발화 이해
- 시퀀스-투-시퀀스(Seq2Seq), Transformer, RNN 등을 사용해 시스템 응답(문장) 생성
- 엔티티·속성 정보를 지식 그래프(예: Wikidata)와 연결해 풍부한 정보 제공- 2-3. 추천 알고리즘
- 전통적 CF, 콘텐츠 기반, 지식 기반 기법을 대화 맥락에 맞춰 적용
- Critiquing 기법: 사용자에게 “더 저렴한 옵션” 같은 구체적 속성 조정을 허용
- 딥러닝·하이브리드 접근: 임베딩 기반 모델(MLP, RBM, Attention 네트워크 등)을 대화 정보와 결합- 2-4. 설명 가능성
- 템플릿 기반 또는 그래프 탐색(배우·감독·장르 관계 등)으로 추천 이유를 문장이나 태그로 제시할 수 있음
- 사용자 만족·신뢰도를 높이는 중요한 요소이나, 아직 연구가 많지 않음
- 현재 CRS의 한계와 앞으로의 연구 방향은 무엇인가?
- 3-1. 표준화·공개 데이터 부족
- 실제 대화 데이터셋이 제한적이며, 각 연구마다 독자적으로 수집한 데이터셋을 사용하고 있음 → 재현성(Reproducibility) 떨어짐- 3-2. 품질 평가의 어려움
- 아직 표준화된 평가 프레임워크가 없어 연구자마다 다양한 메트릭과 실험 방법을 도입하고 있음.
- 개인적으로는, 대화를 통해 수시로 변화하는 사용자의 의도에 맞는 추천을 하기 위해서는 표준화된 평가 프레임워크가 존재하기 힘들다고 생각함.- 3-3. 설명 기능 및 투명성 강화
- 대화형 추천에서 왜 이런 추천이 나왔는지 사용자 친화적으로 풀어내는 연구가 아직 초기 단계- 3-4. 확장성과 유지보수
- 유지비용이 크고, 대규모 학습 자원이 필요하므로 확장성과 유지보수에 관한 연구도 필요
