1.강의 내용
[DL Basic]Optimization
-
Bagging vs Boosting
Bagging: Multiple models are being trained with boostrappinng. ex) Ensemble
Boosting: It focuses on those specific training samples that are hard to classify. -
Gradient Descent
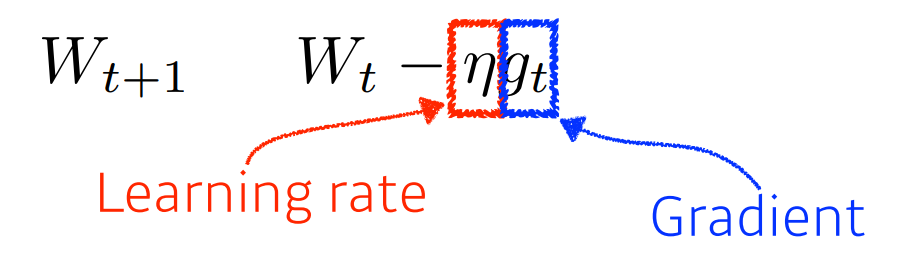
First-order iterative optimization algorithm for finding a local minimum of a differentiable function. -
Gradient Descent Methods
Stochastic gradient descent, Momentum, Nesterov accelerated gradient, Adagrad, Adadelta, RMSprop, Adam
이 중 Adam에 대해 좀더 살펴보면,
Adam: Adaptive Moment Estimation leverages both past gradients and squared gradients
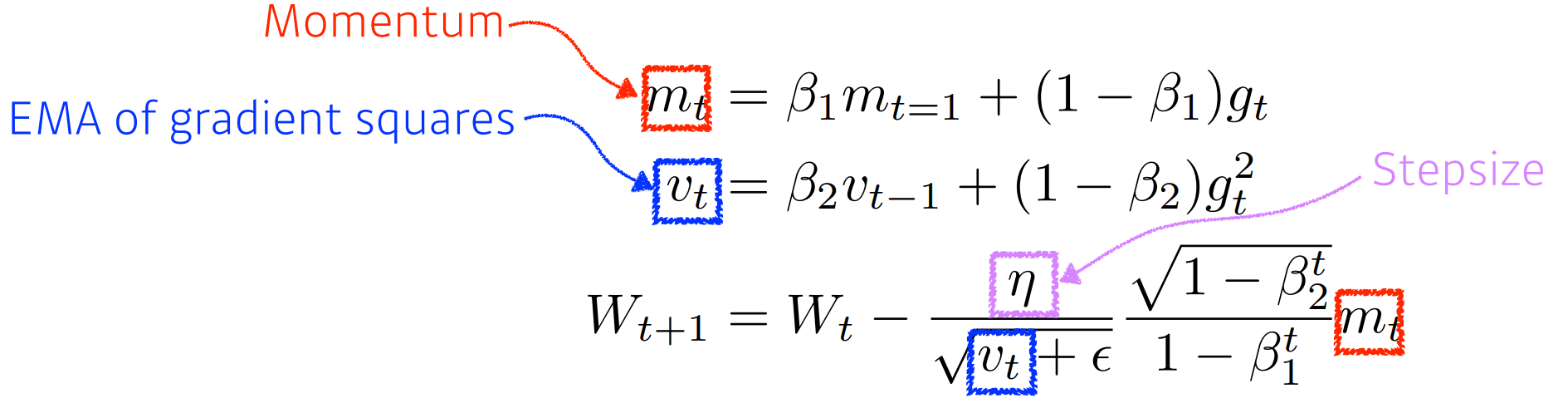
Adam effectively combines momentum with adaptive learning rate approach. -
Regularization
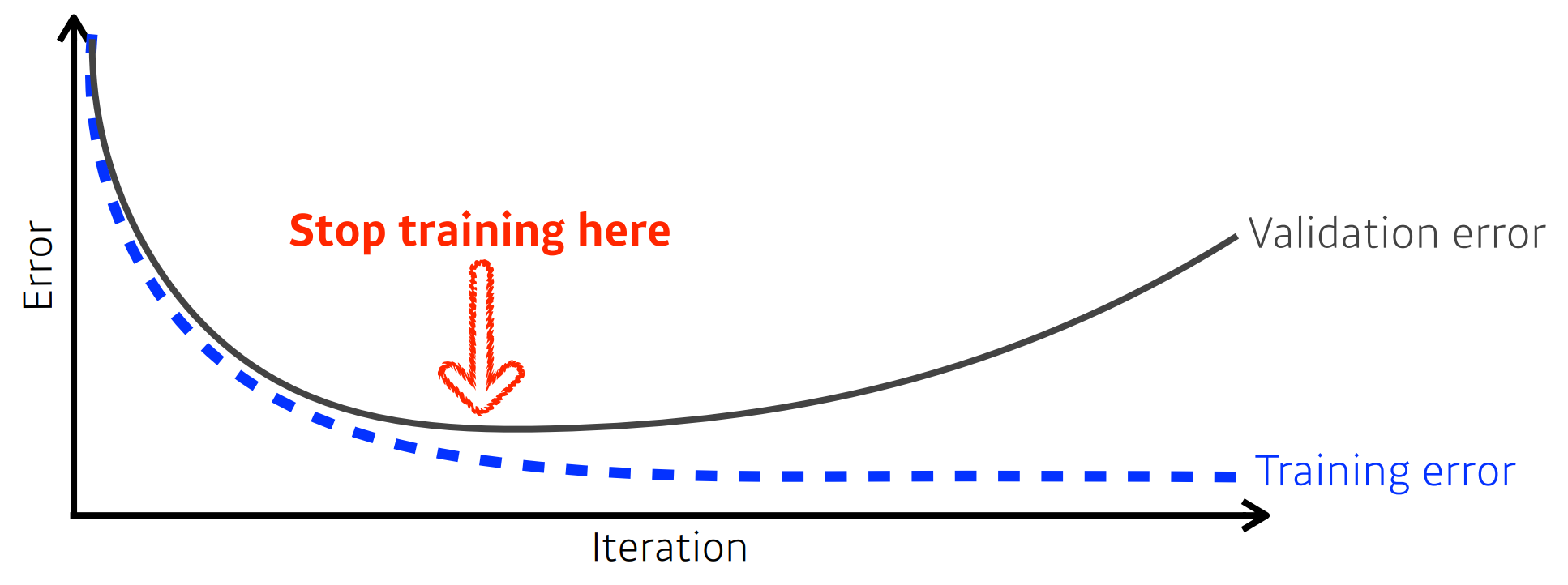
1)Early Stopping
2)Parameter Norm Penalty
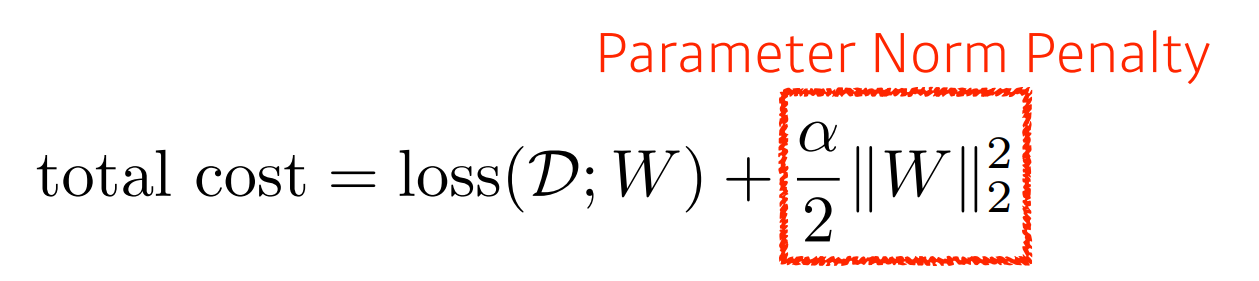
3)Data Augmentation
4)Noise robustness : Add random noises inputs or weights.
5)Label smoothing
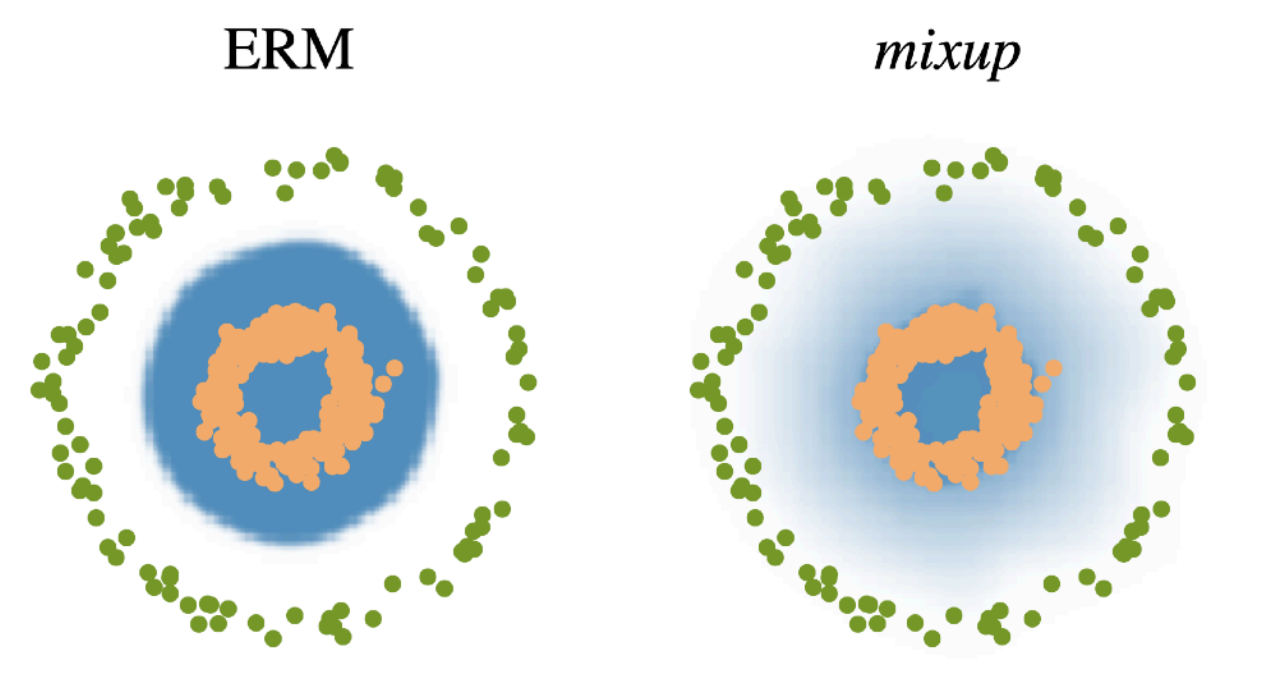
Mix-up constructs augmented training examples by mixing both input and output of two randomly selected training data.
CutMix constructs augmented training examples by mixing inputs with cut and paste and outputs with soft labels of two randomly selected training data.
6)Dropout : In each forward pass, randomly set some neurons to zero.
7)Batch normalization
Batch normalization compute the empirical mean and variance independently for each dimension (layers) and normalize. There are different variances of normalizations.
- 실습
필수과제 2 내용
2.과제 수행 과정/결과물 정리
- Define MLP model
class Model(nn.Module):
def __init__(self,name='mlp',xdim=1,hdims=[16,16],ydim=1):
super(Model, self).__init__()
self.name = name
self.xdim = xdim
self.hdims = hdims
self.ydim = ydim
self.layers = []
prev_hdim = self.xdim
for hdim in self.hdims:
self.layers.append(nn.Linear(
prev_hdim, hdim, bias = True
))
self.layers.append(nn.Tanh()) # activation
prev_hdim = hdim
# Final layer (without activation)
self.layers.append(nn.Linear(prev_hdim,self.ydim,bias=True))
# Concatenate all layers
self.net = nn.Sequential()
for l_idx,layer in enumerate(self.layers):
layer_name = "%s_%02d"%(type(layer).__name__.lower(),l_idx)
self.net.add_module(layer_name,layer)
self.init_param() # initialize parameters
def init_param(self):
for m in self.modules():
if isinstance(m,nn.Conv2d): # init conv
nn.init.kaiming_normal_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m,nn.Linear): # lnit dense
nn.init.kaiming_normal_(m.weight)
nn.init.zeros_(m.bias)
def forward(self,x):
return self.net(x)3.피어 세션
학습 내용 공유
1.과제 코드 리뷰
- 필수과제 2 특성상 스킵
1.강의 내용 및 심화내용 토론
[DL Basic]Optimization
3.논문 리뷰
4.학습회고
이고잉 님의 Git 특강을 들었습니다.
Git은 확실히 다루기 어렵지만, 들으면서 왜 개발자의 필수역량인지 알 수 있었습니다.
논문 리뷰를 통해 한 모델이 나오기까지의 과정을 간략하게 알 수 있었습니다.
day 9에 제 논문 발표가 있을 예정인데 처음인만큼 시간을 많이 할애하여 볼 예정입니다.
