과적합과 과소적합이라네요~
열심히 해봅시다 빨리 해야 함 과제 제출 전까지 ㅋ
모델을 정확하게 쓰는 목적이라네요..
Experimenting With Different Models
이제 여러 대체 모델을 실험해서 어떤 모델을 가장 정확한 예측을 제공하는지 확인할 수 있다..
Decision Tree Model 에는 사용자가 원하거나 오랫동안 필요로 하는 것보다 더 많은 정보를 scikit-learn 의 문서에서 확인할 수 있음
가장 중요한 옵션은 트리의 깊이 를 결정한다.
트리의 깊이는 예측에 도달하기 전에 얼마나 많은 분할을 하는지를 측정하는 척도라는 것을 기억해야 한다.
다음 사진은 비교적 얕은 트리임
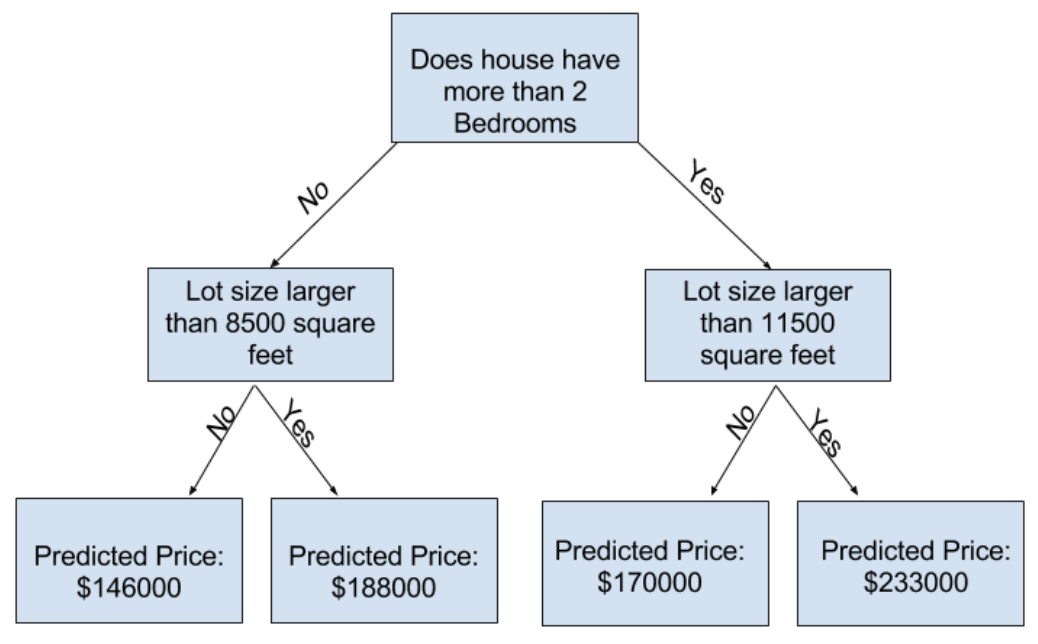
실제로 나무의 최상위 레벨(모든 집)과 잎 사이에 10개의 분할이 있는 경우는 드물지 않음
트리가 깊어질수록 데이터 집합은 더 적은 수의 집을 가진 잎으로 분할됨
트리에 분할이 1개 만 있는 경우, 데이터를 2개의 그룹으로 나눔
각 그룹을 다시 분할하면 4개의 주택 그룹이 생김
또 분할하면 8개의 그룹이 만들어짐
각 레벨에서 더 많은 분할을 추가해서 그룹 수를 두 배로 늘리며 10번째 레벨에 도달할 때까지 210개의 주택그룹이 생김 (1024개의 나뭇잎)
집을 여러 나뭇잎으로 나누면 각 나뭇잎에 있는 집의 수도 줄어듦
집이 매우 적은 잎은 해당 집의 실제 값에 매우 근접한 예측을 하지만 새로운 데이터에 대해서는 신뢰하기 어려운 예측을 할 수 있음 (각 예측은 몇 개의 집만을 기반으로 하기 때문)
이는 모델이 학습 데이터와는 일치하나 새로운 데이터에서는 제대로 작동하지 않는 과적합(Overfitting) 현상이다.
극단적으로 트리가 집을 2개 또는 4개로만 나누면 각 그룹에는 여전히 다양한 집이 있음
학습 데이터에서도 대부분의 주택에 대한 예측 결과가 벗어날 수 있는데, 이를 과소 적합(Underfitting) 이라고 한다.
과소적합과 과적합 사이의 최적점 을 찾아야 함.
시각적으로 나타낸 것은 다음과 같음
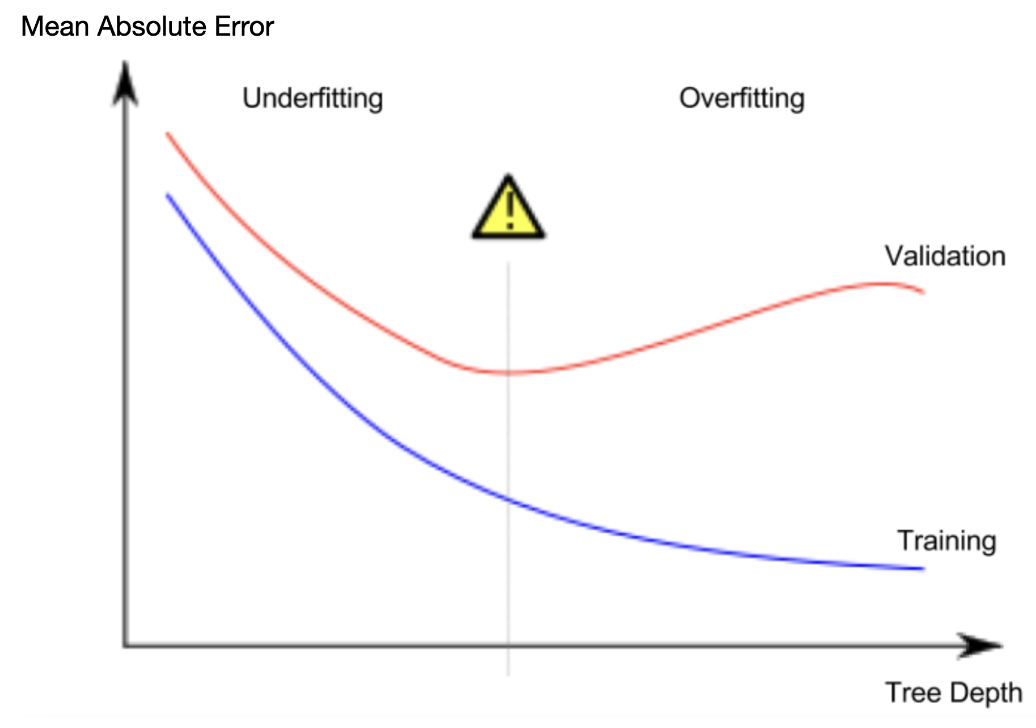
Example
트리 깊이를 제어하는 몇 가지 대안이 있고, 트리를 통과하는 일부 경로가 다른 경로보다 더 큰 깊이를 가질 수 있도록 허용하는 경우가 많다.
하지만 max_leaf_nodes 인수는 과적합과 과소적합을 제어하는 매우 합리적인 방법을 제공한다.
모델에 더 많은 잎을 허용할수록 위 그래프에서 과소적합 영역에서 과적합 영역으로 더 많이 이동한다.
최대 잎 노드에 대한 다양한 값의 MAE(Mean Absolute Error) 점수를 비교하는 데 도움이 되는 유틸리티 함수를 사용할 수 있다.
from sklearn.metrics import mean_absolute_error
from sklearn.tree import DecisionTreeRegressor
def get_mae(max_leaf_nodes, train_X, val_X, train_y, val_y):
model = DecisionTreeRegressor(max_leaf_nodes=max_leaf_nodes, random_state=0)
model.fit(train_X, train_y)
preds_val = model.predict(val_X)
mae = mean_absolute_error(val_y, preds_val)
return(mae)여기서 데이터는 sklearn.model_selection 의 train_test_split 을 사용하여 train_X, val_X, train_y, val_y 로 나누어야 함
for문을 사용해서 max_leaf_nodes 의 다른 값으로 구축된 모델의 정확도를 비교할 수 있다.
for max_leaf_nodes in [5, 50, 500, 5000]:
my_mae = get_mae(max_leaf_nodes, train_X, val_X, train_y, val_y)
print("Max leaf nodes: %d \t\t Mean Absolute Error: %d" %(max_leaf_nodes, my_mae))
MAE가 가장 적은 500이 적절한 잎 숫자라네요~
Conclusion
다음은 요점이다. 모델에서는 문제가 발생할 수 있음
과적합(Overfitting) : 미래에 반복되지 않을 가짜 패턴을 포착하여 예측 정확도가 떨어지는 경우
과소적합(Underfitting) : 관련 패턴을 포착하지 못하여 예측 정확도가 떨어지는 경우
모델 학습에는 사용되지 않는 검증 데이터를 사용하여 후보 모델의 정확도를 측정함
-> 이를 통해 후보 모델을 시도하고 가장 적합한 모델을 유지할 수 있다네요~
