1.강의 내용
[DL Basic]Sequential Models - RNN
- Sequential Model
1)Naive sequence Model
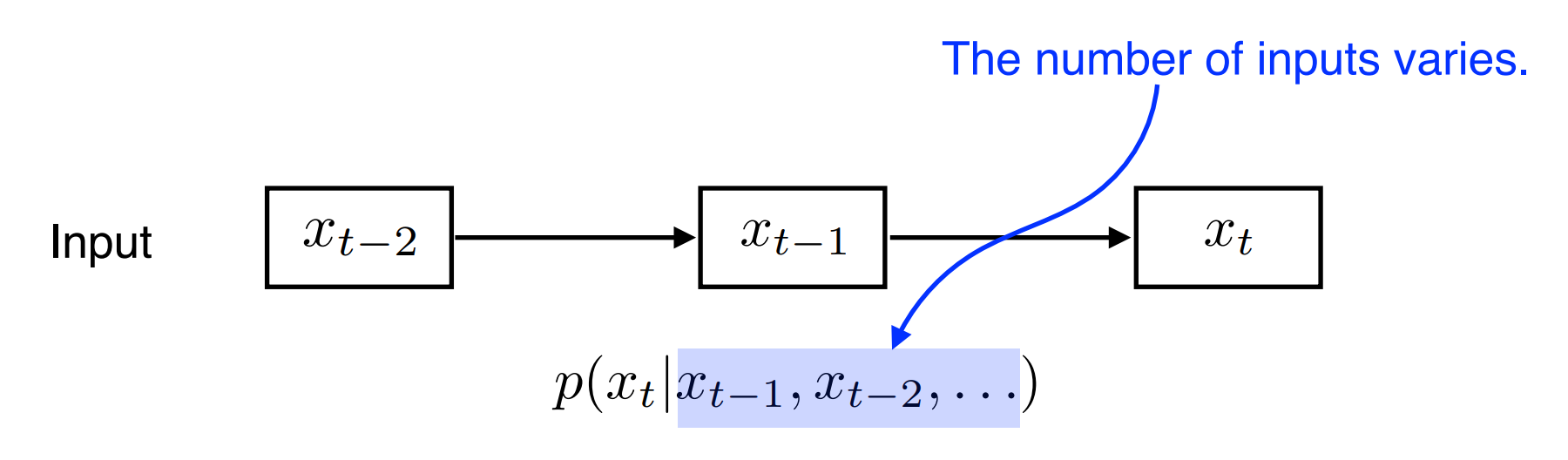
2)Autogressive model
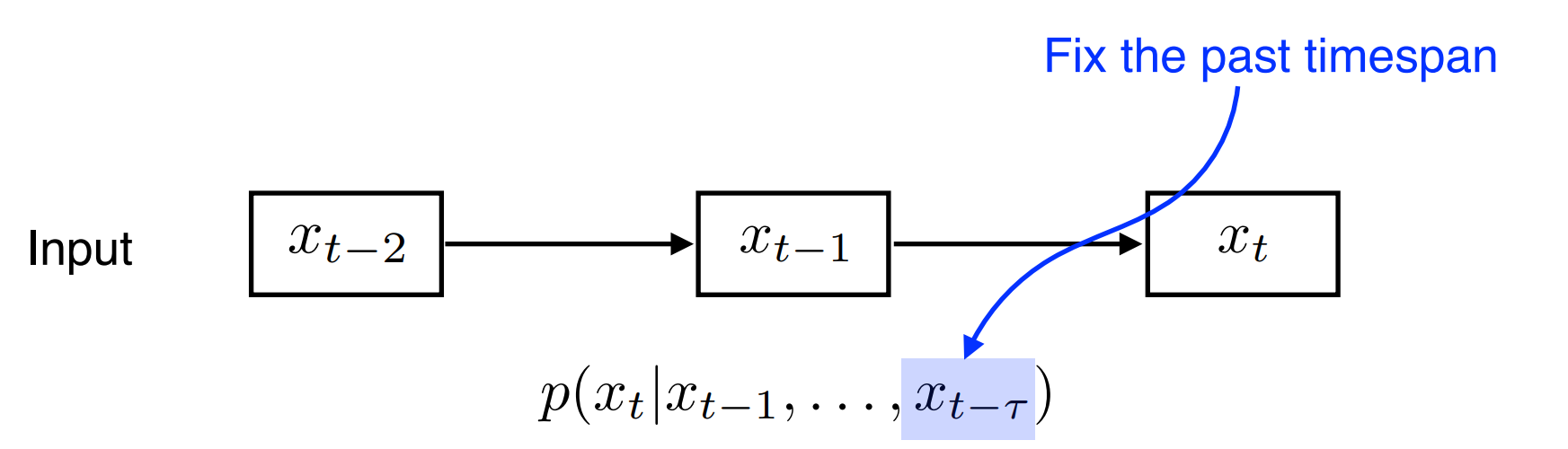
3)Markov model(1st order autoregressive model)
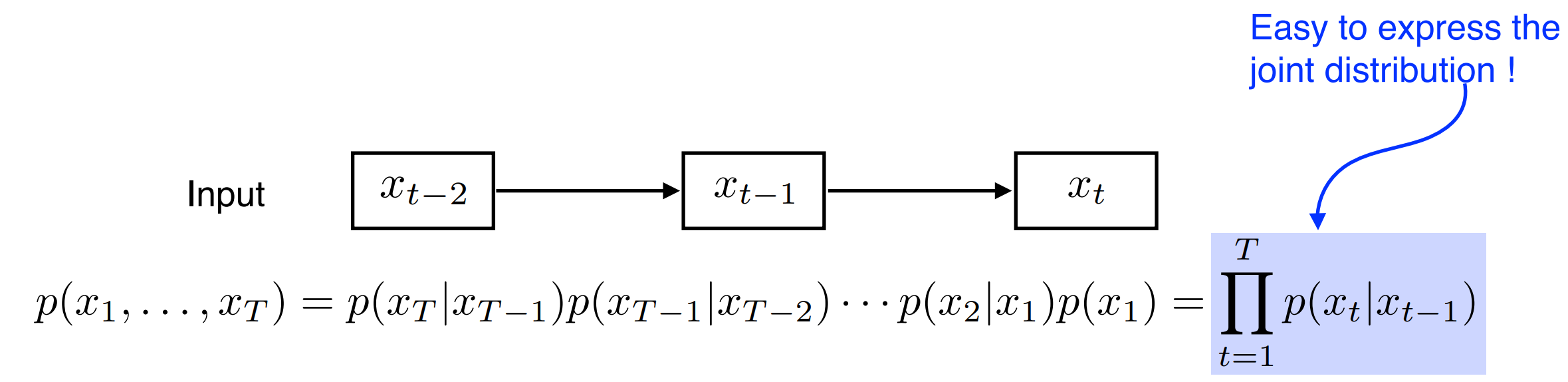
4)Latent autoregressive model
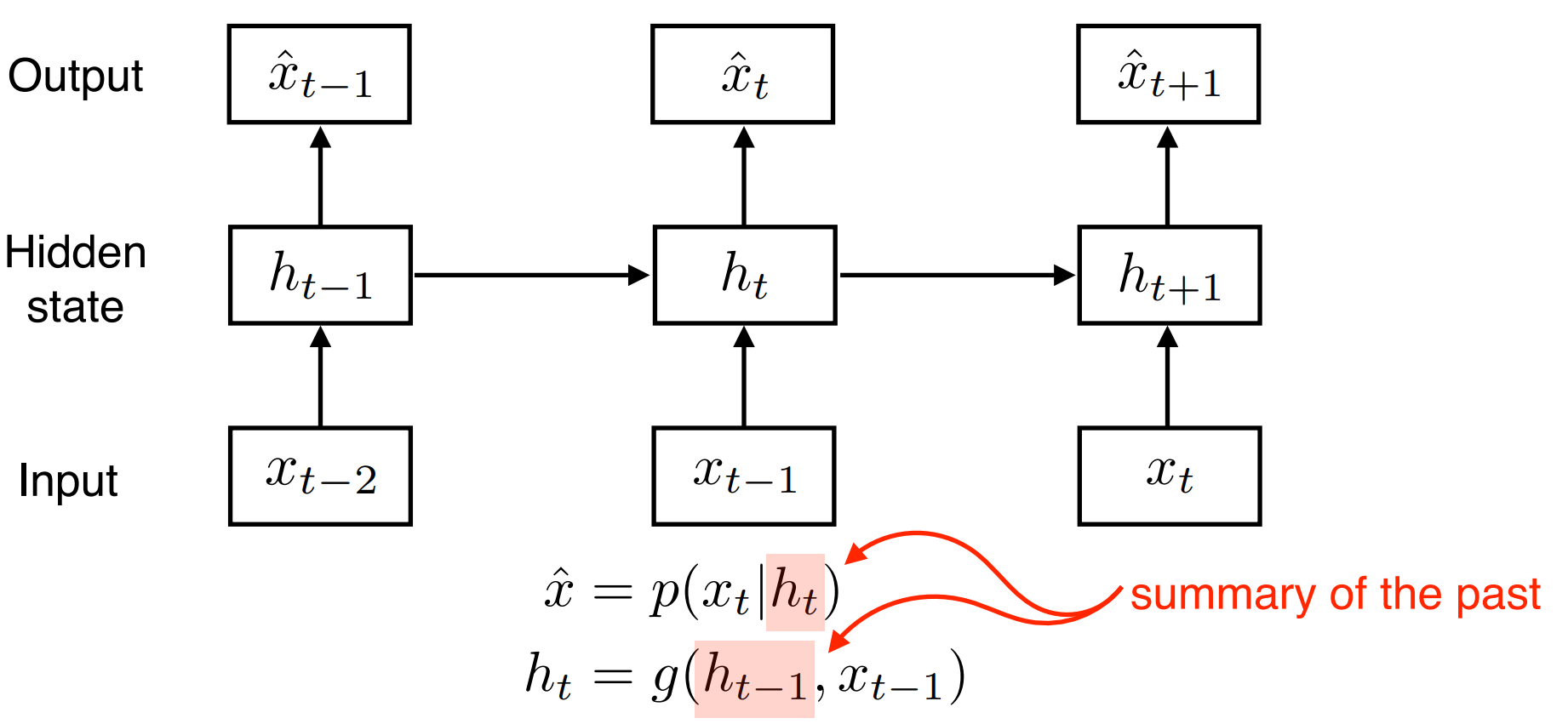
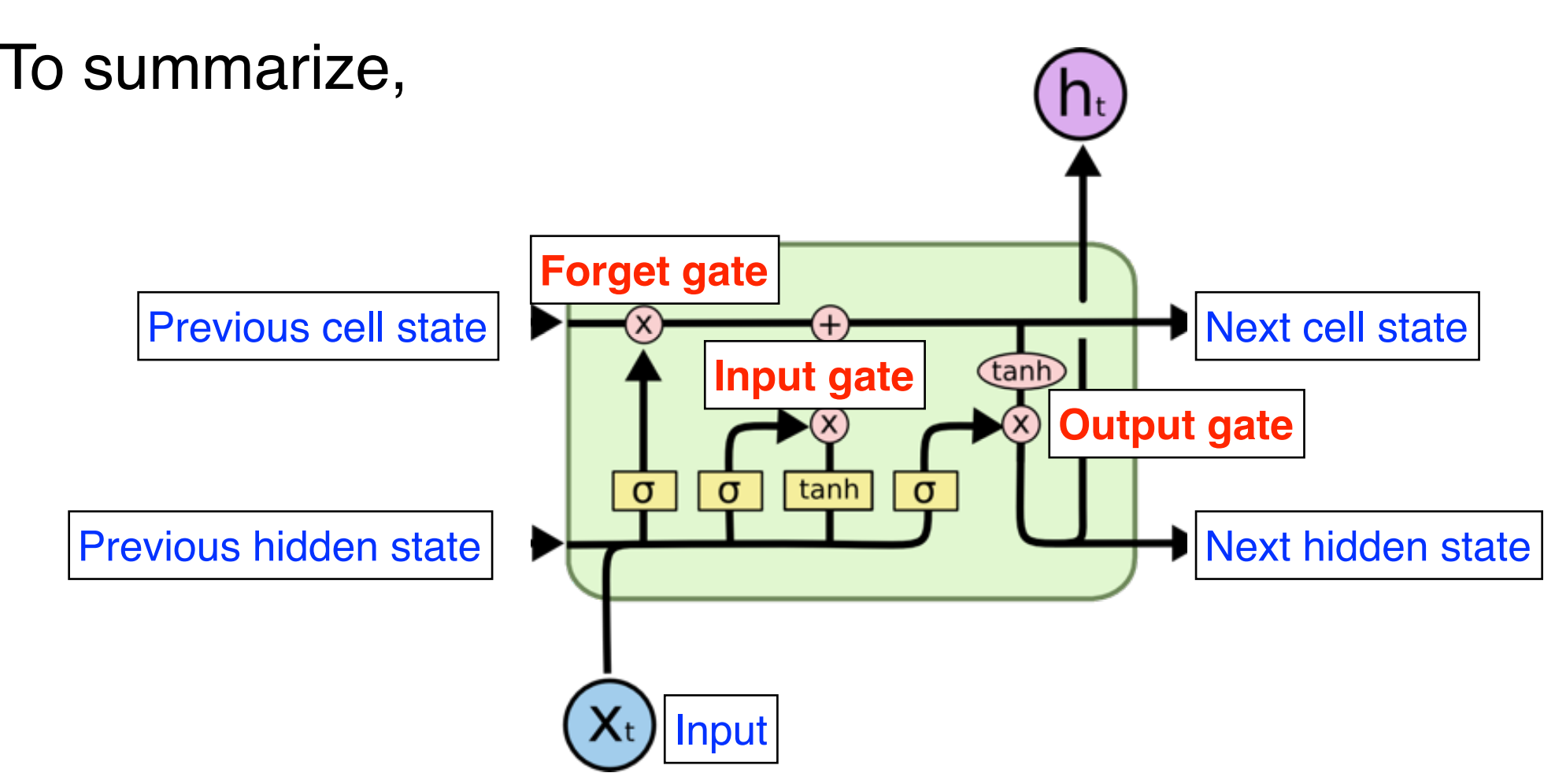
- RNN
(Summarize)
[DL Basic]Sequential Models - Transformer
[참조][Attention is All you need](https://arxiv.org/abs/1706.03762)
- 실습
필수과제 4,5 내용
2.과제 수행 과정/결과물 정리
- Define LSTM model
class RecurrentNeuralNetworkClass(nn.Module):
def __init__(self,name='rnn',xdim=28,hdim=256,ydim=10,n_layer=3):
super(RecurrentNeuralNetworkClass,self).__init__()
self.name = name
self.xdim = xdim
self.hdim = hdim
self.ydim = ydim
self.n_layer = n_layer # K
self.rnn = nn.LSTM(
input_size=self.xdim,hidden_size=self.hdim,num_layers=self.n_layer,batch_first=True)
self.lin = nn.Linear(self.hdim,self.ydim)
def forward(self,x):
# Set initial hidden and cell states
h0 = torch.zeros(
self.n_layer, x.size(0), self.hdim
).to(device)
c0 = torch.zeros(
self.n_layer, x.size(0), self.hdim
).to(device)
# RNN
rnn_out,(hn,cn) = self.rnn(x, (h0,c0))
# x:[N x L x Q] => rnn_out:[N x L x D]
# Linear
out = self.lin(
rnn_out[:,-1 : ]
).view([-1,self.ydim])
return out
R = RecurrentNeuralNetworkClass(
name='rnn',xdim=28,hdim=256,ydim=10,n_layer=2).to(device)
loss = nn.CrossEntropyLoss()
optm = optim.Adam(R.parameters(),lr=1e-3)- Define mha model(Multi-Headed Attention)
class MultiHeadedAttention(nn.Module):
def __init__(self,d_feat=128,n_head=5,actv=F.relu,USE_BIAS=True,dropout_p=0.1,device=None):
"""
:param d_feat: feature dimension
:param n_head: number of heads
:param actv: activation after each linear layer
:param USE_BIAS: whether to use bias
:param dropout_p: dropout rate
:device: which device to use (e.g., cuda:0)
"""
super(MultiHeadedAttention,self).__init__()
if (d_feat%n_head) != 0:
raise ValueError("d_feat(%d) should be divisible by b_head(%d)"%(d_feat,n_head))
self.d_feat = d_feat
self.n_head = n_head
self.d_head = self.d_feat // self.n_head
self.actv = actv
self.USE_BIAS = USE_BIAS
self.dropout_p = dropout_p # prob. of zeroed
self.lin_Q = nn.Linear(self.d_feat,self.d_feat,self.USE_BIAS)
self.lin_K = nn.Linear(self.d_feat,self.d_feat,self.USE_BIAS)
self.lin_V = nn.Linear(self.d_feat,self.d_feat,self.USE_BIAS)
self.lin_O = nn.Linear(self.d_feat,self.d_feat,self.USE_BIAS)
self.dropout = nn.Dropout(p=self.dropout_p)
def forward(self,Q,K,V,mask=None):
"""
:param Q: [n_batch, n_Q, d_feat]
:param K: [n_batch, n_K, d_feat]
:param V: [n_batch, n_V, d_feat] <= n_K and n_V must be the same
:param mask:
"""
n_batch = Q.shape[0]
Q_feat = self.lin_Q(Q)
K_feat = self.lin_K(K)
V_feat = self.lin_V(V)
# Q_feat: [n_batch, n_Q, d_feat]
# K_feat: [n_batch, n_K, d_feat]
# V_feat: [n_batch, n_V, d_feat]
# Multi-head split of Q, K, and V (d_feat = n_head*d_head)
Q_split = Q_feat.view(n_batch, -1, self.n_head, self.d_head).permute(0, 2, 1, 3)
K_split = K_feat.view(n_batch, -1, self.n_head, self.d_head).permute(0, 2, 1, 3)
V_split = V_feat.view(n_batch, -1, self.n_head, self.d_head).permute(0, 2, 1, 3)
# Q_split: [n_batch, n_head, n_Q, d_head]
# K_split: [n_batch, n_head, n_K, d_head]
# V_split: [n_batch, n_head, n_V, d_head]
# Multi-Headed Attention
d_K = K.size()[-1] # key dimension
scores = torch.matmul(Q_split, K_split.permute(0, 1, 3, 2)) / np.sqrt(d_K)
if mask is not None:
scores = scores.masked_fill(mask==0,-1e9)
attention = torch.softmax(scores,dim=-1)
x_raw = torch.matmul(self.dropout(attention),V_split) # dropout is NOT mentioned in the paper
# attention: [n_batch, n_head, n_Q, n_K]
# x_raw: [n_batch, n_head, n_Q, d_head]
# Reshape x
x_rsh1 = x_raw.permute(0,2,1,3).contiguous()
# x_rsh1: [n_batch, n_Q, n_head, d_head]
x_rsh2 = x_rsh1.view(n_batch,-1,self.d_feat)
# x_rsh2: [n_batch, n_Q, d_feat]
# Linear
x = self.lin_O(x_rsh2)
# x: [n_batch, n_Q, d_feat]
out = {'Q_feat':Q_feat,'K_feat':K_feat,'V_feat':V_feat,
'Q_split':Q_split,'K_split':K_split,'V_split':V_split,
'scores':scores,'attention':attention,
'x_raw':x_raw,'x_rsh1':x_rsh1,'x_rsh2':x_rsh2,'x':x}
return out
# Self-Attention Layer
n_batch = 128
n_src = 32
d_feat = 200
n_head = 5
src = torch.rand(n_batch,n_src,d_feat)
self_attention = MultiHeadedAttention(
d_feat=d_feat,n_head=n_head,actv=F.relu,USE_BIAS=True,dropout_p=0.1,device=device)
out = self_attention.forward(src,src,src,mask=None)
Q_feat,K_feat,V_feat = out['Q_feat'],out['K_feat'],out['V_feat']
Q_split,K_split,V_split = out['Q_split'],out['K_split'],out['V_split']
scores,attention = out['scores'],out['attention']
x_raw,x_rsh1,x_rsh2,x = out['x_raw'],out['x_rsh1'],out['x_rsh2'],out['x']3.피어 세션
학습 내용 공유
1.과제 코드 리뷰
- 필수과제 4,5 특성상 스킵
1.강의 내용 및 심화내용 토론
[DL Basic]Sequential Models - RNN
[DL Basic]Sequential Models - Transforemr
3.논문 리뷰
4.학습회고
첫 논문리뷰를 하였던만큼 부족한 점도 많았지만 조원분들께서 잘 들어주셔서 감사했습니다. 이후 과제 해설강의를 들으며 과제 중 궁금했던 부분이 해결되었고, 이후 멘토링 시간을 통해 2주뒤부터 있을 이미지 분류 대회를 어떻게 준비해야할 지 알 수 있는 시간을 가졌습니다.

인지간지