1.강의 내용
[NLP]Advanced Self-supervised Pre-training Models
GPT-2
- Language Models are Unsupervised Multi-task Learners
1.Just a really big transformer LM
2.Trained on 40GB of text
2-1)Quite a bit of effort going into making sure the dataset is good quality
2-2)Take webpages from reddit links with high karma
3.Language model can perform down-stream tasks in a zero-shot setting – without any parameter or architecture modification
- Motivation
The Natural Language Decathlon: Multitask Learning as Question Answering
ex)Bryan McCann, Nitish Shirish Keskar, Caiming Xiong, Richard Socher
- Datasets
1.A promising source of diverse and nearly unlimited text is web scrape such as common crawl
2.Preprocess
2-1)Byte pair encoding (BPE)
2-2)Minimal fragmentation of words across multiple vocab tokens
- Model
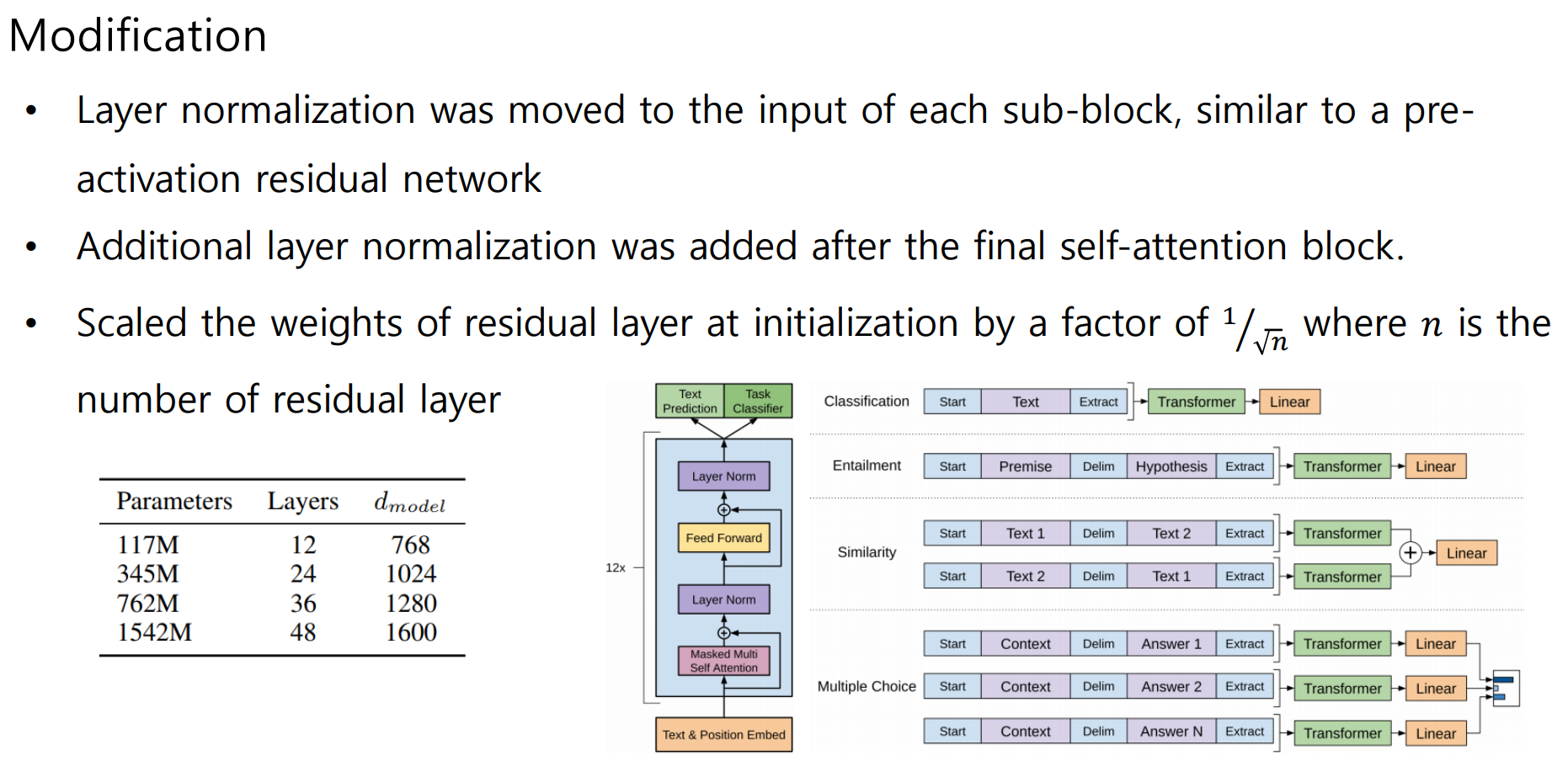
- Question Answering
Use conversation question answering dataset(CoQA)
• Achieved 55 F1 score, exceeding the performance 3 out of 4 baselines
without labeled dataset
• Fine-tuned BERT achieved 89 F1 performance
- Translation

GPT-3
- Language Models are Few-Shot Learners
1.Scaling up language models greatly improves task-agnostic, few-shot performance
2.An autoregressive language model with 175 billion parameters in the few-shot setting
3.96 Attention layers, Batch size of 3.2M
4.Zero-shot performance improves steadily with model size
5.Few-shot performance increases more rapidly

- A Lite BERT for Self-supervised Learning of Language Representations
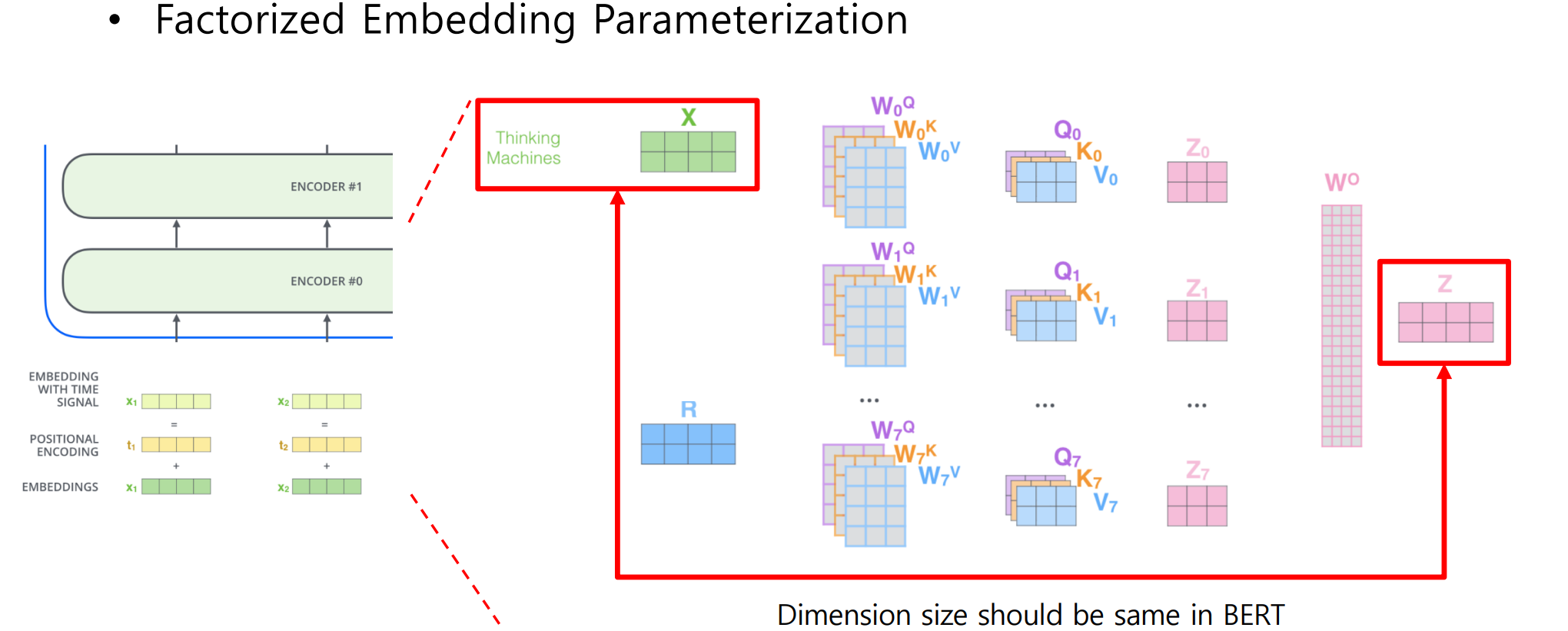
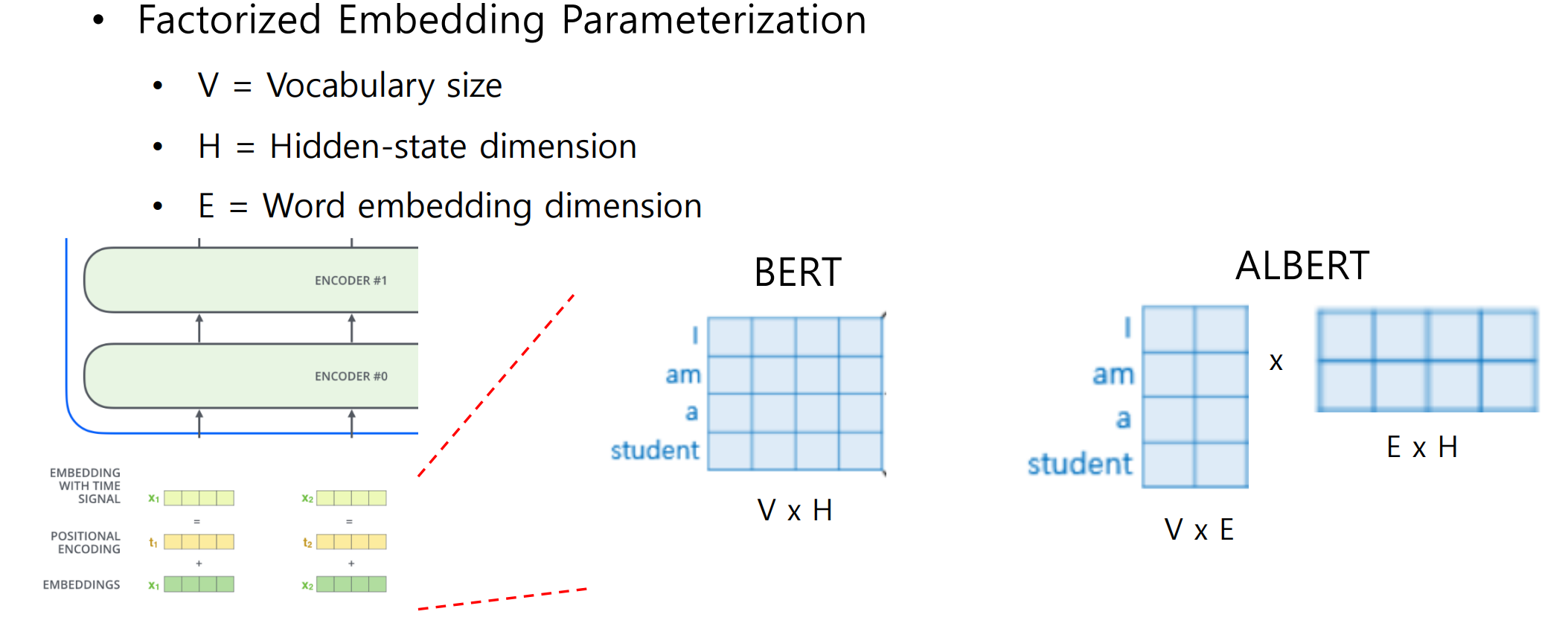
2.과제 수행 과정/결과물 정리
진행 x
3.피어 세션
학습 내용 공유
1.강의 내용 및 심화내용 토론
진행 X
2.과제 내용 및 심화내용 토론
진행 X
4.학습회고
2주간 같이 한 팀원들과 각자 부스트캠프 중 및 이후 계획에 대해 서로 얘기를 나누는 시간을 가졌습니다. 다들 좋으신 분들인데 2주밖에 같이 하지 못 한 것이 참 아쉽습니다. 다만 그중 많은 분들이 다음 기수도 같이 하게 되었습니다. 추석연휴기간 동안 2주간의 u-stage 내용을 복습하며 한동안 쓰지 않았던 git/vs code 등을 다루려 합니다.
