논문 링크
https://arxiv.org/abs/1905.11946
Abstract
- 네트워크의 depth, width, resolution의 조정을 통해 기존 모델(MobileNet, ResNet)의 성능을 향상시키고자 함
- depth, width, resolution을 균일하게 조절하는 model scaling 방법인 compound scaling method 를 제안
- 이를 토대로 자신들만의 새로운 모델인 EfficientNet을 소개
1. Introduction
- 지금까지 ConvNet 모델을 확장시키는 것은 모델의 정확도를 향상시키는데 주로 쓰였다. 하지만 제대로된 이해와 함께 사용된 것은 아니었음
- 그래서 모델 확장에 대해 다시 연구를 한 결과, 네트워크의 depth, width, resolution의 균형을 맞추는 것이 중요하며 이들을 일정한 비율에 따라 조정을 하여 균형을 맞출 수 있다는 것을 알아냄
2. Related Work
- ConvNet Accuracy : 모델의 크기(파라미터 수)가 커질수록 정확도가 커지는 경향을 보임, 하지만 메모리 문제에 부딪힐 수 있기 때문에 더 효율적인 모델을 필요로 함
- ConvNet Efficiency : 현재의 규모가 작은 모델들(압축된 모델들)은 효율을 챙기기 위해 모델의 정확도를 어느 정도 포기함. 하지만 이런 효율을 증대하는 방법들을 매우 큰 모델에 적용시키는 방법은 명확하지 않음. model scaling을 통해 이러한 목표를 달성하고자 함
- Model Scaling : 지금까지 다양한 모델들이 네트워크의 depth, width, resolution의 조정으로 모델의 성능을 높였지만 어떻게하면 효율적으로 scaling을 할 수 있을지는 알려지지 않음.
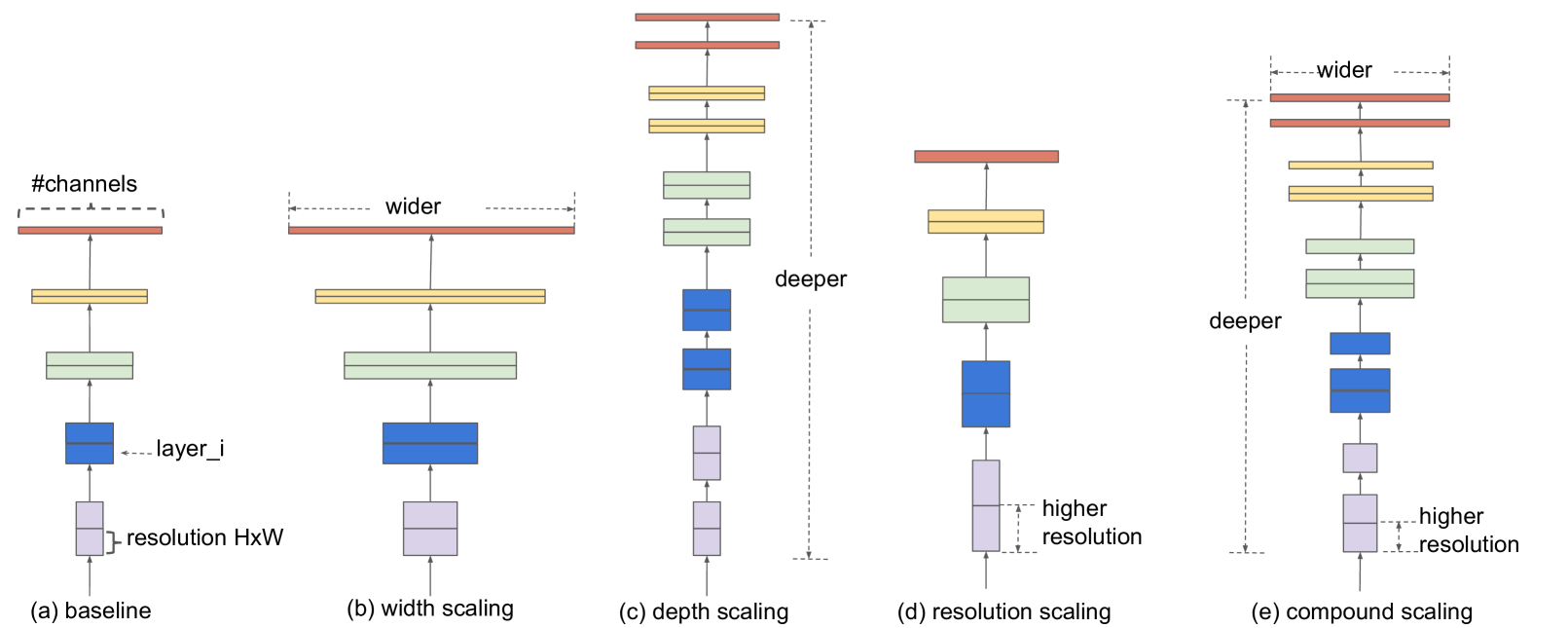
3. Compound Model Scaling
3.1 Probelm Formulation
기본적인 ConvNet의 구조를 다음과 같이 나타낼 수 있다.
는 stage 수, 는 각 Layer, 은 의 반복 횟수, 는 input, 는 input의 shape을 의미.
논문에서 모델이 사용하는 자원이 제한된 상태에서 모델의 정확도를 최대화하는 문제를 풀고자 하므로 문제를 다음과 같이 정의할 수 있다.

은 각각 네트워크의 depth, width, resolution을 의미
3.2 Scaling Dimensions
- Depth() : 가장 많이 쓰인 모델 scaling 방법. 깊이가 깊을수록 더 많고 복잡한 feature들을 잡아낼 수 있고 일반화 성능도 좋아진다. 하지만 깊이가 깊을수록 Vanishing Gradient 문제로 모델을 학습시키기 어려워진다.
- Width() : layer의 width를 키우면(Channel 수를 늘리면) feature들을 잘 잡아내고 학습시키기 용이하다. 하지만 깊이에 비해 큰 width를 가지면 high level feature를 잘 잡아내지 못한다.
- Resolution() : 큰 해상도의 input image는 세부적인 feature를 잡아내 정확도가 높아진다. 하지만 계산량이 많아지고 해상도가 높아져도 그에 비해 정확도가 크게 늘어나지 않는다.
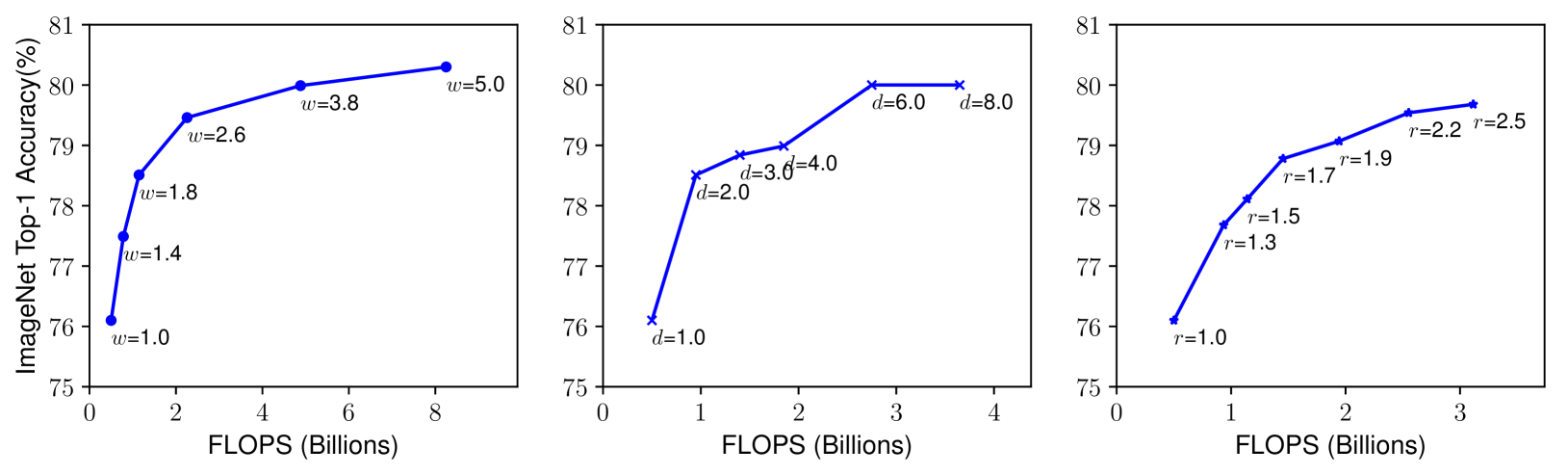
- 네트워크의 depth, width, resolution의 모든 차원을 확장하면 정확도가 향상되지만 더 큰 모델에서는 정확도 향상 폭이 감소하게 된다
3.3 Compound Scaling
-
앞서 언급한 다양한 스케일링 방법이 독립적이지 않음. 즉, 기존의 하나의 방법으로 scaling 하던 것과 달리 다른 방법의 scaling도 함께 조정하고 균형을 맞출 필요가 있음.
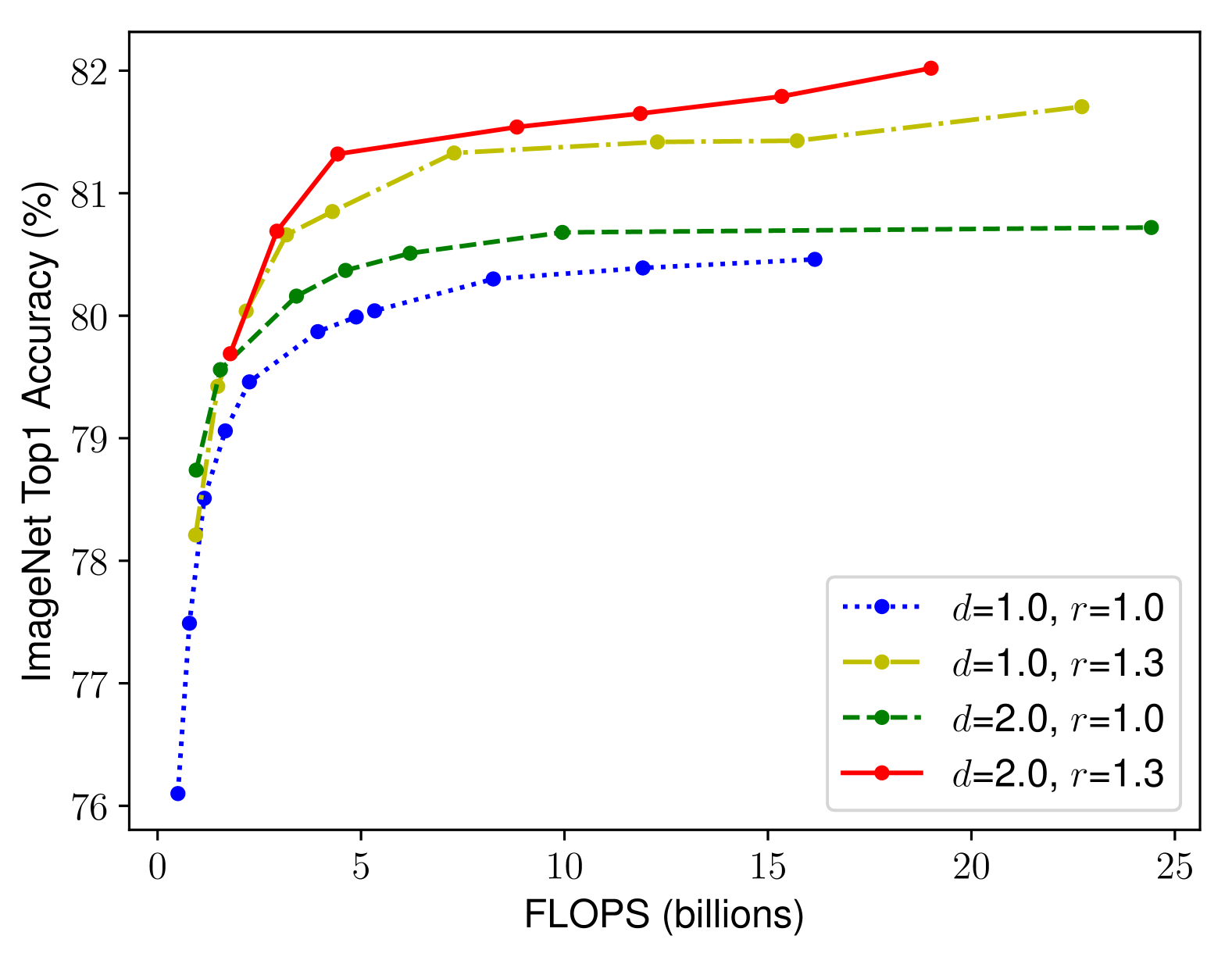
-
즉, 더 나은 정확도와 효율성을 위해서는 ConvNet Scaling 시 네트워크의 depth, width, resolution 균형을 유지하는 것이 중요함. - Compound Scaling Method를 제안
-
Compound Scaling Method : compound coefficient 를 두어 네트워크의 depth, width, resolution을 균일하게 scaling하는 방법
는 사용 가능한 자원 정도에 따라 사용자가 결정하는 계수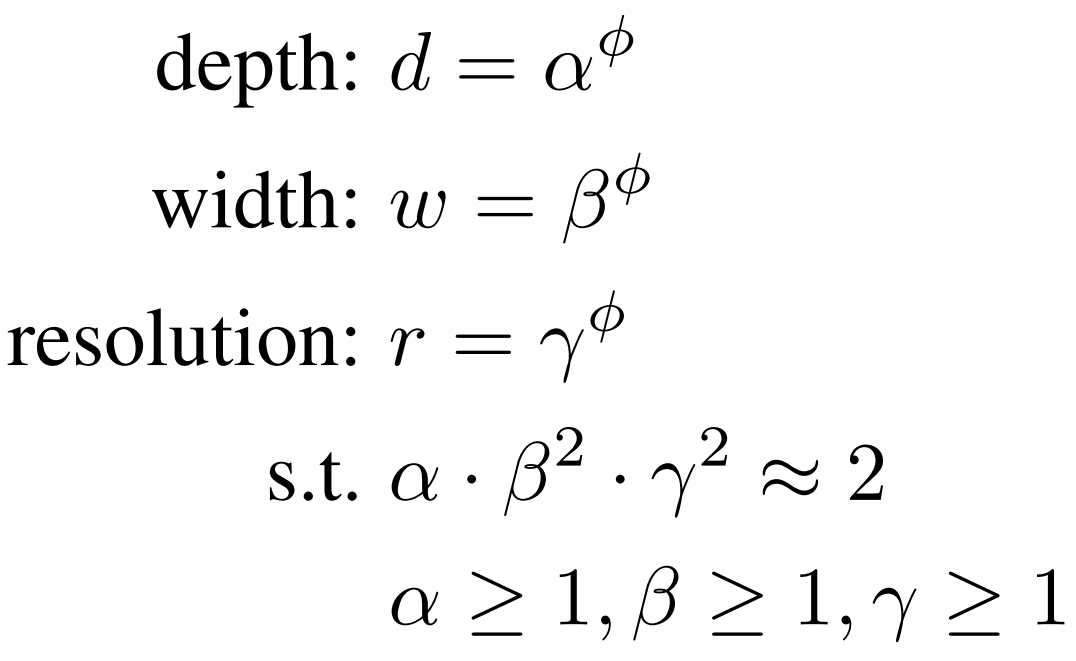
이 논문에서는 로 맞춰 전체 계산량(FLOPS)이 에 비례하도록 잡았다.
(와 에 제곱이 붙는 이유는 width와 resolution의 크기가 배 커지면 계산량은 배 만큼 커지기 때문)
4. EfficientNet Architecture
- Compound Scaling Method를 이미 존재하는 ConvNet(ResNet, MobileNet)에 적용해 평가
- 또한 EfficientNet이라는 새로운 모델에도 적용해 효율을 증명
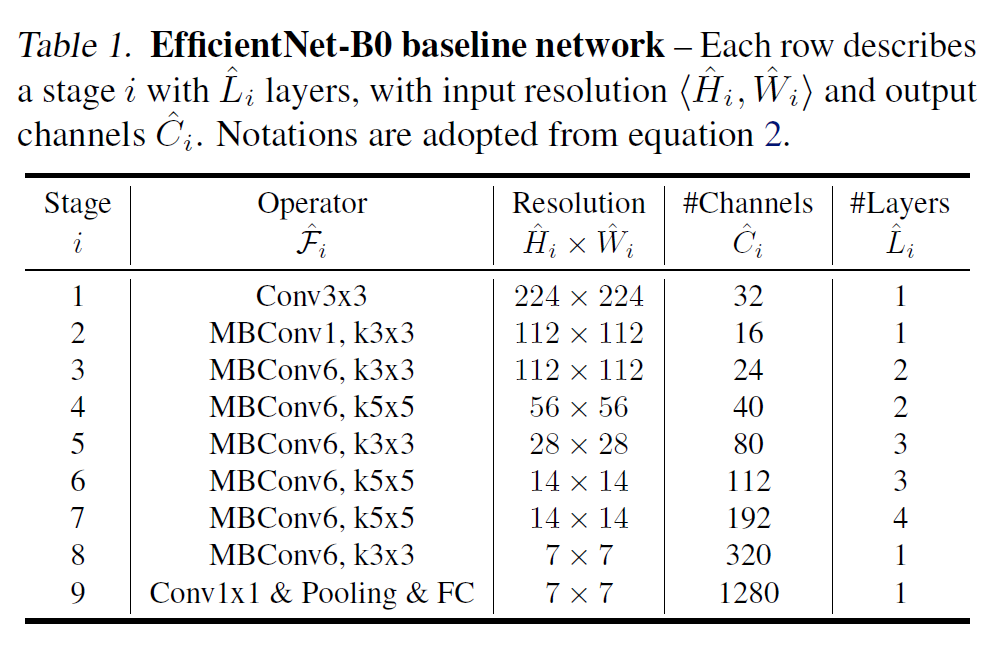
- 위의 EfficientNet-B0의 baseline network를 기반으로 진행 (기존의 MnasNet을 약간 변형하여 모델을 설계하였다고 함, FLOPS를 약 400M로 맞춤)
- 로 두고 시작, grid search를 통해 최적의 를 찾는다. (small grid search 방식)
- 일 때 EfficientNet-B0에서 가 최적의 값
- 최적의 를 찾은 후에는 그 값들을 고정, 값을 늘려가며 model upscaling 진행하며 EfficientNet-B1 ~ B7까지 모델 설계
5. Experiments
5.1 Scaling Up MobileNets and ResNets
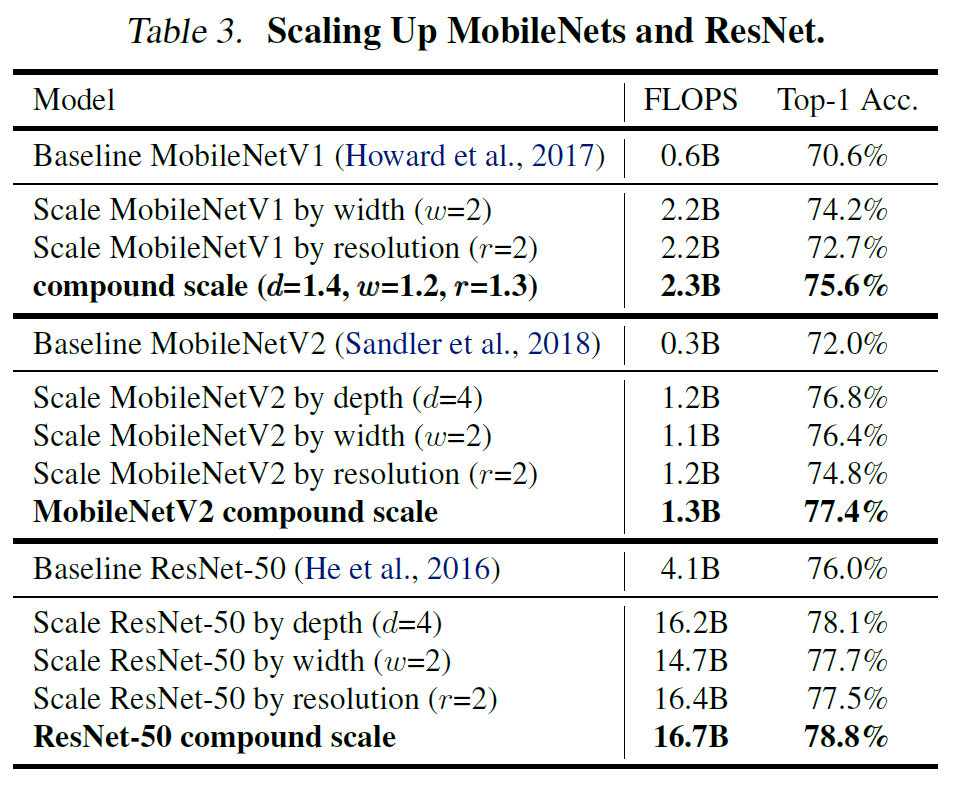
- MobileNet과 ResNet 모델에 Compound Scaling을 적용
- 따로 모델을 scaling up 한것 보다 Compound Scaling을 적용했을 때 더 높은 Accuracy를 기록했다.
5.2 ImageNet Results for EfficientNet
- EfficientNet을 ImageNet Dataset으로 학습
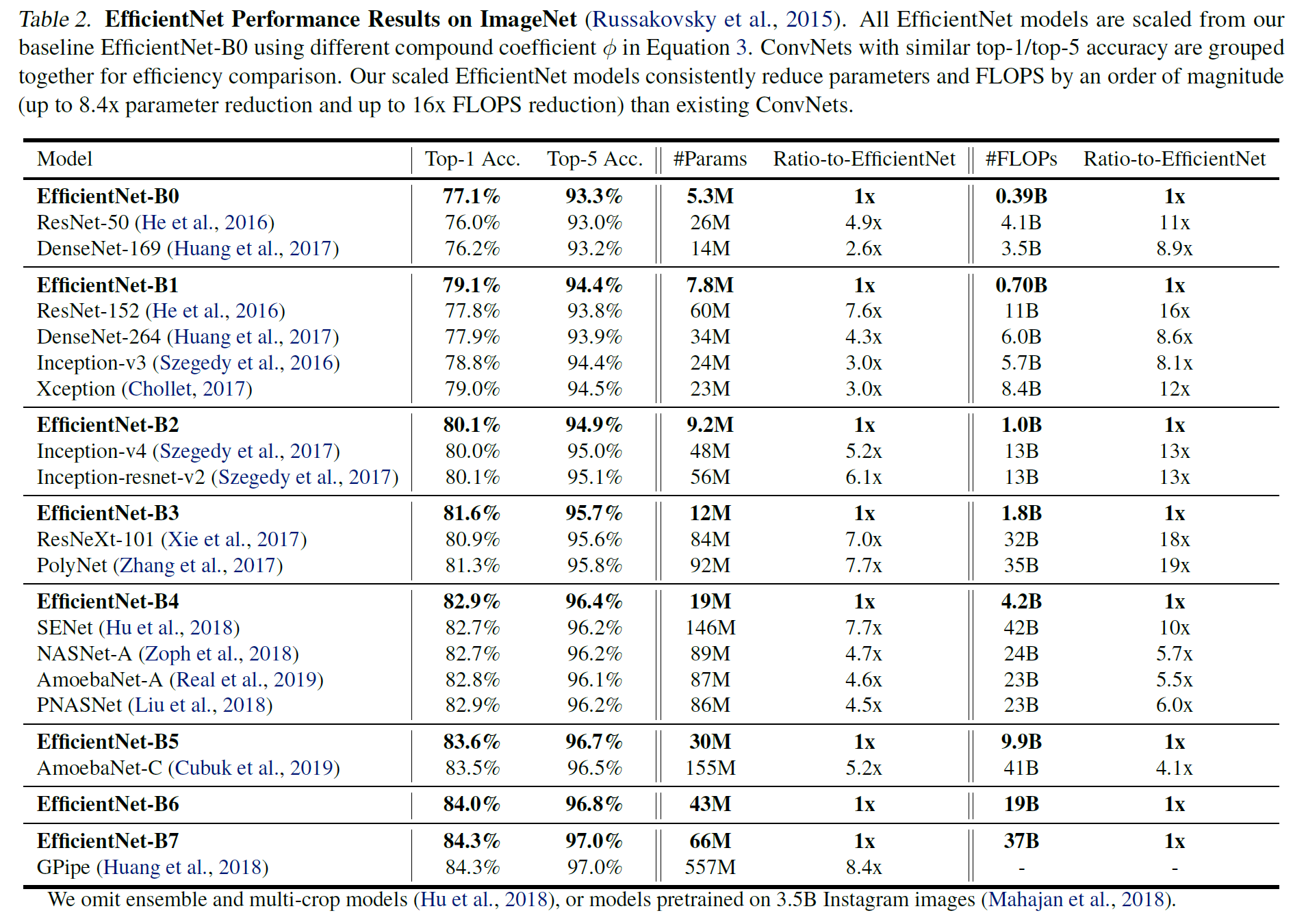
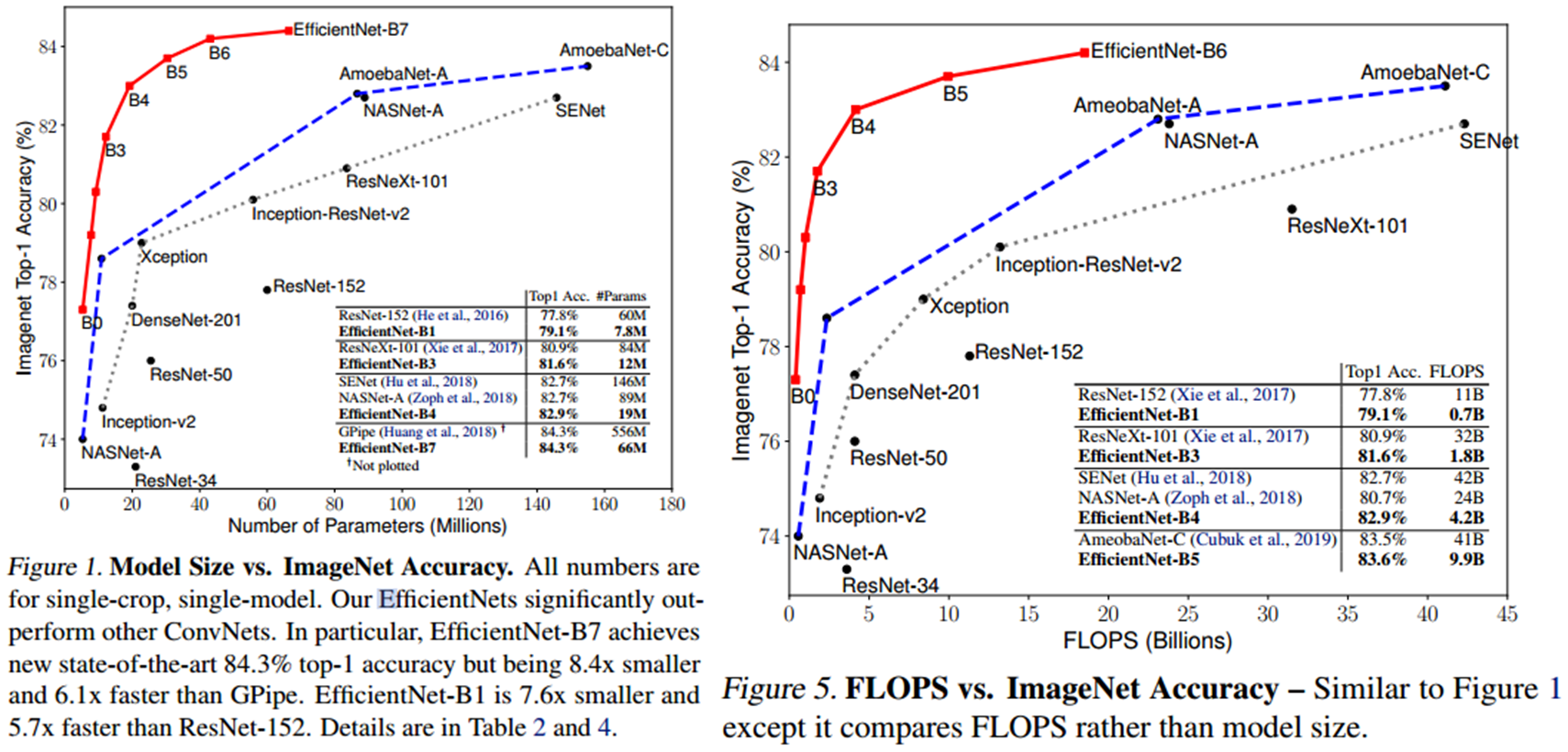
- 기존의 ConvNets 보다 Parameters와 FLOPS 대비 좋은 성능을 보였다.

- 또한 Latency 측면에서도 기존의 모델들보다 빠른 속도를 보였다.
5.3 Transfer Learning Results for EfficientNet
- Transfer Learning Datasets에 적용한 EfficientNet
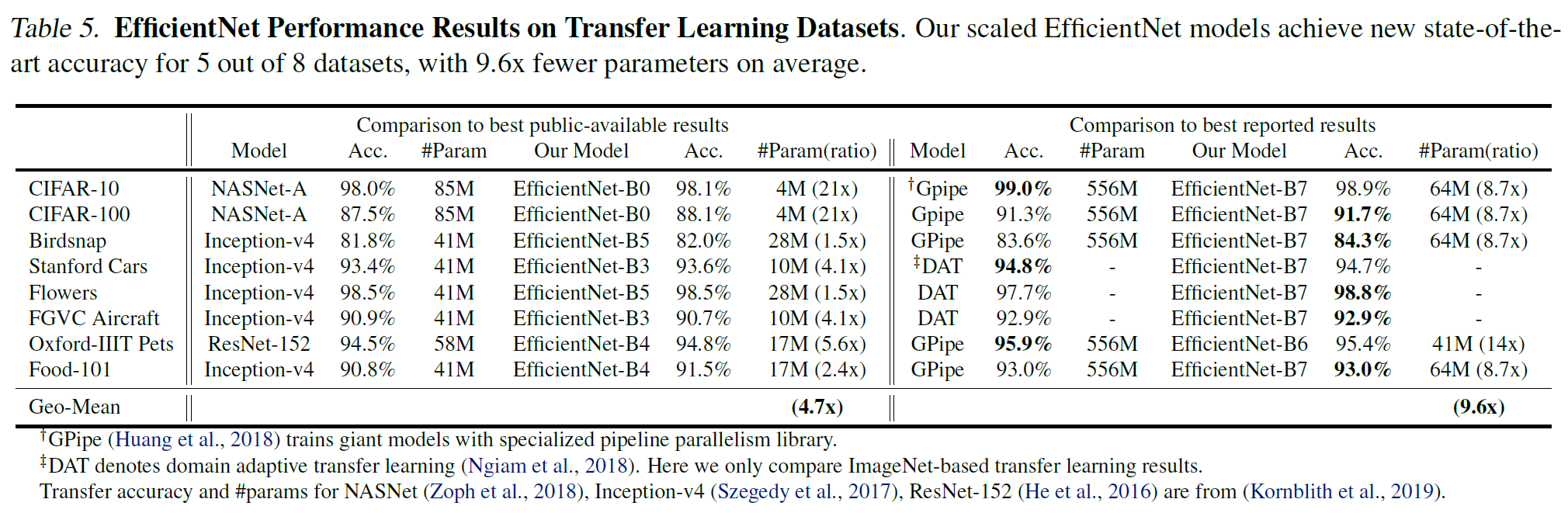
- EfficientNet이 평균 4.7배 적은 파라미터 수로 더 좋은 Accuracy를 기록
- 또한 8개의 Datasets 중 5개의 Datasets를 대상으로 SOTA Accuracy를 달성
- Transfer Learning으로도 훨씬 적은 파라미터 수로 더 좋거나 비슷한 성능을 기록
6. Discussion
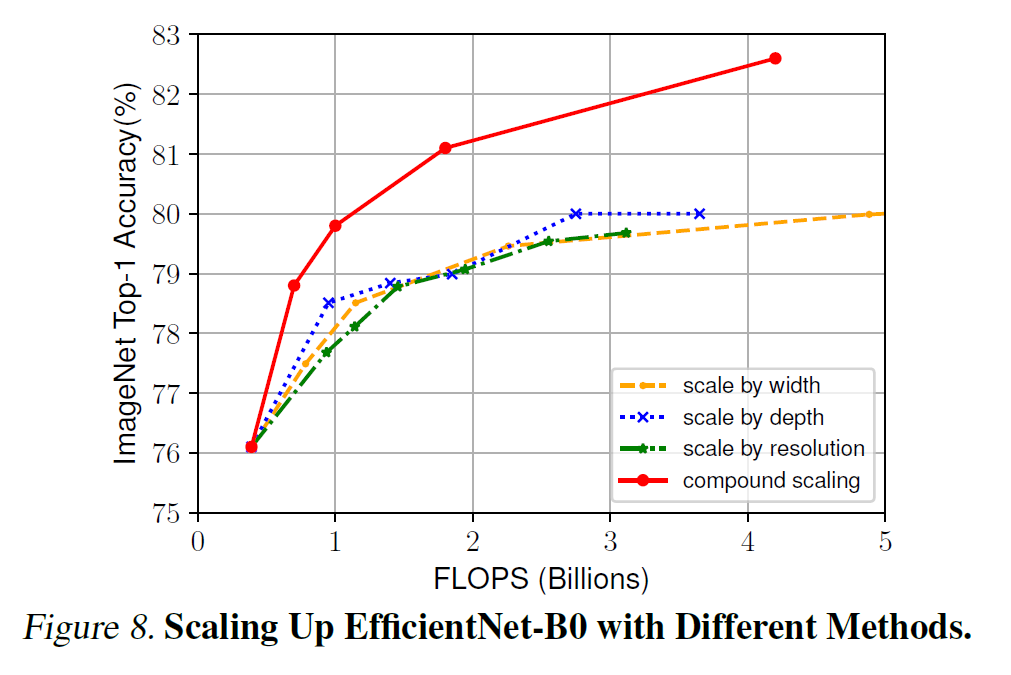
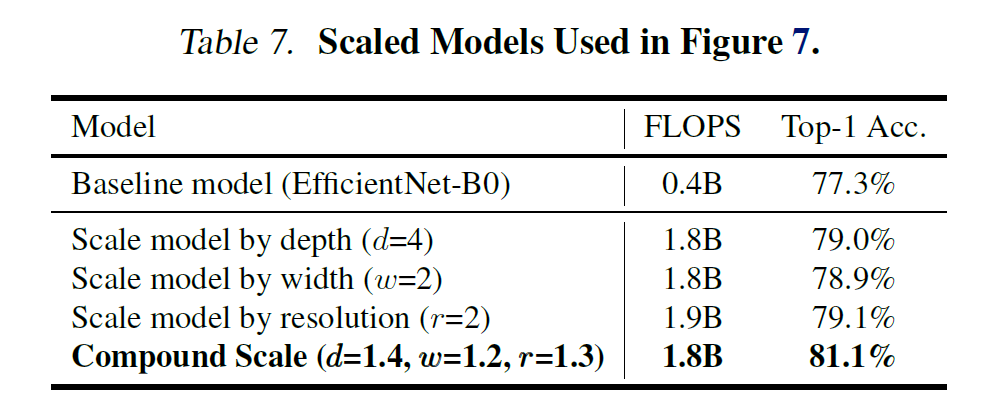
- 네가지의 scaling method를 비교 - 모두 비슷한 FLOPS에 Accuracy를 높여주지만 Compound Scaling의 Accuracy 증가 폭이 제일 높다.
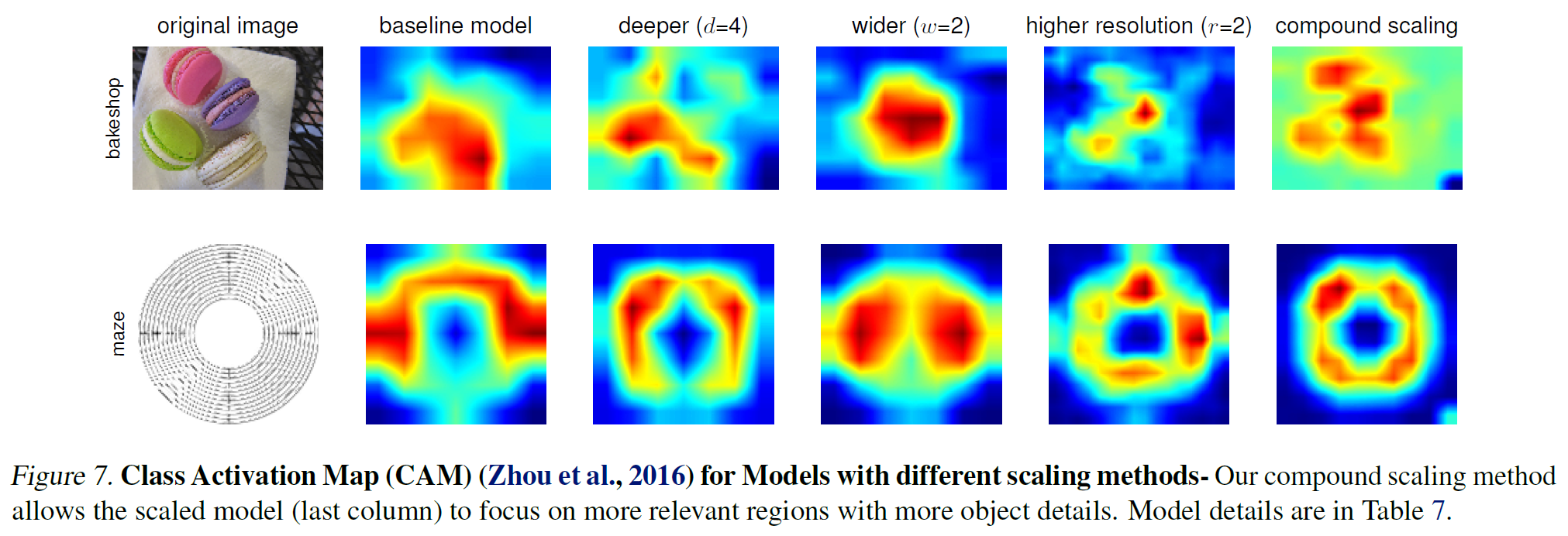
- Compounding Scaling이 잘 되는 이유에 대해 알기 위해 Visualization(CAM)
- 위 네가지의 scaling method들의 Class Activation Map(CAM)을 비교한 결과, Compound Scaling의 방법이 객체의 디테일한 부분에 집중한다는 것을 보여줌
7. Conclusion
네트워크의 depth, width, resolution의 적절한 조정을 통해 모델의 파라미터와 FLOPS를 낮게 유지한 채 Accuracy를 높일 수 있는 Compound Scaling Method를 제시
참고
https://greeksharifa.github.io/computer%20vision/2022/03/01/EfficientNet/
https://deep-learning-study.tistory.com/552
