<논문 리뷰> HutCRS: Hierarchical User-Interest Tracking for Conversational Recommender System (EMNLP 2023)
논문 리뷰
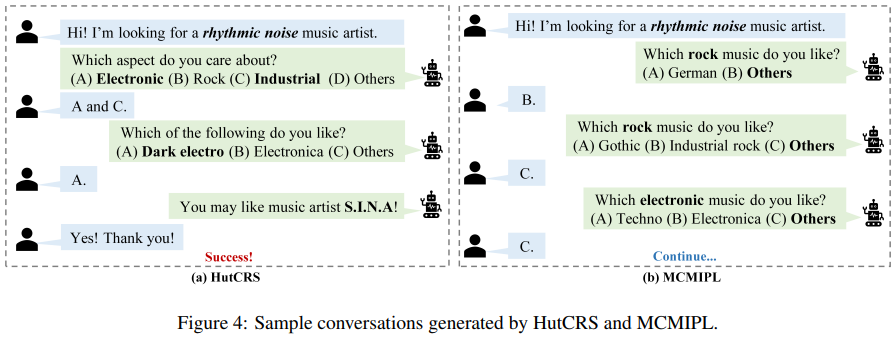
Abstract
기존의 CRS 방식은 사용자의 지식이나 관심도와 무관하게 필요한 각 속성마다 사용자에게 ‘예/아니오’ 형태의 명시적 응답을 요구하기 때문에, 사용자 경험과 의미적 일관성을 크게 저해할 수 있다.
더 나아가, 이전 방법들은 목표 아이템(target item)의 모든 속성을 좋아하고 그와 무관한 속성은 싫어한다고 가정함으로써, 속성 단위(attribute-level) 피드백에 편향을 야기하여 시스템이 목표 아이템을 정확히 식별하는 능력을 떨어뜨릴 수 있다.
이러한 문제를 해결하기 위해, 우리는 더욱 현실적이고 사용자 친화적이며 설명 가능한 CRS 프레임워크인 “대화형 추천 시스템을 위한 계층적 사용자 관심 추적(Hierarchical User-Interest Tracking for Conversational Recommender System, HutCRS)”을 제안한다.
HutCRS는 대화를 두 단계로 구성된 ‘계층적 관심 트리(hierarchical interest tree)’로 묘사하는데,
- 1단계에서는 사용자가 선호하는 측면(aspect)을 식별하고
- 2단계에서는 이 긍정적 측면과 관련된 속성을 묻거나 아이템을 추천한다.
1. Introduction
CRS가 직면한 주요 과제 중 하나는 사용자 선호도를 효율적으로 파악하고 추천 후보를 신속하게 좁히는 방법이다. 다중 라운드 대화형 추천(Multi-round Conversational Recommendation, MCR)은 대화 횟수를 최소화하면서도 성공적인 추천을 달성하는 것을 목표로 한다.
먼저, MCR은 질의된 모든 속성에 대해 사용자가 (예 또는 아니오로) 명확한 답변을 갖고 있다고 전제한다. 하지만 현실에서는 사용자가 목표 아이템의 모든 속성을 반드시 좋아하지 않을 수도 있고, 목표 아이템에 포함되지 않은 속성을 꼭 싫어하는 것도 아닐 수 있다. 이러한 차이 때문에 속성 단위(attribute-level) 피드백이 왜곡되어 시스템이 목표 아이템을 정확히 식별하기 어려워질 수 있다.
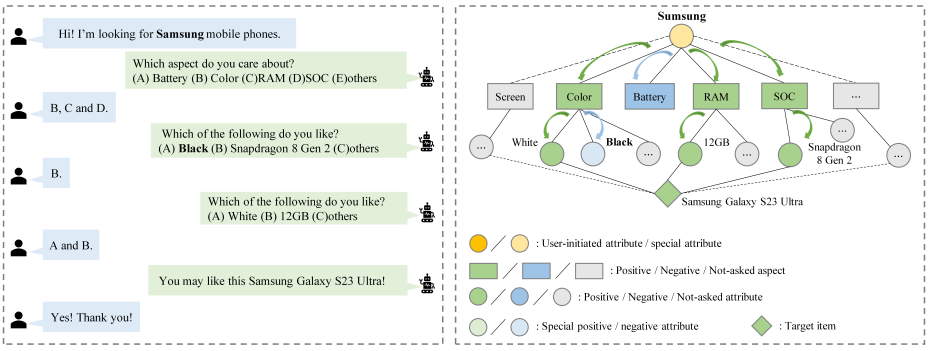
‘어떤 측면을 묻고, 언제 속성을 물어보고, 언제 아이템을 추천할지’에 관한 의사결정 과정을 통합하기 위해 계층적 관심 정책 학습(Hierarchical-Interest Policy Learning, HIPL) 모듈을 개발하였다. 더 나아가, 시스템의 ‘특수한(special) 정보’ 포착 능력을 강화하고자, 속성 단위(attribute-level) 피드백 결과를 분류하는 방식을 제안한다. 예컨대, 과거 데이터에는 존재하지 않으면서 사용자가 긍정적으로 평가한 속성, 또는 과거 데이터에는 존재하지만 사용자가 부정적으로 평가한 속성을 “특수”로 표시한다.
3. Definition and Preliminary
-
기본 개념 정의
- 사용자 집합:
- 아이템 집합:
- 속성(Aspect) 집합:
- 속성 인스턴스(Attribute Instance) 집합:
- 각 아이템 는 해당 아이템의 속성 인스턴스 집합 를 갖고, 각 속성 인스턴스 는 이에 대응하는 aspect 를 가짐
-
에피소드(episode) 설정
- 사용자 에 대해, 허용 가능한 아이템들의 집합 존재
- 의 모든 아이템에 공통으로 속하는 속성 인스턴스 집합을 이라 함
- 세션은 사용자 초기 선택 속성 인스턴스 에서 시작
-
상호작용 과정
- 시스템은 후보 속성 집합 에서 사용자가 어떤 속성을 선호하는지 질의
- 긍정적 피드백을 얻을 때까지 반복
- 이후 긍정적으로 평가된 속성들과 관련된 속성 인스턴스에 대해 추가로 묻거나 아이템을 추천
- 허용 가능한 아이템이 최소 하나 추천되거나, 혹은 시스템이 최대 턴 수 에 도달할 때까지 계속 진행
속성(aspect)은 "항목의 어떠한 공통된 속성(유형)"을 가리키고,
속성인스턴스(attribute instance)는 “그 속성에 해당하는 구체적인 값 또는 세부 특성”을 의미한다.
예를 들어,
속성(aspect)이 “색상(color)”인 경우,
속성인스턴스(attribute instance)는 “빨간색(red)”, “파란색(blue)” 등
실제로 해당 속성이 어떤 값인지 구체적으로 나타내는 항목들이다.
4. HutCRS
Zhang et al. (2022), Lei et al. (2020b), Deng et al. (2021)와 유사하게,
우리의 프레임워크는 정책 네트워크 를 학습하여
누적 보상의 기댓값 을 최대로 하는 것을 목표로 한다.
- : 현재 상태(state)
- : 에이전트가 취하는 행동(action)
- : 중간 보상(intermediate reward)
4.1 Hierarchical User Interest Tracking
정책 네트워크 를 학습하기 위해서는, 먼저 상태(state)와 행동(action)을 정의하고 적절히 표현해야 한다. 이를 위해 본 논문에서는 Hierarchical User State Tracking 모듈을 사용하여 현재 상태를 추적하고, Interest-based Candidate Selection 모듈을 통해 후보를 순위화한다.
사용자 상태 추적에는 계층적 관심 트리(Hierarchical Interest Tree) 개념이 도입된다. 본 트리는 세션 중 사용자 선호도 변화를 추적하여, 주요 속성 및 아이템 노드들을 동적으로 관리한다.
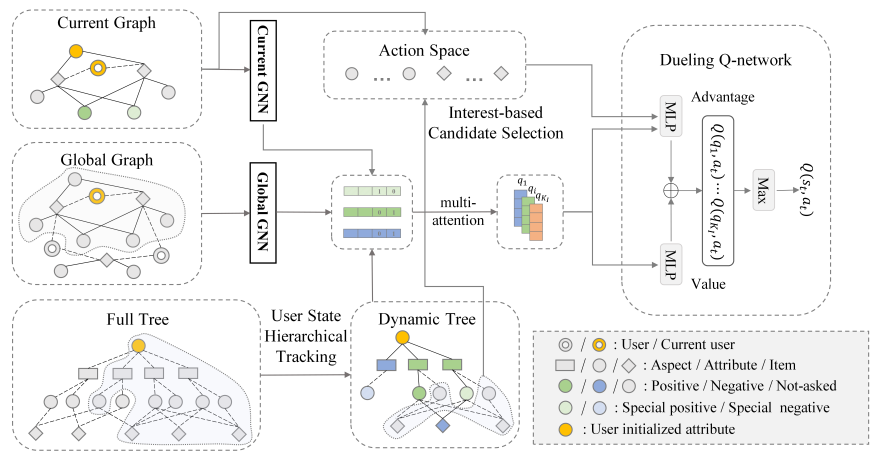
- Current Graph & Global Graph
- Global Graph
- 시스템이 보유한 전체 지식그래프(아이템–속성 관계, 사용자–아이템 상호작용 이력 등)를 의미
- Current Graph
- 현재 사용자 세션에서 사용되는 서브그래프 혹은 작은 규모의 그래프
- 두 그래프 각각은 Global GNN, Current GNN으로 처리되어 노드 임베딩을 산출
- Global Graph에는 전체 정보가 담기고, Current Graph에는 현재 사용자와 직접적으로 연관된 속성/아이템만 포함될 수 있음
- Full Tree & Dynamic Tree
- Full Tree
- 계층적 관심 트리(Hierarchical Interest Tree)의 전체 구조
- 루트 노드: 사용자 초기화 속성
- 첫 번째 계층 노드: 모든 속성(aspect)
- 두 번째 계층 노드: 모든 속성 인스턴스(attribute instance)
- 마지막 계층 노드: 아이템(item)
- Dynamic Tree
- 사용자 피드백을 반영해 Full Tree를 가지치기(prune) 한 후, 현재 세션에서 실제 유효한 노드만 남긴 동적 트리
- 사용자가 상호작용 중 긍정·부정 피드백을 준 노드와 추천 후보에 속하는 노드만 유지
- Interest-based Candidate Selection & Action Space
- Interest-based Candidate Selection
- (1) 그래프 임베딩(Current GNN, Global GNN 결과),
- (2) Dynamic Tree 기반 사용자 상태,
- 두 정보를 종합하여 추천 후보(또는 질의할 속성)를 생성하고 점수화(순위화)
- Action Space
- 시스템이 취할 수 있는 행동들의 집합
- 예: 특정 속성(또는 인스턴스)에 대해 질문하기, 특정 아이템 추천하기 등
- Dueling Q-network (Reinforcement Learning part)
- Dueling Q-network
- 강화학습에서 활용되는 신경망 구조로, Advantage와 Value를 분리하여 를 계산
- Interest-based Candidate Selection에서 나온 후보 행동에 대해 Q값을 산출
- 최종적으로 가 가장 큰 행동을 선택해 사용자와 상호작용 진행
4.1.1 Hierarchical User State Tracking
- 속성 단위 피드백 분류
- Positive Attributes
- 과거 이력(역사 데이터)에 존재하지 않으면서, 사용자가 긍정적으로 평가한 속성
- Negative Attributes
- 과거 이력에 존재하며, 사용자가 부정적으로 평가한 속성
- 이러한 특성을 “특수(special)”로 표시함으로써 시스템이 새로운 정보(positive)나 이전 데이터 상 존재하지만 거부된 정보(negative)를 분명히 구분
- 현재 상태 정의
- 시스템의 현재 상태 는 다음을 포함
-
- 사용자가 수용한(accept), 거부한(reject), 또는 후보(candidate)로 남아 있는 측면(aspect) 집합
-
- 사용자가 수용·거부한 속성 인스턴스, 혹은 특수하게 수용·거부된 속성 인스턴스
-
- 사용자가 거부한 아이템, 추천 후보 아이템
-
- 단계별 업데이트 전략
-
3.1 Stage I: Aspect 질의
- 1. 사용자가 특정 측면(aspect)을 수용() 또는 거부()
- 2. 시스템은 등 관련 집합을 업데이트 (현재 후보 aspect 중 이번 대화로 거절된 aspect를 제거하면서)
- 3. 거부된 측면에 해당하는 속성 인스턴스는 단순히 에 추가하지 않고, 특수 거부()로 분류
- 4. “Aspect instance-based union set” 전략으로 를 갱신- 사용자가 거부한 속성이 포함됐다는 이유만으로 아이템을 전부 제거하지 않고, 사용자 피드백을 종합하여 후보를 결정
-
3.2 Stage II: Attribute 질의
- 1. 후보 속성()을 초기화해, 사용자에게 구체적 속성 인스턴스를 질의
- 2. 수용·거부된 속성 인스턴스( 등)와 특수 속성()을 갱신
- 3. 이 단계에서도 동일한 “attribute instance-based union set” 전략을 적용해, 를 업데이트- 기존 연구(Zhang et al., 2022)처럼 부정 속성이 포함된 아이템을 무조건 제거하지 않음
- 핵심
- “특수(special)” 속성 표시를 통해 사용자 피드백을 세밀하게 반영
- 거부된 속성이 포함된다고 하여 모든 아이템을 배제하지 않고, 실제 사용자의 의도를 최대한 반영
- 두 단계(Stage I, II)로 나누어 측면(aspect) → 속성 인스턴스(attribute instance) 순으로 세분화된 피드백을 수집하고, 이를 통해 후보 아이템을 점진적으로 필터링
4.1.2 Interest-based Candidate Selection
- 동적 가중 그래프(Dynamic Weighted Graph) 구성
-
매 턴 에서 사용자 와 관련된 동적 그래프 를 생성
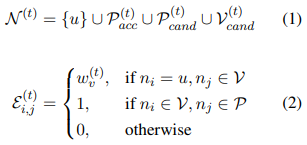
-
노드 집합
- 사용자(), 수용된 속성 인스턴스(), 후보 속성 인스턴스(), 후보 아이템()을 포함
-
엣지 집합
- 노드 쌍 간의 가중치(weighted edge)를 의미
- 예: 사용자와 아이템, 사용자와 속성 인스턴스, 아이템과 속성 인스턴스 간 관계
- 후보 노드(아이템·속성) 랭킹을 위한 가중치 산출
- Deng et al. (2021)의 방식을 따라, 사용자 임베딩 , 아이템 임베딩 , 속성 임베딩 를 활용해 가중치를 계산
- 예: 아이템 노드 의 가중치 는 다음과 같이 정의됨
- 는 시그모이드 함수
- : 사용자–아이템 간 기본 적합도
- : 수용(또는 거부)된 속성 인스턴스가 아이템과 얼마나 일치하는지 반영
- “특수 부정(special negative)” 속성을 고려해 가중치를 감산
- 속성과 아이템을 구분한 랭킹 방식
- 아이템 랭킹과 달리, 속성 랭킹 시에는 사용자 선호를 잡아낼 뿐 아니라 후보 아이템의 불확실성도 함께 줄여야 함
- HutCRS는 이미 사용자의 긍정적 측면(positive aspects)에만 속하는 속성을 묻기 때문에, Wu et al. (2015)의 엔트로피(entropy) 기법을 이용해 후보 순위를 매김
- 사용자에게 질문할 속성이나 추천할 아이템을 선택할 때, 불확실성이 큰 후보를 우선적으로 해결해나가는 전략
4.2 Hierarchical-Interest Policy Learning
1. 그래프 표현 (Short-term & Long-term 선호 반영)
1.1 Current Graph 임베딩
- 동적 그래프 는 현재 턴에서 사용자 와 관련된 속성·아이템 노드를 모아 구성
- -layer GCN (Kipf & Welling, 2016) 적용 → 노드(사용자·아이템·속성 인스턴스) 임베딩 산출
- 단기(Short-term) 관심이 반영된 임베딩 (현재 세션 중심)
1.2 Global Graph 임베딩
- 전역적(Global) 그래프: 전체 사용자·아이템·속성을 포괄해, 장기(Long-term) 선호나 전반적 관계를 캡처
- -layer Global GNN (Schlichtkrull et al., 2018; Chen et al., 2020) → 각 노드의 전역 임베딩 추출
- 과거 히스토리나 일반적 아이템–속성 관계 등을 반영
2. Hierarchical-Interest Extractor (다단계 멀티어텐션)
2.1 거부 아이템·속성 임베딩 결합
- 사용자 거부(rejected) 아이템·속성 인스턴스를 합쳐, 부정적 관심 요약 벡터 생성
- : 거부된 노드 집합
- : 글로벌 그래프 임베딩
- : 학습 파라미터
- “사용자가 싫어하는 특성”을 요약해 반영
2.2 특수(special) 속성 레이블
- 수용(accepted)된 속성 중, 과거 데이터에는 없었으나 이번 세션에서 새롭게 선호가 확인된 경우 special positive로 표시
- “이전에는 없던 속성을 좋아하게 됐다”는 특수 케이스를 강조
2.3 멀티어텐션(Multi-attention) 반복
- : 수용 속성·아이템 임베딩 + 거부 요약 벡터를 입력으로
- 개의 어텐션 네트워크를 순차 적용, 노드 중요도 를 반복 계산
- 예) 첫 어텐션 결과:
- : -번째 반복 후 임베딩
- : 노드 의 상대적 중요도
- 최종 -번째 반복의 결과 가 계층적 사용자 관심을 효과적으로 캡처
3. Action Decision Policy Learning (강화학습 의사결정)
3.1 두 단계(Stage I, II)
-
Stage I
- 상위 측면(aspect)을 탐색하고, 사용자 선호·거부 속성을 식별
- Sum-based로 Q값을 집계해 어느 측면을 물어볼지 결정
-
Stage II
- 긍정적 측면에 대해 구체 속성(attribute) 질의 or 아이템 추천
- Top-based 전략으로 Q값 최댓값을 가진 행동(추천 vs 속성 질의) 선택
- 추천 시 top-K 아이템, 속성 질의 시 top-K 속성 인스턴스를 질문
3.2 Q-value 계산 (Dueling Q-Network)
- : MLP 형태의 듀얼(Advantage/Value) 구조
- Bellman 방정식:
- : 사용자 피드백(긍정/부정/성공)으로 인한 보상
- : 할인율
3.3 학습 기법 (Double DQN, Target Network)
- Double DQN(Van Hasselt et al., 2016) → Q값 과대추정 완화
- Target Network → 주기적으로 파라미터 동기화, 학습 안정화
- Replay Buffer 에서 무작위 샘플링으로 학습:
- : Target Network 파라미터
5. Experiment
5.2 Experiments Setup
-
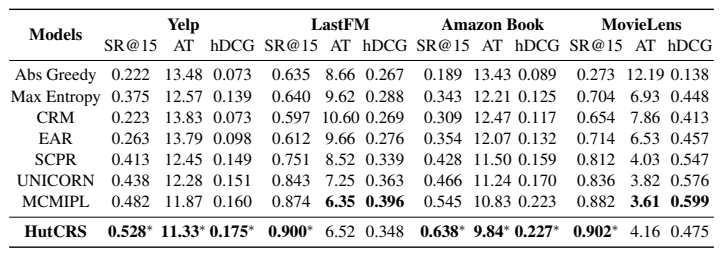
HutCRS는 SR@15에서 기존 모델보다 최대 17% 높은 성능을 기록
-
그러나 AT(Average Turn) 및 hDCG는 일부 데이터셋에서 기존 모델보다 성능이 낮음.
-
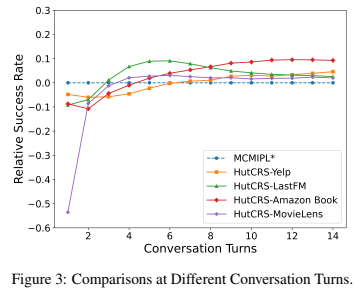
초기 단계(Stage I)에서 HutCRS가 추천을 하지 않기 때문에, MCMIPL에 비해 초기 성공률이 낮을 수 있음.
-
하지만 보다 복잡한 데이터셋(Yelp, Amazon-Book)에서는 전반적인 성능이 더 우수.
전체적으로 HutCRS가 기존 모델보다 더 나은 성능을 발휘한다고 평가됨.
Conclusion & Limitations
Conclusion
- 보다 현실적, 사용자 친화적, 설명 가능한 대화형 추천 프레임워크
- 대화를 두 단계로 나눈 계층적 관심 트리(Hierarchical Interest Tree) 기반
- HIPL 모듈을 통해 의사결정(어떤 속성을 물어볼지, 언제 아이템을 추천할지)과 속성 단위 피드백 분류를 통합
- 4가지 벤치마크 실험에서 우수한 성능을 달성
Limitations
- 계층적 관심 트리 구조를 활용하기 때문에, 속성(attribute)과 측면(aspect) 데이터를 모두 필요로 함
- 대화를 Stage I → Stage II로 나누었으나, Stage II 진입 후 Stage I으로 돌아갈 수 없도록 설계됨
- 이로 인해 단계 간 피드백 상호작용이 제한될 수 있음
- 피드백을 속성 단위로만 분류하고 있어, 아이템 단위 분류가 부족
- 향후 아이템 수준 분류로 확장할 여지가 있음
논문의 주요 내용 정리
HutCRS가 기존 SOTA 모델 대비 성능을 개선할 수 있었던 주요 요인은 대체로 다음과 같습니다:
-
2단계 대화(Aspect → Attribute) 구조
- Stage I에서 먼저 사용자에게 상위 측면(aspect)을 묻고,
- Stage II에서 해당 측면과 관련된 구체적 속성(attribute)을 질문하거나 아이템을 추천
- 이를 통해 질문의 순서를 정교하게 관리하고, 단계별 사용자 피드백을 더욱 체계적으로 반영
- 결과적으로 불필요한 질문을 줄이고, 사용자 선호를 효율적으로 파악
-
Hierarchical-Interest Policy Learning(HIPL) 모듈
- “어떤 측면(aspect)을 물을지”와 “언제 아이템을 추천할지” 같은 의사결정 과정을 통합
- 강화학습(Dueling Q-network 등)을 이용해 단계별로 최적의 행동(질문 vs. 추천)을 학습
- 최소 대화 횟수로 정확한 추천을 달성할 수 있도록 설계
-
속성 단위 피드백 분류(특수 속성 강조)
- 특수(special) 속성(과거 기록에는 없지만 새롭게 수용된 속성, 혹은 기존에 있었지만 새로 거부된 속성)을 별도 관리
- 새롭게 드러난 선호나 역사 데이터와 불일치하는 부분을 효율적으로 포착
- 사용자 선호 모형이 더 정교해져, 추천 정확도 향상에 기여
-
단기·장기 선호를 결합한 그래프 임베딩
- Current Graph(현재 대화 세션 중심)와 Global Graph(전체 사용자–아이템–속성 관계)를 각각 GNN으로 임베딩
- 단기(Short-term) 관심과 장기(Long-term) 취향을 모두 반영해, 사용자 일시적 관심과 일반적 취향 간 균형 확보
-
다단계 멀티어텐션
- 속성·아이템 임베딩, 수용·거부 피드백 등을 여러 차례 어텐션으로 반복 집약
- 사용자 관심을 다각도에서 추출해 최종 행동 결정 시 정확도를 높임
따라서 2단계 대화 설계, 피드백 분류 정교화, 강화학습 기반 정책 학습, 그래프 임베딩 등이 결합되어,
기존 모델보다 유연하고 정확한 대화형 추천이 가능해졌다고 볼 수 있습니다.
이전 SAPIENT 모델과의 차이점
HutCRS
- 사용자 피드백을 (수용/거부/특수) 형태로 명시적으로 분류
- Dynamic Tree(가지치기)로 대화 중 불필요한 속성·아이템을 제외
- 트리 구조(Aspect/Attribute)와 DQN을 결합해, 속성 기반 대화를 효율화
SAPIENT
- 시뮬레이터를 통해 전역적(planning) 미래 대화 전개까지 고려
- HutCRS가 속성에 대하여 명시적으로 분류하여 해당 속성에 대해 질문하거나 추천함에 비해, SAPIENT는 시뮬레이션을 수행하여 예상 보상을 계산 → 최적 행동을 탐색
- 강화학습(Policy) + 탐색(Planning)을 결합해 장기적 보상을 극대화
속성 분할을 통한 대화 효율화와 달리, Planning(계획) 기반 접근이 주는 가장 큰 이점은 “장기적으로 더 나은 보상”을 얻기 위해 각 턴에서의 행동이 이후 대화에 미치는 영향까지 고려한다는 점입니다.
