🍅주제
한국어 혐오 발언 탐지 AI 모델 개발기
1. 개발 환경
프로그래밍 언어:
Python
개발 환경:Google Colab
프레임워크:TensorFlow및Keras
2. 개발 배경
한이음 공모전의 주제인
실시간 인터넷 방송 서비스 보조 프로그램을 제작하기 위해서는 AI가 필요했다. 기존의 자연어 처리 모델로 자주 쓰이는BERT모델은 성능은 좋지만 모델이 무겁다는 단점이 있어 우리가 하려는 프로젝트와는 맞지 않았다. 우리는 실시간 채팅을 AI를 이용하여 바로 처리해야 하기 때문에 더욱 가볍고 빠른 모델이 필요했다. 따라서 상대적으로 빠르고 가벼운CNN모델을 채용하였다
CNN을 선택한 이유 논문
3. 나의 역할
한이음 공모전을 하게 되며 처음에는 웹 프론트엔드 역할을 맡게되었다. 개발 초기인 설계 단계에서 다 같이 시작한 AI 모델 개발 중 나의 모델이 가장 좋은 성능을 보였고, AI 학습 쪽으로 역할을 맡게 되었다.
4. 데이터셋
aihub의텍스트 윤리검증 데이터와 각종 커뮤니티 사이트에서 크롤링한 인터넷 댓글을 직접 만든 욕설 데이터와 혼합하여 사용했다.
데이터는 TSV 파일 형식으로 제공되었으며, 이를JSON형식으로 변환하여 처리했다. 변환된 JSON 형식은 다음과 같다.[ { "id": "615281b0aab10bca18a468e2", "sentences": [ { "id": "615281b0aab10bca18a468e2-1", "speaker": 1, "origin_text": "부랴부랴 왔는데 아무도 안왔네. 시간개념들이 없네", "text": "부랴부랴 왔는데 아무도 안왔네. 시간개념들이 없네", "types": ["CENSURE"], "is_immoral": true, "intensity": 2.0, "intensity_sum": 10, "votes": [ { "intensity": "IRRITABLE", "voter": { "gender": "MALE", "age": 20 } } ], "frame_id": 48327, "mapped_slots": [ {"slot": "V1", "token": "오다", "lu_id": 19549}, {"slot": "N1", "token": "아무", "lu_id": 12468} ] } ] } ]
5. 첫 모델 코드
최종 버전이 아닌 처음 정상적으로 학습된 코드, 문제점이 많이 존재했다
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, Conv1D, GlobalMaxPooling1D, Dense
from tensorflow.keras.callbacks import ModelCheckpoint
import pickle
# CNN 모델 생성
embedding_dim = 100
model = Sequential()
model.add(Embedding(max_features, embedding_dim, input_length=maxlen))
model.add(Conv1D(128, 5, activation='relu'))
model.add(GlobalMaxPooling1D())
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# 모델 구조 확인
model.summary()
# 체크포인트 콜백 설정
checkpoint_path = './checkpoint/model_checkpoint.h5'
checkpoint_callback = ModelCheckpoint(checkpoint_path, monitor='val_accuracy', verbose=1, save_best_only=True, mode='max')
# 모델 학습
epochs = 20
batch_size = 32
history = model.fit(X_train, y_train, epochs=epochs, batch_size=batch_size, validation_data=(X_val, y_val), callbacks=[checkpoint_callback])
# 토크나이저 저장
with open('./checkpoint/tokenizer.pickle', 'wb') as handle:
pickle.dump(tokenizer, handle, protocol=pickle.HIGHEST_PROTOCOL)
# 모델 평가
loss, accuracy = model.evaluate(X_val, y_val)
print(f'Loss: {loss}, Accuracy: {accuracy}')🍅문제점 및 해결방법
첫 모델 개발에 생긴 문제점
AI쪽으로는 관련 개발을 한 적이 없다보니 처음부터 공부를 해야했다. 데이터 전처리부터 어떻게 학습을 시키고 어디서 학습을 해야하는지 등등.
AI 모델을 개발하고 학습하는데 성능 좋은 GPU가 있으면 좋지만 나의 경우 노트북으로만 하기 때문에구글 코랩에서 개발 및 학습을 진행하였다.처음 성공적으로 학습을 마친 모델에는 여러가지 문제점이 존재했다. 그 중 가장 대표적인 문제점들은 5가지가 있었다.
1. 데이터 전처리의 문제
2. 학습 속도의 느림 문제
3. 데이터 불균형의 문제
4. 데이터 부족함의 문제
5. 학습 결과의 부정확함총 5가지의 문제였지만 그 중 1번이 가장 큰 문제였다.
1. 전처리 문제 해결 방법
데이터 전처리가 가장 큰 문제인 이유는 간단했다. 이유는 한국어의 특징에 있었다.
예를 들어시발이라는 욕을ㅅ1ㅂㅅ@ㅂ시불18등 형태를 바꾸더라도 사람들에게는 욕설의 의미가 그대로 전달이 되기 때문이다.위 코드로 학습한 모델은 일반 욕설은 잘 잡아내지만 위 예시처럼 변형시킨 경우 잘 잡아내지 못 하였다.
나는 한국어의 특색인 형태를 변형해도 의미가 전달되는 것을 최대한 반영하여 전처리를 다시 진행하였다. 그 전처리 방법은 여러가지였지만 대표적인 것들은 이렇다.
- 기본적으로 한국어 입력값만 받아들여 특수문자 등이 중간에 삽입이 되면 제외하고 욕설을 읽는 방법
숫자 및 특수문자 변환: 숫자 0~9를영, 일, ... ,구이런식으로 발음으로 바꾸거나, 특수문자^을 한국어 자음ㅅ이나@를ㅇ으로 바꾸는 방법초성 기반 토큰화: 한글의 초성만을 추출하여 비속어의 다양한 변형을 탐지하는 방법n-gram 기반 토큰화: 띄어쓰기를 제거한 후 3-gram 및 4-gram 토큰화를 적용하여 문장 내 비속어 패턴을 더 세밀하게 분석하는 방법# 초성 변환 함수 def to_chosung(text): chosung_list = [ 'ㄱ', 'ㄲ', 'ㄴ', 'ㄷ', 'ㄸ', 'ㄹ', 'ㅁ', 'ㅂ', 'ㅃ', 'ㅅ', 'ㅆ', 'ㅇ', 'ㅈ', 'ㅉ', 'ㅊ', 'ㅋ', 'ㅌ', 'ㅍ', 'ㅎ' ] base_code, chosung_base, jongseong_base = 44032, 588, 28 result = [] for char in text: if '가' <= char <= '힣': char_code = ord(char) - base_code chosung_index = char_code // chosung_base result.append(chosung_list[chosung_index]) else: result.append(char) return ''.join(result) # 텍스트 전처리 함수 def preprocess_text(text, badword_model): # 숫자 -> 한글 치환 number_to_korean = {'0': '영', '1': '일', '2': '이', '3': '삼', '4': '사', '5': '오', '6': '육', '7': '칠', '8': '팔', '9': '구'} text = ''.join([number_to_korean.get(char, char) for char in text]) # 특수문자를 일반 문자로 치환 (예: '@' -> 'a', '!' -> 'i') text = text.replace('@', 'ㅇ').replace('!', 'i').replace('1', 'ㅣ').replace('^', 'ㅅ').replace('1', '일') # 초성 변환 chosung_text = to_chosung(text) # 띄어쓰기 제거 text_without_spaces = text.replace(" ", "") # n-gram 생성 (3-gram과 4-gram) ngrams = [] for n in [3, 4]: ngrams.extend([text_without_spaces[i:i+n] for i in range(len(text_without_spaces)-n+1)]) return " ".join([text.strip(), text_without_spaces, chosung_text, *ngrams])
2. 학습속도의 느림 해결 방법
이것은 학습에 GPU를 안 쓰고 CPU를 써서 생긴 문제였다. 왜인지는 모르겠지만 GPU가 시간이 지나면 다시 CPU로 바뀌는 경우가 종종 있었다. 그냥 학습되는 것을 모니터링하는 것 말고는 방법이 없었다
3. 데이터 불균형의 문제
욕설 데이터셋은 일반 문장 데이터셋에 비해 그 양이 적어 데이터 불균형의 문제가 발생했다. 이는 학습 결과에 있어 부정확한 결과를 초래했다.
오버샘플링: 학습에 쓰이는 데이터인 json파일은 1번부터 7번까지 있었는데, 테스트를 하여 학습량이 부족한 파일은 반복학습을 통해 이 문제를 해결했다.
클래스 가중치 적용: class_weight.compute_class_weight()를 통해클래스 가중치를 계산하고 모델 학습 시 적용했다. 이 방법은 소수 클래스에 더 높은 가중치를 부여하여 학습 시 불균형 문제를 완화할 수 있었다X_train, X_test, y_train, y_test = train_test_split(data, labels, test_size=0.2, random_state=42) X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.2, random_state=42) class_weights = class_weight.compute_class_weight(class_weight='balanced', classes=np.unique(y_train), y=y_train) class_weights = dict(enumerate(class_weights))
4. 데이터 부족함의 문제
데이터 부족 문제: 욕설 데이터셋의 부족함의 문제를 해결하기 위해데이터 증강을 했다. 기존 데이터를 다양한 방식으로 변형하여 데이터셋의 양을 늘릴 수 있으므로, 데이터 부족으로 인한과적합(overfitting)문제를 줄일 수 있었다.
편향된 데이터로 인한 문제 해결: 특정 표현 방식이나 패턴에만 치중된 학습 데이터는 모델이 다른 표현 방식에 대한 일반화 능력을 갖추지 못하게 할 수 있다.예를 들어, 띄어쓰기가 정확한 텍스트만 학습한 모델은 띄어쓰기가 잘못된 문장을 처리하는 데 어려움을 겪을 수 있다.
데이터 증강을 통해 띄어쓰기 오류나 특수 문자 변형 등을 포함한 데이터를 추가하여, 편향된 데이터셋을 보완하고 모델의 대응 능력을 개선할 수 있었다.# 데이터 증강 함수 def augment_data(text, badword_model): augmented = [text] # 띄어쓰기 제거 버전 추가 augmented.append(text.replace(" ", "")) # 랜덤 특수 문자 삽입 special_chars = ['@', '#', '$', '%', '^', '&', '*', '1'] for _ in range(3): index = random.randint(0, len(text) - 1) char = random.choice(special_chars) new_text = text[:index] + char + text[index:] augmented.append(new_text) # 비속어 변형 추가 for badword in badword_model: if badword in text: for variant in badword_model[badword]: augmented.append(text.replace(badword, variant)) return augmented
5. 학습 결과의 부정확함 문제
위에 있는 전처리 및 데이터 불균형 문제를 해결해도 몇몇 단어의 학습 결과가 이상하게 나왔다.
하이퍼파라미터설정 및 지속적인 테스트를 하여 학습 결과를 조정하였다하이퍼파라미터 설정
max_features = 15000 maxlen = 150 embedding_dim = 200 epochs = 20 batch_size = 32
🍅채팅 어플리케이션 연동
1. Flask 서버 설정
app = Flask(__name__) CORS(app, resources = {r"/predict": {"origins": ["*"]}})Flask를 서버로 사용하여 app.run() 부분에서 서버를 시작하고, CORS 설정을 통해 특정 엔드포인트("/predict")에서 CORS 허용도 설정했다.
2. TensorFlow AI 모델 로드
model = tf.keras.models.load_model(model_path)TensorFlow의 Keras를 사용하여 구현된 모델을 불러온다.
함께 로드되는 토크나이저는checkpoint/tokenizer.pickle파일에서 불러오고, 이 토크나이저는 텍스트 데이터를 숫자로 변환하는데 사용된다.
3. AI 모델로 입력 데이터 전처리
텍스트 데이터를 처리할 때
preprocess_text()함수에서 모델에 입력할 수 있는 형태로 변환된다. 텍스트는 먼저 토큰화된 후, 시퀀스 형태로 변환되고, 그 후pad_sequences를 사용해 지정된 길이(여기선 maxlen=100)로 패딩된다.def preprocess_text(text): sequences = tokenizer.texts_to_sequences([text]) padded_sequences = pad_sequences(sequences, maxlen=100) return padded_sequences이 과정은 모델이 텍스트 데이터를 이해할 수 있도록 하기 위한 필수적인 단계이다.
4. WebSocket을 통한 실시간 메시지 수신
코드의 중요한 부분 중 하나는
GraphQL을 사용하여 실시간 메시지를 수신하는 부분이다.WebSocket을 통해Hasura에서Chat_log_stream이라는구독(subscription)을 설정한다.subscription = gql(""" subscription MySubscription($started: timestamptz) { Chat_log_stream(batch_size: 10, cursor: {initial_value: {sent_at: $started}}, where: {}) { content message_id } } """)구독을 통해 실시간으로 채팅 메시지가 들어오면
session.subscribe()메서드를 통해 메시지를 받아오고, 해당 메시지의 텍스트는log['content']에 담긴다.
5. AI 모델을 통한 예측 수행
실시간으로 들어오는 채팅 메시지
(log['content'])는 먼저preprocess_text()함수를 통해 모델에 맞는 입력 형식으로 변환된다.processed_text = preprocess_text(log['content'])
이후, 이 전처리된 데이터를 모델에 입력하여 예측을 수행한다.
predictions = model.predict(processed_text)
모델은 0에서 1 사이의 값을 반환하며, 이 값은 해당 메시지가 공격적인지 여부를 나타낸다. 임계값 0.5를 기준으로
True또는False로 판단한다.is_profanity = bool(predictions[0][0] > 0.5)
6. AI 모델의 결과에 따른 후처리
만약 AI 모델이 해당 메시지를 공격적인(profanity) 것으로 판단하면, mutation 쿼리를 통해 GraphQL로 결과를 전달한다.
여기서는 update_Chat_log라는 쿼리로 데이터베이스에서 메시지의 상태(is_filtered)를 True로 업데이트한다.if is_profanity: mutationParams["mid"] = log["message_id"] response = mutationClient.execute(mutation, variable_values=mutationParams)
7. 전반적인 흐름 요약
- 채팅 메시지가 들어오면
WebSocket을 통해 실시간으로 서버에서 수신.Flask 서버가 메시지를 처리하고, AI 모델을 통해 공격성 예측을 수행.- 예측 결과에 따라 데이터베이스의 메시지 상태를 업데이트.
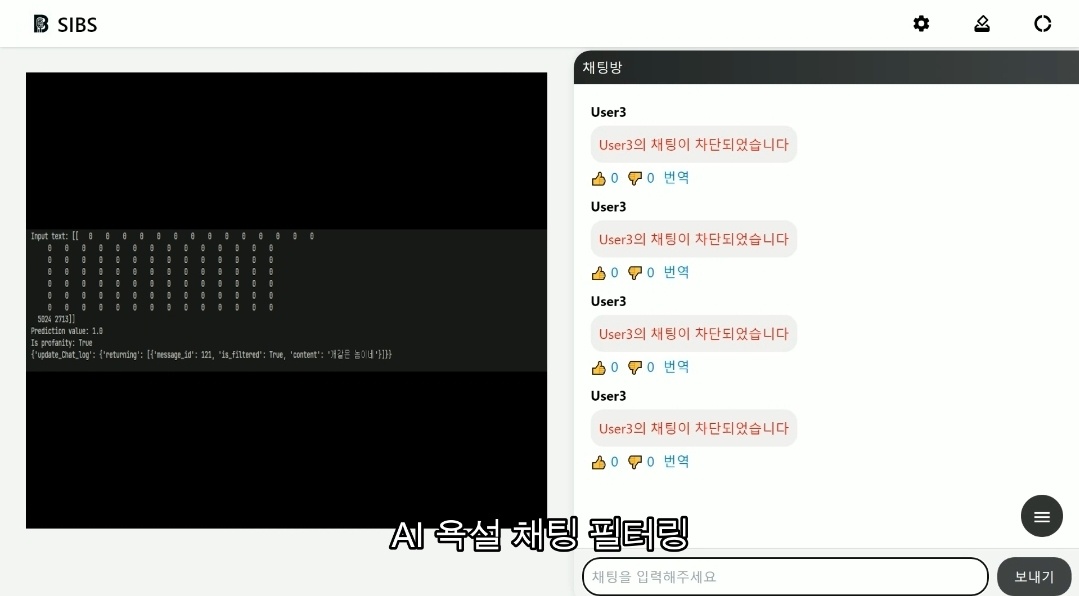
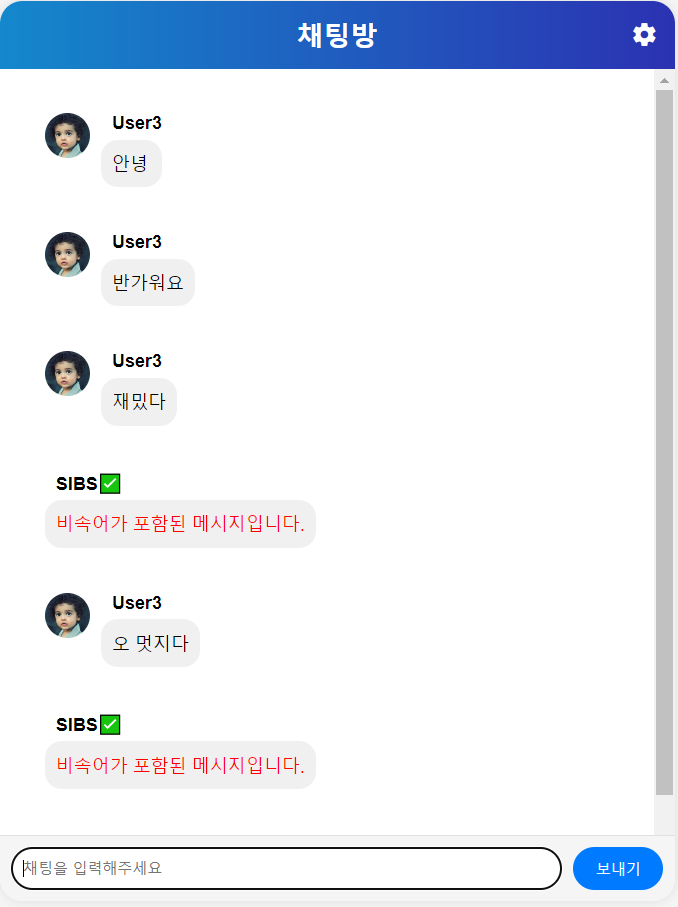
8. 최종 결과물
옆에는 원래 방송화면이 나와야 하지만 채팅의 필터링이 된다는 점을 보여주기 위해 로그를 띄웠다