1.강의 내용
[NLP]Self-supervised Pre-training Models
Recent Trends
1.Transformer model and its self-attention block has become a general-purpose sequence(or set) encoder and decoder in recent NLP applications as well as in other areas.
2.Training deeply stacked Transformer models via a self-supervised learning framework has significantly advanced various NLP tasks through transferlearning, e.g., BERT, GPT-3, XLNet, ALBERT, RoBERTa, Reformer, T5, ELECTRA…
3.Other applications are fast adopting the self-attention and Transformer architecture as well as self-supervised learning approach,
e.g., recommender systems, drug discovery, computer
vision, …
4.As for natural language generation, self-attention models still requires a greedy decoding of words one at a time.
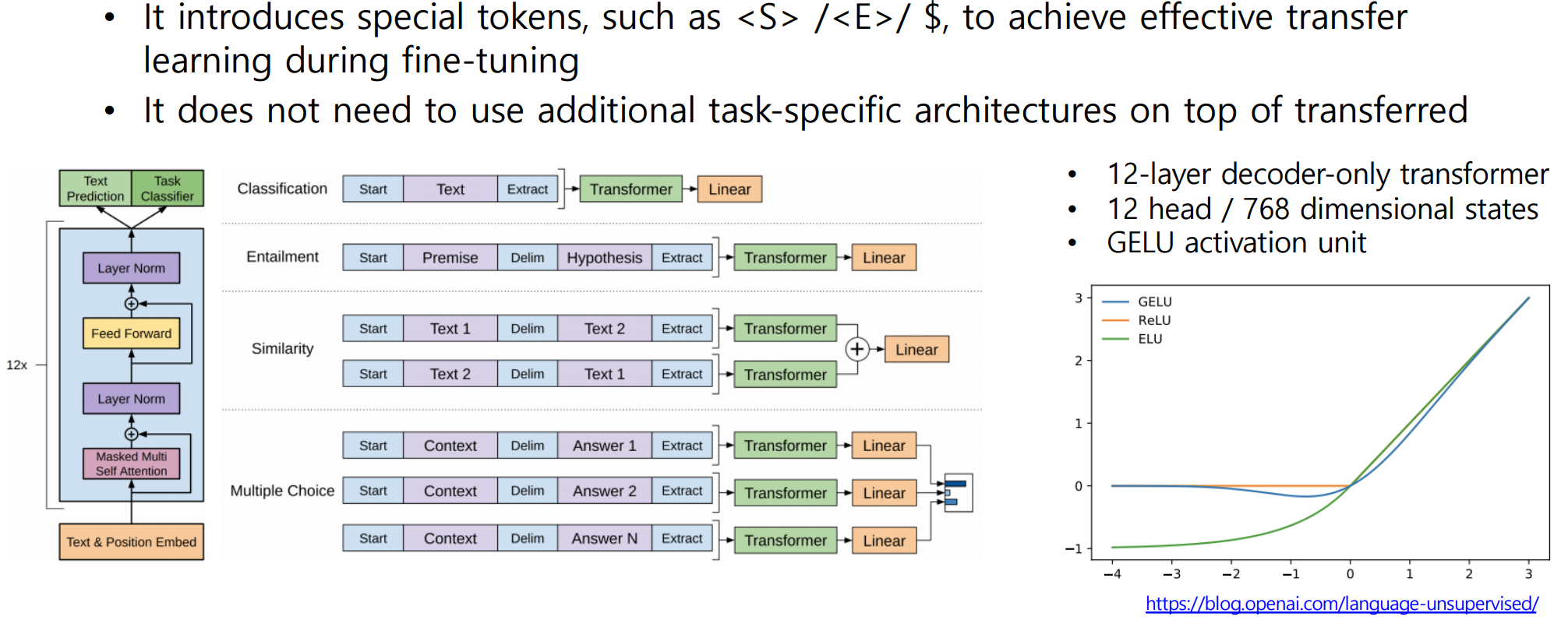
GPT-1
- Improving Language Understanding by Generative Pre-training
BERT
- Pre-training of Deep Bidirectional Transformers for Language Understanding
1.Learn through masked language modeling task
2.Use large-scale data and large-scale model
- Masked Language Model
1.Motivation
Language models only use left context or right context, but language understanding is
bi-directional
2.Problem: Words can “see themselves” (cheating) in a bi-directional encoder
- Pre-training Tasks in BERT

1.Masked Language Model
1)How to
Mask out k% of the input words, and then predict the masked words
e.g., use k= 15%

Too little masking : Too expensive to train
Too much masking : Not enough to capture context
2)Problem - Solution
prob: Mask token never seen during fine-tuning
sol:

2.Next Sentence Predictio

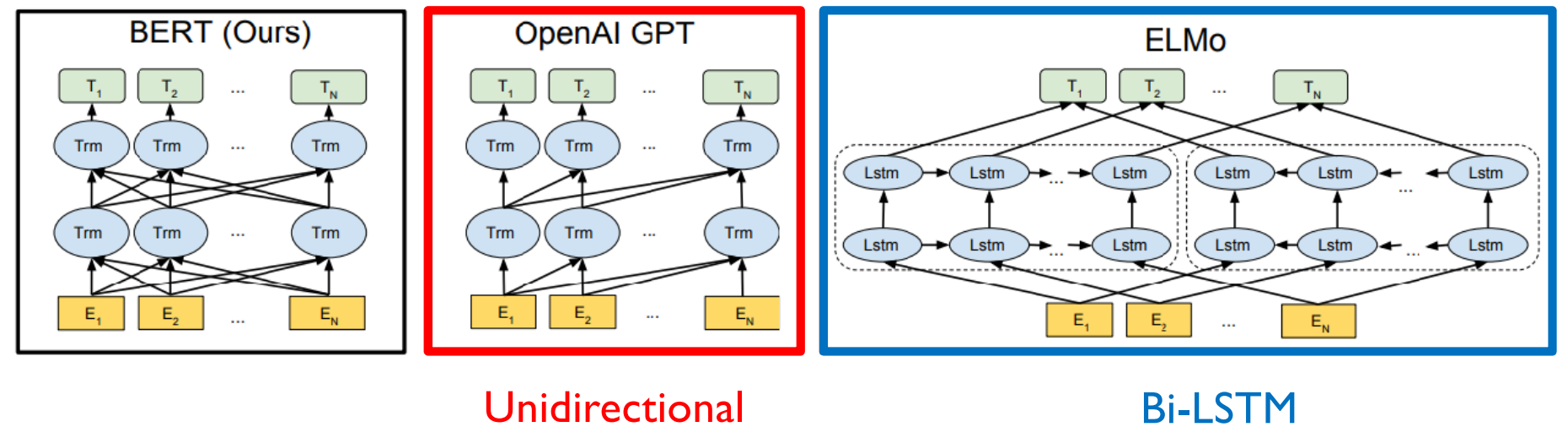
BERT vs GPT

2.과제 수행 과정/결과물 정리
진행 x
3.피어 세션
학습 내용 공유
1.강의 내용 및 심화내용 토론
Q1)BERT의 Masked Language Model의 단점은 무엇이 있을까요? 사람이 실제로 언어를 배우는 방식과의 차이를 생각해보며 떠올려봅시다.
A1)문맥 파악에 중요한 역할을 하는 단어나 모델이 한번도 본 적이 없는 단어를 마스킹하면 모델 입장에서 학습에 어려움이 있을 것 같습니다.
2.과제 내용 및 심화내용 토론
진행 X
4.학습회고
새로운 팀원들과 줌미팅을 하며 공부는 계획의 절반 정도를 한 것 같습니다. 남은 것은 내일 마저 마무리 할 예정입니다.
