<논문 리뷰> SAPIENT: Mastering Multi-turn Conversational Recommendation with Strategic Planning and Monte Carlo Tree Search (NeurIPS 2024)
논문 리뷰
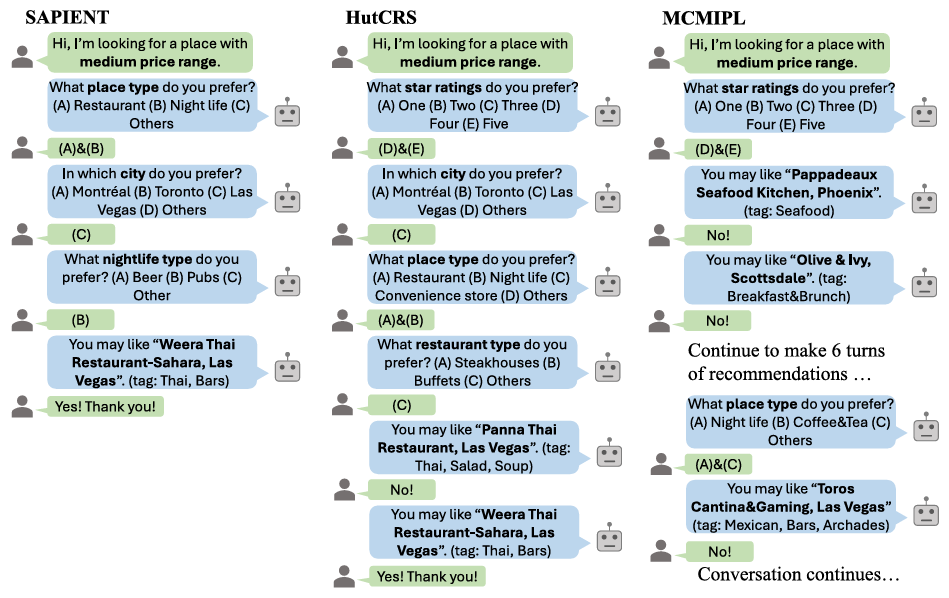
Abstract
대화형 추천 시스템(Conversational Recommender Systems, CRS)은 사용자 선호도를 파악하고 개인화된 추천을 제공하기 위해 대화형 상호작용을 적극적으로 활용하는 시스템입니다.
기존 방법들은 강화학습(Reinforcement Learning, RL) 기반의 에이전트를 훈련하여 탐욕적인(greedy) 액션 선택 또는 샘플링 전략을 사용하지만, 이는 최적이 아닌 대화 계획을 초래할 수 있습니다.
1. Introduction
CRS에는 다양한 설정이 존재하는데, 그중에서도 다중턴 대화 추천(Multi-turn Conversational Recommendation, MCR) 방식이 특히 인기가 높습니다.
MCR은 여러 차례 사용자와 상호작용(즉, 다중 턴) 하면서 점진적으로 사용자의 선호도를 학습할 수 있도록 합니다.
본 연구에서는 MCR을 위한 새로운 전략적 대화 계획 능력을 강화하기 위해, 몬테카를로 트리 탐색(Monte Carlo Tree Search, MCTS)을 활용한 새로운 MCR 프레임워크를 개발합니다.
이 프레임워크는 복잡한 대화 환경을 효과적으로 처리하고, 사용자 경험을 향상시키는 새로운 접근 방식을 제시합니다.
MCR의 핵심 과제
MCR의 주요 목표는, 각 대화 턴에서 어떤 액션(특정 속성 값을 질문할 것인지, 특정 아이템을 추천할 것인지)을 선택할지 결정하는 것입니다.
기존 방법 및 문제점
기존 연구들은 MCR 문제를 마르코프 결정 과정(Markov Decision Process, MDP)으로 공식화하여 접근해 왔습니다.
정책 기반(Policy-based), 가치 기반(Value-based)의 두 가지 방식으로 CRS 에이전트를 훈련해왔는데, 기존 방법들은 다음과 같은 한계점을 가집니다.
- 단기적인 행동 선택 (Myopic Actions)
- 누적 오류 발생 (Cumulative Error)
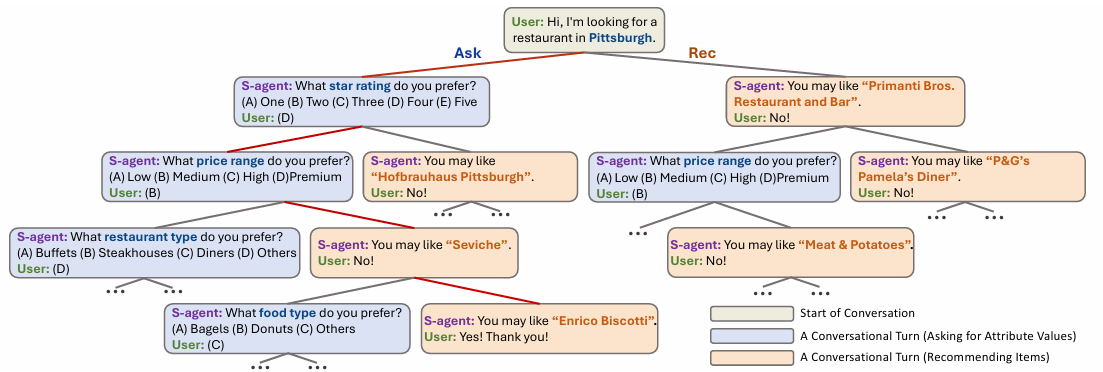
이러한 한계를 해결하기 위해, 본 논문에서는 MCTS 기반의 새로운 MCR 프레임워크인 SAPIENT(Strategic Action Planning with Intelligent Exploration Non-myopic Tactics)를 제안합니다.
SAPIENT는 두 가지 주요 구성 요소로 이루어져 있습니다.
-
S-agent (대화 에이전트) :
실제 대화를 수행하며 추천을 제공.
MCTS 기반의 알고리즘을 활용하여 S-planner와 협력해 대화를 계획함.
전역 정보 그래프(Global Information Graph) 및 개인화 그래프(Personalized Graphs)를 사용해 대화 상태를 표현.
정책 네트워크(Policy Network)와 Q-네트워크(Q-Network)를 통해 액션을 결정.
-
S-planner (대화 기획자) :
MCTS를 활용하여 미래의 대화를 시뮬레이션하고, 최적의 전략을 탐색.
장기적인 보상(Cumulative Reward)을 극대화하는 전략적 대화 계획을 수행.
즉각적인 보상(Greedy Action Selection) 방식이 아니라, 미래 대화를 고려한 비단기적(Non-myopic) 플래닝을 수행.
MCTS의 확장성 문제 해결 (Hierarchical Action Selection)
아이템 및 속성의 크기에 맞게 확장 가능하도록 하기 위해, 계층적 액션 선택(Hierarchical Action Selection) 과정을 도입하였습니다.
탐색 공간이 커지는 문제를 해결하기 위해, 각 턴에서 모든 아이템과 속성을 탐색하는 대신, MCTS가 두 개의 액션 타입(Ask/Rec)만 검색하여 탐색 공간을 크게 줄이고 연산 효율성을 높임.
SAPIENT를 9개의 기존 최첨단 CRS 모델과 비교하고,
4개의 벤치마크 데이터셋에서 SAPIENT가 기존 모델보다 뛰어난 성능을 보인다는 것을 확인했습니다.
SAPIENT-e: 효율적인 변형 모델
SAPIENT의 학습 비용을 줄이기 위한 효율적인 변형 모델
2. Related Work
대표적인 다중턴 CRS 연구는 다음과 같습니다.
-
EAR (Lei et al., 2020b)
사용자 피드백을 반영하는 세 단계의 대화 전략(Three-staged process)을 사용.
-
SCPR (Lei et al., 2020c)
MCR을 사용자, 아이템, 속성 값을 연결하는 지식 그래프(Knowledge Graph) 탐색 문제로 모델링.
-
UNICORN (Deng et al., 2021)
그래프 기반 강화학습(Graph-based RL) 모델을 활용한 MCR 프레임워크.
-
MCMIPL (Zhang et al., 2022)
다중 관심 정책 학습(Multi-interest Policy Learning) 기법을 통해, 사용자의 다양한 속성 선호도를 학습.
-
HutCRS (Qian et al., 2023)
사용자 관심 추적 모듈(User Interest Tracking Module)을 도입하여, 사용자 선호도를 효과적으로 추적.
-
CORE (Jin et al., 2023)
대형 언어 모델(LLM, Large Language Model)을 활용한 CRS 프레임워크를 설계.
사용자 친화적인 프롬프트 및 상호 피드백 메커니즘 포함. -
Chen et al. (2019), Montazeralghaem et al. (2021)
대규모 아이템 및 속성 값을 처리하기 위해 트리 구조 인덱스(Tree-structured Index)와 군집화 알고리즘(Clustering Algorithm) 사용.
3. Notations and Definitions
-
기본 용어
- : 사용자(User) 집합
- : 아이템(Item) 집합
- : 속성(Attribute type) 집합 (예: 가격대, 별점 등)
- : 속성 값(Attribute value) 집합 (예: 중간 가격대, 5성급 등)
-
사용자-아이템 관계
- 각 사용자 는 상호작용한 아이템 집합 를 가짐 (예: 조회, 구매).
- 각 아이템 는 속성 타입 집합 와 해당 속성 값 집합 를 가짐.
-
대화 초기화
- 대화는 사용자 가 처음으로 어떤 속성 타입 와 그에 대응하는 속성 값 를 제시하며 시작
(예: “저는 중간 가격대의 장소를 찾고 있어요.”).
- 대화는 사용자 가 처음으로 어떤 속성 타입 와 그에 대응하는 속성 값 를 제시하며 시작
-
대화 흐름
- 대화의 -번째 턴에서, S-agent(시스템)는 아래 두 액션 중 하나를 수행:
- Ask: 후보 속성 값 집합 중 하나(또는 여러 개)에 대해 “선호를 물어본다.”
- Recommend: 후보 아이템 집합 중 하나(또는 여러 개)를 “추천한다.”
- 사용자는 매 턴마다 “수락(accept)” 혹은 “거절(reject)”로 응답.
- 대화의 -번째 턴에서, S-agent(시스템)는 아래 두 액션 중 하나를 수행:
-
종료 조건
- 사용자()가 추천받은 아이템을 하나 이상 수락하면, 해당 턴 에서 대화 성공(success) 으로 종료.
- 최대 턴 에 도달해도 아이템을 수락하지 않으면, 대화 실패(fail) 로 종료.
-
목표
- 사용자가 수용할 만한 아이템을 빠른 턴 내에 추천해 대화를 종결함.
- (너무 긴 대화는 사용자 피로와 이탈로 이어질 수 있으므로, 가능한 한 적은 턴이 바람직)
4. Method
본 논문에서는 MCR 문제를 장기적(non-myopic) 관점에서 다룰 수 있도록, 몬테카를로 트리 서치(MCTS)를 활용한 새로운 프레임워크 SAPIENT를 제안합니다.
SAPIENT는
- 대화형 추천을 MDP(Markov Decision Process)로 공식화(4.1절),
- S-agent가 현재 상태를 바탕으로 액션을 계층적으로 결정(4.2절),
- S-planner가 MCTS를 통해 미래 대화를 시뮬레이션 및 계획(4.3절),
- 그 결과물로부터 S-agent가 Self-training 방식으로 학습(4.4절)
함으로써 장기 보상을 극대화하는 대화 정책을 학습하게 됩니다.
4.1 MDP Formulation for MCR
MDP 환경 정의
각 사용자 에 대해, MDP 환경을 다음과 같이 정의합니다:
- : 상태(state) 공간
- : 액션(action) 공간
- : 상태 전이 함수
- : 즉시 보상(Reward) 함수
- : 할인율(discount factor)
계층적 액션 선택 (Hierarchical Action Selection)
기존 연구(Nachum et al., 2018)를 참고하여, S-agent는 매 턴 마다 두 단계로 액션을 결정합니다:
- 액션 타입 결정
- 해당 액션 타입에 따라, 구체 액션 (예: 어떤 속성 값을 물어볼지, 어떤 아이템을 추천할지) 결정
상태 정의
-
번째 턴의 상태를 형태로 정의합니다.
- : 지금까지 수락(accept)된 속성 값들의 집합
- : 지금까지 거절(reject)된 속성 값들의 집합
- : 지금까지 거절된 아이템들의 집합
-
대화가 진행되며 사용자가 아이템을 수락하면 대화가 끝나므로, “수락된 아이템 집합”은 상태에 굳이 포함하지 않습니다(는 필요 없음).
-
추가적으로, S-agent는 사용자 의 정보와 전역 정보 그래프 (사용자–아이템–속성 관계를 나타내는 3부 구조 그래프)도 참조할 수 있습니다.
-
초기 상태 는, 사용자가 처음 언급한 속성 타입 과 속성 값 로부터 초기화됩니다
(예: “저는 중간 가격대 식당을 찾고 있어요.”).
액션 (Action)
- 액션 공간 에는 두 가지 유형이 존재합니다:
- ask: 특정 속성 값(예: )에 대한 사용자의 선호를 물어봄
- rec: 특정 아이템(예: )을 추천
- 실제로는 “액션 타입”을 먼저 고른 뒤, 그에 맞는 후보(예: 또는 ) 중 어떤 것을 선택할지 세분화합니다.
보상 (Reward)
- 번째 턴에서의 즉시 보상을 로 두고, 전체 대화(턴 1부터 까지)의 누적 보상은
로 계산합니다.
- 사용자에게 속성이나 아이템을 수락받으면 양의 보상을, 거절당하면 0 또는 음의 보상을 주는 식으로 설계할 수 있습니다.
- 목표는 이 할인 누적 보상을 최대화하도록 대화 정책을 학습하는 것입니다.
요약: MCR을 MDP로 바라보면, 각 대화 턴에서의 상태 , 액션 , 보상 가 정의되고,
에이전트는 장기 보상을 최적화하는 액션 시퀀스를 학습하게 됩니다.
4.2 S-agent
S-agent는 대화 에이전트 역할을 하며, 크게 다음 세 구성으로 이루어져 있습니다:
- State Encoder (상태 인코더)
- Policy Network (정책망)
- Q-Network (듀얼링 Q-네트워크)
이 과정을 통해, S-agent는 매 턴에서 “액션 타입”과 “구체 액션”을 계층적으로 결정합니다.
1) State Encoder
-
그래프 신경망(GNN)을 사용해, 전역 정보 그래프 와 사용자별 피드백 그래프에서 노드 임베딩을 학습합니다.
- 전역 그래프 : 사용자–아이템–속성 관계를 나타내는 3부 구조. (노드 타입이 3가지 이므로)
- 긍정 피드백 그래프 : 사용자 가 지금까지 수락한 속성·아이템 정보를 반영.
- 부정 피드백 그래프 : 거절한 속성·아이템 정보를 반영.
-
이 임베딩들을 Transformer 기반 Aggregator를 통해 종합하여, 상태 표현 를 최종적으로 얻습니다.
- 에는 “사용자가 좋아하거나 싫어한 속성 및 아이템”이 모두 반영된 맥락 정보가 포함됩니다.
2) Policy Network
-
인코딩된 상태 표현 를 입력받아, 이번 턴의 액션 타입 을 확률 분포로 모델링하여 예측합니다.
-
논문에서는 이를 다음과 같이 표현:
-
여기서 는 2-layer 퍼셉트론이며, 출력 차원은 두 개(
ask,rec)입니다. -
결과적으로, S-agent는 정책망을 통해 “이번 턴에서 속성을 물어볼지 vs. 아이템을 추천할지”를 결정합니다.
3) Q-Network
-
정책망에서 액션 타입 가 결정된 뒤, 실제로 어떤 속성/아이템을 선택할지를 Q값을 통해 고릅니다.
-
논문에서는 듀얼링(Dueling) Q-network(Wang et al., 2016) 구조를 사용하는데, 다음 식으로 나타냅니다:
- 여기서
- 는 후보 액션(질문할 속성 값, 추천할 아이템)의 임베딩,
- 와 는 각각 Advantage와 Value 함수를 모델링.
- 이전 연구의 방식을 이용한 것으로 해당 논문에서 자세한 설명은 X
결론: S-agent는
(1) 상태 인코더로부터 풍부한 맥락 정보를 얻어,
(2) Policy Network로 액션 타입을 결정하고,
(3) Q-Network로 구체 액션을 고르는 계층적(hierarchical) 구조를 갖습니다.
4.3 S-planner
S-planner는 대화를 몬테카를로 트리 서치(MCTS)로 시뮬레이션하여, 탐색(exploration)과 활용(exploitation)을 균형 있게 수행하면서 각 사용자에게 가장 적합한 대화 플랜을 찾습니다.
-
트리 구조
- 각 노드(node) 는 상태 를 나타냄.
- 루트 노드 는 “사용자가 처음 언급한 속성 정보를 받은 상태”에 해당.
- 리프 노드(leaf)는 대화가 성공(아이템 수락) 또는 실패(최대 턴 초과) 로 종료된 상태.
- 노드 와 자식 노드 를 잇는 엣지(edge) 는 액션 타입 및 구체 액션 를 의미.
-
- 상태 에서 액션 타입 를 선택했을 때의 기대 미래 보상.
- S-planner는 시뮬레이션 과정에서 를 반복 갱신하여 “어떤 액션 타입이 더 유망한가”를 학습.
-
번의 시뮬레이션
- 각 사용자 에 대해, S-planner는 번의 대화 시나리오(trajectory) 를 탐색해봄.
- 번째 시뮬레이션 궤적을 라고 하며, 이는 들의 시퀀스로 구성.
네 가지 단계 (Search Tree)
탐색과 활용을 균형 있게 맞추기 위해서,
MCTS에서 ‘트리 정책(Tree Policy)’을 세울 때 UCT 공식을 사용하였습니다.
exploitation (활용) : 이미 성능(승률)이 좋아 보이는 노드를 더 자주 선택하여 빠르게 이점을 누리기
exploration (탐색) : 아직 충분히 방문(시도)되지 않은 노드를 적당히 탐색해볼 기회를 주기
-
Trajectory Selection
-
루트부터 리프까지 현재 트리 상에서 “가장 유망해 보이는 경로”를 선택.
-
유망한 경로는 UCT(Upper Confidence bound for Trees) 공식을 사용하여,
- 여기서 는 탐색 계수(exploration factor)로 두 항의 비중을 조절
- 는 노드 의 방문 횟수
- 는 에서 액션 타입 를 택했을 때 도달하는 자식 노드.
- exploitation-exploration 간 균형을 맞출 수 있음.
-
액션 타입 를 선택한 뒤, 구체 액션 는 Q-네트워크로
로 결정.
-
-
Node Expansion
- 리프 노드(더 이상 자식 노드가 없는 상태)에 도달하면,
ask와rec두 액션 타입에 대응하는 자식 노드를 새로 만든다. - 새 자식 노드의 기대 보상 는, Q-네트워크가 추정하는 최댓값으로 초기화하여
- “이 노드에 잠재적으로 높은 가치가 있을 수 있다”고 알려주면,
이후 탐색에서 그 노드를 시도해볼 동기가 생기고, 실제 방문을 통해 점차 정확한 값을 업데이트하게 되고, 향후 탐색을 위한 휴리스틱 가이드로 삼음.
- 리프 노드(더 이상 자식 노드가 없는 상태)에 도달하면,
-
Conversation Simulation
- 확장된 노드부터 대화를 가상으로 계속 진행하여,
- 정책망으로 액션 타입을 고르고, Q-네트워크로 구체 액션을 골라,
- 사용자가 수락(success) 하거나 실패(fail) 할 때까지 시뮬레이션함.
-
Reward Back-propagation
- 시뮬레이션이 끝나면(성공 or 실패 시점), 리프에서 루트로 거슬러 올라가며 방문 횟수와 를 갱신:
- 여기서 는 “턴 부터 대화가 끝날 때까지” 얻은 누적 보상.
- 는 노드 의 방문 횟수.
- 이 업데이트는 오차 방향으로
1/씩 이동하는 식이며, 확률적 경사상승(stochastic gradient ascent)와 유사함.
- 시뮬레이션이 끝나면(성공 or 실패 시점), 리프에서 루트로 거슬러 올라가며 방문 횟수와 를 갱신:
요약:
S-planner는 MCTS로 “대화 트리”를 확장 & 시뮬레이션하면서,
탐색/활용을 균형 있게 해 장기 보상이 높은 액션 타입을 찾아내고,
이를 통해 최적에 가까운 대화 플랜을 형성합니다.
4.4 Guiding S-agent with S-planner
S-planner를 통해 최적(또는 고보상) 대화 플랜을 찾은 뒤, 그 결과를 이용하여 S-agent(Policy & Q-Network)를 훈련합니다.
이는 Self-training loop(Silver et al., 2017)를 형성하며, S-agent가 점차 장기적 대화 계획 능력을 발전시키도록 만듭니다.
Self-training Process
-
Best Conversation Plan 사용
- MCTS 시뮬레이션 결과 중 누적 보상(cumulative reward)이 높은 대화 플랜(trajectory)들을 골라,
- 각 턴에서의 경험 를 메모리 에 저장합니다.
- 이 때, 와 가 있어야 “다음 상태에서의 Q값”을 정확히 추정 가능.
-
Prioritized Experience Replay (PER)
- 메모리 로부터 샘플을 우선순위에 따라 뽑아(batch) 훈련
- 연속적이고 시계열로 상관된 데이터에서 발생할 수 있는 편향(Mnih et al., 2015)을 완화.
Policy Network Update
- Supervised 방식으로, S-planner가 결정한 액션 타입 를 정책망이 그대로 따라가도록 학습
- 즉,
- classification 문제에서 자주 사용되는 손실 함수
- 이는 “S-planner가
ask를 고른 턴에서는ask확률을 높이고,rec를 고른 턴에서는rec확률을 높이도록” 유도하는 로스. - = 정책 네트워크가 S-planner가 찾은 최적의 액션을 예측하도록 학습하는 방식
Q-Network Update
- Double Q-learning(van Hasselt et al., 2016) 기법을 사용해,
- 온라인 네트워크 와 타깃 네트워크 로 오버에스티메이션을 방지.
- 식 (6):
- 여기서 는 MDP의 할인율입니다.
Improving Training Efficiency: SAPIENT-e
-
문제점: 가장 보상 높은 Trajectory들만 골라 학습하면 질은 좋지만, 충분한 수를 확보하려면 시뮬레이션 비용이 커짐.
-
해결책(SAPIENT-e):
- 모든 시뮬레이션 궤적을 활용(좋은 궤적 + 나쁜 궤적 포함).
- 대신, Plackett-Luce 모델(Luce, 1959; Plackett, 1975)을 사용해,
- 보상 순위가 높은 궤적의 확률을 높이고, 낮은 궤적의 확률을 낮추도록 학습.
- 식 (7)에서 보이는 것처럼,
- 누적 보상 순으로 정렬된 여러 트라이젝터리에 대해, 정책망이 “보상 높은 순서를 더 선호”하도록 최적화.
- 효과: 성능은 SAPIENT 대비 약간 떨어질 수 있지만, 학습 효율(트래젝터리 수집 비용)이 크게 개선.
결론:
1. S-planner로 좋은 대화 플랜을 얻고,
2. 그 경험(trajectory)을 메모리에 저장해
3. Policy & Q-Network를 업데이트.
- (기본 SAPIENT) 보상 높은 궤적만
- (SAPIENT-e) 모든 궤적을 랭킹 기반으로 활용
이렇게 Self-training 루프를 반복함으로써, S-agent가 단계적으로 장기 보상에 최적화된 대화 정책을 학습하게 됩니다.
5. Experimental Settings
Datasets
- 본 연구에서는 Yelp (Lei et al., 2020b), LastFM (Lei et al., 2020b),
Amazon-Book (McAuley et al., 2015), MovieLens (Harper and Konstan, 2015)
총 4개의 벤치마크 데이터셋을 활용하여 SAPIENT를 평가합니다.
User Simulator
- 실제 사용자와의 대규모 대화형 실험은 비용이 매우 크므로,
논문에서는 기존 연구 (Lei et al., 2020b; Deng et al., 2021; Zhang et al., 2022; Zhao et al., 2023; Qian et al., 2023)에서
널리 사용되는 사용자 시뮬레이터를 이용합니다. - 각 사용자 에 대해 시뮬레이션을 통해 대화를 생성하며(상세 내용은 Appendix F.2),
이는 대규모 평가에도 낮은 비용으로 실행 가능하다는 장점이 있습니다 (Lei et al., 2020a; Zhang and Balog, 2020).
Evaluation Metrics
- 기존 문헌 (Deng et al., 2021; Zhang et al., 2022)를 따라, 다음 세 지표를 사용합니다:
- Success Rate (SR):
- 최대 턴 이내에 사용자가 아이템을 수락한 대화의 비율.
- Average Turn (AT):
- 평균 대화 턴 수(짧을수록 좋음).
- hDCG (Deng et al., 2021):
- 추천된 아이템 목록 중 정답 아이템의 랭킹 품질을 평가하기 위한 지표(DCG 변형).
- Success Rate (SR):
9가지 최첨단(SoTA) 기법과 비교 평가를 진행합니다.
6. Experimental Results
6.1 Overall Performance Comparison
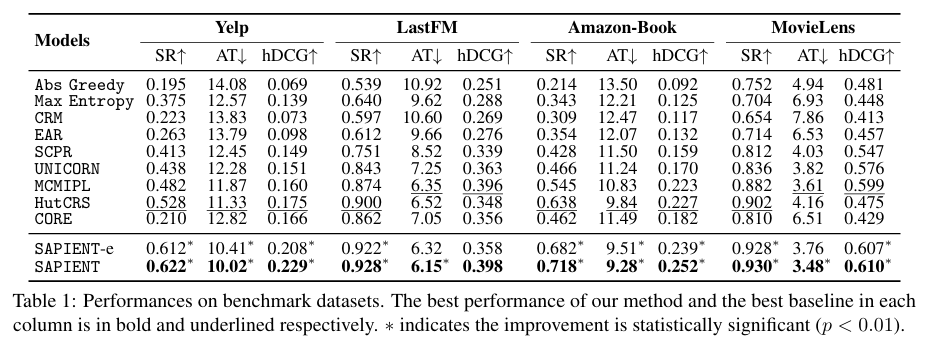
-
비교 대상: 9개의 최신(SoTA) 베이스라인과 비교하여, Table 1에 결과 제시
-
주요 관찰점
-
SAPIENT의 전반적 성능 우수
- 모든 데이터셋에서, 모든 지표(SR, AT, hDCG)에 대해 일관된 향상을 보임
- 평균적으로 SR은 +9.1%, AT는 -6.0%(짧아짐), hDCG는 +11.1% 개선 (베이스라인 대비)
- 이는 MCTS 기반 장기적(planning) 대화 전략 덕분
-
장기 전략이 중요한 데이터셋일수록 성능 향상 두드러짐
- Yelp, Amazon-Book처럼 대화 길이(AT)가 긴 경우, SAPIENT가 확실히 우세
- LastFM, MovieLens는 상대적으로 대화가 짧아서, 기존 모델들도 준수
-
SAPIENT-e 역시 높은 추천 성공률
- 고품질 트래젝터리만을 쓰지 않고도, 여전히 모든 베이스라인보다 우수
- 효율성과 성능 사이에서 좋은 절충안 역할
-
6.2 Efficiency Analysis
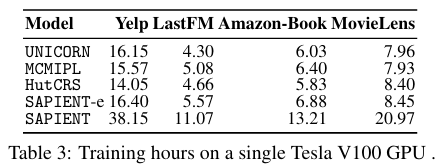
-
SAPIENT-e의 훈련 시간은 베이스라인과 크게 다르지 않음
-
SAPIENT의 경우 베이스라인의 2배 정도 소요되며, MCTS 시뮬레이션 시 forward propagation만 수행하므로, 다소의 추가 연산에도 큰 지연 없이 학습
-
추론 단계에서는 트리 탐색을 수행하지 않으므로, 실시간 응답 시에도 베이스라인과 유사한 속도
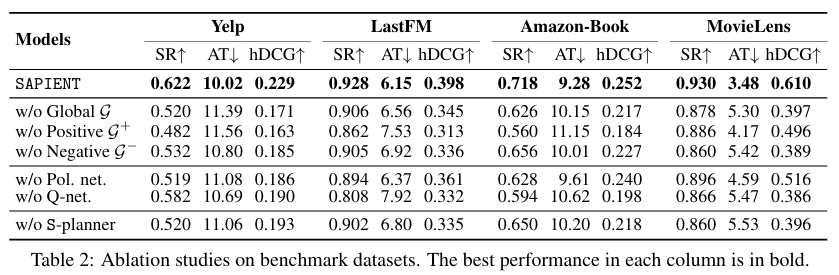
6.3 Ablation Study
-
목적: SAPIENT의 주요 구성 요소(그래프, 네트워크 구조 등)의 기여를 확인
-
결과 요약:
-
각 그래프(, , ) 모두 필수
- 전역 그래프 : 사용자–아이템–속성 관계 추출에 중요
- 긍정 그래프 , 부정 그래프 : 사용자의 선호/비선호 피드백 반영에 필수
-
Policy Network & Q-Network 둘 다 필요
- Policy Network 없이 임의(random) 타입 선택하면 성능 급락
- Q-Network 없이 Entropy 기반 아이템 선택해도 성능 급락
- 즉, 상위 정책(
askvs.rec)과 하위 구체 액션(속성/아이템) 결정이 모두 중요
-
S-planner로부터의 가이드가 결정적
- S-planner를 제거하고 샘플된 온정책(on-policy) 궤적만으로 학습 시, 오류 누적 및 편향
- 고보상 궤적을 직접 제공하는 S-planner가 있어야 전략적 대화 가능
-
6.4 Hyperparameter Sensitivity
-
탐색 계수 와 롤아웃 횟수 (MCTS 시뮬레이션 횟수)에 대한 민감도 실험 (Appendix F.6)
-
결과:
- 가 너무 작으면 성능이 떨어짐 → 충분한 탐색 필요
- 을 1에서 20으로 늘리면 성능 급상승, 20 초과시에는 안정적
- 즉, 부근이 효율(적은 시뮬레이션)과 성능(장기 보상) 사이의 균형점을 이룸
7. Conclusion
-
SAPIENT: 새로운 MCR 프레임워크
- 전략적이고(long-term), 단기적 보상에 얽매이지 않는(non-myopic) 대화 계획을 가능하게 함
- 계층적 액션 선택 + MCTS 기반 대화 트리 탐색 + 고보상 대화 플랜을 사용한 에이전트 학습
-
추론 시(inference), S-agent는 S-planner 없이도 축적된 학습 결과로 의사결정을 내림
-
SAPIENT-e 변형: MCTS 효율성을 높이는 방안 제시
-
결론: 벤치마크 데이터셋에서 대규모 실험을 통해, 제안 프레임워크의 유효성이 검증됨
8. Limitations
-
액션 타입의 단순성
- 현재는
ask/rec두 가지 유형만 다룸 - 예: “별점 5 아이템 추천” vs. “별점 3 아이템 추천”처럼 더 세분화된 액션은 고려하지 못함
- 향후 연구: 액션 추상화(추가 세분화) 기법으로 액션 공간을 확장할 계획 (Bai et al., 2016)
- 현재는
-
학습 비용
- SAPIENT는 사용자별 여러 번의 시뮬레이션 롤아웃(MCTS)이 필요 → 기존 기법 대비 계산량이 더 큼
- 향후 연구: 병렬 가속(Chaslot et al., 2008 ) 등을 적용해 MCTS 학습 효율 높이는 방법 모색
-
사용자 시뮬레이터 한계
- 시뮬레이터가 현실 사용자의 복잡한 행동 양상을 완전히 재현하지 못할 수 있음
- 향후 연구: 대형 언어 모델(LLM)을 활용한 더 정교한 사용자 시뮬레이터 개발 검토
-
공정성·편향 문제
- CRS가 올바르게 배포되면 유용하지만, 잘못 사용될 경우 편향(bias) 이슈가 생길 수 있음 (Shen et al., 2022)
- 향후 연구: 탈편향(debiasing) 알고리즘 등을 접목해 안전하고 책임감 있는 추천을 보장
