1.강의 내용
[NLP]Recurrent Neural Network and Language Modeling
Basic structure
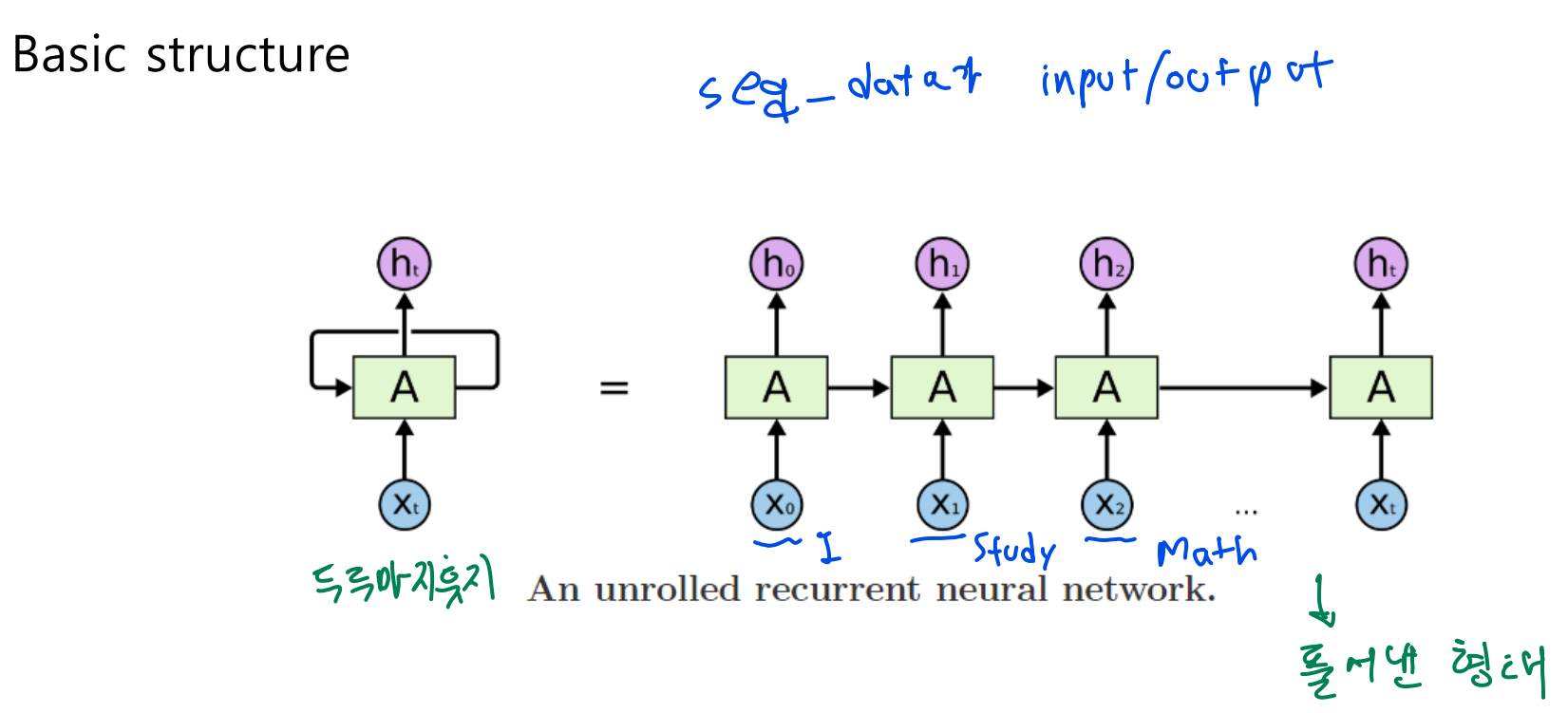

- 매 time step마다 같은 weight를 공유한다.
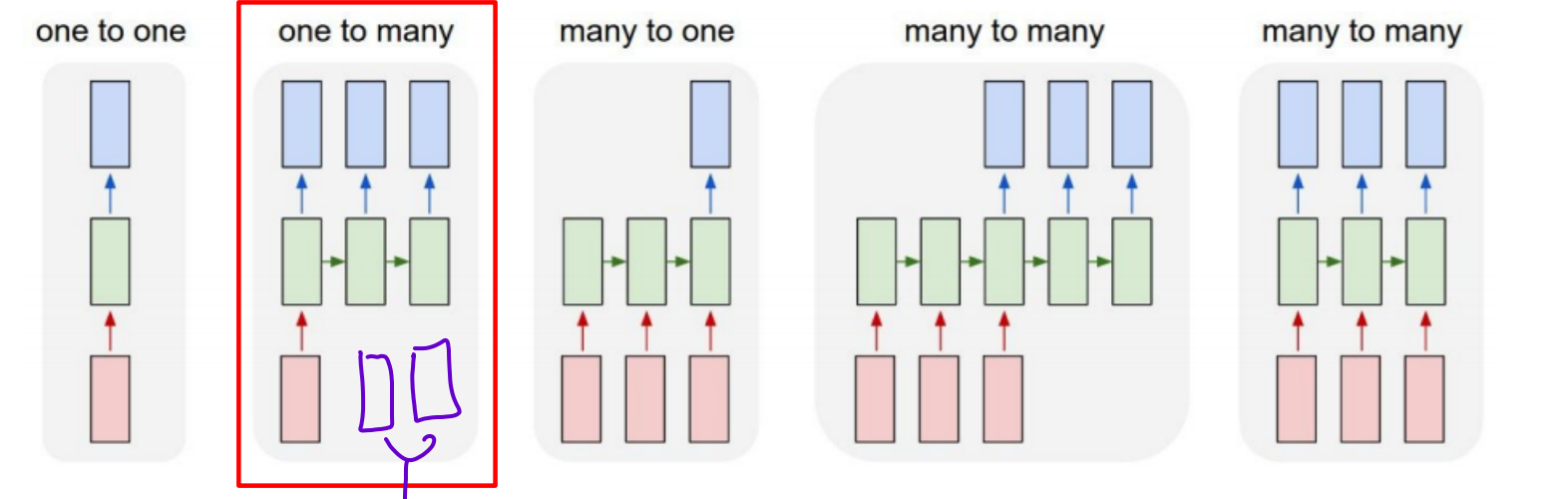
Types of RNNs
- 문제점: Bottleneck problem
[NLP]LSTM and GRU
LSTM
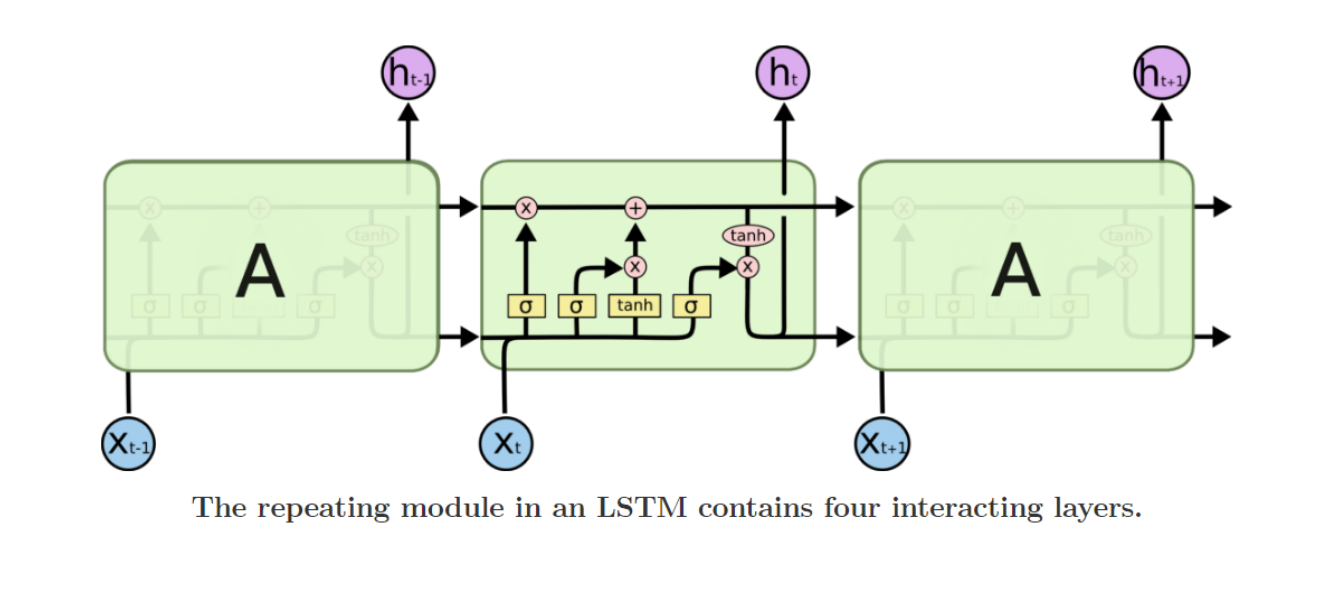
- Core Idea: pass cell state information straightly without any transformation
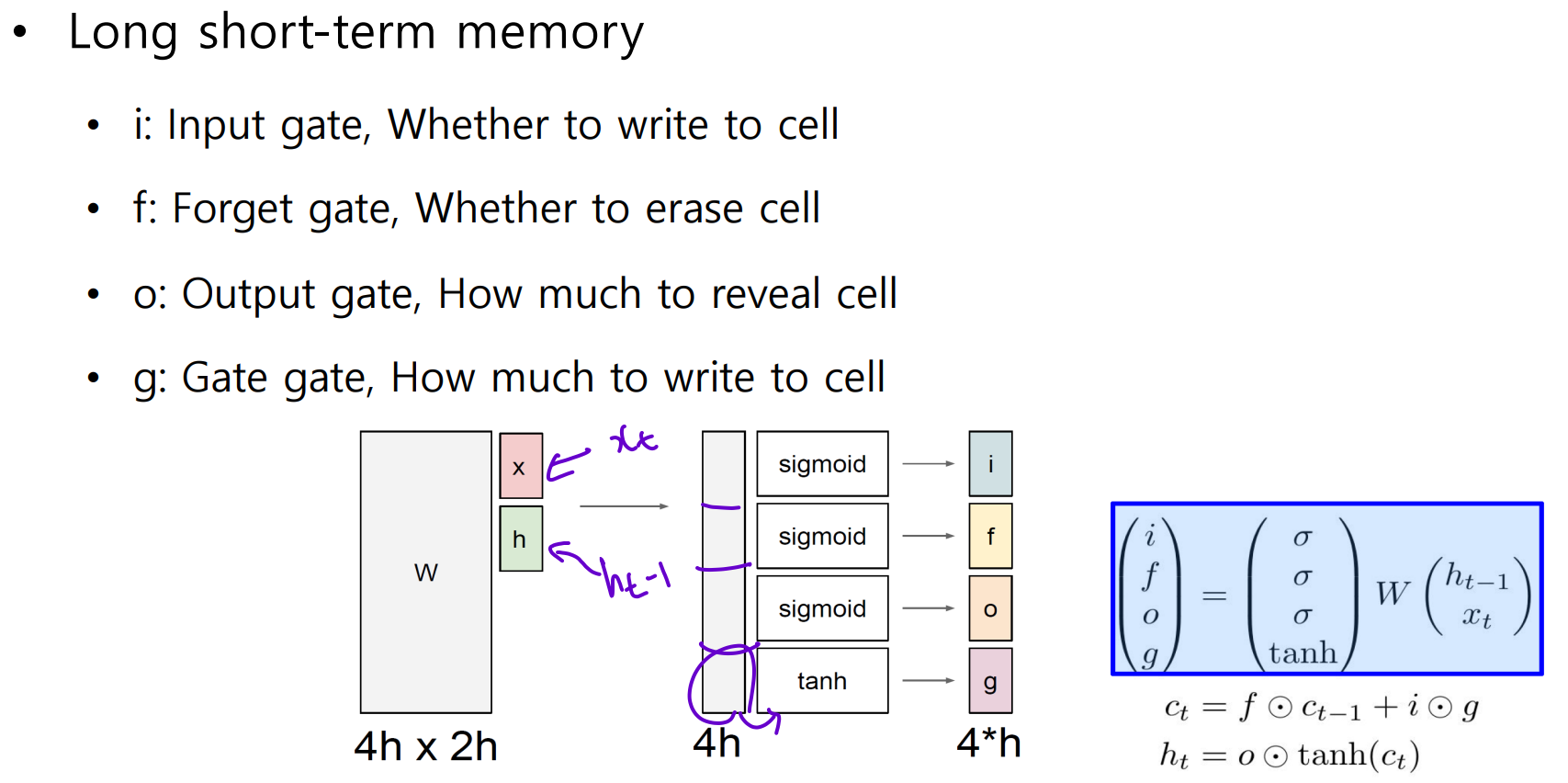
Summary on RNN/LSTM/GRU
- RNNs allow a lot of flexibility in architecture design
- Vanilla RNNs are simple but don’t work very well
- Backward flow of gradients in RNN can explode or vanish
- Common to use LSTM or GRU: their additive interactions improve gradient flow
2.과제 수행 과정/결과물 정리
[필수과제 1] 완료
3.피어 세션
학습 내용 공유
1.강의 내용 및 심화내용 토론
Q) "매 time step마다 rnn 모델을 정의하는 파라미터 w는 모든 time step에서 동일한 값을 공유한다"라는데 정확한 개념을 잘 모르겠어요.
A)같은 의미를 담지만 단어의 배열이 다른 문장 2개를 예시로 들어보겠습니다., 1.'On Monday, it was snowing' 2.'It was snowing on Monday'. 같은 weight를 공유함으로 문장별로 각 step에서 새롭게 training할 필요가 없게됩니다. hidden layer가 2개 이상인 경우에선 각 layer마다 주어진 weight값은 다르다고 합니다.
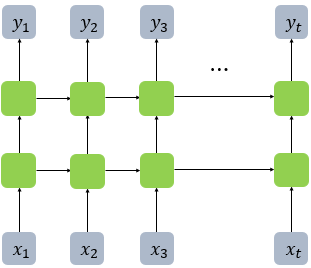
Q)one to many에서 두번째, 세번째 입력값을 크기는 같지만 0으로 채워진 값을 넣는다고 하는데 h_t 계산하기 위해서 필요한 것 일까요? 굳이 0을 넣어주는 이유가 있을까요??
A)time step을 뜻하는 index t는 one-to-many의 경우 output seq 길이로 정의되므로(many-to-one의 경우는 input seq의 길이로 정의) 길이를 맞추기 위해 일반적으로 value가 0인 vector를 추가적으로 넣습니다.(단, 꼭 value가 0일 필요는 없음)
4.학습회고
RNN/LSTM/GRU에 대해서는 어느 정도 알고 있다고 생각했었는데, 실습/과제/피어세션을 통해 확실하게 알게 되었습니다.
특히, 피어세션 중 나눴던 강의내용을 통해 스쳐지나간 부분들을 확실하게 알 수 있었습니다.
