
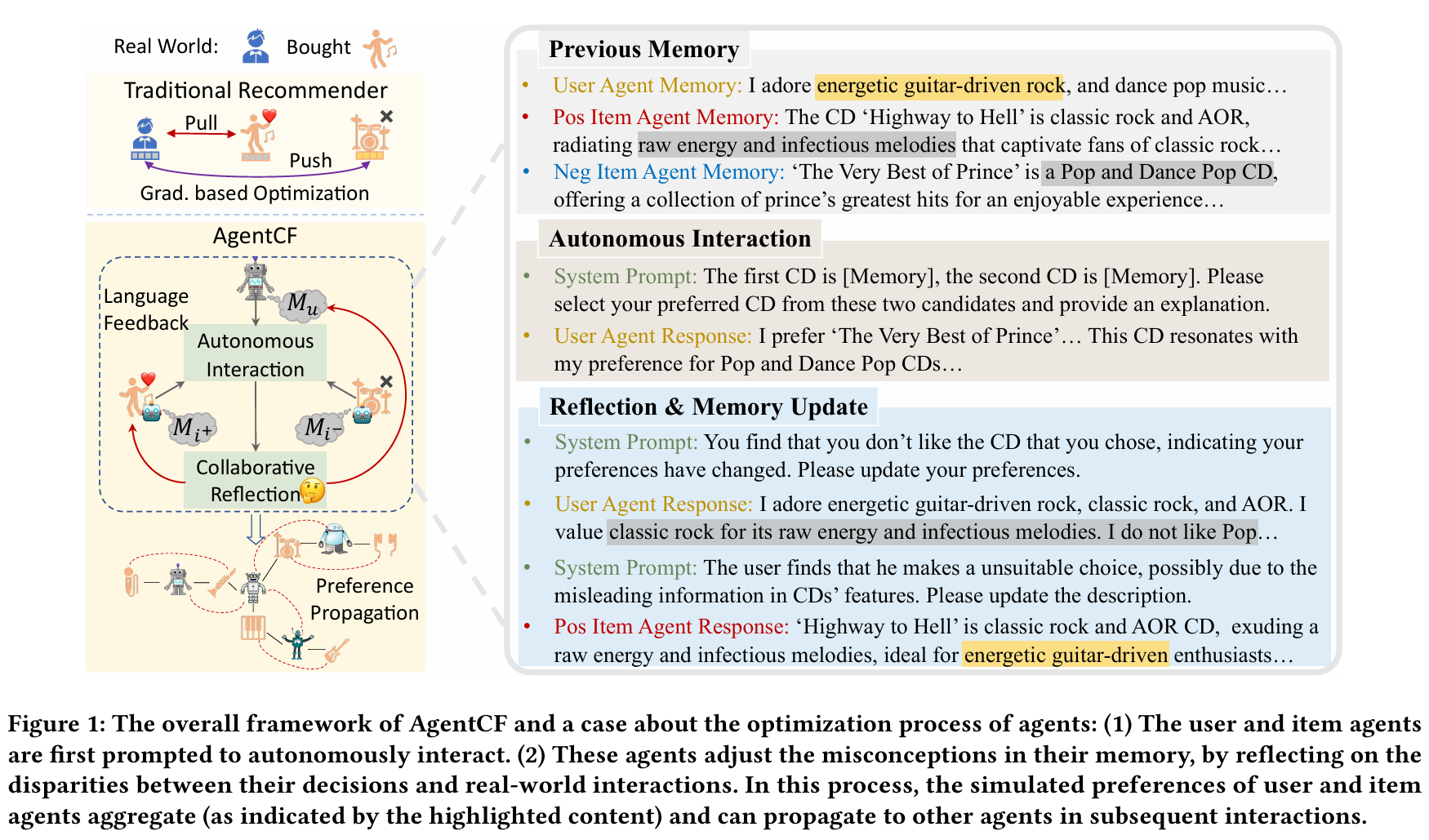
Overview of AgentCF
AgentCF는 사용자 구매 이력을 기반으로 사용자/아이템을 각각 에이전트로 생성하고, 각자의 메모리를 초기화합니다. 학습 과정에서는 pairwise 방식으로 positive/negative item을 제공하며, user agent는 이 중 하나를 선택하고 선택 이유를 생성합니다. 실제 상호작용 기록과 비교하여 잘못된 선택 시 user/item agent가 자율적으로 reflection을 통해 메모리를 업데이트합니다. 이 과정을 반복하면서 에이전트는 점점 현실 사용자와 아이템의 특성을 더 잘 반영하게 됩니다.
Abstract
AgentCF는 추천 시스템의 사용자–아이템 상호작용을 에이전트 기반 협업 필터링으로 시뮬레이션하는 프레임워크입니다.
기존 연구가 주로 사용자 에이전트만 다루었다면, AgentCF는 아이템도 에이전트로 설정하여 사용자 에이전트와 함께 최적화하는 점이 핵심입니다. 즉, 사용자와 아이템 모두가 자율적으로 상호작용하고, 이를 통해 개인화된 행동 패턴(선호도)을 학습하도록 지원합니다.
이를 위해 LLM(대규모 언어 모델)은 ‘동결(freeze)’되어 파라미터가 바뀌지 않고, 에이전트들의 ‘메모리(문자열 형태)’를 반복적으로 업데이트하며 협업 필터링을 수행합니다. 이렇게 사용자–아이템 양측 에이전트가 함께 최적화되어, 실제 사용자의 구매 기록과 비교하면서 현실에 가까운 추천 시뮬레이션이 가능합니다.
1. Introduction
일반적인 인간 행동에는 대화뿐 아니라, 제품 구매·클릭과 같은 비언어적 상호작용이 존재합니다. 예를 들어, 추천 시스템에서는 “금요일에 기저귀를 사는 사람이 맥주도 구매할 확률이 높다”와 같은 행동 패턴이 협업 필터링 모델에서 잘 포착됩니다. 하지만 이 같은 사용자 행동 패턴을 단순히 자연어로만 LLM에게 전달하면, LLM이 보편적 언어적 지식에 의존하여 개인화된 행동 모델링에 어려움을 겪을 수 있습니다.
이를 해결하기 위해, AgentCF는 사용자 에이전트(user agent)와 아이템 에이전트(item agent)를 모두 시뮬레이션하고 협업 학습(collaborative learning)을 수행합니다. 아이템은 직접 ‘행동(구매)’을 하지는 않지만, 자신을 좋아할 수 있는 ‘잠재적 채택자(preferrer)’ 정보를 에이전트 메모리에 축적하고, 사용자가 해당 아이템을 선택하도록 영향을 주는 형태로 모델링합니다. 이렇게 사용자의 선호뿐 아니라 아이템의 관점(특징·주요 수요층)이 함께 최적화되는 방식으로 동작합니다.
FAQ: “아이템은 직접 행동하지 않는데 에이전트로 두는 이유?”
아이템 에이전트를 별도로 둠으로써, 이 아이템이 어떤 특성을 가졌고, 누구에게 선호되었는지를 기록·갱신할 수 있습니다. 즉, 사용자가 아이템을 평가하듯, 아이템도 ‘잠재적 채택자’를 가진다는 관점으로 에이전트를 구성합니다. 이를 통해 사용자가 다른 아이템과 상호작용할 때, 아이템들이 알고 있는 사용자들의 취향 정보를 유기적으로 전파할 수 있습니다.
2. Methodology
2.1 Preliminaries
-
LLM 동결(freeze)
- AgentCF에서는 LLM(대규모 언어 모델)의 내부 파라미터를 업데이트하지 않고, 고정된 상태로 활용합니다.
- 대신 사용자 에이전트와 아이템 에이전트 각각에 메모리(문자열 텍스트)를 두어, 여러 상호작용 및 반성 과정을 거치며 이 메모리 내용을 갱신합니다.
- 모델 자체를 미세조정(fine-tuning)할 필요 없이, 프롬프트나 메모리의 업데이트만으로 에이전트의 선호도·특징을 점차 현실 데이터에 맞추어 갑니다.
-
사용자/아이템 에이전트 초기화
- 실제 추천 시스템에서 수집된 사용자 구매 이력을 기반으로, 사용자 에이전트와 아이템 에이전트를 생성하고, 각 에이전트에 초기 텍스트 정보(취향, 장르, 카테고리 등)를 기록해둡니다.
-
학습(시뮬레이션) 방식 개요
- 사용자 에이전트가 positive/negative 아이템 후보 중 하나를 선택하고 선택 이유를 생성합니다.
- 이 결과를 실제 기록과 비교해 잘못된 선택이었다면, 사용자·아이템 에이전트가 반성(reflection)을 통해 서로의 메모리를 협업적으로 업데이트합니다.
- 이러한 과정을 여러 상호작용에 반복 적용함으로써, 에이전트가 점차 현실 사용자의 구매 패턴 및 아이템 특성을 정확히 반영하게 됩니다.
2.2 Collaborative Agent Optimization
에이전트 기반 협업 필터링을 구현하기 위해, 사용자 에이전트와 아이템 에이전트가 가진 메모리를 어떻게 구성·갱신하는지를 설명합니다.
Previous Memory : 구매 이력에 없는 item은 neg에 포함되어 있음
Autonomous Interaction : user agent 메모리의 잘못된 정보로 원래 구매 이력과 다른 선택을 함
Reflection & Memory Update : 시스템의 응답에 따라 user, item 에이전트가 수정됨사용자 에이전트의 메모리
- 단기 메모리 (Short-term memory, (M_u^s))
“현재” 사용자의 취향이나 상태를 표현하는 자연어 텍스트를 저장합니다. 예시:
“나는 에너지가 넘치는 기타 록 음악을 좋아해.”
- 장기 메모리 (Long-term memory, (M_u^l))
시간에 따라 변화하거나 과거 상호작용에서 축적된 취향 정보를 기록해둡니다.
새로운 상호작용이 발생할 때마다, 단기 메모리를 장기 메모리에 추가(append)함으로써 과거 선호도 변화를 추적합니다.
아이템 에이전트의 메모리
- 통합 메모리 (Integrated memory, (M_i))
아이템의 고유 특성(제목, 장르, 카테고리 등)과 해당 아이템을 선호한 사용자들의 취향 정보가 함께 저장됩니다. 예시:“이 CD는 파워풀한 보컬과 서정적인 멜로디로 구성되어 있어, 에너지가 넘치는 록을 좋아하는 사람에게 어필함.”
협업적 반성(Collaborative Reflection)
- 아이템 후보 선택
- 사용자 에이전트에게 (실제 구매했던) positive 아이템과 (구매하지 않았던) negative 아이템 중 하나를 선택하라고 지시합니다.
- 결과 비교
- 실제 사용자 구매 기록과 비교해, 에이전트 선택이 틀렸다면 그 차이를 피드백합니다.
- 반성(Reflection) 및 메모리 업데이트
- 사용자 에이전트는 자신의 단기 메모리 내용을 재검토하고, “내가 왜 이 아이템을 틀리게 선택했는지” 반성하며 취향 묘사를 업데이트합니다.
- 아이템 에이전트(특히 positive 아이템)는 사용자와의 관계, 타 사용자들의 선호 정보를 종합해, “어떤 점이 이 사용자에게 잘못 어필되었나”를 분석합니다.
- 이렇게 사용자–아이템 양측이 함께 업데이트됨으로써, 각 에이전트 메모리에 상호 관계가 녹아들게 됩니다.
- 협업 필터링 효과
- 아이템 에이전트가 과거에 학습한 다른 사용자들의 선호 정보를 자연스럽게 전파하고, 사용자 에이전트 또한 이 아이템에 대한 인상을 업데이트하여 다음 상호작용에 반영합니다.
- 결과적으로 유사 사용자끼리 비슷한 아이템을 선호하게끔 하는 협업 필터링의 핵심 아이디어를, 에이전트 차원에서 재현합니다.
2.3 Agent Interaction Inference
Advanced Prompting Strategies
: 장기 메모리에서 사용자에게 특화된 정보를 검색해 추가하거나
: 사용자 과거 상호작용 리스트 자체를 추가로 제공해 순차 추천으로 확장하는 방법을 시도할 수 있습니다.
3. Experiments
AgentCF의 학습 및 평가를 어떻게 진행했는지, 실험 과정을 요약합니다. 샘플링 방식, 평가지표, 비교 모델 설정, 추가 분석, 그리고 다양한 상호작용 유형을 시뮬레이션한 결과를 간략히 정리했습니다.
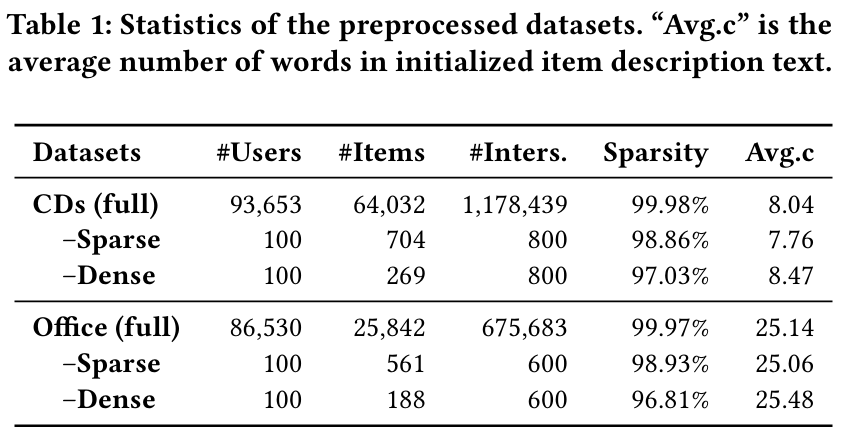
3.1 Dataset Sampling & Evaluation
-
Sparsity 제어:
- 아이템 수가 서로 다른 규모로 샘플링해, 데이터 희소성(sparsity)이 추천 성능에 미치는 영향을 확인합니다.
- 사용자별로 일정 개수의 상호작용을 추출하여, ‘희소’·‘밀집’ 데이터셋을 만들어 비교 실험을 수행합니다.
-
후보 아이템 구성:
- 테스트 시, 사용자가 실제로 상호작용한 정답 아이템(ground truth) 1개와, 상호작용하지 않은 9개 아이템(부정 예시)을 합쳐 총 10개 후보를 구성합니다.
- 모델이 정답 아이템을 상위에 랭크할수록 DCG(Discounted Cumulative Gain)가 높아집니다.
- 후보군을 3번 변경하여 얻은 평균값으로 최종 NDCG@K 성능을 계산합니다.
-
비교 모델:
- BPR, SASRec:
- 각각 협업 필터링 대표 모델(BPR)과 순차 추천 모델(SASRec)입니다.
- 샘플링된 소규모 데이터셋으로 학습한 경우, 그리고 원본(전체) 데이터셋으로 학습한 경우를 모두 비교합니다.
- Pop:
- 단순 인기도 기반 모델. 샘플링/전체 차이가 의미가 없으므로 전체 데이터 통계만 사용합니다.
- Zero-shot 모델(LLMRank 등):
- 샘플링된 데이터셋에 대해, 사용자의 과거 이력을 바로 LLM에 투입해 랭킹을 시도합니다.
- BPR, SASRec:
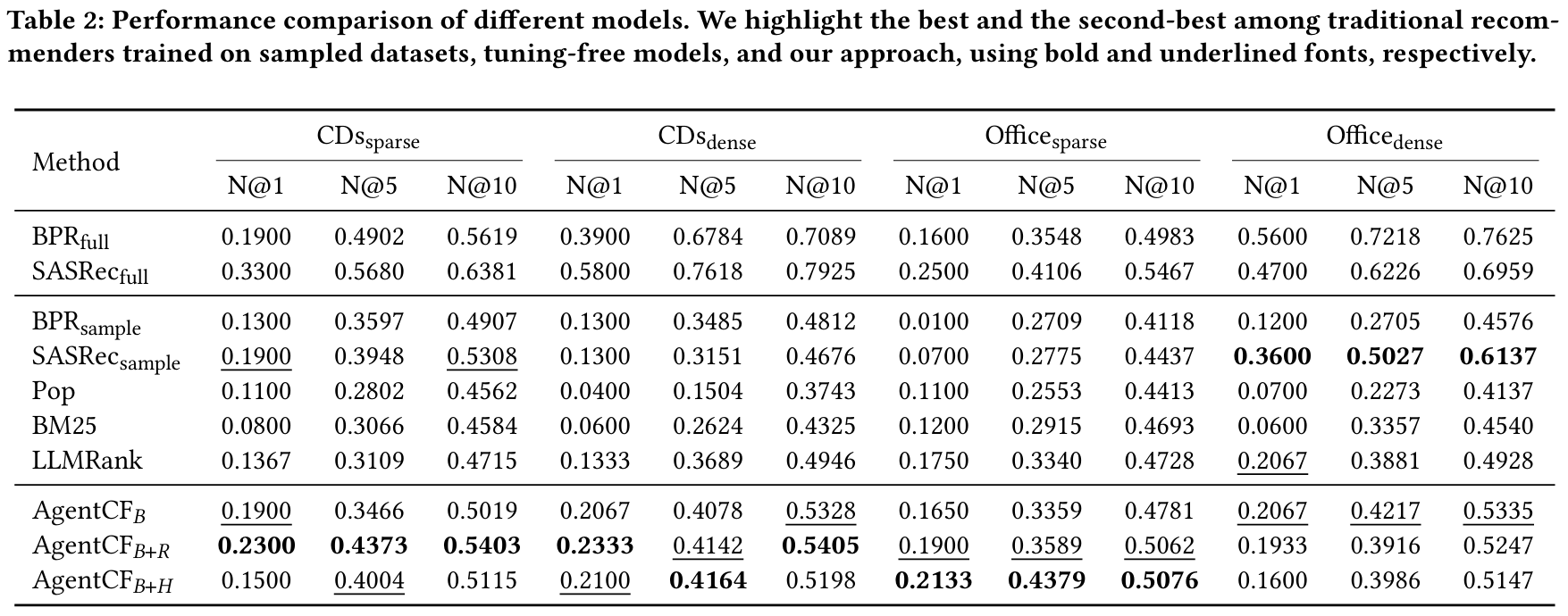
LLMRank는 사용자의 과거 이력을 LLM에 바로 입력해 Zero-shot 추론을 수행하지만, 내부 파라미터가 변경되지 않고 메모리 업데이트 과정이 없다는 점에서 AgentCF와 차이를 보입니다.
AgentCF는 사용자·아이템 에이전트가 반성(reflection)을 통해 메모리를 지속적으로 갱신한다는 특징 덕분에, LLMRank 대비 꾸준히 높은 NDCG 성능을 달성합니다.
또한, Office 데이터셋이 item description text가 더 길기 때문에, LLM이 활용할 수 있는 자연어 정보가 많아지는 효과가 있습니다. 이로 인해 전반적으로 Office가 CD보다 LLM 기반 모델들의 성능이 더 높게 나타납니다(예: LLMRank, AgentCF 변형들). 즉, 충분한 텍스트 설명이 제공될수록 LLM이 사용자·아이템 메모리(및 과거 행동)에 대한 추론을 풍부하게 수행할 수 있어 개인화 품질이 더 좋아진다는 점을 확인할 수 있습니다.
3.2 Reflection-Based Training
- Reflection 프롬프트:
- 사용자 에이전트가 정답과 다른 아이템을 고르면, “왜 잘못 골랐는지 반성하고, 메모리를 업데이트하라”는 프롬프트를 줍니다.
- 사용자(또는 아이템) 에이전트는 자기소개(혹은 특징 기술)를 자연어로 수정하여, 선호·특징을 갱신합니다.
- 반대로, 올바른 선택을 했을 경우에는 “네 선택이 맞았다”는 피드백을 받아, 해당 아이템에 대한 긍정적 묘사를 강화합니다.
- 결과:
- 이러한 반성(reflection) 과정을 통해, 단순히 LLM에 프롬프트만 입력하는 모델(예: LLMRank)보다 좋은 성능을 보였습니다.
- 이는 사용자 행동 패턴과 LLM이 학습한 보편적 언어 지식 간의 간극을, 반복 반성 과정에서 에이전트 메모리를 조정함으로써 메워주기 때문입니다.
3.3 Further Model Analyses
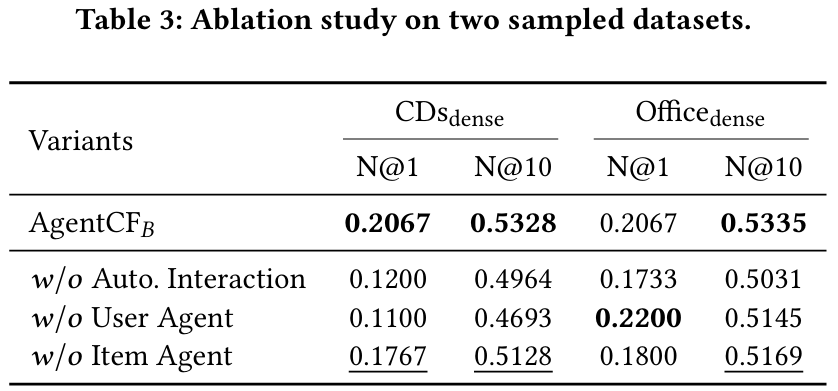
3.3.1 Ablation Study
-
w/o Autonomous Interaction
- 사용자가 직접 positive/negative 후보 중 선택하는 자율 상호작용 단계를 생략하고, 실측 데이터만 에이전트에게 주입하는 설정입니다.
- 이 경우, 에이전트가 본인 행동과 실제 행동의 차이를 자율적으로 인지·반성하는 기회가 줄어듭니다.
- 결과적으로 반성(reflection) 과정의 효과가 약해져 성능이 떨어집니다.
-
w/o User Agent
- 사용자 에이전트 최적화를 제거하고, 사용자를 단순히 과거 상호작용(텍스트)만으로 표현하는 시나리오입니다.
- 사용자 측 메모리를 지속적으로 업데이트하지 않으므로, 개인화된 취향이 잘 반영되지 않아 성능이 하락합니다.
- 다만, 아이템 설명이 긴 데이터셋(예: Office)처럼, LLM이 충분한 텍스트 단서를 얻을 수 있는 경우엔 일시적으로 높은 성능을 내기도 합니다. 그러나 전반적으로 사용자 에이전트 최적화가 유리함을 확인했습니다.
-
w/o Item Agent★
- 아이템 에이전트를 별도로 두지 않고, 아이템을 단순한 텍스트 정보로만 처리하는 경우입니다.
- 아이템 측 메모리가 협업 필터링에서 매우 중요한 역할(선호도 전파)을 하기 때문에, 이 부분을 제거하면 사용자 간 취향 공유가 줄어듭니다.
- 실험 결과 성능 하락이 있으며, 상호작용과 유저 에이전트만큼은 아닐지라도 아이템 에이전트 최적화가 협업 필터링의 핵심임을 보여줍니다.
3.3.2 Performance Comparison w.r.t. Position & Popularity Bias
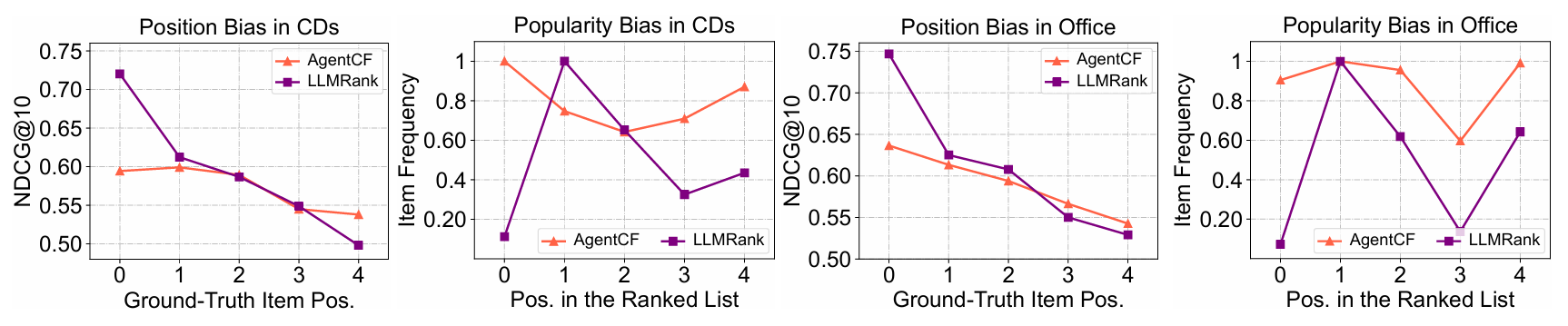
- 전형적인 LLM 기반 추천(LLMRank 등)은 인기 아이템, 혹은 리스트 상단(첫 번째 후보 등)에 배치된 아이템을 과도하게 선택하는 편향이 있습니다.
- AgentCF에서는 각 사용자 에이전트가 가진 개인화 메모리 덕분에, 인기·위치 편향을 완화합니다.
3.3.3 Collaboration & Reflection Effects
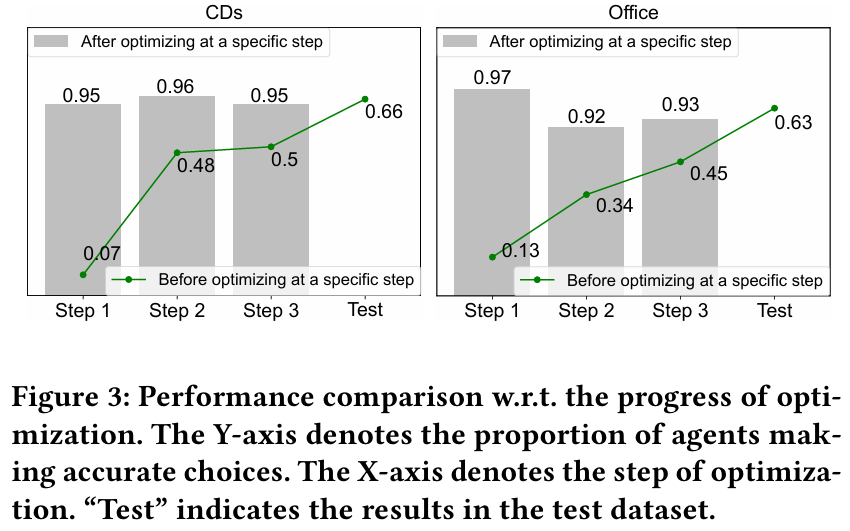
- 에이전트가 여러 상호작용 단계를 거치며, 실제 행동(ground truth)과 일치하도록 학습됩니다.
- 특히, ‘반성’ 프롬프트로 인해 90% 이상 확률로 긍정 아이템을 고르게 되며, 협업 필터링 아이디어를 자연스럽게 반영할 수 있습니다.
3.4 Simulations on Other Types of Interactions
-
사용자–사용자 상호작용
- 예: 한 사용자 에이전트가 다른 사용자 에이전트의 리뷰를 읽고, 아이템 구매 결정을 바꾸는 시나리오.
- 실제 리뷰 신뢰도와 유사한 거동(“비슷한 취향 사용자 리뷰를 더 신뢰”)을 보입니다.
-
아이템–아이템 상호작용
- 신제품(콜드스타트) 아이템 에이전트가 기존 인기 아이템 에이전트로부터 정보를 받아, 잠재적 선호층에 대한 인사이트를 얻습니다.
- 이를 통해 사용자 선호 정보를 빠르게 학습해 랭킹 성능을 향상합니다.
-
선호도 전파(Preference Propagation)
- 특정 사용자 에이전트의 고유 취향이 아이템 에이전트에 반영되고,
- 이후 해당 아이템을 접한 새로운 사용자 에이전트가, 간접적으로 동일 취향을 학습하게 됩니다.
- 이는 협업 필터링에서 말하는 “유사 취향자 간 정보 공유”를 자연어 메모리 기반으로 구현한 예시입니다.
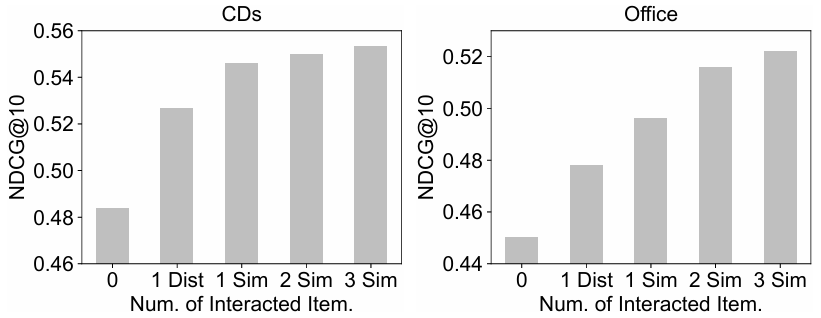
Item 자신과 구별되는 다른 identity 정보를 가지는 에이전트와의 상호작용에서도 성능이 향상되는 모습을 확인할 수 있습니다.
=> 이는 논문에서 identity 정보와 메모리 사이의 관계를 이해하고 있다고 해석합니다.
FAQ: “Identity와 Memory는 무엇이 다를까?"
Identity 정보: 아이템의 고유하고 변하지 않는 특성(예: “이 앨범은 록 장르다.”).
메모리: 실제로 여러 사용자와 상호작용하면서 얻은 동적 정보(“로맨틱한 분위기의 곡을 좋아하는 사용자들이 이 앨범도 좋아했다.”)
FAQ: "서로 다른 Identity를 가진 아이템과도 협업이 되는가?"
록 앨범(A)을 예로 들면, 처음에 “록 장르”라는 Identity만 있으면 주로 록 음악 팬에게만 매력적일 것처럼 보입니다.
하지만 A가 사용자들과 여러 번 상호작용하다 보면, “록 팬이 아니더라도 에너지가 넘치는 곡을 좋아하면 괜찮아할 수 있다” 같은 추가 정보(메모리)를 얻게 됩니다.
이 정보를 “전혀 다른 장르”로 분류된 앨범(B)과 교환(아이템 간 상호작용)할 때, B도 A가 발견한 “에너지가 넘치는 곡” 선호 사용자 정보를 활용할 수 있습니다.
FAQ: "관계를 이해하고 있다는 것이 무슨 의미일까?"
서로 다른 Identity(장르, 특성)를 갖더라도, 상호작용에서 얻은 메모리(사용자들이 어떤 면을 좋아했는지) 덕분에 아이템들끼리 협업이 가능해지고, 그 결과 성능(추천 정확도)이 더 좋아진다는 점에서 "관계를 이해하고 있다"고 표현한 것이라 생각합니다.
Conclusion
AgentCF는 사용자와 아이템을 모두 에이전트로 모델링하고, LLM은 동결한 채 이 에이전트들의 메모리만 협업적으로 업데이트하는 방식으로 작동합니다.
- 협업 필터링의 핵심 아이디어(양측 관계, 사용자 간 취향 전파 등)가 자연어 메모리·반성(reflection) 기법으로 실현되었습니다.
- 사용자–사용자 리뷰 교환, 아이템–아이템 정보 공유 등 다양한 시뮬레이션이 가능하며, 실제 사용자 데이터를 반영해 개인화된 상호작용을 더욱 풍부하게 재현할 수 있습니다.
향후에는 대규모 데이터셋을 대상으로 스케일업하거나, 에이전트 간 협력이 필요해지는 추가 시나리오(멀티에이전트 협업, 윤리적 프라이버시 고려 등)를 탐색함으로써, LLM 에이전트 생태계를 발전시킬 수 있을 것으로 기대됩니다.
C.3 Item-item Interaction
원문 (Original Text)
In this experiment, we explore whether interactions between new
and popular item agents can enable new item agents to estimate the
preferences of potential adopters and alleviate cold-start problems.
To do this, for well-trained user and item agents, we first simulate
the item cold-start scenario by removing the memories of ground
truth item agents, and only retaining their identity information,
such as titles and categories. Then, we enable these “new” item
agents to retrieve and interact with several popular item agents that
possess either similar or distinct identity information to them but
have rich interaction records, by performing dense retrieval and
taking their identity information as queries. During this process,
the “new” item agents read the memory of popular item agents,
thereby estimating their potential descriptions and adjusting their
memory. We finally prompt the user agents to rank these ground
truth items among nine other randomly sampled but well-trained
item agents, and compare the ranking results obtained using the
original cold-start memories and the adjusted memories.
한국어 번역 (Translation)
본 실험에서는, 새로운(new) 아이템 에이전트와 인기(popular) 아이템 에이전트 간의 상호작용이 새로운 아이템 에이전트에게 잠재적 사용자(채택자)의 선호도를 추정할 수 있는 단서를 제공하고, 콜드스타트 문제를 완화할 수 있는지 탐구합니다.
이를 위해, 우선 잘 학습된 사용자/아이템 에이전트를 준비하고, 아이템 콜드스타트 상황을 시뮬레이션하기 위해 실제 아이템(ground truth) 에이전트의 메모리를 제거하고, 제목/카테고리와 같은 최소한의 아이덴티티 정보만 남깁니다. 그 후, 이러한 ‘신규(new)’ 아이템 에이전트가 자신과 비슷하거나 혹은 전혀 다른 아이덴티티를 가진 인기 아이템 에이전트와 상호작용하도록 합니다(“Dense Retrieval” 기법을 사용해, 인기 아이템의 아이덴티티 정보를 쿼리로 삼아 검색).
이 과정에서 신규 아이템 에이전트는 인기 아이템 에이전트의 메모리를 읽어보며, 자신의 잠재적 설명(아이템 특징)을 추론·갱신하게 됩니다. 마지막으로 사용자 에이전트에게 해당 아이템을 9개의 다른 (이미 잘 학습된) 아이템 후보와 함께 랭킹하게 하고, 메모리를 조정하기 전(콜드스타트 상태)과 조정한 후(정보 반영)의 순위를 비교합니다.
Initialization (예시 초기화)
원문 (Original Text)
• Cold-start Item Agent The CD is called “Early Days: The Best of Led Zeppelin, Vol. 1”. The category of this CD is: “Rock; Rock Guitarists; Guitar Gods”. • Popular Item Agent A “Led Zeppelin 1” is a Rock CD that epitomizes captivating rock music with powerful guitar solos and a raw energy... ...(이하 생략)
한국어 번역 (Translation)
• 콜드스타트 아이템 에이전트 이 CD의 이름은 “Early Days: The Best of Led Zeppelin, Vol. 1”이며, 카테고리는 “Rock; Rock Guitarists; Guitar Gods”로 설정합니다. • 인기 아이템 에이전트 A “Led Zeppelin 1”은 강렬한 기타 솔로와 거친 에너지가 돋보이는 매력적인 록 음악을 상징하는 Rock CD입니다... ...위와 같이, “Cold-start Item Agent”의 메모리는 제목과 카테고리 등 최소 정보만 남기고,
“Popular Item Agent A/B/C/...”는 풍부한 사용자 상호작용 기록과 특성을 포함하고 있습니다.
Cold-start Item Memory Refinement
원문 (Original Text)
• Cold-start Item Agent system prompt “Early Days: The Best of Led Zeppelin, Vol. 1” is a rock CD that showcases the captivating exceptional talent of Led Zeppelin...한국어 번역 (Translation)
• 콜드스타트 아이템 에이전트에게 주어지는 system prompt “Early Days: The Best of Led Zeppelin, Vol. 1”은 Led Zeppelin의 탁월한 재능을 보여주는 록 CD입니다...
- 이와 같은 System Prompt를 통해, 신규 아이템 에이전트가 인기 아이템 에이전트들의 메모리(예: 기타 연주 스타일, 장르 특성, 사용자 반응)에서 추가 정보를 흡수해, 자기소개(메모리)를 갱신하게 됩니다.
