<논문 리뷰> Large Language Models are Zero-Shot Rankers for Recommender Systems (ECIR 2024)
논문 리뷰
본 논문은 대형 언어 모델(LLMs, Large Language Models)이 추천 시스템의 제로샷 랭킹(zero-shot ranking) 모델로 얼마나 효과적인지 탐구합니다. 전통적인 추천 시스템과 달리, LLM은 별도의 데이터 학습 없이도 사용자 상호작용 이력을 기반으로 후보 아이템을 순위화할 수 있는 가능성을 보여줍니다.
zero-shot : 해당 도메인이나 아이템에 대해 학습 데이터가 전혀 없는 상태
Abstract
최근 대규모 언어 모델(LLMs, 예: GPT-4)은 추천 작업을 포함하여 다양한 범용 작업을 해결할 수 있는 뛰어난 잠재력을 보여주고 있습니다. 본 연구는 추천 시스템의 랭킹 모델로서 대규모 언어 모델의 역량을 조사하는 것을 목표로 합니다.
이를 위해, 순차적 상호작용 이력을 조건으로 하고, 후보 생성 모델에 의해 검색된 아이템을 후보로 간주하여 추천 문제를 조건부 랭킹 작업으로 공식화하였습니다. 이후, 순차적 상호작용 이력, 후보 아이템, 랭킹 명령어를 포함하는 프롬프트 템플릿을 신중히 설계하여, LLM을 활용한 랭킹 과제를 해결하는 특정 프롬프트 접근 방식을 제안합니다.
실험 결과, LLM은 기존 추천 모델과 동등하거나 더 나은 제로샷 랭킹 능력을 보유하고 있음을 입증했습니다. 또한, LLM이 과거 상호작용의 순서를 인식하는 데 어려움을 겪고, 위치 편향과 같은 문제에 영향을 받을 수 있지만, 이를 완화하기 위해 특별히 설계된 프롬프트와 부트스트랩 전략이 효과적임을 확인했습니다.
prompt template : LLM에 입력되는 자연어 형태의 질문, 설명, 명령 등을 구조화된 형식으로 설계한 틀
bootstrap strategy : 모델 학습이나 평가의 편향을 줄이고 안정성을 높이기 위해 사용하는 전략
1. Introduction
대부분의 기존 모델은 특정 도메인 또는 작업 시나리오의 사용자 행동 데이터로 학습되며, 두 가지 주요 문제를 가지고 있습니다.
- limited expressive power : 기존 모델은 주로 클릭한 상품 시퀀스와 같은 과거 상호작용 행동에서 사용자 선호도를 포착하기 때문에 실제 사용자 선호도를 명시적으로 이해하기 어렵고, 복잡한 사용자 관심사를 모델링하는 데 표현력이 제한적이다.
- narrow experts : 이러한 모델은 배경 지식이나 상식적인 지식에 의존하는 복잡한 추천 작업을 해결하는 데 있어서 지식이 부족하다.
이에 따라, 추천 성능과 상호작용을 개선하기 위해 사전 학습된 언어 모델을 사용하려는 노력이 증가하고 있습니다. 이러한 모델은 자연어로부터 사용자의 선호도를 명시적으로 포착하거나 텍스트 코퍼스로부터 풍부한 배경지식을 이용하여 새로운 도메인이나 상황에서도 유용한 추천을 생성하게 합니다.
본 논문에서는 보다 상세한 실증 연구를 통해 추천 모델 역할을 하는 LLM의 역량을 살펴보고자 합니다.
전반적으로, 우리는 다음과 같은 핵심 질문에 답하려고 시도합니다:
- LLM의 제로샷 랭킹 성능에 영향을 미치는 요인은 무엇인가?
- LLM이 추천 작업에서 의존하는 데이터나 지식은 무엇인가?
결과적으로, 추천 시스템의 강력한 랭킹 모델로서 LLM을 개발하는 방법에 대해 몇 가지 중요한 발견을 제시합니다.
- LLM은 주어진 순차적 상호작용 이력의 순서를 인식하는 데 어려움을 겪습니다.
- 하지만, 특정하게 설계된 프롬프트를 사용하면 LLM이 순서를 인식하도록 유도할 수 있으며, 이는 랭킹 성능을 향상시킵니다.- LLM은 랭킹 시 위치 편향(position bias)과 인기 편향(popularity bias)을 겪습니다.
- 그러나 부트스트래핑 또는 특별히 설계된 프롬프트 전략을 통해 이러한 편향을 완화할 수 있습니다.
2. General Framework for LLMs as Rankers
LLM의 추천 능력을 조사하기 위해 먼저 추천 프로세스를 조건부 랭킹 작업으로 공식화합니다. 다음으로 추천 작업을 해결하기 위해 LLM을 적용하는 일반적인 프레임워크를 설명합니다.
2.1 Problem Formulation
한 사용자의 과거 상호작용 (상호작용 시간 순서대로)가 "조건"으로 주어졌을 때, 관심 있는 상품이 더 높은 순위에 오를 수 있도록 후보 상품 의 순위를 매기는 것이 과제입니다.
실제로, 후보 상품은 일반적으로 전체 상품 집합 () 에서 후보 생성 모델에 의해 검색됩니다. 또한, 각 상품 는 설명 텍스트 와 연관되어 있다고 가정합니다.
2.2 Ranking with LLMs Using Natural Language Instructions
먼저 각 사용자에 대해 순차적인 상호작용 이력 (조건)과 검색된 후보 상품 (후보)를 각각 포함하는 두 개의 자연어 패턴을 구성합니다.
그런 다음, 이러한 패턴을 최종 명령어로 자연어 템플릿 에 채웁니다. 이러한 방식으로 LLM은 명령어를 이해하고 명령어가 제시하는 대로 순위 결과를 출력합니다. 다음은 접근 방식의 세부적인 명령어 설계에 대해 설명합니다.
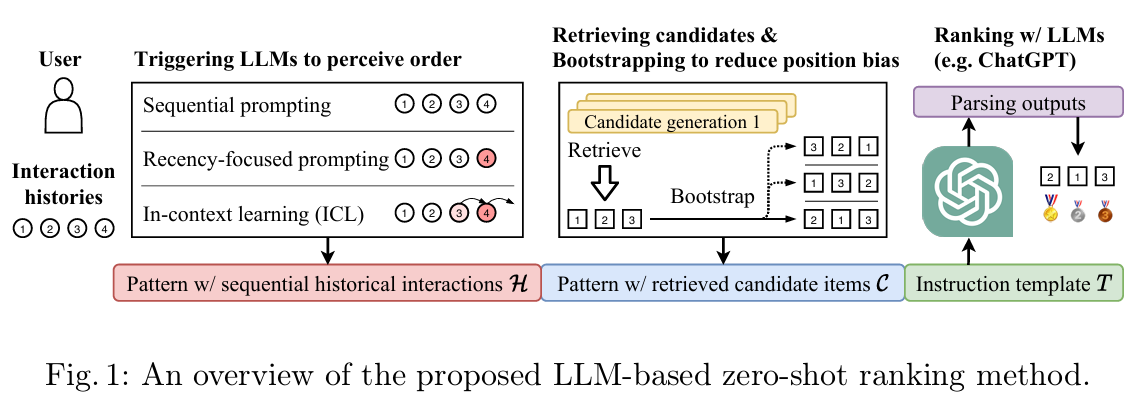
Sequential historical interactions (순차적 과거 상호작용)
LLM이 과거 사용자 행동에서 사용자 선호도를 파악할 수 있는지 알아보기 위해, 순차적 과거 상호작용 를 LLM의 입력으로 명령에 포함시킵니다.
LLM이 과거 상호작용의 순차적 특성을 인식할 수 있도록 하기 위해 세 가지 방법으로 명령을 구성할 것을 제안합니다:
-
순차적 프롬프트 (Sequential Prompting)
- 과거 상호작용을 시간 순서대로 정렬합니다.
- 예:
"나는 과거에 다음과 같은 영화를 순서대로 시청했습니다: '0. 멀티플리시티', '1. 쥬라기 공원', ..."
-
최근 중심 프롬프트 (Recency-focused Prompting)
- 순차적인 상호작용 기록에 더해 가장 최근의 상호작용을 강조하는 문장을 추가할 수 있습니다.
- 예:
"나는 과거에 다음과 같은 영화를 순서대로 시청했습니다: '0. 멀티플리시티', '1. 쥬라기 공원', ... 가장 최근에 본 영화는 죽은 대통령입니다."
-
상황 내 학습 (In-Context Learning, ICL)
- In-Context Learning은 LLM이 다양한 작업을 풀기 위한 대표적인 프롬프트 방식으로, 프롬프트에 데모 예시를 포함하여 LLM이 특정 작업을 해결하도록 지시합니다.
- 예:
"내가 과거에 다음 영화를 순서대로 본 적이 있다면: '0. 멀티플리시티', '1. 쥬라기 공원', ... 순으로 본 적이 있다면, 죽은 대통령을 추천해야 하고, 이제 내가 죽은 대통령을 봤으니 ..."
Retrieved candidate items (검색된 후보 상품)
일반적으로 순위를 매길 후보 상품은 여러 후보 생성 모델에 의해 먼저 검색됩니다.
LLM으로 이러한 후보 상품의 순위를 매기기 위해 후보 상품 를 순차적으로 정렬하기도 합니다.
- 예:
"이제 다음에 볼 수 있는 후보 영화는 20개입니다: '0. 시스터 액트', '1. 선셋 블러바드', ..."
논문에서는 상대적으로 작은 후보 풀을 고려하며, 순위를 매기기 위해 20개의 후보 상품(즉, )을 유지합니다.
프롬프트에서 후보 상품의 순서를 다르게 생성하여, LLM의 순위 결과가 후보 배열 순서(위치 편향)에 영향을 받는지 여부를 검토합니다.
Ranking with large language models (대규모 언어 모델로 순위 매기기)
기존 연구에 따르면, LLM은 자연어 명령어를 따라 제로 샷 환경에서 다양한 작업을 해결할 수 있습니다.
LLM을 랭킹 모델로 사용하기 위해 최종적으로 위에서 언급한 패턴을 명령 템플릿 에 통합합니다.
- 명령 템플릿의 예:
"[순차적인 과거 상호작용을 포함하는 패턴 H] [검색된 후보 상품을 포함하는 패턴 C] 나의 시청 이력에 따라 이 영화들의 순위를 매겨주세요."
Parsing the output of LLMs (대규모 언어 모델의 출력 파싱하기)
LLM이 자연어로 생성한 텍스트를 후보 아이템과 비교하여 정확하고 구조화된 추천 결과를 생성합니다.
효율적인 문자열 매칭 알고리즘(KMP)을 활용해 빠르고 정확하게 후보를 매칭합니다.
후보 리스트 외 아이템을 처리하여 결과의 신뢰성과 정확성을 높입니다.

- ML-1M 데이터셋은 영화 추천에 특화되어 있으며, 사용자와 아이템 간의 상호작용이 상대적으로 많고 희소성이 낮아 더 밀집된 데이터를 제공합니다.
- Games 데이터셋은 게임 추천에 특화되어 있으며, 사용자와 아이템 간의 상호작용이 상대적으로 적고 희소성이 높아 희박한 데이터를 나타냅니다.
- ML-1M과 Games 데이터셋의 특성을 비교함으로써, 제안된 모델이 희소한 데이터(Games)와 밀도 높은 데이터(ML-1M) 모두에서 잘 작동하는지 평가할 수 있습니다.
3. Empirical Studies
-
사용된 데이터셋:
- MovieLens-1M (ML-1M):
- 영화 평점 데이터셋.
- 사용자 평점을 상호작용(interaction)으로 간주.
- Amazon Review Games:
- 아마존 리뷰 데이터셋의 "Games" 카테고리.
- 리뷰를 상호작용으로 간주.
- MovieLens-1M (ML-1M):
-
데이터 전처리:
- 5개 미만의 상호작용이 있는 사용자 및 아이템은 필터링.
- 각 사용자의 상호작용을 시간순 정렬(가장 오래된 상호작용이 먼저).
- 영화/상품 제목을 아이템의 설명 텍스트로 사용:
- 이유:
- LLM의 내재적 세계 지식을 기반으로 추천할 수 있는지 평가.
- 계산 자원 절약.
- 더 많은 텍스트 특징 활용은 향후 연구 과제.
- 이유:
Evaluation and Implementation Details
-
평가 방법:
- 기존 연구를 따라 Leave-One-Out 전략 사용:
- 마지막 상호작용 → 테스트 세트의 정답(Ground-Truth).
- 마지막 이전 상호작용 → 검증 세트(validation set)에서 사용.
- 기존 연구를 따라 Leave-One-Out 전략 사용:
-
랭킹 성능 평가:
- NDCG@K (Normalized Discounted Cumulative Gain, N@K) 메트릭 사용.
- 후보군의 개수 내에서 인 순위를 평가.
-
구현 세부사항:
- RecBole 라이브러리를 사용해 실험 수행.
- 상호작용 시퀀스는 최대 길이 50으로 잘라서(truncated) 사용.
- ML-1M 데이터셋에서는 모든 사용자 평가.
- Games 데이터셋에서는 랜덤으로 6,000명의 사용자 샘플링.
-
LLM 설정:
- OpenAI API의 gpt-3.5-turbo를 사용.
- Hyperparameter:
- Temperature: 0.2.
- 모든 결과는 최소 3번 반복 실행의 평균으로 보고하여 랜덤성의 영향을 줄임.
3.1 Can LLMs Understand Prompts that Involve Sequential Historical User Behaviors?
본 연구에서는 과거 사용자 행동을 프롬프트로 인코딩하여 추천을 위해 특별히 훈련되지 않은 대규모 언어 모델에 입력합니다.
LLM은 주어진 과거 사용자 행동의 순서를 이해할 수 있는가?
1. 실험 설정
- 후보군 구성:
- 총 20개의 아이템:
- 1개의 정답 아이템(ground-truth item).
- 19개의 무작위 음성 데이터(negative samples).
- 총 20개의 아이템:
- 목표:
- 과거 행동 데이터를 분석하여 관심 있는 아이템이 더 높은 순위에 배치되도록 함.
2. 비교 대상
-
Ours:
- 순차적 프롬프트(sequential prompting) 사용.
-
Random Order:
- 과거 사용자 행동 데이터를 모델에 입력하기 전에 무작위로 섞음.
-
Fake History:
- 원래의 행동 데이터를 무작위로 샘플링된 가짜 아이템으로 교체.
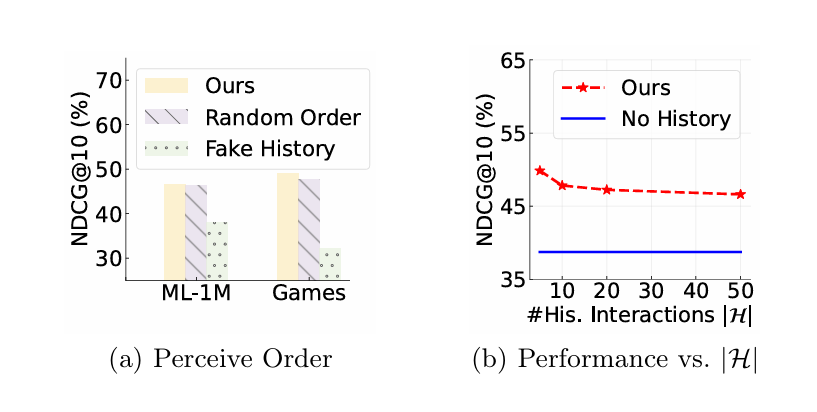
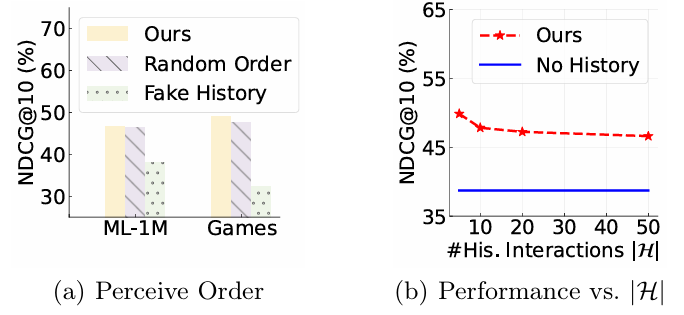
3. 결과 분석
(a): 모델 간 성능 비교
- Ours:
- 가짜 행동 데이터를 사용하는 변형(Fake History)보다 더 나은 성능을 보임.
- 그러나 Ours와 Random Order의 성능은 유사:
- 이는 LLM이 과거 사용자 행동의 순서에 민감하지 않음을 나타냄.
(b): 행동 데이터 수와 성능 간의 관계
- 프롬프트에 포함된 최신 행동 데이터의 수 를 5에서 50까지 변화시킴.
- 결과:
- 행동 데이터 수가 많아져도 성능이 향상되지 않음.
- 너무 많은 데이터는 성능 저하를 초래.
위의 관찰에 따르면, 기본적인 프롬프트 전략으로는 LLM이 상호작용 이력에서 순서를 인식하기 어려움을 발견했습니다.
이에 따라, 최근 상호작용된 아이템을 강조하고, LLM의 순서 인식 능력을 이끌어내기 위해 두 가지 대안적인 프롬프트 전략을 제안했습니다.
랜덤으로 검색된 후보군에서의 성능 비교
1. 열의 구성
-
Method:
- 사용된 추천 모델(또는 방법).
- full: 대상 데이터셋에서 학습된 모델.
- zero-shot: 대상 데이터셋에서 학습되지 않고, 사전 학습(pre-trained)된 모델.
-
Metric (NDCG@K):
- : 추천 순위의 정확도를 평가하는 메트릭.
- : 추천 리스트에서 상위 개 아이템의 성능을 측정.
-
Dataset:
- ML-1M: 영화 추천 데이터셋.
- Games: 게임 추천 데이터셋.
2. 행의 구성
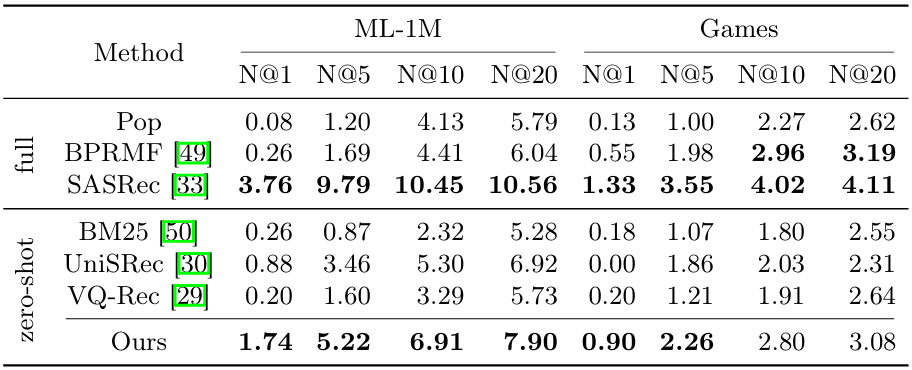
- Full 모델
- Pop: 단순히 인기 있는 아이템을 추천하는 모델.
- BPRMF: Bayesian Personalized Ranking Matrix Factorization.
- SASRec: Self-Attentive Sequential Recommendation.
- Zero-Shot 모델
- BM25: 텍스트 기반 검색 알고리즘.
- UniSRec: Pre-trained universal sequential recommender.
- VQ-Rec: Vector Quantization-based recommender.
- LLM 기반 모델:
- Sequential: 순차적 프롬프트 사용.
- Recency-Focused: 최근 중심 프롬프트 사용.
- In-Context Learning: 상황 내 학습을 활용한 프롬프트.
3. 결과 분석
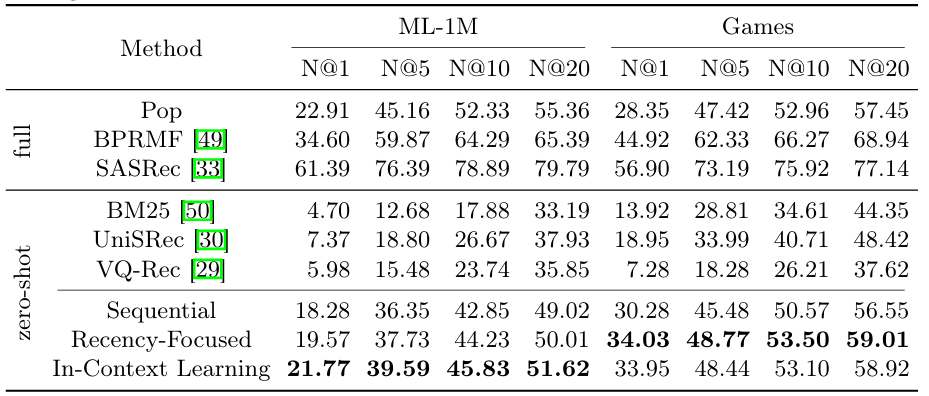
Full 모델
- SASRec:
- 모든 에서 가장 높은 성능 기록.
- 이는 full 모델이 데이터셋에 대해 학습된 경우 강력한 성능을 발휘함을 보여줌.
- Pop과 BPRMF:
- SASRec보다 낮은 성능을 보임.
Zero-Shot 모델
-
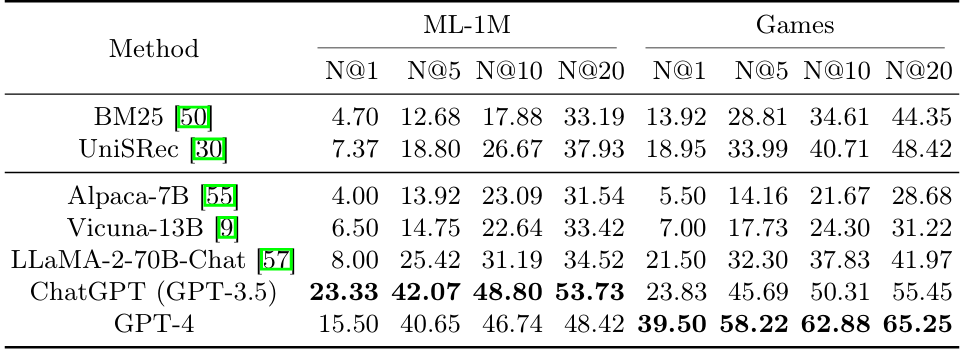
LLM 기반 방법 (Sequential, Recency-Focused, In-Context Learning):
- In-Context Learning 이 ML-1M에서 가장 높은 성능을 기록:
- ML-1M:
- , , , .
- ML-1M:
- Recency-Focused 가 Games에서 모두 가장 높은 성능을 기록:
- Games:
- , , , .
- Games:
- 이는 위 두 프롬프트 전략이 제로샷 환경에서 효과적으로 작동함을 보여줌.
- In-Context Learning 이 ML-1M에서 가장 높은 성능을 기록:
-
BM25, UniSRec, VQ-Rec:
- LLM 기반 방법보다 전반적으로 낮은 성능을 기록.
4. 해석
Full 모델 vs Zero-Shot 모델
- Full 모델 (SASRec):
- 데이터셋에 대해 학습된 경우, Zero-Shot 모델보다 우수한 성능을 보임.
- Zero-Shot 모델 (LLM 기반):
- Recency-Focused, In-Context Learning은 학습되지 않은 상태에서도 꽤 우수한 성능을 발휘.
Observation 1 :
LLM은 주어진 순차적 상호작용 이력에서 순서를 인식하는 데 어려움을 겪습니다.
특별히 설계된 프롬프트(Recency-Focused, In-Context Learning)를 사용함으로써, LLM이 과거 사용자 행동의 순서를 인식하도록 유도할 수 있으며, 이는 개선된 랭킹 성능으로 이어집니다.
3.2 Do LLMs suffer from biases while ranking?
이 섹션에서는 LLM 기반 추천 모델이 겪을 수 있는 두 가지 편향, 즉 위치 편향과 인기 편향에 대해 설명합니다. 또한 이러한 편향을 완화하는 방법에 대해서도 논의합니다.
LLM이 랭킹에서 편향을 겪는가?
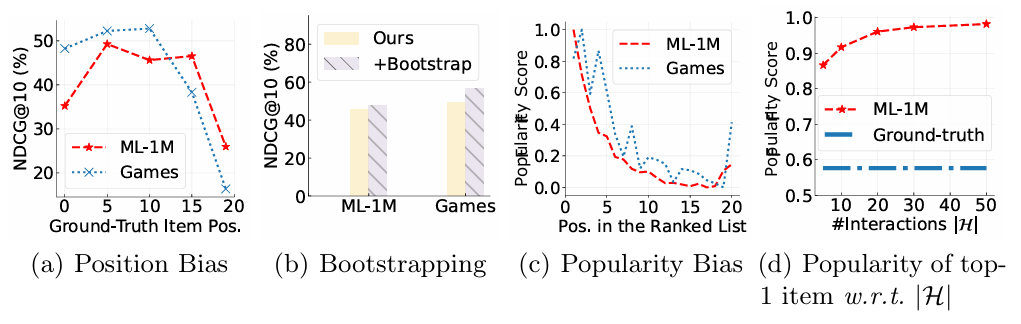
Fig.3: Biases and debiasing methods in the ranking of LLMs.
실험 개요
- 목표:
- LLM 기반 추천 모델이 위치 편향(Position Bias) 및 인기 편향(Popularity Bias)에 영향을 받는지 확인.
- 이러한 편향을 완화하기 위한 전략을 제안.
Fig.3 (a): 위치 편향 (Position Bias)
- 실험 설정:
- 정답 아이템(ground-truth)을 프롬프트에서 위치를 달리하여 평가.
- 위치: {0, 5, 10, 15, 19}.
- 결과:
- 정답 아이템이 리스트의 마지막에 위치할수록 성능(랭킹 정확도)이 크게 하락.
- 이는 LLM이 후반부 아이템에 덜 민감함을 의미.
- 해석:
- LLM 기반 랭커는 위치 편향(Position Bias)을 겪음.
- 기존 추천 모델과는 다른 성격의 편향이 존재.
Fig.3 (b): 부트스트래핑으로 위치 편향 완화
- 전략:
- 부트스트래핑: 후보 아이템을 반복적으로 무작위 섞은 후 결과를 병합하여 최종 랭킹 생성.
- 결과:
- 부트스트래핑 적용 시 모든 데이터셋에서 성능 향상.
- 이는 위치 편향을 완화하는 데 효과적임을 보여줌.
Fig.3 (c): 인기 편향 (Popularity Bias)
- 실험 설정:
- 아이템의 인기도를 정규화된 빈도로 측정하여 랭킹의 각 위치에서 평가.
- 결과:
- LLM은 인기 아이템을 상위에 배치하는 경향.
- 특히 ML-1M과 Games 데이터셋 모두에서 동일한 패턴 관찰.
- 해석:
- LLM은 학습 데이터에서 인기 있는 아이템의 텍스트 빈도를 학습하며, 이를 추천에 반영.
Fig.3 (d): 상호작용 이력을 활용하여 인기 편향 완화
- 전략:
- 프롬프트에서 상호작용 수 를 조정.
- 최신 데이터에 초점을 맞춰 과거 행동을 활용.
- 결과:
- 가 감소할수록 인기 편향이 감소.
- 최신 상호작용 데이터를 활용하면, 인기 아이템보다 개인화된 추천이 강화됨.
Zero-shot ranking performance comparison (설명 생략)
Observation 2 :
LLM은 랭킹에서 위치 편향(Position Bias) 및 인기 편향(Popularity Bias)을 겪습니다.
이러한 편향은 부트스트래핑(Bootstrapping)과 특별히 설계된 프롬프트 전략과 같은 방법으로 완화 가능합니다.
3.3 How Well Can LLMs Rank Candidates in a Zero-Shot Setting?
이 섹션에서는 제로 샷 설정에서 LLM이 후보 상품의 순위를 얼마나 잘 매길 수 있는지 파악합니다.
먼저 벤치마킹 실험을 통해 기존 추천 모델, 기존 제로샷 추천 방법, 제안한 LLM 기반 방법 등 무작위 후보에 대한 다양한 방법 간의 순위 지정 성능을 비교합니다. 다음으로, 다양한 전략에 의해 검색된 하드 네거티브가 있는 후보에 대해 LLM 기반 방법을 평가하여 LLM의 순위가 무엇에 따라 달라지는지 자세히 살펴봅니다.
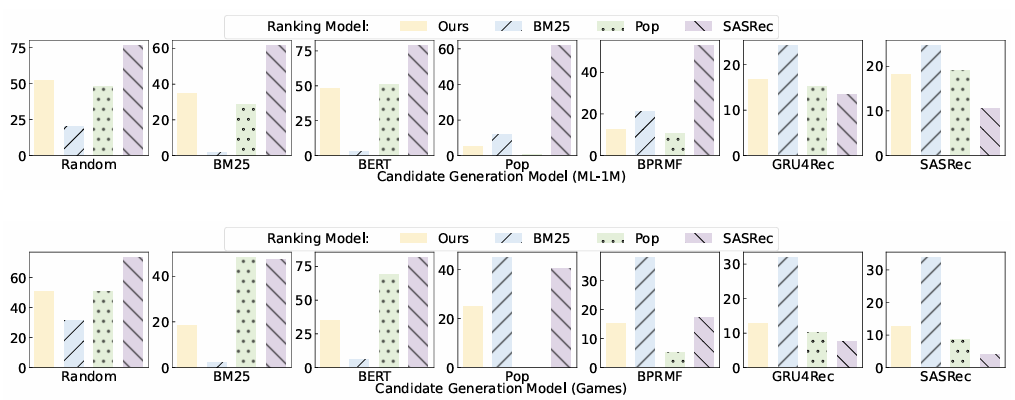
Fig.4: Ranking performance measured by NDCG@10 (%) on hard negatives.
Table 4: Performance comparison on candidates retrieved by multiple candidate
generation models.
실험 설정
- 다양한 후보 생성 모델에서 생성된 하드 네거티브(hard negatives)를 포함한 후보군에 대해 LLM 기반 모델(Ours)의 성능을 평가.
- hard negative: 사용자가 관심을 가진 항목과 비슷하지만, 실제로는 사용자가 좋아하지 않을 가능성이 높은 항목.
- LLM이 주어진 후보의 순위를 매기는 방법을 더 자세히 조사하기 위해, 다양한 후보 생성 방법으로 검색된 후보에 대한 LLM의 순위 성능을 평가합니다. 이러한 후보들은 실사 상품에 대한 하드 네거티브로 볼 수 있으며, 특정 상품 범주에 대한 LLM의 순위 지정 능력을 측정하는 데 사용할 수 있습니다.
- (1) BM25 및 BERT 와 같은 콘텐츠 기반 방법은 과거에 상호 작용한 상품과 후보 간의 텍스트 특징 유사성을 기반으로 후보를 검색하고,
- (2) Pop, BPRMF, GRU4Rec, SASRec 를 포함한 상호작용 기반 방법은 사용자-상품 상호 작용에 대해 학습된 기존 추천 모델을 사용하여 상품을 검색합니다. 후보가 주어지면 LLM 기반 모델(Ours)과 대표적인 콘텐츠 기반(BM25) 및 상호 작용 기반(Pop 및 SASRec) 방법의 순위 성능을 비교합니다.
결과
-
ML-1M 데이터세트
- 인기 상품(예: Pop, BPRMF)이 포함된 후보 세트에서는 LLM 기반 방법이 높은 순위를 차지하지 못함.
-
Games 데이터세트
- 인기 상품 후보와 텍스트 유사 후보 모두에서 유사한 순위 성능을 보임.
- 이는 상품 인기도와 텍스트 특징이 LLM 기반 순위에 비슷하게 기여한다는 것을 보여줌.
-
하드 네거티브의 영향
- 두 데이터세트 모두에서 상호작용 기반 후보 생성 방법(예: SASRec)에 의해 검색된 하드 네거티브의 영향을 받음.
- 그러나 LLM 기반 방법은 SASRec과 같은 순전히 상호작용 기반 모델보다 하드 네거티브에 덜 민감함.
결론
- LLM의 강점:
- 다양한 후보 생성 모델에서 안정적으로 높은 성능을 기록.
- 하드 네거티브가 포함된 복잡한 후보군에서도 인기도, 텍스트 특징, 사용자 행동을 종합적으로 고려하여 순위를 매김.
- 제로샷 환경에서의 가능성:
- Ours 모델은 대상 데이터셋에 대해 학습된 모델(SASRec)과 비슷하거나 우수한 성능을 보임.
- ML-1M과 같은 데이터셋에서는 LLM의 내재적 세계 지식이 영화 간의 유사성을 측정하고 추천하는 데 유용.
- 기존 모델과의 차이:
- 기존 모델은 특정 측면(예: 인기도 또는 텍스트 특징)에 의존하지만, LLM은 다양한 정보와 사용자 행동을 통합적으로 활용.
Observation 3:
LLM은 다양한 후보 생성 모델에서 검색된 후보들에 대해 제로샷 랭킹 능력을 가지고 있으며, 특히 실제 환경에서 여러 전략을 조합한 설정에서도 강력한 성능을 발휘합니다.
5. Conclusion
본 연구는 추천 시스템의 제로샷 랭킹 모델로서 LLM의 역량을 조사하였습니다.
자연어 프롬프트를 구성하여 LLM이 과거 상호작용, 후보 아이템, 명령 템플릿을 활용하도록 설계하였고,
프롬프트 전략과 부트스트래핑을 사용해 LLM의 위치 편향(position bias)과 인기 편향(popularity bias) 문제를 완화 하였습니다.
-
주요 발견 :
- 순차적 상호작용 순서를 더 잘 인식하도록 개선 가능함
- 위치 및 인기 편향을 완화할 방법 제시
-
향후 연구 방향 :
- 효율적으로 튜닝할 수 있는 LLM 기반 추천 모델 개발
6. Limitations
-
실험에서는 ChatGPT를 주요 LLM으로 사용
- 폐쇄형 상용 서비스로, 내부적으로 성능을 향상시키는 추가 기술 통합 가능성 존재
-
오픈소스 LLM(예: LLaMA 2, Mistral)과 비교 시 성능 격차 확인 가능
=> 이 격차로 인해 오픈소스 모델만으로는 LLM의 능력을 충분히 평가하기 어려움 -
특정 프롬프트와 데이터셋으로 인한 편향 가능성 존재
내가 생각한 향후 연구 방향
-
실시간 데이터와 내재된 지식의 융합
-
현재 논문에서는 사전 학습된 지식을 활용해 제로샷 환경에서 추천을 제공합니다. 그러나 실시간 데이터를 결합하면 더 나은 성능과 적응력을 확보할 수 있을 것입니다.
-
실시간 사용자 행동 데이터를 추가 반영하는 LLM 모델의 프롬프트 설계가 앞으로의 주요 연구주제가 될 것이라고 생각합니다. (오프라인 학습된 지식과 실시간 데이터를 동적으로 결합하는 방법론 개발)
-
-
LLM이 제로샷 환경에서 발생하는 편향(인기 편향, 위치 편향)을 완화하기 위해 부트스트래핑 이외의 추가적인 debiasing 방법이 존재할 것이라 생각합니다.
-
제로샷 랭킹 성능의 한계 탐구
- LLM이 의존하는 데이터나 지식의 성격을 파악할 수 있다면, 제로샷 환경에서 어떤 요인이 모델 성능을 제한하거나 강화하는지 이해할 수 있습니다. 이는 제로샷 환경 뿐만 아니라 CRS 전반적으로 활용될 수 있는 연구라고 생각합니다.
논문을 읽으며 든 생각들
본 논문에서는 LLM이 상호작용의 순서를 인식하지 못하는 문제를 해결하기 위해 프롬프트 양식을 조정한다거나, 편향을 줄이기 위해 부트스트래핑을 사용하는 등 여러 효율적인 방안들을 고안하였습니다.
하지만 개인적으로 제로샷 환경에서 성능을 향상시켰다는 점보다는 논문의 실험 결과와 같이 해당 도메인의 데이터로 학습된 모델이 성능이 우수하다는 점에서 "제로샷 환경에서의 추천 성능 향상이 유의미한 연구일까?" 하는 생각이 논문을 읽으며 지속되었습니다.
따라서 해당 연구가 어떤 의미를 갖는지를 더 자세히 찾아보았는데, 이전에 읽었던 Survey Paper에서와 같이 CRS는 양질의 학습 데이터 확보가 어려울 뿐만 아니라 대규모 데이터를 LLM에 학습시키는 것 또한 많은 비용이 든다는 점에서, 사전 학습된 LLM을 적절한 프롬프트 양식과 편향을 줄이는 방식을 통해 추가 학습 없이 추천 모델로 사용할 수 있다는 점에서 유의미 하다는 것을 깨달았습니다.
또한 다양한 도메인 지식을 내재하고 있기에, 폭넓은 추천 시스템으로서 활용될 수 있고, 사용자 데이터 수집 및 저장이 불가능한 환경에서 우수한 성능을 보일 수 있다는 점을 알게 되었습니다.
연구의 목적을 단순 성능 개선이 아니라 사전 학습된 지식의 활용 가능성 측면에서 바라본다면, 내재된 지식을 통해 문제를 해결할 수 있는 능력을 확장한다는 관점에서 유의미한 결과를 도출하였다고 생각합니다.
