[GPT-1] Improving Language Understanding by Generative Pre-Training
*본 템플릿은 DSBA 연구실 이유경 박사과정의 템플릿을 토대로 하고 있습니다.
1. 논문이 다루는 Task
- Task: 트랜스포머 디코더만을 활용해 Unlabeled 된 Text를 Unsupervised pre-training하여 task에 맞게모델 fine-tuning 하여 각종 Task에 적용할 수 있는 Transformer의 디코더만 사용한 모델
기존의 모델들은 사전학습된 language representation을 활용하여 다운스트림 Task에 적용한다. 현재 GPT는 Unlabeled 된 Text를 Unsupervised pre-training 모델을 각기 다른 Task 에 마지막 레이어를 추가해 fine-tuning 하여 각종 GLUE에 있는 각종 task에서 SOTA 성능을 달성하였다.
💡 상세 설명 :
- GPT-1은 Trnasformer의 디코만을 사용하여 GLUE 및 각종 벤치마크에서 SOTA의 성능을 달성하였다.
- 모델을 각기 다른 Task에 fine-tuning 할때 Task에 맞는 레이어를 맨 마지막에 추가시켜 fine-tuning을 진행한다.
- Pretrained 모델을 학습 할때 Unsupervised learning을 통하여 대규모 텍스트 데이터를 통하여 학습을 진행하였다.
- Pretrained 모델의 학습은 다음 토큰을 예측하는 방식을 사용하였다.
- 현재 ChatGPT의 프롬프트처럼 LM 모델 Zero shot의 지평선을 열었다.
2. 기존 연구 한계
Semi-supervised learning for NLP
기존에도 Unlabled된 대규모의 말뭉치를 사용하려고 했던 시도가 많이 존재하였다. 대규모 말뭉치의 통계값을 이용하고 훈련된 임베딩 벡터를 이용하는 시도가 있었다. 실제로 위와 같은 방법들이 효과는 있었지만 하지만 단어 수준의 관계 밖에 캡처할수 없다고 주장한다. 논문에서는 좀 더 높은 의미론적인 관계를 캡처하는데 목표를 둔다.
Unsupervised pre-training
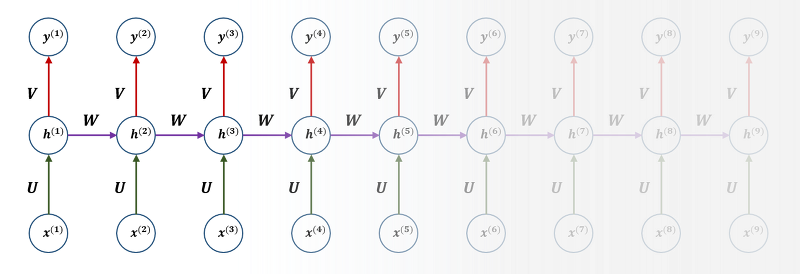
초기에는 이미지 분류나 회기작업에서 대규모 데이터를 통하여 초기값을 지정하고 이를 활용하는 기술을 연구하였지만 이 기술이 입증이 되면서 더욱 많은 작업에 활용되었다. NLP에서는 LSTM이 활용되었지만 long-term dependency의 문제로 인해 오히려 예측하는 능력이 짧아진다고 주장하며 트랜스포머의 이점을 주장하였다.
Auxiliary training objectives
추가적인 sub object function을 두는 것으로써 많은 성능 향상을 이루어냈다. 초기에는 POS 태깅, 엔티티 인식등이 주를 이루고 보다 최근엔 언어 모델링을 sub object function 로 활용하였다.
3. Framework
GPT-1은 Two-stage의 학습 방법을 가지고 있다.
1. 대규모 텍스트 코퍼스를 통해 언어 모델을 학습한다.
2. task에 맞게 레이블이 지정된 데이터를 사용하여 모델을 미세조정 한다.
Unsupervised pre-training
첫 번째 스텝인 Unsupervised pre-training은 대규모의 텍스트를 통해 언어 모델을 학습하게 되는데 이때
= window size
= conditional probability
= neural network with parameters
위 목적 함수를 최대화 시키는 방향으로 학습을 진행하게 된다.
= Token Context Vector
= number of layers
= token embedding matrix
= position embedding matrix
이때 사용하는 모델은 여러개의 레이어를 가진 을 사용하게 되며 수식은 위와 같다.
Supervised fine-tuning
Unsupervised pre-trainingd으로 훈련된 모델의 파라미터를 가져와서. 새로운 task에 맞는 labeled 된 데이터 에 훈련시킨다. 이때 추가적으로 Linear layer가 추가 된다.
= sequence of input tokens
= laebl
= final transformer block's activation
= added linear output layer
목적 함수는 아래와 같다.
또한 위 논문에서 추가적으로 언어모델링을 sub object function으로 만들게 되면 일반화 성능과 수렴을 가속한다고 주장하며 아래와 같이 목적 함수를 결합하여 사용하게 된다.
같은 경우 위의 수식에서 가 로 바뀌었는데 이는 새로운 데이터에 대하여도 Unsupervised pre-training을 동일하게 수행한다는 의미다.
Task-specific input transformations
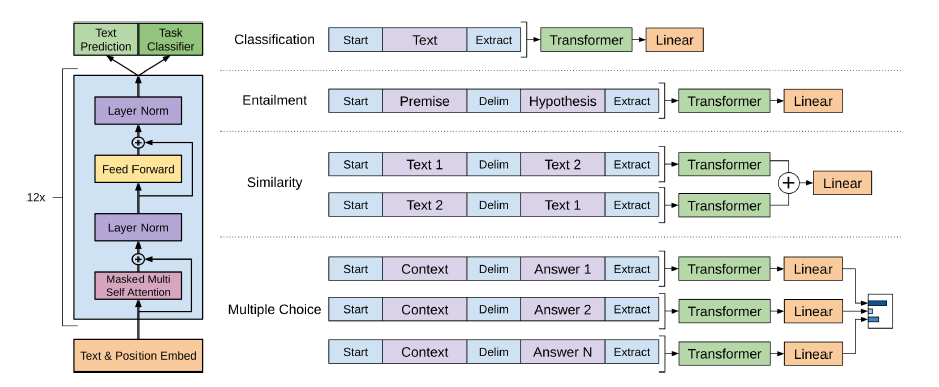
비록 학습은 LM으로 진행 되었지만 Downstream task시에 input 모양이 다를 수밖에 없는 점을 위와같이 수정하였다.
1. Classification : 입력되는 text 앞 뒤로 token을 부착시켜 Transformer의 입력으로 넣는다.
2. Entailment : 전제 가설 의 형식으로 입력을 넣는다.
3. Similarity : Entailment와 유사하게 입력이 들어가지만 두 가지의 문장의 순서가 존재하지 않기 때문에 문장의 순서를 바꿔서 입력으로 넣게 된다. 최종적으로 transformer의 나온 두가지의 문장의 벡터를 element-wise sum하여 Linear의 입력에 넣어 분류하게 된다.
4. Question Answering and Commonsense Reasoning : 각각은 Entailment와 유사하지만 Context는 동일하며 Answer N개 만큼의 벡터를 각각의 Linear에 통과시켜 이를 softmax layer을 통과시켜 출력 분포를 만들게된다.
✨Contribution
- Unsupervised pre-training을 사용하여 대규모 텍스트 코퍼스를 학습에 사용할 수 있게 하였으며 덕분에 Supervised fine-tuning에서 많은 성능 향상을 얻어내었다.
- 입력을 교체하고 최소한의 레이어를 교체함으로써 각 task를 수행할 수 있다.
- sub object function인 Auxiliary training objectives 을 도입하여 labeled된 데이터 에서도 보다 원활한 학습을 진행하게 하였다.
4. 실험 및 결과
setup
Unsupervised pre-training 데이터는 BookCorpus dataset으로 진행하였다. 논문에서는 책이라서 long term dependency를 학습 할 수 있다고 주장한다. 또한 ELMO는 문장을 모두 섞어 버려서 long term dependency 학습하기 어렵다고 주장한다.
Model specifications
- = 768
- _ = 12
- _ = 12
- - = 3072
모델은 - 과 을 제외하면 기본 Transformer와 동일하다. 추가적인 변경사항으로는 활성화 함수를 Gelu로 변경하였으며 모델 학습 시 l2 regularization을 사용하였다. positional encoding의 경우 주기함수 대신 학습 가능한 파라미터로 대체 하였다.
Pre-Training details
- = 100
- = 2.5e-4
- = cosine schedule
- = 514
- = 64
Fine-tuning details
- = 3
- = 6.25e-5
- = 32
- = linear learning rate decay schedule
- = 0.5
Experiment
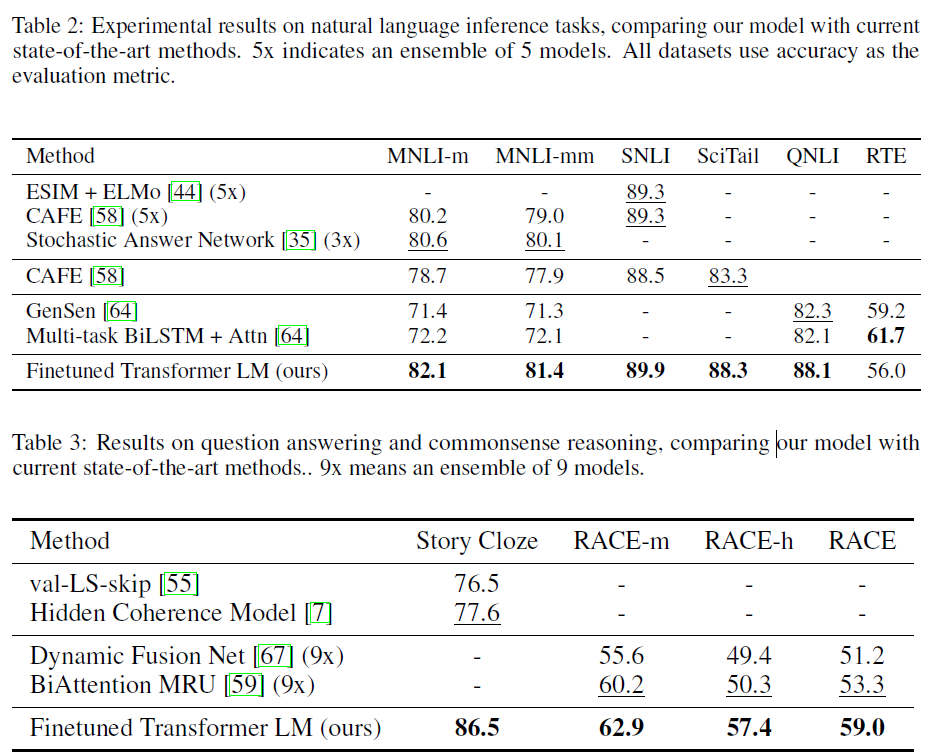
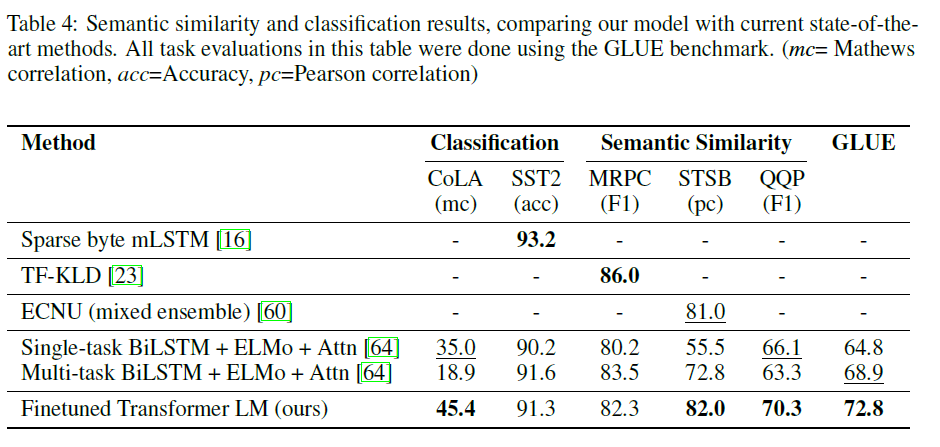
GPT-1은 12가지의 코퍼스에서 9개에서 SOTA를 달성하였다. SOTA가 아니더라도 비교적 SOTA에 근접한 높은 성능을 달성하였으며. 소규모의 작은 데이터셋(STS-B 5.7k)그리고 다양한 크기(SNLI 550k)의 데이터셋에서 잘 작동함을 증명해내었다.
Analysis
Impact of number of layers transferred
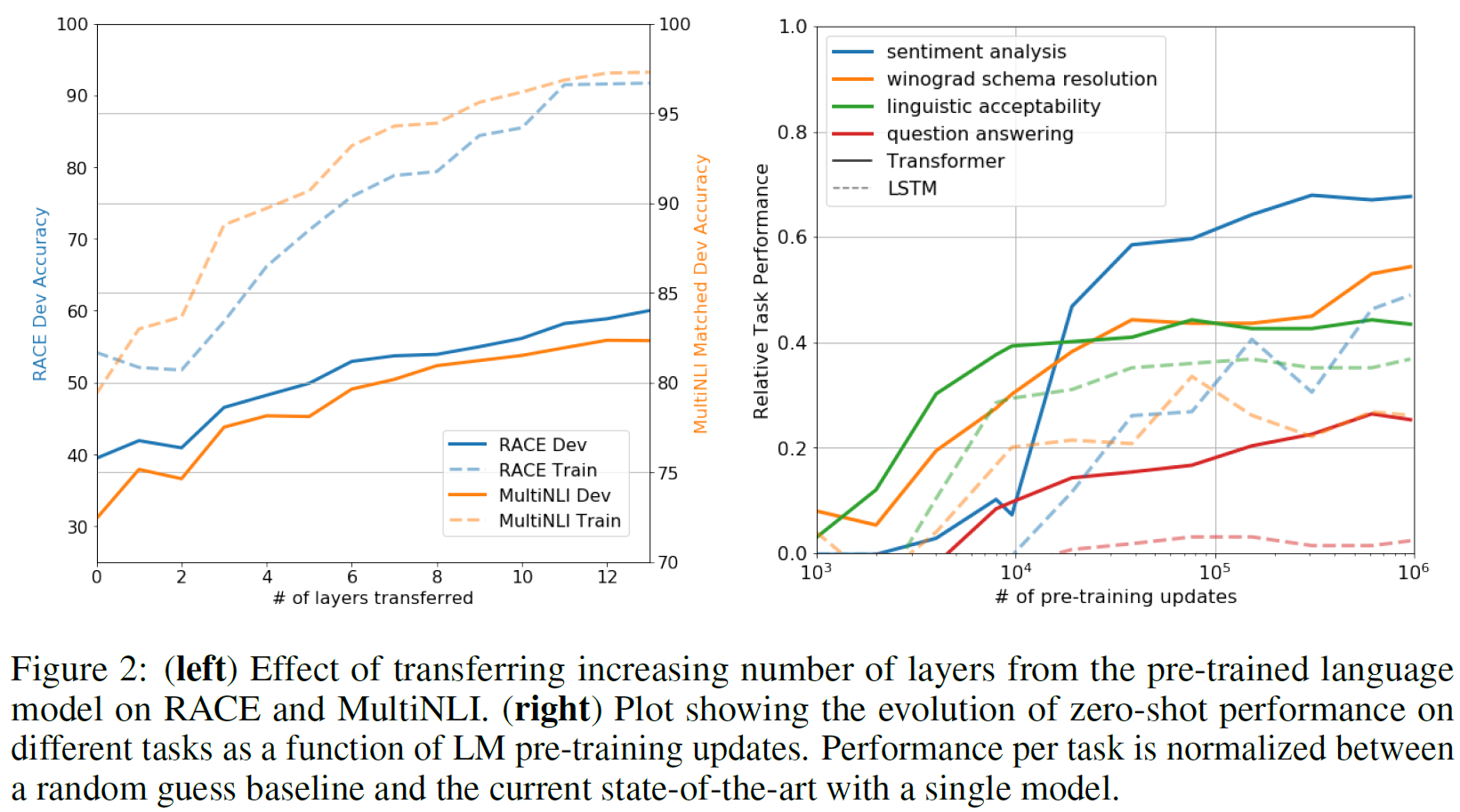
왼쪽의 그래프는 layers수의 증가량에 따라 RACE와 MultiNLI에 대해 실험을 진행하였다. pre-trained 된 GPT의 레이어를 몇개를 가져올까 하는것인데 오른쪽으로 갈 수록 output에 가까운 레이어를 가져오게 된다. 그래프를 보아도. 성능이 올라가게 되는데 이는 각각의 레이어가 문제를 해결하기위한 유용한 기능이 포함되있다고 주장한다.
Zero-shot Behavior
오른쪽 그래프는 GPT-1의 pre-train의 진행만으로 task마다의 다운스트림 테스크에 대한 성능을 보여주는 것 이다. 그래프를 보았을때 LSTM을 pre-train 시킨 것보다 GPT-1이 높은 성능을 보여주고 있다. 여기서의 결과는 LM 자체가 파인튜닝,제로 샷 없이 문제를 해결하는 과정을 보여준다.
- Sentiment analysis : 문장에 토큰을 append 시키고 출력을 , 로 제한하였다.
- winograd schema resolution : 명확한 대명사 2가지를 가능한 참조로 바꾸고 생성 모델이 차환후 나머지 시퀀스에 대하여 더 높은 토큰의 로그 확률을 할당한다.
- Linguistic Acceptability : 출력 토큰의 average token log-probability를 이용하여 thresholding으로 예측
- question answering : 문서와 질문을 입력으로 하여 생성되는 문장들 중에 가장 average log-probability가 높은 문장을 예측한다.
Ablation studies
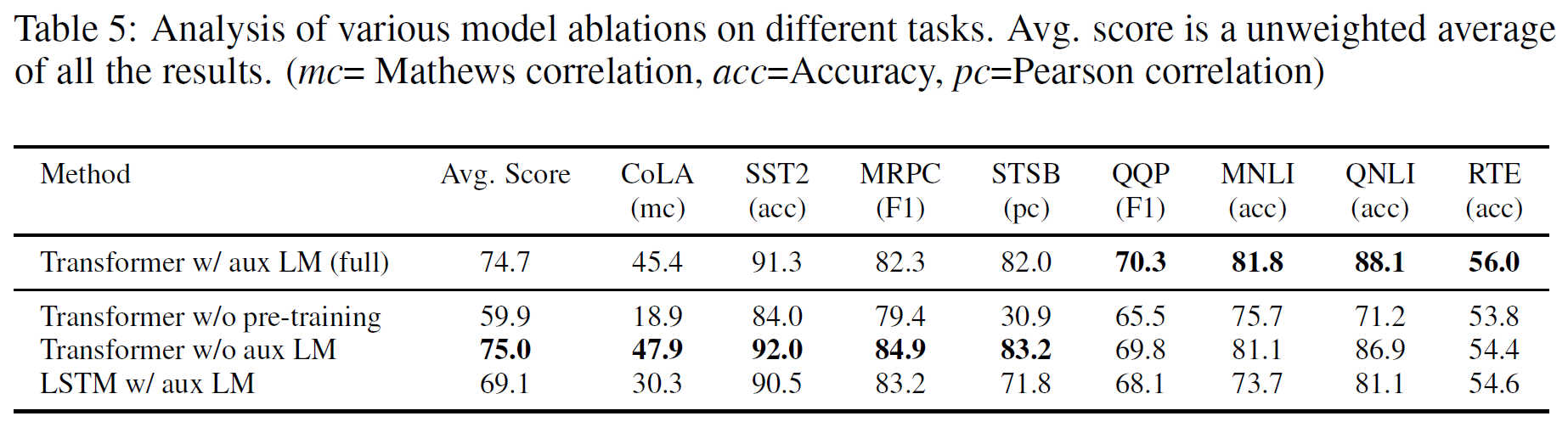
여기서는 전체 GPT-1과 보조 LM 목적함수가 없을경우 그리고 LSTM에 대하여 비교한다.
논문에서 주장하는 바에 따르면
1. fint-tuning 단계에서 보조 LM 목적함수는 NLI task들과 QQP같은 큰데이터셋에서 도움이 되지만 작은 데이터셋에서는 그렇지 못한다고 주장한다.
2. Transformer의 구조를 2048 unit의 LSTM으로 대체하였는데 MRPC를 제외하고 평균점수가 5.6점이 감소한다.
3. pre-train 없이 task를 진행하였을시 14.8% 성능이 감소하였다.
Conclusion
OpenAI에서 개발된 모델로 단어와문장의 의미를 이해하고 다음의 나올 텍스트를 예측할 수 있다.
pre-train을 통하여 두가지의 스텝으로 간단하게 학습을 진행하며 트랜스포머의 구조를 채택함으로써 확실히 장거리 context를 잘 캡처하고 다양한 task에 대하여 fine-tuning을 보다 손쉽게 진행할 수 있다.
확실히 ELMo와 같은 년도에 출시했지만 Transformer의 구조를 채택한점이 큰 것 같다.
회고
GPT-1은 논문리뷰하면서 머리가 조금 아픈것같다. BERT는 많이 써봐서 그런지 비교적 익숙했지만 GPT는 써본적이 ChatGpt밖에 없어 조금 어색한것같은 느낌이 들었다. ELMo를 리뷰한적은 없어서 글이 상당히 난잡하지만 앞으로 읽을게 많으므로 ELMo는 따로 영상을 보고 다음 논문 리뷰를 이어나가야겠다.
